当前位置:网站首页>深度学习经典网络解析目标检测篇(一):R-CNN
深度学习经典网络解析目标检测篇(一):R-CNN
2022-04-23 18:04:00 【Jsper0420】
深度学习经典网络解析(一):R-CNN
R-CNN论文详情见我的博客:
深度学习论文阅读(七):R-CNN《Rich feature hierarchies for accurate object detection and semantic segmentation》
1.背景介绍
目标检测(Object Detection) 就是一种基于目标几何和统计特征的图像分割,它将目标的分割和识别合二为一,通俗点说就是给定一张图片要精确的定位到物体所在位置,并完成对物体类别的识别。其准确性和实时性是整个系统的一项重要能力。
在卷积神经网络被成功应用于图像分类后,2014 年,Ross Girshick,Jeff Donahue 等人提出了 R-CNN(Regions with CNN features)方法,并尝试将其应用到目标检测上。之前 Szegedy 等人已经尝试用深度卷积神经网络直接预测目标检测边界框,将定位(localization)问题看作一个回归(regression)问题,但是效果并不是很好,在 Pascal VOV 2007 数据集上只有 30.5% 的精度。R-CNN 在此基础上进行了反思,放弃了把问题简单地看作成一个回归模型,转而使用滑窗(sliding-window)的方法,并达到了 58.5% 的精度。
R-CNN的全称是Region-CNN (区域卷积神经网络),是第一个成功将深度学习应用到目标检测上的算法。R-CNN基于卷积神经网络(CNN),线性回归,和支持向量机(SVM)等算法,实现目标检测技术。
2.目标检测(Object Detection)
想要了解R-CNN,一定先要明白目标检测是什么?只有了解了目标检测的原理,才能理解R-CNN。在计算机视觉众多的技术领域中,目标检测(Object Detection)也是一项非常基础的任务,图像分割、物体追踪、关键点检测等通常都要依赖于目标检测。
在目标检测时,由于每张图像中物体的数量、大小及姿态各有不同,也就是非结构化的输出,这是与图像分类非常不同的一点,并且物体时常会有遮挡截断,所以物体检测技术也极富挑战性,从诞生以来始终是研究学者最为关注的焦点领域之一。
在计算机视觉中,图像分类、目标检测和图像分割都属于最基础、也是目前发展最为迅速的3个领域,我们可以看一下这几个任务之间的区别。
图像分类:输入图像往往仅包含一个物体,目的是判断每张图像是什么物体,是图像级别的任务,相对简单,发展也最快。
目标检测:输入图像中往往有很多物体,目的是判断出物体出现的位置与类别,是计算机视觉中非常核心的一个任务。 ·
图像分割:输入与物体检测类似,但是要判断出每一个像素属于哪一个类别,属于像素级的分类。图像分割与物体检测任务之间有很多联系,模型也可以相互借鉴。
目标检测是深度学习的一个重要应用,就是在图片中要将里面的物体识别出来,并标出物体的位置,一般需要经过两个步骤:
1、分类,识别物体是什么

2、定位,找出物体在哪里

除了对单个物体进行检测,还要能支持对多个物体进行检测,如下图所示:

这个问题并不是那么容易解决,由于物体的尺寸变化范围很大、摆放角度多变、姿态不定,而且物体有很多种类别,可以在图片中出现多种物体、出现在任意位置。因此,目标检测是一个比较复杂的问题。
最直接的方法便是构建一个深度神经网络,将图像和标注位置作为样本输入,然后经过CNN网络,再通过一个分类头(Classification head)的全连接层识别是什么物体,通过一个回归头(Regression head)的全连接层回归计算位置,如下图所示:

但“回归”不好做,计算量太大、收敛时间太长,应该想办法转为“分类”,这时容易想到套框的思路,即取不同大小的“框”,让框出现在不同的位置,计算出这个框的得分,然后取得分最高的那个框作为预测结果,如下图所示:

