当前位置:网站首页>Regular expression of shell programming and text processor
Regular expression of shell programming and text processor
2022-08-10 21:52:00 【Guannan cattle x people】
目录
引言:正则表达式,又称规则表达式.(Regular Expression),在代码中常简写为 regex、regexp 或 RE),计算机科学的一个概念.正则表达式通常被用来检索,替换那些符合某个模式(规则)的文本.
正则表达式
正则表达式定义
正则表达式,又称正规表达式,常规表达式
使用字符串来描述、匹配一系列符合某个规则的字符串
正则表达式--通常用于判断语句中,Used to check whether some strings meet a certain format
正则表达式是由普通字符与元字符组成
正则表达式组成
普通字符
大小写字母、数字、标点符号及一些其他符号
元字符
在正则表达式中具有特殊意义的专用字符
Linux 中常用的有两种正则表达式引擎
基础正则表达式:BRE
扩展正则表达式: ERE
基础正则表达式元字符
支持的工具: grep、egrep、sed、awk
基础正则表达式是常用的正则表达式部分
| 元字符 | 作用 |
| * | 匹配前面子表达式0次或者多次 例:goo*d,go.*d |
| [list] | 匹配list列表中的一个字符 例:go[loa]d,[a-z],[0-9]匹配任意一位数字 |
| [^list] | 匹配任意非list列表中的一个字符 例:[^0-9],[^a-z]匹配任意一位非小写字母 |
| \{n,m\} | 匹配前面子表达式n到m次 例:go\{2,3\}d,'[0-9]\{2,3\}'匹配两位到三位数字 |
| \{n,\} | 匹配前面子表达式不少于n次 例:go\{2,\}d,'[0-9]\{2,\}'Match two or more digits |
| \{n\} | 匹配前面子表达式n次 例:go\{2\}d,'[0-9]\{2\}'匹配两位数字 |
| . | 匹配除\n之外的任何一个字符 例:go.d , g..d |
| $ | 匹配字符串结束的位置 例:word$,^$匹配空行 |
| ^ | 匹配字符串开始的位置 例:^a,^the,^#,^[a-z] |
| \ | 转义字符,Used to cancel the meaning of special symbols 例:\!,\n,\$等 |
