当前位置:网站首页>CV+Deep Learning - network architecture Pytorch recurrence series - classification (3: MobileNet, ShuffleNet)
CV+Deep Learning - network architecture Pytorch recurrence series - classification (3: MobileNet, ShuffleNet)
2022-08-10 07:42:00 【Tourist 26024】
上一话
 https://blog.csdn.net/XiaoyYidiaodiao/article/details/125692368?spm=1001.2014.3001.5501
https://blog.csdn.net/XiaoyYidiaodiao/article/details/125692368?spm=1001.2014.3001.5501因为没人看,I want to quit...
Introduction This series focuses on recurrence计算机视觉(分类、目标检测、语义分割)中深度学习各个经典的网络模型,以便初学者使用(浅入深出)!
代码都运行无误!!
First, the classic classification network module of deep learning is reproduced,It is specialized in target detectionBackbone(10.,11.)But its main purpose is to extract features so it is also put here,有:
1.LeNet5(√,一)
2.VGG(√,一)
3.AlexNet(√,一)
4.ResNet(√,一)
5.ResNeXt(√,二)
6.GoogLeNet(√,二)
7.MobileNet(√)
8.ShuffleNet(√)
9.EfficientNet(√)
10.VovNet
11.DarkNet
...
代码:
7.MobileNet
7.3 MoblieNet v3[9]
首先,Reproduce to Inverted Residual Module,如图 1. .
1x1 conv 升维
3x3 conv DepthWise
(SE 通道注意机制)
1x1 conv 降维
its first floorconv结构为ConvBNAvtivation.
class ConvBNActivation(nn.Sequential):
def __init__(self, norm_layer, activation_layer, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.ReLU6
super(ConvBNActivation, self).__init__(
nn.Conv2d(in_channels=in_planes, out_channels=out_planes,
kernel_size=kernel_size, stride=stride, padding=padding,
groups=groups, bias=False),
norm_layer(out_planes),
activation_layer())SE通道注意力机制(adv_avg_pool->fc(channles/4)->relu->fc->hardsigmoid)
class SqueezeExcitation(nn.Module):
def __init__(self, input_c, squeeze_factor=4):
super(SqueezeExcitation, self).__init__()
squeeze_c = _make_divisible(input_c // squeeze_factor, 8)
self.fc1 = nn.Conv2d(in_channels=input_c, out_channels=squeeze_c, kernel_size=1)
self.fc2 = nn.Conv2d(in_channels=squeeze_c, out_channels=input_c, kernel_size=1)
@autocast()
def forward(self, x):
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = F.relu(scale)
scale = self.fc2(scale)
scale = F.hardsigmoid(scale)
return scale * xConfiguration file for the Inverted Residuals module
class InvertedResidualConfig:
def __init__(self, input_c, kernel, expanded_c, out_c, use_se, activation, stride, width_multi):
self.input_c = self.adjust_channels(input_c, width_multi)
self.kernel = kernel
self.expanded_c = self.adjust_channels(expanded_c, width_multi)
self.out_c = self.adjust_channels(out_c, width_multi)
self.use_se = use_se
# whether using h-swish activation
self.use_hs = activation == 'HS'
self.stride = stride
@staticmethod
def adjust_channels(channels, width_multi):
return _make_divisible(channels * width_multi, 8)倒残差模块
class InvertedResidual(nn.Module):
def __init__(self, cnf, norm_layer):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)
layers = []
activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU
# expand
if cnf.expanded_c != cnf.input_c:
layers.append(
ConvBNActivation(norm_layer=norm_layer, activation_layer=activation_layer,
in_planes=cnf.input_c, out_planes=cnf.expanded_c, kernel_size=1))
# depthwise
layers.append(
ConvBNActivation(norm_layer=norm_layer, activation_layer=activation_layer,
in_planes=cnf.expanded_c, out_planes=cnf.expanded_c,
kernel_size=cnf.kernel, stride=cnf.stride,
groups=cnf.expanded_c))
if cnf.use_se:
layers.append(SqueezeExcitation(cnf.expanded_c))
# project
layers.append(
ConvBNActivation(norm_layer=norm_layer, activation_layer=nn.Identity,
in_planes=cnf.expanded_c, out_planes=cnf.out_c,
kernel_size=1))
self.block = nn.Sequential(*layers)
self.out_channels = cnf.out_c
self.is_strided = cnf.stride > 1
def forward(self, x):
result = self.block(x)
if self.use_res_connect:
result += x
return result复现MobileNet v3
class mobilenet_v3(nn.Module):
def __init__(self,
inverted_residual_setting,
last_channels, block, norm_layer, num_classes=1000, init_weights=False):
super(mobilenet_v3, self).__init__()
if not inverted_residual_setting:
raise ValueError("The inverted_residual_setting should not be empty.")
elif not (isinstance(inverted_residual_setting, List) and
all([isinstance(s, InvertedResidualConfig) for s in inverted_residual_setting])):
raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d, eps=0.001, momentum=0.01)
layers = []
# building first layer
firstconv_output_c = inverted_residual_setting[0].input_c
layers.append(
ConvBNActivation(norm_layer=norm_layer, activation_layer=nn.Hardswish,
in_planes=3, out_planes=firstconv_output_c,
kernel_size=3, stride=2))
# building inverted residual blocks
for cnf in inverted_residual_setting:
layers.append(block(cnf, norm_layer))
# building last several layers
lastconv_input_c = inverted_residual_setting[-1].out_c
lastconv_output_c = 6 * lastconv_input_c
layers.append(
ConvBNActivation(norm_layer=norm_layer, activation_layer=nn.Hardswish,
in_planes=lastconv_input_c, out_planes=lastconv_output_c,
kernel_size=1))
self.features = nn.Sequential(*layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.classifier = nn.Sequential(
nn.Linear(lastconv_output_c, last_channels),
nn.Hardswish(),
nn.Dropout(0.2),
nn.Linear(last_channels, num_classes))
self.init_weights = init_weights
if self.init_weights:
self._initialize_weights()
def _initialize_weights(self):
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x复现MobileNet v3 Large