根据上面比较出来的得分高低,选择了右下角的黑框作为目标位置的预测。
但问题是:框要取多大才合适?太小,物体识别不完整;太大,识别结果多了很多其它信息。那怎么办?那就各种大小的框都取来计算吧。
如下图所示(要识别一只熊),用各种大小的框在图片中进行反复截取,输入到CNN中识别计算得分,最终确定出目标类别和位置。

这种方法效率很低,实在太耗时了。那有没有高效的目标检测方法呢?R-CNN横空出世
3.R-CNN
3.1 传统目标检测
传统的目标检测方法一般分为三个阶段:首先在给定的图像上选择一些候选的区域,然后对这些区域提取特征,最后使用训练的分类器进行分类。

- 区域选择
这一步是为了对目标进行定位。传统方法是采用穷举策略。由于目标可能在图片上的任意位置,大小不定,因此使用滑动窗口的策略对整幅图像进行遍历,而且需要设置不同的长宽。这种策略虽然可以检测到所有可能出现的位置,但是时间复杂度太高,产生的冗余窗口太多,严重影响后续特征的提取和分类速度的性能。

- 特征提取
提取特征的好坏会直接影响到分类的准确性,但又由于目标的形态多样性,提取一个鲁棒的特征并不是一个简单的事。这个阶段常用的特征有SIFT(尺度不变特征变换 ,Scale-invariant feature transform)和HOG( 方向梯度直方图特征,Histogram of Oriented Gradient)等。
- 分类器
最后是分类器,常常被使用的分类器包含Adaboost,SVM,Decision Tree等。在很多时候单一的分类器可能并不能满足我们的要求,如今使用深度学习来完成各项任务,尤其是参加各类比赛的时候,一定会使用不同的模型不同的输入进行Ensemble。比如我们常见的使用不同的裁剪子区域进行预测,或者使用不同的基准模型进行预测,最后取平均概率等。
综上所述,传统目标检测存在两个主要问题:一个是基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余;二是手工设计的特征对于多样性没有很好的鲁棒性。
3.2 R-CNN与传统目标检测
R-CNN与传统目标检测比较,R-CNN使用了CNN网络来提取特征。
采用大样本下有监督预训练+小样本微调的方式解决小样本难以训练甚至过拟合等问题(现实任务中,带标签的数据可能很少)
3.3 R-CNN目标检测流程
流程如下图所示:


- 首先是原图,然后在原图上使用一定的方法产生一些感兴趣的区域,也就是可能含有目标的区域(region proposals)。
- 将产生的候选区域resize到一个固定大小(因为神经网络的输入是固定的,其实卷积操作的输入可以不固定,全连接层的输入大小才是固定的,这也是后面几个模型会改进的),
- 将resize后的图像输入到一个CNN网络(这个网络可以是现成的模型,然后微调即可),CNN网络会提取出固定维度的特征向量(原文中使用了AlexNet,去掉最后一个输出层,提取出4096维的特征,也远比传统方式的少了很多)
- 再将提取到的特征输入给预先训练好的一组SVM分类器(一共有k个,k即是类别总数,每个都是二分类器),识别出区域中的目标是什么(同时也就大致定位了目标的位置,后面的内容会对该位置精修,使其更准确。