| 注:egrep,awk使用{n}、{n,}、{n,m} 匹配时“{}”前面不用加“\” | |
扩展正则表达式
扩展正则表达式是对基础正则表达式的扩充深化
| 元字符 | 作用 |
| + | 匹配前面子表达式一次以上 例:go+d,将匹配至少一个o,如god,good,goood等 |
| ? | 匹配前面子表达式0次或一次 例:go?d,matches will begd或者god |
| () | Creates the characters in parentheses as a whole 例:g(oo)+d,将匹配oo整体一次以上 |
| | | Match a string of strings as OR 例:g(oo|la)d,将匹配good或glad |
文本处理工具
grep 命令
grep命令使用正则表达式来搜索文本,并且把匹配的文本打印出来
grep [选项] ..查找条件 目标文件
| 常用选项 | |
| -E | 将样式为延伸的正则表达式来使用. |
| -c | 计算符合样式的列数. |
| -i | 忽略字符大小写的差别. |
| -n | 列出所有匹配的文本行,并显示行号 |
| -o | 只显示被模式匹配到的字符串 |
| -v | 显示不包含匹配文本的所有行. |
| --color=auto | 可以将找到的关键词部分加上颜色的显示 |
-c 统计zmj的行数 不显示内容

-i Case-insensitive find all in filethe的行
I created a test file first,Inside is a short text in English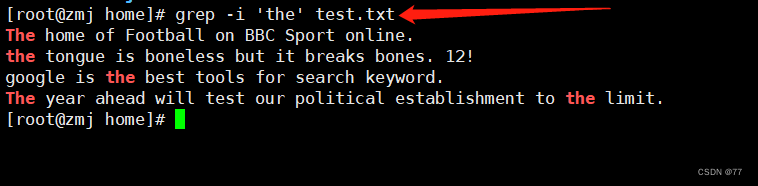
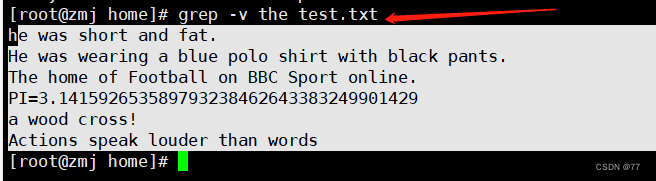
-v 取反 查找文件中,没有the的行显示出来
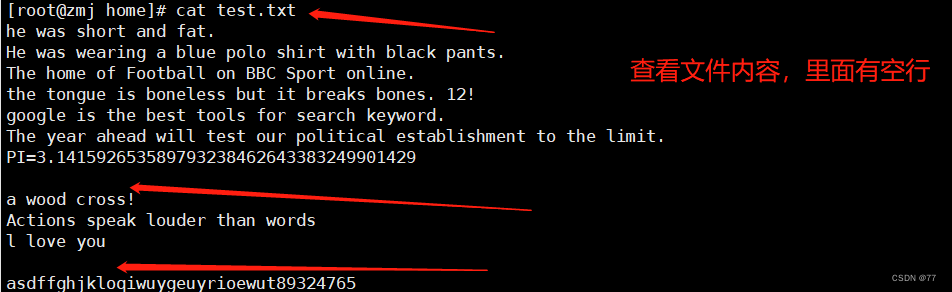
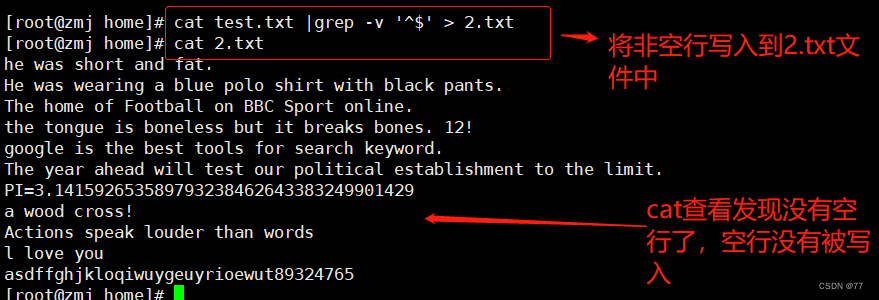
将非空行写入到2.txt文件
-n 查找并显示行数
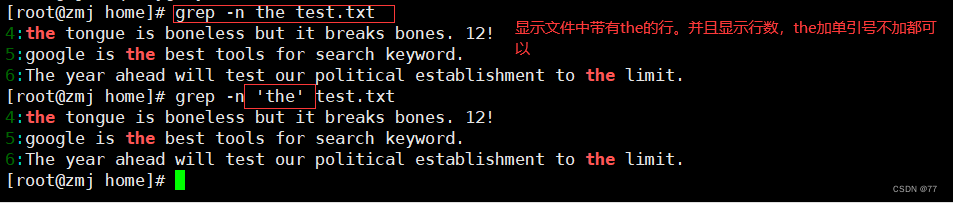 若反向选择,如查找不包含“the”字符的行,则需要通过 grep 命令的“-v”选项实现,并配合“-n”一起使用显示行号.
若反向选择,如查找不包含“the”字符的行,则需要通过 grep 命令的“-v”选项实现,并配合“-n”一起使用显示行号.