def mobilenet_v3_large(reduced_tail=False, num_classes=1000, pretrained=False, init_weights=False):
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, False, 'RE', 1),
bneck_conf(16, 3, 64, 24, False, 'RE', 2),
bneck_conf(24, 3, 72, 24, False, 'RE', 1),
bneck_conf(24, 5, 72, 40, True, 'RE', 2),
bneck_conf(40, 5, 120, 40, True, 'RE', 1),
bneck_conf(40, 5, 120, 40, True, 'RE', 1),
bneck_conf(40, 3, 240, 80, False, 'HS', 2),
bneck_conf(80, 3, 200, 80, False, 'HS', 1),
bneck_conf(80, 3, 184, 80, False, 'HS', 1),
bneck_conf(80, 3, 184, 80, False, 'HS', 1),
bneck_conf(80, 3, 480, 112, True, 'HS', 1),
bneck_conf(112, 3, 672, 112, True, 'HS', 1),
bneck_conf(112, 5, 672, 160 // reduce_divider, True, 'HS', 2),
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, 'HS', 1),
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, 'HS', 1),
]
last_channels = adjust_channels(1280 // reduce_divider)
model = mobilenet_v3(inverted_residual_setting=inverted_residual_setting, last_channels=last_channels,
block=None, norm_layer=None, num_classes=num_classes, init_weights=init_weights)
if pretrained:
# if you want to use cpu, you should modify map_loaction=torch.device("cpu")
pretrained_models = torch.load(models_urls['mobilenet_v3_large'], map_location=torch.device("cuda:0"))
# transfer learning
del pretrained_models['features.1.block.0.0.weight']
model.load_state_dict(pretrained_models, strict=False)
return model复现MobileNet v3 Small

