当前位置:网站首页>可能95%的人还在犯的PyTorch错误
可能95%的人还在犯的PyTorch错误
2022-08-09 10:21:00 【PaperWeekly】

作者 | serendipity
单位 | 同济大学
研究方向 | 行人搜索、3D人体姿态估计

引言
或许是 by design,但是这个 bug 目前还存在于很多很多人的代码中。就连特斯拉 AI 总监 Karpathy 也被坑过,并发了一篇推文。
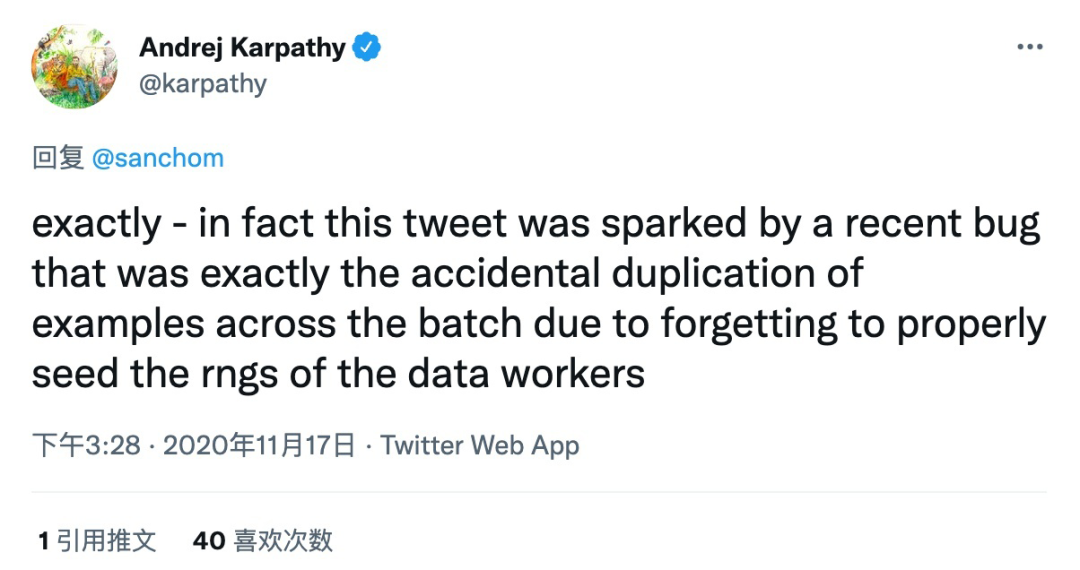
事实上,这条推特是由最近的一个 bug 引发的,该 bug 正是由于忘记正确地为 DataLoader workers 设置随机数种子,而在整个训练过程中意外重复了 batch 数据。
2018 年 2 月就有人在 PyTorch 的 repo 下提了 issue [1],但是直到 2021 年 4 月才修复。此问题只在 PyTorch 1.9 版本以前出现,涉及范围之广,甚至包括了 PyTorch 官方教程 [2]、OpenAI 的代码 [3]、NVIDIA 的代码 [4]。

PyTorch DataLoader的隐藏bug
在PyTorch中加载、预处理和数据增强的标准方法是:继承 torch.utils.data.Dataset 并重载它的 __getitem__ 方法。为了应用数据增强,例如随机裁剪和图像翻转,该 __getitem__ 方法通常使用 NumPy 来生成随机数。然后将该数据集传递给 DataLoader 创建 batch。数据预处理可能是网络训练的瓶颈,因此有时需要并行加载数据,这可以通过设置 Dataloader的 num_workers 参数来实现。
我们用一段简单的代码来复现这个 bug,PyTorch 版本应 <1.9,我在实验中使用的是 1.6。
import numpy as np
from torch.utils.data import Dataset, DataLoader
class RandomDataset(Dataset):
def __getitem__(self, index):
return np.random.randint(0, 1000, 3)
def __len__(self):
return 8
dataset = RandomDataset()
dataloader = DataLoader(dataset, batch_size=2, num_workers=2)
for batch in dataloader:
print(batch)输出为
tensor([[116, 760, 679], # 第1个batch, 由进程0返回
[754, 897, 764]])
tensor([[116, 760, 679], # 第2个batch, 由进程1返回
[754, 897, 764]])
tensor([[866, 919, 441], # 第3个batch, 由进程0返回
[ 20, 727, 680]])
tensor([[866, 919, 441], # 第4个batch, 由进程1返回
[ 20, 727, 680]])我们惊奇地发现每个进程返回的随机数是相同的!!