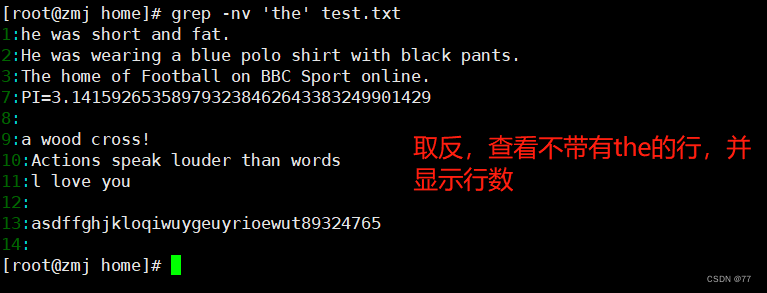
利用中括号“[]”来查找集合字符

查找“oo”前面不是“t”的字符串,只需要通过集合字符的反向选择“[^]”来实现该目的
首与行尾字节 ^ $,^ 符号,在字符类符号(括号[])之内与之外是不同的! 在 [] 内代表『反向选择』,在 [] 之外则代表定位在行首的意义!
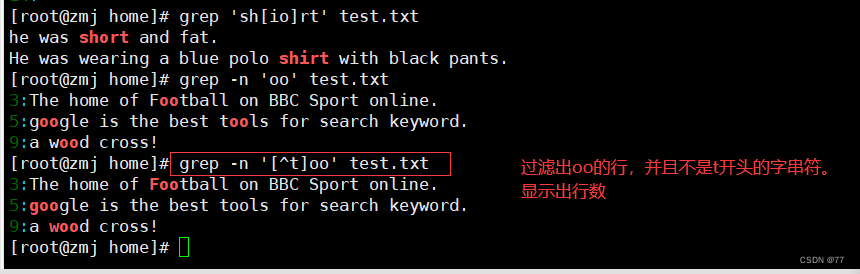
可以使用“grep -n‘[^a-z]oo’test.txt”命令实现,其中“a-z”表示小写字母,大写字母则通过“A-Z”表示.

查找包含数字的行可以通过“grep -n ‘[0-9]’ ceshi.txt”命令来实现

基础正则表达式包含两个定位元字符:“^”(行首)与“$”(行尾)

 Filter out lines that start with characters and numbers,显示行号 (Invert the square brackets,中括号外^以.,..开头)
Filter out lines that start with characters and numbers,显示行号 (Invert the square brackets,中括号外^以.,..开头)

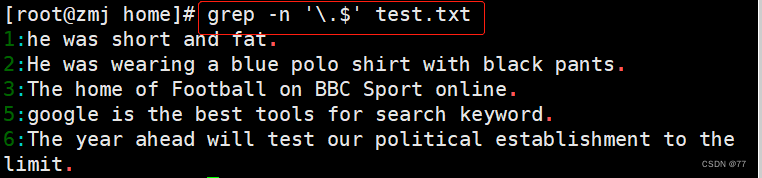
过滤出以.结尾的行
因为小数点(.)在正则表达式中也是一个元字符,所以在这里需要用转义字符“\”将具有特殊意义的字符转化成普通字符
egrep 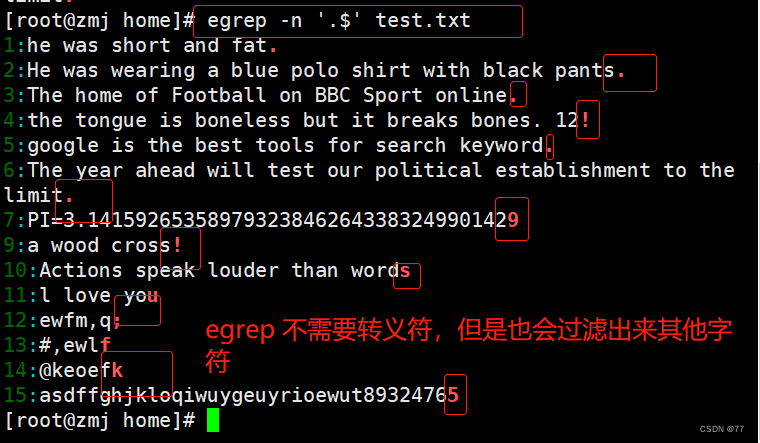
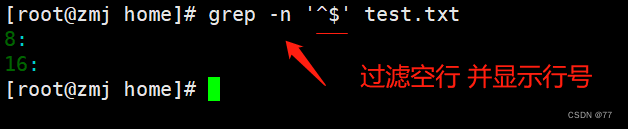
当查询空白行时,执行“grep -n‘^$’ test.txt”命令即可
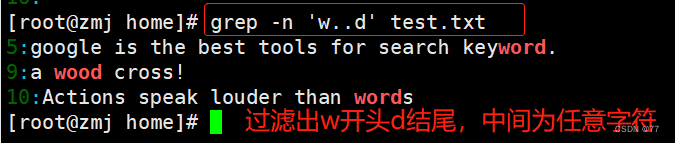
查找任意一个字符“.”与重复字符“*”
在正则表达式中小数点(.)也是一个元字符,代表任意一个字符.例如执行以下命令就可以查找“w??d”的字符串,即共有四个字符,以 w 开头 d 结尾.