def mobilenet_v3_small(reduced_tail=False, num_classes=1000, pretrained=False, init_weights=False):
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, True, 'RE', 2),
bneck_conf(16, 3, 72, 24, False, 'RE', 2),
bneck_conf(24, 3, 88, 24, False, 'RE', 1),
bneck_conf(24, 5, 96, 40, True, 'HS', 2),
bneck_conf(40, 5, 240, 40, True, 'HS', 1),
bneck_conf(40, 5, 240, 40, True, 'HS', 1),
bneck_conf(40, 5, 120, 48, True, 'HS', 1),
bneck_conf(48, 5, 144, 48, True, 'HS', 1),
bneck_conf(48, 5, 288, 96 // reduce_divider, True, 'HS', 2),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, 'HS', 1),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, 'HS', 1),
]
last_channels = adjust_channels(1024 // reduce_divider)
model = mobilenet_v3(inverted_residual_setting=inverted_residual_setting, last_channels=last_channels,
block=None, norm_layer=None, num_classes=num_classes, init_weights=init_weights)
if pretrained:
# if you want to use cpu, you should modify map_loaction=torch.device("cpu")
pretrained_models = torch.load(models_urls['mobilenet_v3_small'], map_location=torch.device("cuda:0"))
model.load_state_dict(pretrained_models, strict=False)
return model完整代码
import torch
import torch.nn as nn
from functools import partial
from typing import List
from utils.path import CheckPoints
from torch.cuda.amp import autocast
from torch.nn import functional as F
__all__ = ['mobilenet_v3_large', 'mobilenet_v3_small']
models_urls = {
# 'mobilenet_v3_small' : 'https://download.pytorch.org/models/mobilenet_v3_small-047dcff4.pth'
'mobilenet_v3_small': '{}/mobilenet_v3_small-047dcff4.pth'.format(CheckPoints),
# 'mobilenet_v3_large' : 'https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth'
'mobilenet_v3_large': '{}/mobilenet_v3_large-8738ca79.pth'.format(CheckPoints)
}
def MobileNet_v3(pretrained=False, num_classes=1000, init_weights=False, type='small'):
if type == 'small':
return mobilenet_v3_small(pretrained=pretrained, num_classes=num_classes, init_weights=init_weights)
elif type == 'large':
return mobilenet_v3_large(pretrained=pretrained, num_classes=num_classes, init_weights=init_weights)
else:
raise ValueError("Unsupported MobileNet V3 Type!")
def _make_divisible(ch, divisor=8, min_ch=None):
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class ConvBNActivation(nn.Sequential):
def __init__(self, norm_layer, activation_layer, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.ReLU6
super(ConvBNActivation, self).__init__(
nn.Conv2d(in_channels=in_planes, out_channels=out_planes,
kernel_size=kernel_size, stride=stride, padding=padding,
groups=groups, bias=False),
norm_layer(out_planes),
activation_layer())
class SqueezeExcitation(nn.Module):
def __init__(self, input_c, squeeze_factor=4):
super(SqueezeExcitation, self).__init__()
squeeze_c = _make_divisible(input_c // squeeze_factor, 8)
self.fc1 = nn.Conv2d(in_channels=input_c, out_channels=squeeze_c, kernel_size=1)
self.fc2 = nn.Conv2d(in_channels=squeeze_c, out_channels=input_c, kernel_size=1)
@autocast()
def forward(self, x):
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = F.relu(scale)
scale = self.fc2(scale)
scale = F.hardsigmoid(scale)
return scale * x
class InvertedResidualConfig:
def __init__(self, input_c, kernel, expanded_c, out_c, use_se, activation, stride, width_multi):
self.input_c = self.adjust_channels(input_c, width_multi)
self.kernel = kernel
self.expanded_c = self.adjust_channels(expanded_c, width_multi)
self.out_c = self.adjust_channels(out_c, width_multi)
self.use_se = use_se
# whether using h-swish activation
self.use_hs = activation == 'HS'
self.stride = stride
@staticmethod
def adjust_channels(channels, width_multi):
return _make_divisible(channels * width_multi, 8)
class InvertedResidual(nn.Module):
def __init__(self, cnf, norm_layer):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)
layers = []
activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU
# expand
if cnf.expanded_c != cnf.input_c:
layers.append(
ConvBNActivation(norm_layer=norm_layer, activation_layer=activation_layer,
in_planes=cnf.input_c, out_planes=cnf.expanded_c, kernel_size=1))
# depthwise
layers.append(
ConvBNActivation(norm_layer=norm_layer, activation_layer=activation_layer,
in_planes=cnf.expanded_c, out_planes=cnf.expanded_c,
kernel_size=cnf.kernel, stride=cnf.stride,
groups=cnf.expanded_c))
if cnf.use_se:
layers.append(SqueezeExcitation(cnf.expanded_c))
# project
layers.append(
ConvBNActivation(norm_layer=norm_layer, activation_layer=nn.Identity,
in_planes=cnf.expanded_c, out_planes=cnf.out_c,
kernel_size=1))
self.block = nn.Sequential(*layers)
self.out_channels = cnf.out_c
self.is_strided = cnf.stride > 1
def forward(self, x):
result = self.block(x)
if self.use_res_connect:
result += x
return result
class mobilenet_v3(nn.Module):
def __init__(self,
inverted_residual_setting,