简而言之就是:
- 给定一张输入图片,从图片中提取 2000 个类别独立的候选区域。
- 对于每个区域利用 CNN 抽取一个固定长度的特征向量。
- 再对每个区域利用 SVM 进行目标分类。
对于R-CNN而言:
-
区域选择
够生成候选区域的方法很多,比如:objectness、selective search、category-independen object proposals、constrained parametric min-cuts(CPMC)、multi-scale combinatorial grouping、Ciresan。R-CNN 采用的是 Selective Search 算法。 -
特征提取
R-CNN 抽取了一个 4096 维的特征向量,采用的是 Alexnet。需要注意的是 Alextnet 的输入图像大小是 227x227。而通过 Selective Search 产生的候选区域大小不一,为了与 Alexnet 兼容,R-CNN 采用了非常暴力的手段,那就是无视候选区域的大小和形状,统一变换到 227*227 的尺寸。有一个细节,在对 Region 进行变换的时候,首先对这些区域进行膨胀处理,在其 box 周围附加了 p 个像素,也就是人为添加了边框,在这里 p=16。 -
分类器
对象分类器(特定的一组SVM分类器),有多少个类别,就需要训练多少个SVM分类器,每个分类器判断输入是不是对应的类别。
3.4 R-CNN网络架构
R-CNN使用的网络是AlexNet,预训练数据集是ILSVRC2013。
因为 AlexNet 的出现,世人的目光重回神经网络领域,以此为契机,不断涌出各种各样的网络比如 VGG、GoogleNet、ResNet 等等。受 AlexNet 启发,论文作者尝试将 AlexNet 在 ImageNet 目标识别的能力泛化到 PASCAL VOC 目标检测上面来。

AlexNet网络的具体详解,请见我的博客:
深度学习经典网络解析(二):AlexNet
3.5 Selective Search与R-CNN
传统目标检测方法中的区域选择过程用的是穷举法的思路而不是生成候选区域方法,每滑一个窗口检测一次,相邻窗口信息重叠高,检测速度慢,这导致出现非常多的无效区域的判断,一张普通大小的图像可以轻易提出超过1万的候选区域。那有没有办法减小候选区域的数量呢?
J. R. R. Uijlings在2012年提出了selective search方法,这种方法其实是利用了经典的图像分割方法Graphcut,首先对图像做初始分割,然后通过分层分组方法对分割的结果做筛选和归并,最终输出所有可能位置,将候选区域缩小到2000个左右。

具体来说,首先通过将图像进行过分割得到若干等区域组成区域的集合S,这是一个初始化的集合;
然后利用颜色、纹理、尺寸和空间交叠等特征,计算区域集里每个相邻区域的相似度; 找出相似度最高的两个区域,将其合并为新集并从区域集合中删除原来的两个子集。重复以上的迭代过程,直到最开始的集合S为空,得到了图像的分割结果,得到候选的区域边界,也就是初始框。
在R-CNN框架中使用Selective search将候选区域控制在了2000个左右,然后将对应的框进行缩放操作,送入CNN中进行训练,通过SVM和回归器确定物体的类别并对其进行定位。由于CNN具有非常强大的非线性表征能力,可以对每一个区域进行很好的特征学习,所以性能大大提升。
R-CNN的主要特点有以下三点:
利用了selective search方法,即先通过实例分割将图像分割为若干小块,然后选择相似度较高的小块,把这些相似小块合并为一个大块,最后整个物体生成一个大的矩形框,通过这种方法大大提高候选区域的筛选速度。
用在ImageNet数据集上进行学习的参数对神经网络进行预处理,解决了在目标检测训练过程中标注数据不足的问题。(也就是迁移学习)
通过线性回归模型对边框进行校准,减少图像中的背景空白,得到更精确的定位。
该方法将PASCAL VOC上的检测率从35.1%提升到了53.7%,其意义与AlexNet在2012年取得分类任务的大突破是相当的,对目标检测领域影响深远。不过,selective search方案仍然有计算量过大的问题。
3.6 IoU 交并比
目标检测当中,有一个常用的指标,叫IoU(Intersection over Union), 它常常用来衡量目标检测任务中,预测结果的位置信息的准确程度。
在目标检测的课题里,我们需要从给定的图片里,推测出这张图片里有哪样(或者是哪几样)东西,并且推测这样(或者这几样)东西在图片中的具体位置。比如,在下面这张图片里,我们推测出图片当中有个STOP标识,并且给出了它的推测位置(红色的方框)。
但是,图片中绿色的方框才是STOP标识真正的位置。两个方框所在的位置存在着一定的偏差。那么,我们应该怎么来衡量这个偏差的大小呢?

