当前位置:网站首页>Add spark related dependencies and packaging plugins (sixth bullet)
Add spark related dependencies and packaging plugins (sixth bullet)
2022-08-10 06:54:00 【Insufficient hair volume】
目录
添加sparkrelated dependencies and packaged plugins
步骤1 打开pom.xmlàAdded the following dependencies,点击右下角enable auto-import自动下载
步骤2 右击main下的ScalaCreate a file firstpackage并命名为cn.itcast
步骤3 创建WordCount.scalafile for word frequency statistics alt+回车:Select Import Package
步骤3 创建WordCount.scalafile for word frequency statistics alt+回车:Select Import Package
注意:需要事先在D盘创建word文件夹下的words.txt里面内容如下:(It is best not to use Chinese paths)

添加sparkrelated dependencies and packaged plugins
步骤1 打开pom.xmlàAdded the following dependencies,点击右下角enable auto-import自动下载
<!--设置依赖版本号-->
<properties>
<scala.version>2.11.8</scala.version>
<hadoop.version>2.7.1</hadoop.version>
<spark.version>2.0.0</spark.version>
</properties>
<dependencies>
<!--Scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!--Spark-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!--Hadoop-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>Select autoload after adding dependencies

步骤2 右击main下的ScalaCreate a file firstpackage并命名为cn.itcast
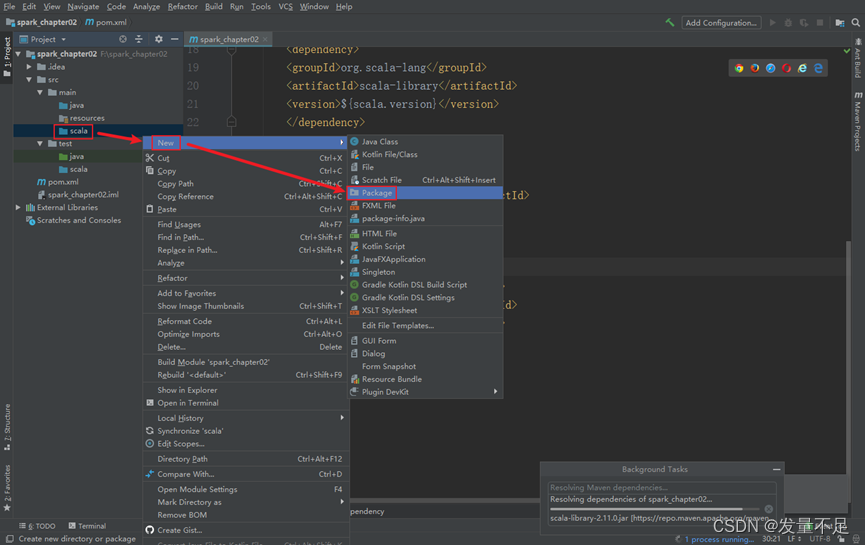

步骤3 创建WordCount.scalafile for word frequency statistics alt+回车:Select Import Package
问题:没有scala文件创建选项

解决方法:




After adding the plugin package, you can: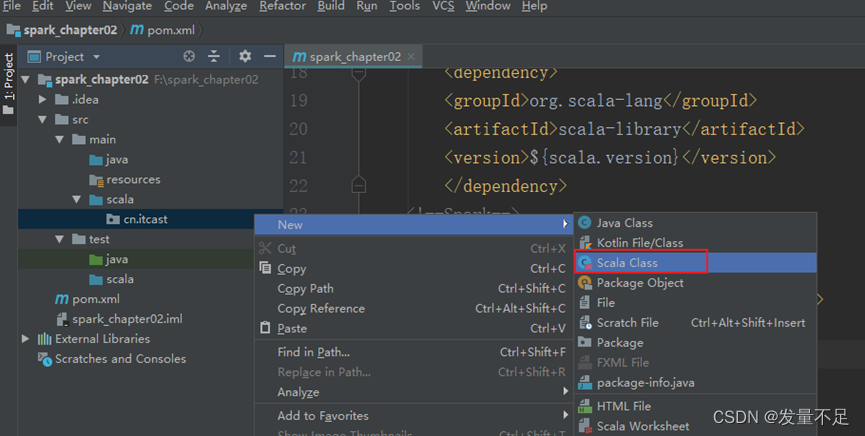