问题原因
PyTorch 用 fork [5] 方法创建多个子进程并行加载数据。这意味着每个子进程都会继承父进程的所有资源,包括 Numpy 随机数生成器的状态。

解决方法
注: spawn 方法则是从头构建一个子进程,不会继承父进程的随机数状态。 torch.multiprocessing 在Unix 系统中默认使用 fork ,在 MacOS 和 Windows上默认是 spawn 。所以这个问题只在 Unix 上出现。当然,也可以强制在 MacOS 和 Windows 中使用 fork 方式创建子进程。
DataLoader的构造函数有一个可选参数 worker_init_fn。在加载数据之前,每个子进程都会先调用此函数。我们可以在 worker_init_fn 中设置 NumPy 的种子,例如:
def worker_init_fn(worker_id):
# np.random.get_state(): 得到当前的Numpy随机数状态,即主进程的随机状态
# worker_id是子进程的id,如果num_workers=2,两个子进程的id分别是0和1
# 和worker_id相加可以保证每个子进程的随机数种子都不相同
np.random.seed(np.random.get_state()[1][0] + worker_id)
dataset = RandomDataset()
dataloader = DataLoader(dataset, batch_size=2, num_workers=2, worker_init_fn=worker_init_fn)
for batch in dataloader:
print(batch)正如我们期望的那样,每个 batch 的值都是不同的。
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[180, 413, 50],
[894, 318, 729]])
tensor([[530, 594, 116],
[636, 468, 264]])等一下,假如我们再多迭代几个 epoch 呢?
for epoch in range(3):
print(f"epoch: {epoch}")
for batch in dataloader:
print(batch)
print("-"*25)我们发现,虽然在一个 epoch 内恢复正常了,但是不同 epoch 之间又出现了重复。
epoch: 0
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[939, 988, 37],
[983, 933, 821]])
tensor([[832, 50, 453],
[ 37, 322, 981]])
-------------------------
epoch: 1
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[939, 988, 37],
[983, 933, 821]])
tensor([[832, 50, 453],
[ 37, 322, 981]])
-------------------------
epoch: 2
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[939, 988, 37],
[983, 933, 821]])
tensor([[832, 50, 453],
[ 37, 322, 981]])
-------------------------因为在默认情况下,每个子进程在 epoch 结束时被杀死,所有的进程资源都将丢失。在开始新的 epoch 时,主进程中的随机状态没有改变,用于再次初始化各个子进程,所以子进程的随机数种子和上个 epoch 完全相同。
因此我们需要设置一个会随着 epoch 数目改变而改变的随机数,例如:np.random.get_state()[1][0] + epoch + worker_id。
上述随机数在实际应用中很难实现,因为在 worker_init_fn 中无法得知当前是第几个 epoch。但是 torch.initial_seed() 可以满足我们的需求。
def seed_worker(worker_id):
worker_seed = torch.initial_seed() % 2**32
np.random.seed(worker_seed)实际上,这就是 PyTorch 官方推荐的做法 [6]。
没有准备深入研究的读者到这里已经可以了,以后创建 DataLoader 时,把 worker_init_fn 设置为上面的 seed_worker 函数即可。想了解背后原理的,请看下一节,会涉及到 DataLoader 的源码理解。

为什么torch.initial_seed()可以?
我们首先要了解多进程 DataLoader 的处理流程。
1. 在主进程中实例化 DataLoader(dataset, num_workers=2)。
2. 创建两个 multiprocessing.Queue [7] 用来告诉两个子进程各自应该负责取哪几个数据。假设 Queue1 = [0, 2], Queue2 = [1, 3] 就代表第一个子进程应该负责取第 0,2 个数据,第二个进程负责第 1,3 个数据。当用户要取第 index 个数据时,主进程先查询哪个子进程是空闲的,如果第二个子进程空闲,则把 index 放入到 Queue2 中。 再创建一个 result_queue [8] 用来保存子进程读取的数据,格式为 (index, dataset[index])。
3. 每个 epoch 开始时,主要干两件事情。a): 随机生成一个种子 [9] base_seed b): 用 fork 方法创建 2 个子进程 [10]。在每个子进程中,将 torch 和 random 的随机数种子设置为 base_seed + worker_id。然后不断地查询各自的队列中有没有数据,如果有,就取出里面的 index,从 dataset 中获取第 index 个数据 dataset[index],将结果保存到 result_queue 中。
在子进程中运行 torch.initial_seed(),返回的就是 torch 当前的随机数种子,即 base_seed + worker_id。因为每个 epoch 开始时,主进程都会重新生成一个 base_seed,所以 base_seed 是随 epoch 变化而变化的随机数。此外,torch.initial_seed()返回的是 long int 类型,而 Numpy 只接受 uint 类型([0, 2**32 - 1]),所以需要对 2**32 取模。
如果我们用 torch 或者 random 生成随机数,而不是 numpy,就不用担心会遇到这个问题,因为 PyTorch 已经把 torch 和 random 的随机数设置为了 base_seed + worker_id。
综上所述,这个 bug 的出现需要满足以下两个条件:
PyTorch 版本 < 1.9
在 Dataset 的
__getitem__方法中使用了 Numpy 的随机数
附录
一些候选方案。
pytorch-image-models [11]
def seed_worker(worker_id): worker_info = torch.utils.data.get_worker_info() # worker_info.seed == torch.initial_seed() np.random.seed(worker_info.seed % 2**32)@晚星 [12]
def seed_worker(worker_id): seed = np.random.default_rng().integers(low=0, high=2**32, size=1) np.random.seed(seed)@ggggnui [13]
class WorkerInit: def __init__(self, global_step): self.global_step = global_step def worker_init_fn(self, worker_id): np.random.seed(self.global_step + worker_id) def update_global_step(self, global_step): self.global_step = global_step worker_init = WorkerInit(0) dataloader = DataLoader(dataset, batch_size=2, num_workers=2, worker_init_fn=worker_init.worker_init_fn) for epoch in range(3): for batch in dataloader: print(batch) # 需要注意的是len(dataloader)必须>=num_workers,不然还是会重复 worker_init.update_global_step((epoch + 1) * len(dataloader))