我们通常使用IoU(Intersection over Union)这个指标来衡量上面提到的偏差的大小。
IoU的计算原理很简单:

用数学中集合的语言来说,也就是两个区域的“交集”, 除以两个区域的“并集”↓
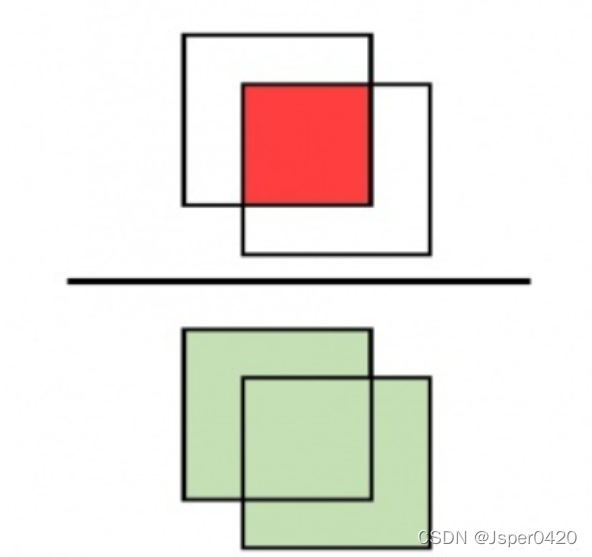
IoU的最大值为1,此时物体的实际区域与推测区域完全重合;IoU的最小值为0,此时物体的实际区域与推测区域完全没有重叠的部分。
IoU实际上是一个比较严格的评价指标。实际区域与推测区域稍微有些偏离,得出来的IoU的值也可能会变得相当小。
3.7 非极大值抑制NMS
先前说道,selective research会产生2k个region proposals。经过svm打分后,一个物体可能就有多个框。如下图:
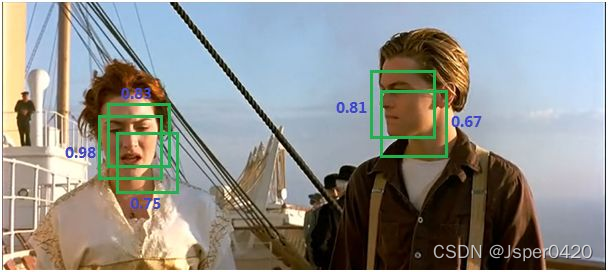
但是我们需要一个物体只有一个最优框(相对同一物体的所有的框,即SVMs打分后得到的矩阵的一个列向量中挑选最优的)。于是使用NMS来抑制冗余的框,得到如下图的结果:

举一个例子:某个物体最终得到了A,B,C,D,E,F六个框,按照SVMs打分从高到低刚好也是A,B,C,D,E,F。挑选出得分最高的A,然后遍历剩下的(候选集),依次计算相对于A的IOU,如果IOU>阈值,则抛弃对应的框(例如:IOU(A,B)>阈值,则抛弃B),否则放回候选集。遍历完后,如果候选集还有元素且元素个数大于1,继续挑选出候选集中得分最高的(例如上一轮只抛弃了B,候选集中是C,D,E,F,那么现在得分最高的的是C),然后遍历候选集,再依次计算(同上),知道候选集中没有元素,或者只剩一个元素。那么留下的就是最优的框。
也就是说还是会有多个框,我的理解是IOU>阈值就抛弃,杜绝了在同一个区域内重复出现多个框,但是一幅图中可能有多个同类型的目标,例如上图就有两张脸,剩下的多个框一定程度上是标注的多个目标
3.8 修正候选区域:BBox Regression
去掉了冗余的box还不够,因为这些box都是算法生成的,与ground truth肯定存在出入,我们希望这些box能尽可能接近ground truth。例如下图

黄色是算法生成的region proposal,绿色是ground truth,我们需要让微调黄色的框,让其接近绿色的框。于是使用了一组BBox Repression(每个分别对应一个类别)来做这个事情,输入原本的框,预测出一个新的框来接近ground truth。因为一个框可以用四个值来表示(x,y,w,h)分别是框的中心点横坐标,中心点纵坐标,宽,高。