步骤3 创建WordCount.scalafile for word frequency statistics alt+回车:Select Import Package
注意:需要事先在D盘创建word文件夹下的words.txt里面内容如下:(It is best not to use Chinese paths)

package cn.itcast
# 导入包
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象,设置appName和Master地址
val sparkconf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
//2.创建SparkContext对象,它是所有任务计算的源头,它会创建DAGScheduler和TaskScheduler
val sparkContext = new SparkContext(sparkconf)
//设置日志级别
//sparkContext.setLogLevel("WARN")
//3.读取数据文件,RDDIt can be simply understood as a collection,集合中存放的元素是String类型
val data : RDD[String] = sparkContext.textFile("D:\\word\\words.txt")
//4.切分每一行,获取所有的单词
val words :RDD[String] = data.flatMap(_.split(" "))
//5.每个单词记为1,转换为(单词,1)
val wordAndOne :RDD[(String, Int)] = words.map(x =>(x,1))
//6.相同单词汇总,前一个下划线表示累加数据,The next underscore indicates new data
val result: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//7.收集打印结果数据
val finalResult: Array[(String, Int)] = result.collect()
println(finalResult.toBuffer)
//8.关闭sparkContext对象
sparkContext.stop()
}
}
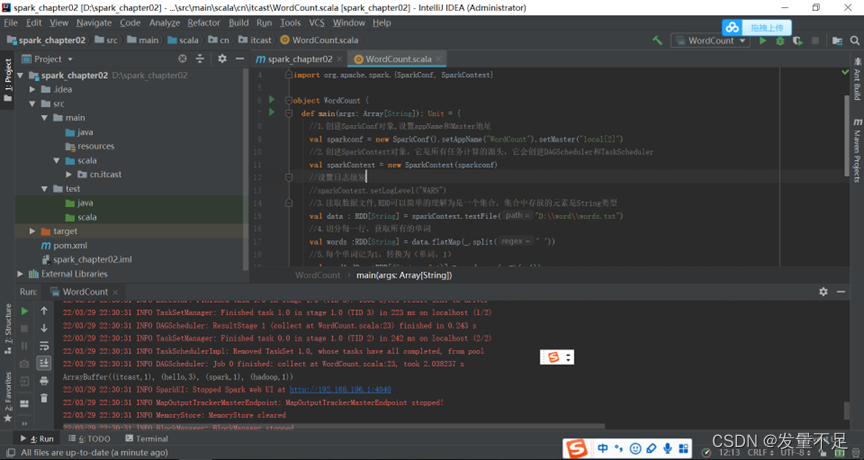
You can see the calculated word frequencyitcast(1)Hadoop(1)spark(1)hello(3)

可能碰到的问题:
If you encounter an error in the running result or the result does not come out,did not let goScala-sdk-2.11.8
解决方法:



如果没有则需要手动添加:



解决以上问题,运行结果如下
You can see the calculated word frequencyitcast(1)Hadoop(1)spark(1)hello(3)
边栏推荐
- A few lines of code can crash the system;
- Excuse me.Oracle CDC connector supports LogMiner and XStream API two ways to capture
- 阿里巴巴(中国)网络技术有限公司、测试开发笔试二面试题(附答案)
- Deep understanding of the array
- 2022 Henan Mengxin League No. 5: University of Information Engineering B - Transportation Renovation
- Sort binary tree code
- 关于MongoDb查询Decimal128转BigDecimal问题
- CuteOneP 一款php的OneDrive多网盘挂载程序 带会员 同步等功能
- 2022 Henan Mengxin League Game (5): University of Information Engineering C - Throwing a Handkerchief
- 力扣(LeetCode)221. 最大正方形(2022.08.09)
猜你喜欢

自动化测试框架Pytest(一)——入门

【愚公系列】2022年08月 Go教学课程 034-接口和多态

一文2600字手把手教你编写性能测试用例

1413. Stepwise Summation to Get Minimum Positive Numbers

神经网络样本太少怎么办,神经网络训练样本太少

ES13 - ES2022 - The 123rd ECMA Congress approves the ECMAScript 2022 language specification

概率分布及其应用

Elementary Structure

WooCommerce 安装和 rest api 使用

自动化测试框架Pytest(三)——自定义allure测试报告
随机推荐
2022 Henan Mengxin League (fifth) game: University of Information Engineering H - Xiao Ming drinking milk tea
34. Talk about why you want to split the database?What methods are there?
预测股票涨跌看什么指标,如何预测明天股票走势
order by injection and limit injection, and wide byte injection
【MySQL】SQL语句
Why do games need hot updates
【愚公系列】2022年08月 Go教学课程 034-接口和多态
基于STC8G2K64S4单片机通过OLED屏幕显示模拟量光敏模拟值
什么是MQTT网关?与传统DTU有哪些区别?
2022河南萌新联赛第(五)场:信息工程大学 J - AC自动机
什么是长轮询
阿里巴巴(中国)网络技术有限公司、测试开发笔试二面试题(附答案)
深入理解数组
【MySQL】使用MySQL Workbench软件新建表
裸辞—躺平—刷题—大厂(Android面试的几大技巧)
MySQL设置初始密码—注意版本mysql-8.0.30
pytest之parametrize参数化
761. Special Binary Sequences
oracle业务表的数据发生增删改,该表的索引会写redo,undo吗?
数据库公共字段自动填充