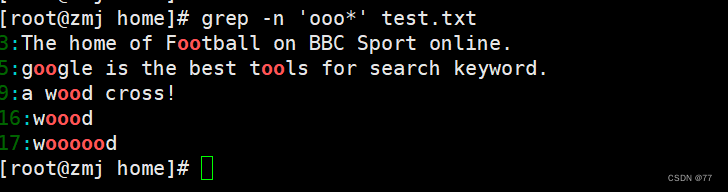
若查询包含至少两个 o 以上的字符串,则执行“grep -n 'ooo*' test.txt”命令即可
查询以 w 开头 d 结尾,中间包含至少一个 o的字符串
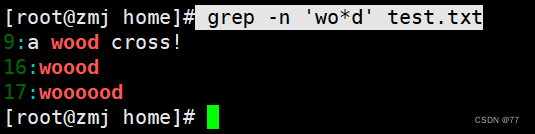
查找连续字符范围“{}”
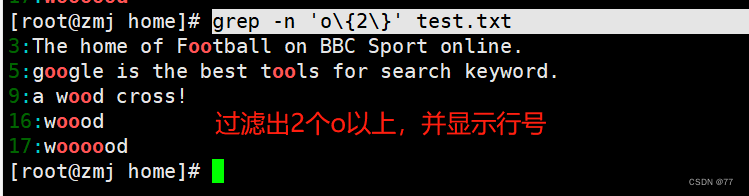
查询以 w 开头以 d 结尾,中间包含 2~5 个 o 的字符串
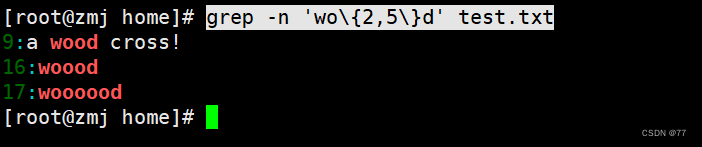
查询以 w 开头以 d 结尾,中间包含 2 个或 2 个以上 o 的字符串
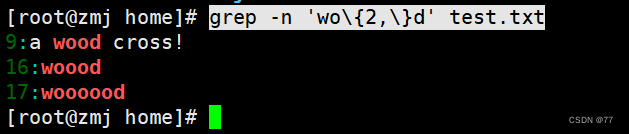
例题
First look up and list alllogfile and redirect togrep
使用grep 查找error 的行
使用grep 来查找不包含info 的行
cut 列截取工具
使用说明:cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出.如果不指定 File 参数,cut 命令将读取标准输入.必须指定 -b、-c 或 -f 标志之一
| 常用选项 | |
| -b | 按字节截取 |
| -c | 按字符截取,常用于中文 |
| -d | Specify what to separate and intercept,默认为制表符 |