我们想将红色框转为蓝色框(接近与ground truth,留坑:为什么不直接转为绿色框)。转换方式如下:
G x ′ = A w ⋅ d x ( A ) + A x G y ′ = A h ⋅ d y ( A ) + A y \begin{aligned} &G_{x}^{\prime}=A_{w} \cdot d_{x}(A)+A_{x} \\ &G_{y}^{\prime}=A_{h} \cdot d_{y}(A)+A_{y} \end{aligned} Gx′=Aw⋅dx(A)+AxGy′=Ah⋅dy(A)+Ay
G w ′ = A w ⋅ exp ( d w ( A ) ) G h ′ = A h ⋅ exp ( d h ( A ) ) \begin{aligned} G_{w}^{\prime} &=A_{w} \cdot \exp \left(d_{w}(A)\right) \\ G_{h}^{\prime} &=A_{h} \cdot \exp \left(d_{h}(A)\right) \end{aligned} Gw′Gh′=Aw⋅exp(dw(A))=Ah⋅exp(dh(A))
可以看到其实就是需要学会 d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) d_{x}(A), d_{y}(A), d_{w}(A), d_{h}(A) dx(A),dy(A),dw(A),dh(A) 四个变化 (可能有点迷糊,接着往 下看吧)。我们知道红框与绿框之间真正的平移和缩放为:
t x = ( x − x a ) / w a , t y = ( y − y a ) / h a t W = log ( w / w a ) , t h = log ( h / h a ) \begin{aligned} t_{\mathrm{x}} &=\left(x-x_{\mathrm{a}}\right) / w_{\mathrm{a}}, \quad t_{\mathrm{y}}=\left(y-y_{\mathrm{a}}\right) / h_{\mathrm{a}} \\ t_{\mathrm{W}} &=\log \left(w / w_{\mathrm{a}}\right), \quad t_{\mathrm{h}}=\log \left(h / h_{\mathrm{a}}\right) \end{aligned} txtW=(x−xa)/wa,ty=(y−ya)/ha=log(w/wa),th=log(h/ha)
将 t ∗ ( ∗ ⊂ x , y , w , h ) t_{*}(* \subset x, y, w, h) t∗(∗⊂x,y,w,h) 带入上面的四个公式,替换掉 d ∗ ( A ) d_{*}(A) d∗(A),是不是就能理解上面的四个变化 了。现在我们想让 d ∗ d_{*} d∗ 尽可能接近 t ∗ t_{*} t∗ 。同时在region proposal与GT相差较小时, d ∗ d_{*} d∗ 可以视 为一种线性变化:
d ∗ ( A ) = w ∗ T ⋅ Φ ( A ) d_{*}(A)=w_{*}^{T} \cdot \Phi(A) d∗(A)=w∗T⋅Φ(A)
其中 ϕ ( A ) \phi(A) ϕ(A) 就是region proposal在feature map中对应的特征值。
怎么去衡量 t ∗ t_{*} t∗ 和 d ∗ d_{*} d∗ 之间的差距呢,也就是定义Loss函数:
Loss = ∑ i N ( t ∗ i − w ^ ∗ T ⋅ Φ ( A i ) ) 2 \operatorname{Loss}=\sum_{i}^{N}\left(t_{*}^{i}-\widehat{w}_{*}^{T} \cdot \Phi\left(A^{i}\right)\right)^{2} Loss=i∑N(t∗i−w
∗T⋅Φ(Ai))2
3.9 R-CNN训练
有监督的预训练:之前说过R-CNN创新的一个地方就是采用大样本下有监督预训练+小样本微调的方式解决小样本难以训练甚至过拟合等问题。所以我们可以直接使用现有的训练好的网络,许多深度学习库中都有集成一些厉害的网络结构以及训练好的权值,直接拿来用就好了。当然也可以重新设计网络结构,然后用一个大的数据集来训练就好了。注意这个数据集里也有目标的bounding box信息,但是预训练中只用了图像的label信息,即这里训练的还是一个分类器,跟定位无关。