last_channels, block, norm_layer, num_classes=1000, init_weights=False):
super(mobilenet_v3, self).__init__()
if not inverted_residual_setting:
raise ValueError("The inverted_residual_setting should not be empty.")
elif not (isinstance(inverted_residual_setting, List) and
all([isinstance(s, InvertedResidualConfig) for s in inverted_residual_setting])):
raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d, eps=0.001, momentum=0.01)
layers = []
# building first layer
firstconv_output_c = inverted_residual_setting[0].input_c
layers.append(
ConvBNActivation(norm_layer=norm_layer, activation_layer=nn.Hardswish,
in_planes=3, out_planes=firstconv_output_c,
kernel_size=3, stride=2))
# building inverted residual blocks
for cnf in inverted_residual_setting:
layers.append(block(cnf, norm_layer))
# building last several layers
lastconv_input_c = inverted_residual_setting[-1].out_c
lastconv_output_c = 6 * lastconv_input_c
layers.append(
ConvBNActivation(norm_layer=norm_layer, activation_layer=nn.Hardswish,
in_planes=lastconv_input_c, out_planes=lastconv_output_c,
kernel_size=1))
self.features = nn.Sequential(*layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.classifier = nn.Sequential(
nn.Linear(lastconv_output_c, last_channels),
nn.Hardswish(),
nn.Dropout(0.2),
nn.Linear(last_channels, num_classes))
self.init_weights = init_weights
if self.init_weights:
self._initialize_weights()
def _initialize_weights(self):
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def mobilenet_v3_large(reduced_tail=False, num_classes=1000, pretrained=False, init_weights=False):
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, False, 'RE', 1),
bneck_conf(16, 3, 64, 24, False, 'RE', 2),
bneck_conf(24, 3, 72, 24, False, 'RE', 1),
bneck_conf(24, 5, 72, 40, True, 'RE', 2),
bneck_conf(40, 5, 120, 40, True, 'RE', 1),
bneck_conf(40, 5, 120, 40, True, 'RE', 1),
bneck_conf(40, 3, 240, 80, False, 'HS', 2),
bneck_conf(80, 3, 200, 80, False, 'HS', 1),
bneck_conf(80, 3, 184, 80, False, 'HS', 1),
bneck_conf(80, 3, 184, 80, False, 'HS', 1),
bneck_conf(80, 3, 480, 112, True, 'HS', 1),
bneck_conf(112, 3, 672, 112, True, 'HS', 1),
bneck_conf(112, 5, 672, 160 // reduce_divider, True, 'HS', 2),
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, 'HS', 1),
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, 'HS', 1),
]
last_channels = adjust_channels(1280 // reduce_divider)
model = mobilenet_v3(inverted_residual_setting=inverted_residual_setting, last_channels=last_channels,
block=None, norm_layer=None, num_classes=num_classes, init_weights=init_weights)
if pretrained:
# if you want to use cpu, you should modify map_loaction=torch.device("cpu")
pretrained_models = torch.load(models_urls['mobilenet_v3_large'], map_location=torch.device("cuda:0"))
# transfer learning
del pretrained_models['features.1.block.0.0.weight']
model.load_state_dict(pretrained_models, strict=False)
return model
def mobilenet_v3_small(reduced_tail=False, num_classes=1000, pretrained=False, init_weights=False):
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, True, 'RE', 2),
bneck_conf(16, 3, 72, 24, False, 'RE', 2),
bneck_conf(24, 3, 88, 24, False, 'RE', 1),
bneck_conf(24, 5, 96, 40, True, 'HS', 2),
bneck_conf(40, 5, 240, 40, True, 'HS', 1),
bneck_conf(40, 5, 240, 40, True, 'HS', 1),
bneck_conf(40, 5, 120, 48, True, 'HS', 1),
bneck_conf(48, 5, 144, 48, True, 'HS', 1),
bneck_conf(48, 5, 288, 96 // reduce_divider, True, 'HS', 2),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, 'HS', 1),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, 'HS', 1),
]
last_channels = adjust_channels(1024 // reduce_divider)
model = mobilenet_v3(inverted_residual_setting=inverted_residual_setting, last_channels=last_channels,
block=None, norm_layer=None, num_classes=num_classes, init_weights=init_weights)
if pretrained:
# if you want to use cpu, you should modify map_loaction=torch.device("cpu")
pretrained_models = torch.load(models_urls['mobilenet_v3_small'], map_location=torch.device("cuda:0"))
model.load_state_dict(pretrained_models, strict=False)
return model8.ShuffleNet
8.1.ShuffleNet v1[10]
不复现,understand its innovation
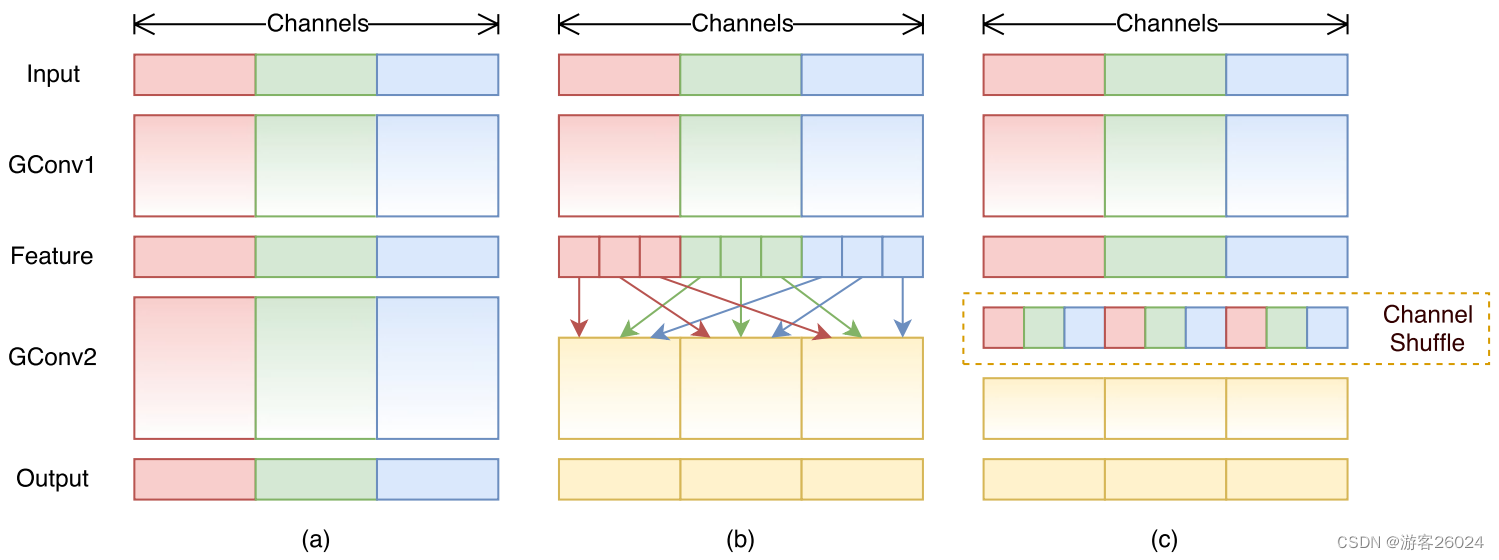
首先,Channels对于普通的GConvOperation is shown in Fig 4.(a),is for the groupChannelsDo serial stacking,And for different groups there was no information exchange before,这样效果不好
改进之后,如图 4.(b)假设我们的group采用了3组,红绿蓝;The obtained features for each group are further divided,Put the first portion of each group together,Put the second together,The third is put together as shown4.(c),这样的feature mapThe information between different groups is fused
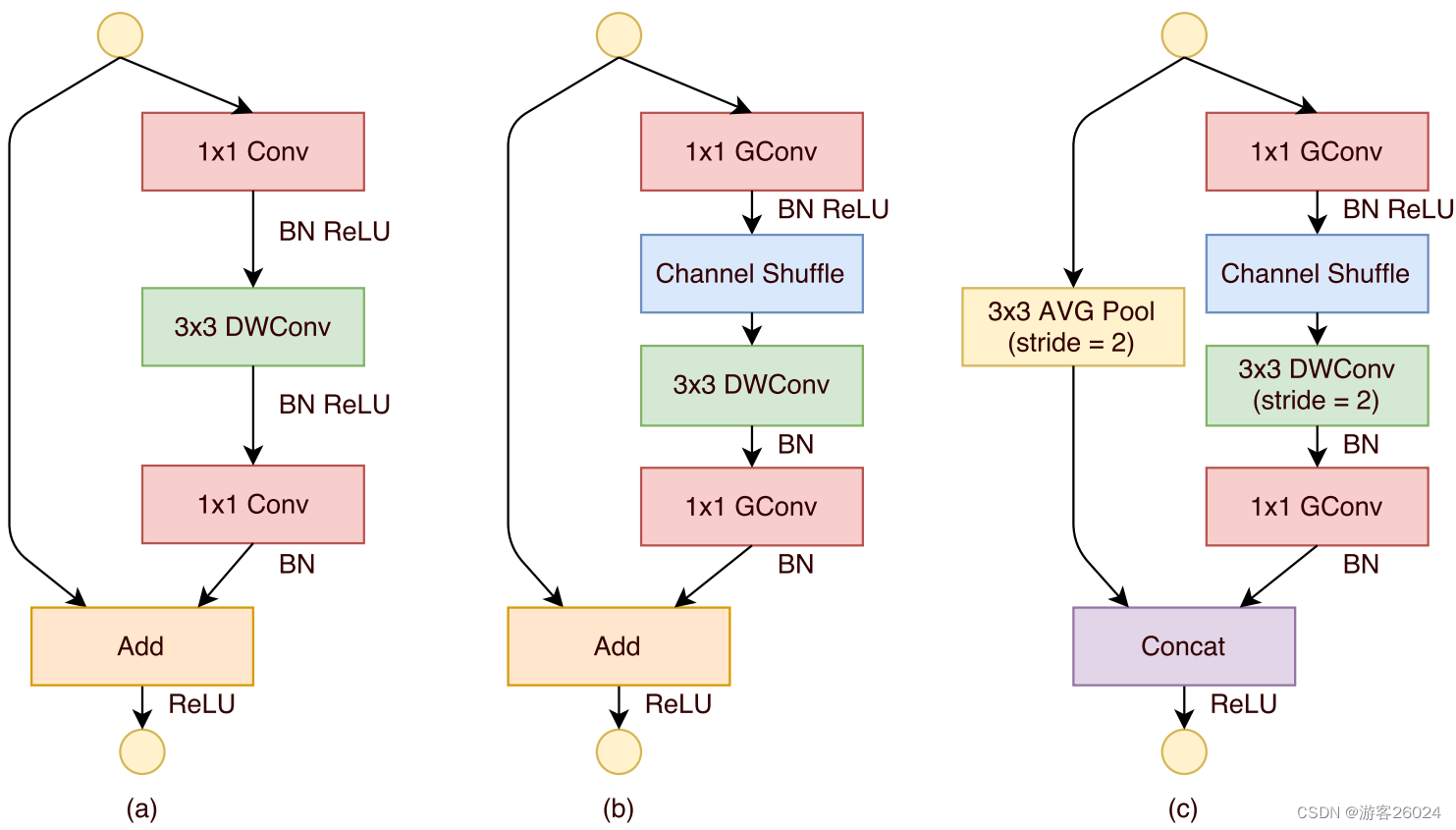
因为ResNeXt中的block的pwConv(1x1 Conv)occupies the computational cost93.4%,改进之后的block如图 5.(b),(c)1x1 Conv改为1x1GConv,其中图 5.(b)stride为1 图5.(c)stride为2
ShuffleNet v1完整版,如图 6.

