当前位置:网站首页>深度学习--自编码器(AutoEncoder)
深度学习--自编码器(AutoEncoder)
2022-08-09 10:15:00 【AI_孟菜菜】
自编码器:
自编码器是用于无监督学习,高效编码的神经网络,自动编码器的目的就在于,学习一组数据的编码,通常用于数据的降维,自编码是一种无监督的算法,网络分为:输入层,隐藏层(编码层),解码层,该网络的目的在于重构输入,使其隐藏层的数据表示更加好,利用了反向传播,将输入值和目标值设置一样,就可以不断的进行迭代训练。
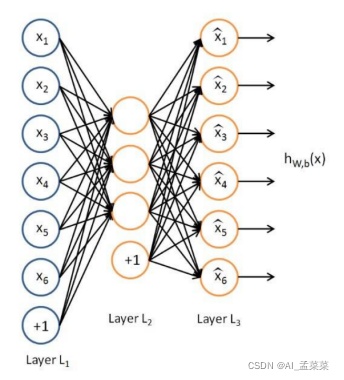
自编码的学习目标就在于使h(x)≈x,自编码是属于神经网络一类的,但是他和PCA也紧密相关:
- 它和PCA都属于无监督的学习算法
- 她要最小化和PCA一样的目标函数
- 他是一种神经网络
- 这种神经网络的目标输出就是输入
自编码器的分类:
一:欠完备自编码
- 香草自编码
- 多层自编码
- 卷积自编码CAE
二:正则编码器
- 稀疏自编码
- 去噪自编码DAE
- 收缩自编码
三:变分自编码VAE
自编码器分为两个部分:
编码器:h = f(x)
解码器:r = g(h)
也就是说整个自编码器可以由:r = g(h(x))来描述,其中输出r与原始的输入是相近的
最后我们希望得到的是有用的h,如果这个h比输入的x维度要小,那么这种自编码就叫做欠完备自编码,它们的代价公式就可以是用均方误差:

因此,非线性的编码器,和非线性的解码器,就可以捕捉到相比较PCA更加有用的信息。在这里,隐含层维数(1024)小于输入维数(10000),则称这个编码器是有损的。通过这个约束,来迫使神经网络来学习数据的压缩表征。
网络结构:![]()
多层自编码:
这个就很好理解了,将隐藏层的层数加深:
网络结构为: ![]()
卷积自编码就更简单了,无非就是将原本的神经网络层,替换成卷积神经网络
自动编码器其实就是非常简单的神经结构。它们大体上是一种压缩形式,类似于使用MP3压缩音频文件或使用jpeg压缩图像文件。

自动编码器与主成分分析(PCA)密切相关。事实上,如果自动编码器使用的激活函数在每一层中都是线性的,那么瓶颈处存在的潜在变量(网络中最小的层,即代码)将直接对应(PCA/主成分分析)的主要组件。通常,自动编码器中使用的激活函数是非线性的,典型的激活函数是ReLU(整流线性函数)和sigmoid/S函数。
网络背后的数学原理理解起来相对容易。从本质上看,可以把网络分成两个部分:编码器和解码器。
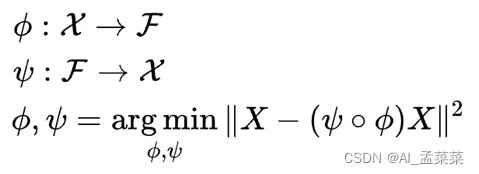
编码器函数用ϕ表示,该函数将原始数据X映射到潜在空间F中(潜在空间F位于瓶颈处)。解码器函数用ψ表示,该函数将瓶颈处的潜在空间F映射到输出函数。此处的输出函数与输入函数相同。因此,我们基本上是在一些概括的非线性压缩之后重建原始图像。
编码网络可以用激活函数传递的标准神经网络函数表示,其中z是潜在维度。
相似地,解码网络可以用相同的方式表示,但需要使用不同的权重、偏差和潜在的激活函数。
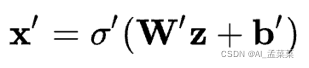
随后就可以利用这些网络函数来编写损失函数,我们会利用这个损失函数通过标准的反向传播程序来训练神经网络。
![]()
由于输入和输出的是相同的图像,神经网络的训练过程并不是监督学习或无监督学习,我们通常将这个过程称为自我监督学习。自动编码器的目的是选择编码器和解码器函数,这样就可以用最少的信息来编码图像,使其可以在另一侧重新生成。
如果在瓶颈层中使用的节点太少,重新创建图像的能力将受到限制,导致重新生成的图像模糊或者和原图像差别很大。如果使用的节点太多,那么就没必要压缩了。
自动编码机可以进行权值共享,即解码器和编码器的权值彼此互为转置,这样可以加快网络学习的速度,因为训练参数的数量减少了,但同时降低了网络的灵活程度。
自动编码机的一个非常好的应用是降维,而且自动编码机能产生比 PCA 更好的结果。自动编码机也可用于特征提取、文档检索、分类和异常检测。
边栏推荐
猜你喜欢
一天半的结果——xmms on E2
Battery modeling, analysis and optimization (Matlab code implementation)
![[ASM] Bytecode operation MethodVisitor case combat generation object](/img/a9/df07614f875794d55d530bd04dc476.jpg)
[ASM] Bytecode operation MethodVisitor case combat generation object