特定领域的微调:经过预训练,我们有了一个“超强的”分类器,AlexNet有1000个输出,即可以区分1000个类。但是这个分类器再强,目前对于我们的任务来说可能没有太大的用处。因为它没有见识过特定任务中的数据样式。所以需要使用任务中的数据集对其进行微调。其中包括参数以及结构。
根据任务,将输出层改为N+1:N个类别,多的一个是背景。原文中所谓的特定任务是PASCAL VOC,使用了PASCAL VOC 2010的数据集,其中只需要区分20个类别
样本:这里有个IOU的概念,不懂得百度一下就能知道。因为样本数据中往往一个类别只有一个Bounding box(Ground Truth,即样本中的目标位置信息),而通过Selective search算法产生的region proposals跟Ground Truth肯定有出入。现在将IOU>0.5的region proposals打上对应类别的标签,否则打上背景标签,采用one-hot编码。
参数设置:学习率设置为了预训练时学习率的1/10,说是这样不会破坏初始。然后mini-batch size=128,其中32个正样本(涵盖所有类),96个负样本。
例如现在要做一个交通标志的检测系统,而ILSVRC2013中并没有交通标志的图片,但是做的任务是相近的,网络底层提取到的特征一定程度上也是通用的,所以在原有基础上加入新的数据集,让其拥有了识别交通信号的能力。这样做最大的好处是可以在小样本上得到较好的模型。因为样本数据很少,如果模型的初值随机化,那么很大可能得不到理想的模型。
对象分类器(特定的一组SVM分类器):有多少个类别,就需要训练多少个SVM分类器,每个分类器判断输入是不是对应的类别。正样本:CNN提取的ground truth的特征向量;负样本:CNN提取的IOU<0.3的region prosoals的特征向量。(注意这里正负样本的定义要比CNN严格,且输入是CNN提取到的特征向量)因为负样本的个数远远多于正样本,一是会造成比例失衡,二是负样本太多了,会造成外存和内存的压力。所以采用了hard negative mining。注意SVM的训练是单独的,因为需要和CNN训练时不一样的样本,而且需要先训练好CNN来提取特征。
当上述的完成了,我们就得到了R-CNN模型(应该还要加上NMS步骤)。这个模型可以很好的分类region proposals,同时也就对目标做了大概的定位。但是注意region proposals太多了,而且和ground truth存在出入,所以需要使用非极大值抑制法(NMS)去掉多余的region proposals以及使用BBox Regression来修正box的位置。
4. SPP-Net(扩展)
尽管 RCNN通过减少了候选框减少了计算量,利用了CNN进行学习提升了特征表达能力,但是它仍然有两个重大缺陷。SPPnet是目标检测领域不可忽略的一篇论文,何恺明大神的作品,阅读起来感觉亲切多了。
SPPnet主要有两处亮点:
- 它解决了深度卷积神经网络(CNNs)的输入必须要求固定图像尺寸(例如224*224)的限制。
- 在目标检测领域它提高了提取特征的效率,速度相比R-CNN提升24-102倍。
4.1 R-CNN存在的问题
1.冗余计算
因为R-CNN的方法是先生成候选区域,再对区域进行卷积,其中候选区域会有一定程度的重叠,因为selective search方法仍然不够好,导致CNN对相同区域进行重复卷积提取特征。而且R-CNN方法将提取后的特征存储下来,然后使用传统的SVM分类器进行分类,导致需要很大的存储空间。
2.候选区域的尺度缩放问题
因为R-CNN方法将所有区域缩放到同一尺度进行网络训练,而实际selective search选取的目标框有各种尺寸,这可能导致目标的变形,无论是剪裁还是缩放都不能解决这个问题。
4.2 SPP-Net创新点
4.2.1 让网络的输入图片可以是任意尺寸
SPP-Net主要对第二个缺陷进行改进,其主要思想是去掉了原始图像上的crop/warp等操作,换成了在卷积特征上的空间金字塔池化层(Spatial Pyramid Pooling,SPP)之所以要对图像进行缩放到固定的尺度,是因为全连接层的存在。全连接层的输入需要固定的大小,所以要使用不同大小的图片,就必须在输入全连接层之前进行统一变换。但是直接进行裁剪或缩放会使图片信息发生丢失,有时候会因为候选框太小的原因导致只能获得部分目标,使输入神经网络的信息不完整,如下图。