8.2.ShuffleNet v2[11]
FLOPs:注意s小写,Expressed as can be used to measure 算法 或者 模型 的 复杂度
但是,The complexity of computing deep learning networks can’t just be looked atFLOP,还和memory access cost(MAC)Memory access costs, etc,ShuffleNet v2Four network architecture design criteria are proposed:(See the paper for specific proof)
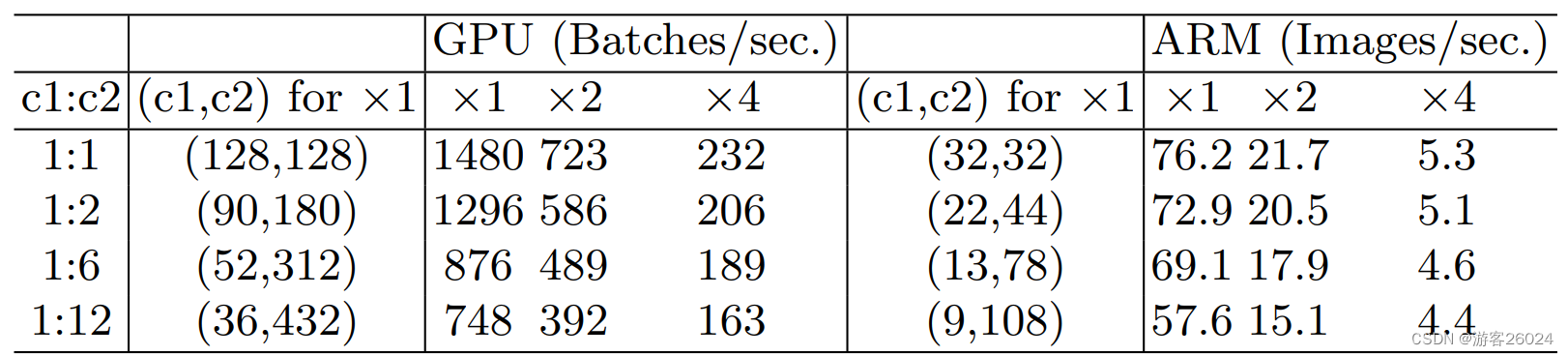
G1: Equal channel width minimizes memory access cost (MAC)当 The input feature matrix and output feature matrix of the convolutional layerchannels相等 时 且 FLOPs保持不变,Intra-visit costs are minimal. 如图 7., c1与c2的比例为1:1时,GPU和ARM的速度最快.
G2: Excessive group convolution increases MAC当GConv的组(group)增大时 且 保持FLOPs不变,The memory access cost will also increase.如图 8. ,g越小,GPU和CPUthe higher the access speed.