文内链接 & 参考文献
[1] https://github.com/pytorch/pytorch/issues/5059
[2] https://github.com/pytorch/tutorials/blob/af754cbdaf5f6b0d66a7c5cd07ab97b349f3dd9b/beginner_source/data_loading_tutorial.py%23L270-L271
[3] https://github.com/openai/ebm_code_release/blob/18898a24ee24dcd75c41ac3e228b9db79e53237c/data.py%23L465-L470
[4] https://github.com/NVlabs/Deep_Object_Pose/blob/11bbc3b8545e099b35901a13f549ddddacd7dd1f/scripts/train.py%23L518-L521
[5] https://docs.python.org/3/library/multiprocessing.html%23contexts-and-start-methods
[6] https://pytorch.org/docs/stable/notes/randomness.html%23dataloader
[7] https://github.com/pytorch/pytorch/blob/bc3d892c20ee8cf6c765742481526f307e20312a/torch/utils/data/dataloader.py%23L897
[8] https://github.com/pytorch/pytorch/blob/bc3d892c20ee8cf6c765742481526f307e20312a/torch/utils/data/dataloader.py%23L888
[9] https://github.com/pytorch/pytorch/blob/bc3d892c20ee8cf6c765742481526f307e20312a/torch/utils/data/dataloader.py%23L495
[10] https://github.com/pytorch/pytorch/blob/bc3d892c20ee8cf6c765742481526f307e20312a/torch/utils/data/dataloader.py%23L901
[11] https://github.com/rwightman/pytorch-image-models/blob/e4360e6125bb0bb4279785810c8eb33b40af3ebd/timm/data/loader.py#L149
[12] https://www.zhihu.com/people/wan-xing-13
[13] https://www.zhihu.com/people/ggggnui
[14] https://tanelp.github.io/posts/a-bug-that-plagues-thousands-of-open-source-ml-projects/
[15] https://github.com/pytorch/pytorch/pull/56488
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·

边栏推荐
- Throwing a question? The execution speed of the Count operation in the Mysql environment is very slow. You need to manually add an index to the primary key---MySql optimization 001
- Collections and Functions
- 从源码分析UUID类的常用方法
- Umi Hooks
- 集合与函数
- 深度学习--生成对抗网络(Generative Adversarial Nets)
- 蓄电池建模、分析与优化(Matlab代码实现)
- The GNU Privacy Guard
- 拿下跨界C1轮投资,本土Tier 1高阶智能驾驶系统迅速“出圈”
- 借问变量何处存,牧童笑称用指针,Go lang1.18入门精炼教程,由白丁入鸿儒,go lang类型指针(Pointer)的使用EP05
猜你喜欢


![[项目配置] 配置Qt函数库和ui界面库的封装并调用的项目](/img/e9/d41f144a2f27e76f97cd6401d37578.png)

随机推荐
antd表单
1003 我要通过! (20 分)
判断一段文字的width
上传张最近做的E2用的xmms的界面的截图
快速解决MySQL插入中文数据时报错或乱码问题
编解码(seq2seq)+注意机制(attention) 详细讲解
一天半的结果——xmms on E2
Electron application development best practices
function two
KMP& sunday
Redis + NodeJS 实现一个能处理海量数据的异步任务队列系统
GeoScene Pro 2.1下载地址与安装基本要求
实现下拉加载更多
WUSTOJ:n个素数构成等差数列
Master-slave postition changes cannot be locked_Slave_IO_Running shows No_Slave_Sql_Running shows No---Mysql master-slave replication synchronization 002
Win7 远程桌面限制IP
1: bubble sort
Win系统 - 罗技 G604 鼠标蓝灯闪烁、失灵解决方案
socket实现TCP/IP通信
分类预测 | MATLAB实现CNN-GRU(卷积门控循环单元)多特征分类预测