图像裁剪之后再进行缩放操作又会导致物体变形失真,同样影响检测效果。

深度卷积神经网络的基础结构分为:卷积层(conv layers)->池化层(pooling layers)->全连接层(fc layers)。我们在设计网络的时候,全连接层的输入维数必须提前固定。从全连接层往前推的话,就必须保持第一层卷积的输入尺寸是固定的,例如224 * 224(ImageNet)、32 * 32(LenNet)等。这也就要求我们在检测图片时,需要将图片经过crop(裁剪)、warp(拉伸)等操作把图片变换成固定尺寸,才能输入神经网络。这些操作在一定程度上会导致图片信息的丢失或者变形。对此SPPnet提出的解决方案是在最后一层卷积层后用空间金字塔池化层(Spatial Pyramid Pooling)代替普通池化层。
SPP提出可以通过一个特殊的池化层,Spatial Pyramid Pooling层来解决,它实现了将输入的任意尺度的特征图组合成了特定维度的输出,从而去掉了原始图像上的crop/warp等操作的约束。

Spatial Pyramid Pooling把卷积操作之后的特征图(feature maps),以不同大小的块(池化框)来提取特征,分别是4 * 4,2 * 2,1 * 1,将这三张网格放到下面这张特征图上,就可以得到16+4+1=21种不同的块(Spatial Bins),我们从这21个块中,每个块提取出一个特征(提取方式有平均池化、最大池化等),这样就得到了固定的21维特征向量。以不同的大小格子的组合方式来池化的过程就是空间金字塔池化。这么一来,我们只要设计m个n * n大小的网格就可以生成任意维数的特征向量,而不需要在意经过多层卷积操作后的特征图的大小是多少,这也意味着我们不需要在意网络输入的图片尺寸。
Spatial Pyramid Pooling是在卷积特征上的空间金字塔池化层,不管输入的图像是多大,假设最终的单个通道的featuramap尺度为N*N。**利用max pooling操作将其分成1x1,2x2,4x4的3张子图,从而原来任意的N*N的featuremap,都被表示成为21维的固定维度的向量**,然后输入全连接层。在实际进行检测任务的时候,就可以根据任务本身来设计这个spp操作。这样就解决了不同输入大小图的问题,避免了缩放变形等操作。