G3: Network fragmentation reduces degree of parallelism网络设计的碎片化程度越高,GPU与CPUthe slower the access speed.如图 9.,1-fragmentMay represent a convolutional layer with only one layer,2-fragment-seriesMay represent a series of convolutional layers with two layers,4-fragment-seriesMay represent a series of convolutional layers with four layers;2-fragment-parallelMay indicate that there are two convolutional layers in parallel,4-fragment-parallelMay indicate that there are four convolutional layers in parallel.

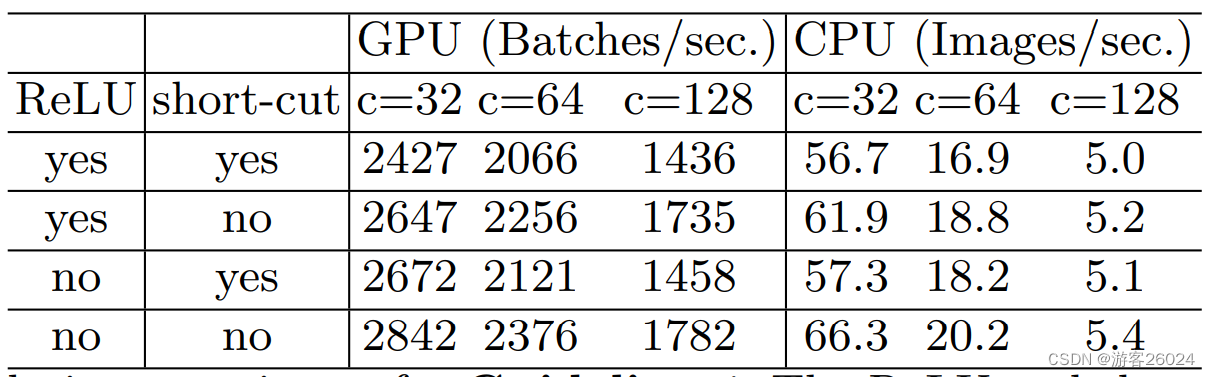
G4: Element-wise operations are non-negligibleElement-wise(ReLU,short-cut)The impact of the operation cannot be ignored.如图 10.,ReLU与short-cutUse less,GPU与CPU的访问速度越快.
According to the above four network architecture design criteria,设计出的block如图 11.(c),(d),复现如下

First reproduce the graph 11.(c)中的channel shuffle,就是将channel按照准则G1对半分
def channel_shuffle(x, groups):
batch_size, num_channels, height, width = x.shape
channels_per_group = num_channels // groups
# reshape
# [batch_size, num_channels, height, width] -> [batch_size, group, channels_per_group, height, width]
x = x.view(batch_size, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batch_size, -1, height, width)
return x复现block,按照准则G2将g设为1,G3将fragmentSet to less and less,如图11.(c),(d),以前的ReLUBoth branches are executed,按照准则G4A branch is executedReLU
class InvertedResidual(nn.Module):
def __init__(self, input_c, output_c, stride):
super(InvertedResidual, self).__init__()
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.stride = stride
assert output_c % 2 == 0
branch_features = output_c // 2
# << -> x2
assert (self.stride != 1) or (input_c == branch_features << 1)
if self.stride == 2:
self.branch1 = nn.Sequential(
self.depthwise_conv(input_c, input_c, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(input_c),
nn.Conv2d(input_c, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU()
)
else:
self.branch1 = nn.Sequential()
self.branch2 = nn.Sequential(
nn.Conv2d(input_c if self.stride > 1 else branch_features, branch_features, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(),
self.depthwise_conv(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU()
)
@staticmethod
def depthwise_conv(input_c, ouptput_c, kernel_size, stride, padding=0, bias=False):
return nn.Conv2d(in_channels=input_c, out_channels=ouptput_c, kernel_size=kernel_size,
stride=stride, padding=padding, bias=bias, groups=input_c)
@autocast()
def forward(self, x):
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out复现shufflenet v2,如图 12.