3D打印了这个杜邦线理线神器,从此桌面再也不乱了
今天做了手机播放器的均衡器
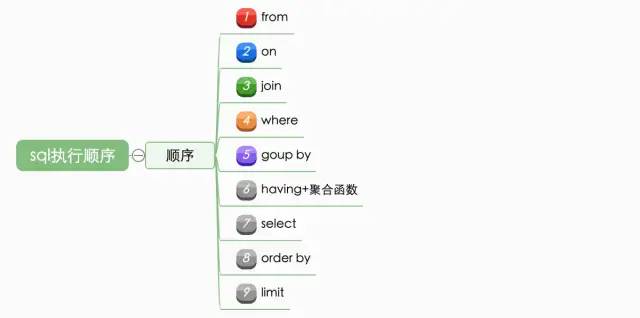
MySQL执行过程及执行顺序
多线程(基础)
![[贴装专题] 视觉贴装平台与贴装流程介绍](/img/ec/870af3b56a487a5ca3a32a611234ff.png)
[贴装专题] 视觉贴装平台与贴装流程介绍
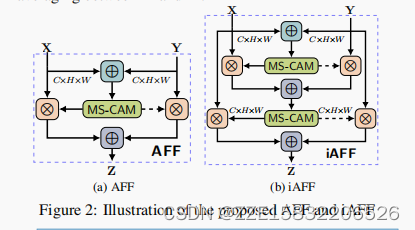
Attentional Feature Fusion
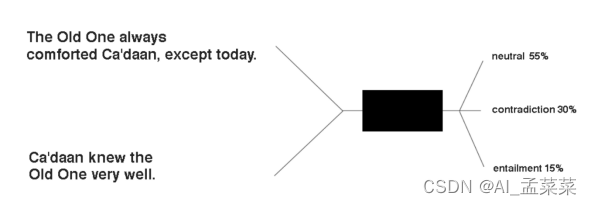
ESIM(Enhanced Sequential Inference Model)- 模型详解

随机推荐
编程技术提升
KMP& sunday
多线程(基础)
markdown转ipynb--利用包notedown
MySQL全文索引
JDBC中的增删改查操作
写一个通讯录小程序
函数组件和类组件和dva视图更新问题
EndNote使用指南
条件控制语句
OSCS开源软件安全周报,一分钟了解本周开源软件安全大事
实验室装修及改造工程程序简介
关于页面初始化
开源SPL,WebService/Restful广泛应用于程序间通讯,如微服务、数据交换、公共或私有的数据服务等。
Redis cache update strategy actively
【size_t是无符号整数 (-1 > 10) -> 1】
极域Killer 1.0代码
xmms的歌词显示及音量控制OK
小程序员的发展计划
basic operator