4.2.2 改进特征计算时的低效
利用R-CNN进行目标检测,虽然在VOC和ImageNet上都表现了出色的检测精度,但是R-CNN提取特征的计算非常耗时,主要因为在对每张图片中的多达2000个的候选区域的像素反复调用CNN进行提取特征。其中的候选区域存在大量重叠的部分,这种设计明显造成了大量的计算浪费。
SPPnet的做法是首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。然后把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中通过映射关系找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后再进入CNN,因为SPP-Net只需要一次对整张图片进行特征提取,速度会大大提升。
而问题的关键在于特征图(feature maps)的大小是根据图片的大小与卷积层的卷积核大小(kernel size)与步长(stride)决定的,如何在特征图上找到原图上对应的候选区域,即两者之间的映射关系是怎么样的。
论文中给出一个公式:
假设 ( x ′ , y ′ ) \left(x^{\prime}, y^{\prime}\right) (x′,y′) 表示特征图上的坐标点,坐标点 ( x , y ) (x, y) (x,y) 表示原输入图片上的点,那么它们之间有如下转 换关系,这种映射关心与网络结构有关: ( x , y ) = ( S x ′ , S y ′ ) (x, y)=\left(S x^{\prime}, S y^{\prime}\right) (x,y)=(Sx′,Sy′)
反过来,我们希望通过 ( x , y ) (x, y) (x,y) 坐标求解 ( x ′ , y ′ ) \left(x^{\prime}, y^{\prime}\right) (x′,y′) ,那么计算公式如下:
Left、Top: x ′ = ⌊ x / S ⌋ + 1 x^{\prime}=\lfloor x / S\rfloor+1 x′=⌊x/S⌋+1
Right,Bottom : x ′ = ⌈ x / S ] i a n − 1 x^{\prime}=\lceil x / S]^{i a n}-1 x′=⌈x/S]ian−1.
S就是CNN中所有的strides的乘积,包含了池化、卷积的stride
4.3 SPP-Net一些问题
继承了R-CNN的问题
① 需要存储大量特征
② 复杂的多阶段训练
③ 训练时间长
5. 总结
首先回顾一下R-CNN处理流程:
- 输入一张多目标图像,采用selective search算法提取约2000个region proposals;
- 先在每个region proposal周围加上16个像素值(为proposal region的平均值,倾向于这个)的边框,再直接变形为227×227的大小(AlexNet的输入大小);
- 先将所有warped region proposals减去自身平均值后,再依次将每个227×227的warped region proposal输入AlexNet CNN网络获取4096维的特征,2000个region proposals的CNN特征组合成2000×4096维矩阵;
- 将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘,获得2000×20维矩阵表示每个region proposal是某个物体类别的得分;
- 分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠region proposals,得到该列即该类中得分最高的一些region proposals;
- 分别用20个回归器对上述20个类别中剩余的region proposals进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。
R-CNN技术要点:
- R-CNN 采用 AlexNet
- R-CNN 采用 Selective Search 技术生成 Region Proposal.
- R-CNN 在 ImageNet 上先进行预训练,然后利用成熟的权重参数在 PASCAL VOC 数据集上进行 fine-tune
- R-CNN 用 CNN 抽取特征,然后用一系列的的 SVM 做类别预测。
- R-CNN 的 bbox 位置回归基于 DPM 的灵感,自己训练了一个线性回归模型。
R-CNN缺点:
- 需要存储大量特征
- 复杂的多阶段训练
- 训练时间长
版权声明
本文为[Jsper0420]所创,转载请带上原文链接,感谢
https://blog.csdn.net/muye_IT/article/details/124309145
边栏推荐
- C language input and output (printf and scanf functions, putchar and getchar functions)
- Climbing watermelon video URL
- word frequency count
- Scikit learn sklearn 0.18 official document Chinese version
- Stanford machine learning course summary
- Logic regression principle and code implementation
- MySQL auto start settings start with systemctl start mysqld
- 读取excel,int 数字时间转时间
- What are the relationships and differences between threads and processes
- Use of list - addition, deletion, modification and query
猜你喜欢

Remember using Ali Font Icon Library for the first time

2022 Jiangxi Photovoltaic Exhibition, China Distributed Photovoltaic Exhibition, Nanchang Solar Energy Utilization Exhibition

Installation du docker redis
2022江西光伏展,中国分布式光伏展会,南昌太阳能利用展

C medium? This form of

Qt读写XML文件(含源码+注释)

idea中安装YapiUpload 插件将api接口上传到yapi文档上
QTableWidget使用讲解
Batch export ArcGIS attribute table
Re regular expression
随机推荐
C byte array (byte []) and string are converted to each other
String function in MySQL
Box pointer of rust
纳米技术+AI赋能蛋白质组学|珞米生命科技完成近千万美元融资
Welcome to the markdown editor
Eigen learning summary
Implementation of object detection case based on SSD
Multi thread crawling Marco Polo network supplier data
Installation du docker redis
Re expression régulière
Visualization of residential house prices
Array rotation
Go's gin framework learning
Build openstack platform
C1 notes [task training part 2]
Crawl the product data of Xiaomi Youpin app
C1 notes [task training chapter I]
MySQL_01_简单数据检索
Timestamp to formatted date
2022江西储能技术展会,中国电池展,动力电池展,燃料电池展