当前位置:网站首页>ESIM(Enhanced Sequential Inference Model)- 模型详解
ESIM(Enhanced Sequential Inference Model)- 模型详解
2022-08-09 10:15:00 【AI_孟菜菜】
Esim:
ESIM(Enhanced Sequential Inference Model)是一个综合应用了BiLSTM和注意力机制的模型,在文本匹配中效果十分强大,也是目前为止非常最复杂的模型。
首先什么是文本匹配,简单来说就是分析两个句子是否具有某种关系,比如有一个问题,现在给出一个答案,我们就需要分析这个答案是否匹配这个问题,所以也可以看成是一个二分类问题(输出是或者不是)。现在主要基于SNIL和MutilNLI这两个语料库,它们包含两个句子premise和hypothesis以及一个label,label就是判断这两个句子的关系,接下来我们分析esim如何做的文本匹配的分析。
就像上面提到的,这个问题简单来说就是输入两个句子,输出一个label,这里一共有三个label(neutral(中性)、contradiction(矛盾)、entailment(蕴含)),那么我们就可以简单地用下图表示这个模型:
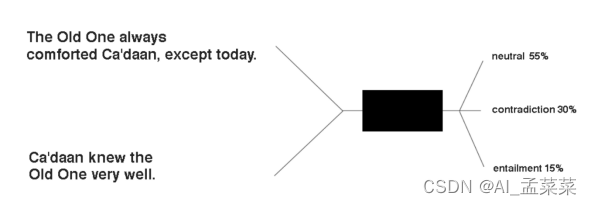
模型结构:

ESIM一共包含四部分,Input Encoding、Local Inference Modeling、Inference Composition、Prediction
Input Encoding
既然输入是两个句子,首先肯定是做word embedding了,方法有很多,这里假设直接用预训练的word2vec把句子转换成矩阵,注意,这时候我们得到的向量因为是基于word2vec预训练的向量得到的,并没有反映出句子中的前后文联系,所以我们这里继续利用BiLSTM再重新转换一下,得到最终的输入变量:

上面的ai、bi就是premise和hypothesis的某个单词的表示,这个过程就是ESIM中的input encoding过程。
我们先看一下这一层结构的输入内容,输入一般可以采用预训练好的词向量或者添加embedding层,接下来就是一个双向的LSTM,起作用主要在于对输入值做encoding,也可以理解为在做特征提取,最后把其隐藏状态的值保留下来,其中i与j分别表示的是不同的时刻,a与b表示的是上述提到的p与h。
Local Inference Modeling
这一层的任务主要是把上一轮拿到的特征值做差异性计算。这里作者采用了attention机制,其中attention weight的计算方法如下:
![]()
就是需要分析这两个句子之间的联系,具体怎么分析,首先要注意的是,我们现在得到的句子和单词的表示向量,是基于当前语境以及单词之间的意思综合分析得到的,那么如果两个单词之间联系越大,就意味着他们之间的距离和夹角就越少,比如(1,0)和(0,1)之间的联系,就没有(0.5,0.5)和(0.5,0.5)之间的联系大。在理解了这一点之后,我们再来看看ESIM是怎么分析的。
正如之前所说的,如果两个词向量联系较大,那么乘积也会较大,然后:

这两条公式是整个ESIM的精髓所在,上述几条公式的目的,简单来说可以这样理解,比如a中有一个单词"good",首先我分析这个词和另一句话中各个词之间的联系,计算得到的结果e{ij}标准化后作为权重,用另一句话中的各个词向量按照权重去表示"good",这样一个个分析对比,得到新的序列。以上过程称为Local Inference Modelling(本地推理模型)。
得到encoding值与加权encoding值之后,下一步是分别对这两个值做差异性计算,作者认为这样的操作有助于模型效果的提升,论文中有两种计算方法,分别是对位相减与对位相乘,最后把encoding两个状态的值与相减、相乘的值拼接起来。
很明显,这一步就是分析差异,从而判断两个句子之间的联系是否足够大了,ESIM主要是计算新旧序列之间的差和积,并把所有信息合并起来储存在一个序列中:

Inference Composition(合成推理)
为什么要把所有信息储存在一个序列中,因为ESIM最后还需要综合所有信息,做一个全局的分析,这个过程依然是通过BiLSTM处理这两个序列:
在这一层中,把之前的值再一次送到了BiLSTM中,这里的BiLSTM的作用和之前的并不一样,这里主要是用于捕获局部推理信息![]() 及其上下文,以便进行推理组合。
及其上下文,以便进行推理组合。

值得注意的是,F是一个单层神经网络(ReLU作为激活函数),主要用来减少模型的参数避免过拟合,另外,上面的t表示BiLSTM在t时刻的输出。
最后把BiLSTM得到的值进行池化操作,分别是最大池化与平均池化,并把池化之后的值再一次的拼接起来。

因为对于不同的句子,得到的向量v长度是不同的,为了方便最后一步的分析,这里进行了池化处理,把结果储存在一个固定长度的向量中。值得注意的是,因为考虑到求和运算对于序列长度是敏感的,因而降低了模型的鲁棒性,所以ESIM选择同时对两个序列进行average pooling和max pooling,再把结果放进一个向量中:
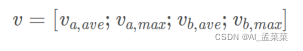
Prediction
最后把V 送入到全连接层,激活函数采用的是 tanh,得到的结果送到softmax层。
总结:
ESIM与BiMPM在相似度匹配任务中都是使用较多的模型,但是ESIM训练速度快,效果也并没有逊色太多,如果加入了语法树,其最终效果也能进一步的提升。
边栏推荐
猜你喜欢
![[Machine Learning] Detailed explanation of web crawler combat](/img/ac/f00f0c81e66ba526ac39ee60fad72b.png)
[Machine Learning] Detailed explanation of web crawler combat
![[贴装专题] 视觉贴装平台与贴装流程介绍](/img/ec/870af3b56a487a5ca3a32a611234ff.png)
[贴装专题] 视觉贴装平台与贴装流程介绍

Practical skills: a key for image information in the Harbor, quick query image
分类预测 | MATLAB实现CNN-GRU(卷积门控循环单元)多特征分类预测

【MySQL】mysql因为字符集导致left join出现Using join buffer (Block Nested Loop)
Super detailed MySQL basic operations

阿里神作!吃透这份资料入厂率高达99%
多线程(基础)
动态内存管理
分类预测 | MATLAB实现CNN-LSTM(卷积长短期记忆神经网络)多特征分类预测
随机推荐
OSCS开源软件安全周报,一分钟了解本周开源软件安全大事
2021-01-11-雪碧图做表情管理器
写一个通讯录小程序
LeetCode(剑指 Offer)- 25. 合并两个排序的链表
技术分享 | 使用 cURL 发送请求
[Machine Learning] Detailed explanation of web crawler combat
【size_t是无符号整数 (-1 > 10) -> 1】
socket实现TCP/IP通信
分类预测 | MATLAB实现CNN-LSTM(卷积长短期记忆神经网络)多特征分类预测
快速解决MySQL插入中文数据时报错或乱码问题
【八大排序④】归并排序、不基于比较的排序(计数排序、基数排序、桶排序)
Multi-threaded cases - timer
xmms已经发布到v1.3了,好久没写博客了
TELNET协议相关RFC
electron 应用开发优秀实践
EndNote使用指南
Win7 远程桌面限制IP
多线程案例——定时器
OpenGL 2.0编程例子
【八大排序②】选择排序(选择排序,堆排序)