class ShuffleNetV2(nn.Module):
def __init__(self, stages_repeats, stages_out_channels, inverted_residual=InvertedResidual, num_classes=1000):
super(ShuffleNetV2, self).__init__()
if len(stages_repeats) != 3:
raise ValueError("expected stages_repeats as list of 3 positive ints")
if len(stages_out_channels) != 5:
raise ValueError("expected stages_out_channels as list of 5 positive ints")
self._stage_out_channels = stages_out_channels
# input RGB image
input_channels = 3
output_channels = self._stage_out_channels[0]
self.conv1 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU()
)
input_channels = output_channels
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# Static annotations
self.stage2: nn.Sequential
self.stage3: nn.Sequential
self.stage4: nn.Sequential
stage_names = ["stage{}".format(i) for i in [2, 3, 4]]
for name, repeats, output_channels in zip(stage_names, stages_repeats, self._stage_out_channels[1:]):
seq = [inverted_residual(input_channels, output_channels, 2)]
for i in range(repeats - 1):
seq.append(inverted_residual(output_channels, output_channels, 1))
setattr(self, name, nn.Sequential(*seq))
input_channels = output_channels
output_channels = self._stage_out_channels[-1]
self.conv5 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU()
)
self.fc = nn.Linear(output_channels, num_classes)
@autocast()
def forward(self, x):
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
x = x.mean([2, 3])
x = self.fc(x)
return x
def shufflenet_v2_x0_5(num_classes=1000, pretrained=False):
return shufflenet_v2_x('0_5', stages_repeats=[4, 8, 4], stages_out_channels=[24, 48, 96, 192, 1024],
num_classes=num_classes, pretrained=pretrained)
def shufflenet_v2_x1_0(num_classes=1000, pretrianed=False):
return shufflenet_v2_x('1_0', stages_repeats=[4, 8, 4], stages_out_channels=[24, 116, 232, 464, 1024],
num_classes=num_classes, pretrianed=pretrianed)
def shufflenet_v2_x1_5(num_classes=1000, pretrained=False):
return shufflenet_v2_x('1_5', stages_repeats=[4, 8, 4], stages_out_channels=[24, 176, 352, 704, 1024],
num_classes=num_classes, pretrained=pretrained)
def shufflenet_v2_x2_0(num_classes=1000, pretrained=False):
return shufflenet_v2_x('2_0', stages_repeats=[4, 8, 4], stages_out_channels=[24, 244, 488, 976, 2048],
num_classes=num_classes, pretrained=pretrained)完整代码
import torch
from torch import nn
from utils.path import CheckPoints
from torch.cuda.amp import autocast
__all__ = [
'shufflenet_v2_x0_5',
'shufflenet_v2_x1_0',
'shufflenet_v2_x1_5',
'shufflenet_v2_x2_0',
]
model_urls = {
# 'shufflenet_v2_x0_5': 'https://download.pytorch.org/models/shufflenetv2_x0.5-f707e7126e.pth',
'shufflenet_v2_x0_5': '{}/shufflenetv2_x0.5-f707e7126e.pth'.format(CheckPoints),
# 'shufflenet_v2_x1_0': 'https://download.pytorch.org/models/shufflenetv2_x1-5666bf0f80.pth',
'shufflenet_v2_x1_0': '{}/shufflenetv2_x1-5666bf0f80.pth'.format(CheckPoints),
# 'shufflenet_v2_x1_5': 'https://download.pytorch.org/models/shufflenetv2_x1_5-3c479a10.pth',
'shufflenet_v2_x1_5': '{}/shufflenetv2_x1_5-3c479a10.pth'.format(CheckPoints),
# 'shufflenet_v2_x2_0': 'https://download.pytorch.org/models/shufflenetv2_x2_0-8be3c8ee.pth',
'shufflenet_v2_x2_0': '{}/shufflenetv2_x2_0-8be3c8ee.pth'.format(CheckPoints),
}
def shufflenet_v2_x(arch, stages_repeats, stages_out_channels, num_classes, pretrained, **kwargs):
model = ShuffleNetV2(stages_repeats, stages_out_channels, num_classes=num_classes, **kwargs)
if pretrained:
pretrained_models = torch.load(model_urls['shufflenet_v2_x' + arch], map_location=torch.device("cuda:0"))
model.load_state_dict(pretrained_models, strict=False)
return model
def channel_shuffle(x, groups):
batch_size, num_channels, height, width = x.shape
channels_per_group = num_channels // groups
# reshape
# [batch_size, num_channels, height, width] -> [batch_size, group, channels_per_group, height, width]
x = x.view(batch_size, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batch_size, -1, height, width)
return x
class InvertedResidual(nn.Module):
def __init__(self, input_c, output_c, stride):
super(InvertedResidual, self).__init__()
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.stride = stride
assert output_c % 2 == 0
branch_features = output_c // 2
# << -> x2
assert (self.stride != 1) or (input_c == branch_features << 1)
if self.stride == 2:
self.branch1 = nn.Sequential(
self.depthwise_conv(input_c, input_c, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(input_c),
nn.Conv2d(input_c, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU()
)
else:
self.branch1 = nn.Sequential()
self.branch2 = nn.Sequential(
nn.Conv2d(input_c if self.stride > 1 else branch_features, branch_features, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(),
self.depthwise_conv(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU()
)
@staticmethod
def depthwise_conv(input_c, ouptput_c, kernel_size, stride, padding=0, bias=False):
return nn.Conv2d(in_channels=input_c, out_channels=ouptput_c, kernel_size=kernel_size,
stride=stride, padding=padding, bias=bias, groups=input_c)
@autocast()
def forward(self, x):
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
class ShuffleNetV2(nn.Module):
def __init__(self, stages_repeats, stages_out_channels, inverted_residual=InvertedResidual, num_classes=1000):
super(ShuffleNetV2, self).__init__()
if len(stages_repeats) != 3:
raise ValueError("expected stages_repeats as list of 3 positive ints")
if len(stages_out_channels) != 5:
raise ValueError("expected stages_out_channels as list of 5 positive ints")
self._stage_out_channels = stages_out_channels
# input RGB image
input_channels = 3
output_channels = self._stage_out_channels[0]
self.conv1 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU()
)
input_channels = output_channels
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# Static annotations
self.stage2: nn.Sequential
self.stage3: nn.Sequential
self.stage4: nn.Sequential
stage_names = ["stage{}".format(i) for i in [2, 3, 4]]
for name, repeats, output_channels in zip(stage_names, stages_repeats, self._stage_out_channels[1:]):
seq = [inverted_residual(input_channels, output_channels, 2)]
for i in range(repeats - 1):
seq.append(inverted_residual(output_channels, output_channels, 1))
setattr(self, name, nn.Sequential(*seq))
input_channels = output_channels
output_channels = self._stage_out_channels[-1]
self.conv5 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU()
)
self.fc = nn.Linear(output_channels, num_classes)
@autocast()
def forward(self, x):
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
x = x.mean([2, 3])
x = self.fc(x)
return x
def shufflenet_v2_x0_5(num_classes=1000, pretrained=False):
return shufflenet_v2_x('0_5', stages_repeats=[4, 8, 4], stages_out_channels=[24, 48, 96, 192, 1024],
num_classes=num_classes, pretrained=pretrained)
def shufflenet_v2_x1_0(num_classes=1000, pretrianed=False):
return shufflenet_v2_x('1_0', stages_repeats=[4, 8, 4], stages_out_channels=[24, 116, 232, 464, 1024],
num_classes=num_classes, pretrianed=pretrianed)
def shufflenet_v2_x1_5(num_classes=1000, pretrained=False):
return shufflenet_v2_x('1_5', stages_repeats=[4, 8, 4], stages_out_channels=[24, 176, 352, 704, 1024],
num_classes=num_classes, pretrained=pretrained)
def shufflenet_v2_x2_0(num_classes=1000, pretrained=False):
return shufflenet_v2_x('2_0', stages_repeats=[4, 8, 4], stages_out_channels=[24, 244, 488, 976, 2048],
num_classes=num_classes, pretrained=pretrained)9. EfficientNet
Write by chance...
运行结果
7.MobileNet v3
(1) large
basenet: MobileNet_v3_large
dataset: ImageNet
batch_size: 32
optim: SGD
lr: 0.001
momentum: 0.9
weight_decay: 1e-4
scheduler: ReduceLROnPlateau
patience: 2
epoch: 30
pretrained: True
| No.epoch | times/epoch | top1 acc (%) | top5 acc (%) |
|---|---|---|---|
| 5 | 3h58min13s | 71.15 | 90.32 |
(2) small
basenet: MobileNet_v3_small
dataset: ImageNet
batch_size: 32
optim: SGD
lr: 0.001
momentum: 0.9
weight_decay: 1e-4
scheduler: ReduceLROnPlateau
patience: 2
epoch: 30
pretrained: True| No.epoch | times/epoch | top1 acc (%) | top5 acc (%) |
|---|---|---|---|
| 5 | 3h54min38s | 68.89 | 88.92 |
8.ShuffleNet v2
basenet: ShuffleNet_v2_x0_5
dataset: ImageNet
batch_size: 32
optim: SGD
lr: 0.001
momentum: 0.9
weight_decay: 1e-4
scheduler: ReduceLROnPlateau
patience: 2
epoch: 30
pretrained: True| No.epoch | times/epoch | top1 acc (%) | top5 acc (%) |
|---|---|---|---|
| 5 | 3h52min0s | 55.61 | 78.84 |
参考文献
边栏推荐
- Using the color picker
- 数据库公共字段自动填充
- Introduction to the delta method
- MySQL索引事务
- navicat for mysql 连接时报错:1251-Client does not support authentication protocol requested by server
- day16--抓包工具Charles的使用
- MySQL database monthly growth problem
- 神经网络样本太少怎么办,神经网络训练样本太少
- 图像处理用什么神经网络,神经网络提取图片特征
- COLMAP+OpenMVS realizes 3D reconstruction mesh model of objects
猜你喜欢

DGIOT supports industrial equipment rental and remote control

DGIOT三千万电表集抄压测

Introduction to the delta method

Quickly enter the current date and time

概率分布及其应用

PHP笔记 28 29 30 31
DGIOT支持工业设备租赁以及远程管控

Uni-app开发微信小程序使用本地图片做背景图

自动化测试框架Pytest(三)——自定义allure测试报告
Add spark related dependencies and packaging plugins (sixth bullet)
随机推荐
快速输入当前日期与时间
基于ABP的AppUser对象扩展
SQL建表问题,帮我看看好吗朋友们~大家人。!
WooCommerce installation and rest api usage
ATH10传感器读取温湿度
二叉树 --- 堆
MySQL设置初始密码—注意版本mysql-8.0.30
Synchronization lock synchronized traces the source
761. Special Binary Sequences
初使jest 单元测试
1413. Stepwise Summation to Get Minimum Positive Numbers
34. Talk about why you want to split the database?What methods are there?
浅谈C语言实现冒泡排序
VS2013-调试汇编代码-生成asm文件-结构体内存布局-函数参数压栈-调用约定
卷积神经网络卷积层公式,卷积神经网络运算公式
如何正确理解线程机制中常见的I/O模型,各自主要用来解决什么问题?
34. 谈谈为什么要拆分数据库?有哪些方法?
Rust学习:6.3_复合类型之元组
mysql之两阶段提交
自动化测试框架Pytest(三)——自定义allure测试报告