| -f | 通常和-d一起 |
案例
分割打印passwd第7列
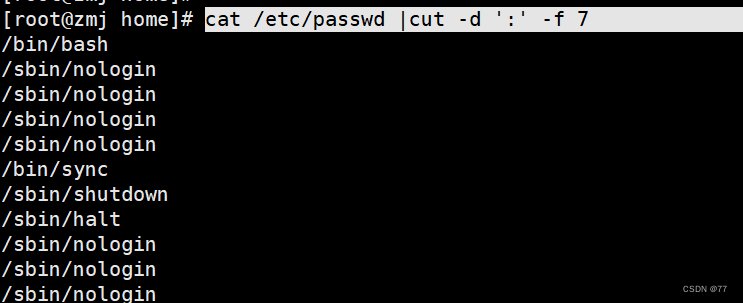
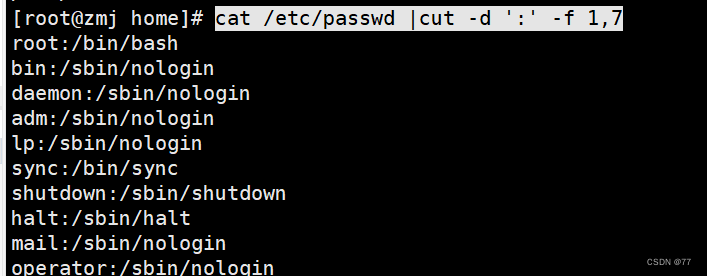
分割打印passwd第1列和第7列
查看当前登录用户的第4个字节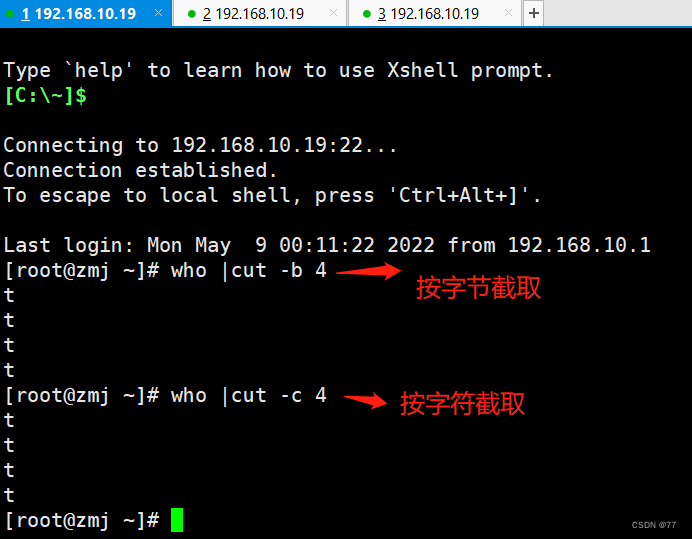
-b 与 -c 的区别
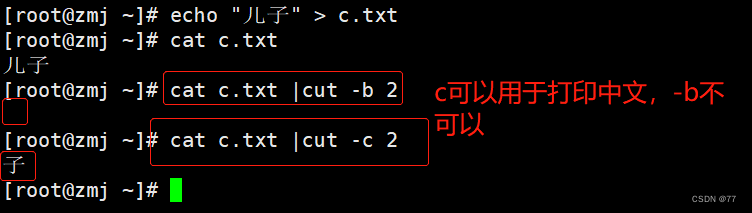
cut只擅长于处理单个字符为间隔的文本,-b只能分割字母,-c既可以分割字母也可以分割中文
sort 排序工具
sort 是一个以行为单位对文件内容进行排序的工具,也可以根据不同的数据类型来排序.例如数据和字符的排序就不一样
语法:sort [选项] 参数
| 常用选项 | |
| -t | 指定分隔符,默认使用[Tab]吧 键或空格分隔 |
| -k | 指定排序区域,哪个区间排序 |
| -n | 按照数字进行排序,默认是以文字形式排序 |
| -u | 等同于 uniq,表示相同的数据仅显示一行,注意:如果行尾有空格去重就不成功 |
| -r | 反向排序,默认是升序,-r就是降序 |
| -o | 将排序后的结果转存至指定文件 |
| -f | 忽略大小写,会将小写的字母都转换为大写字母来进行比较 |
| -b | 忽略每行前面的空格 |
案例
不加任何选项默认按第一列升序,字母的话就是从a到z由上而下显示
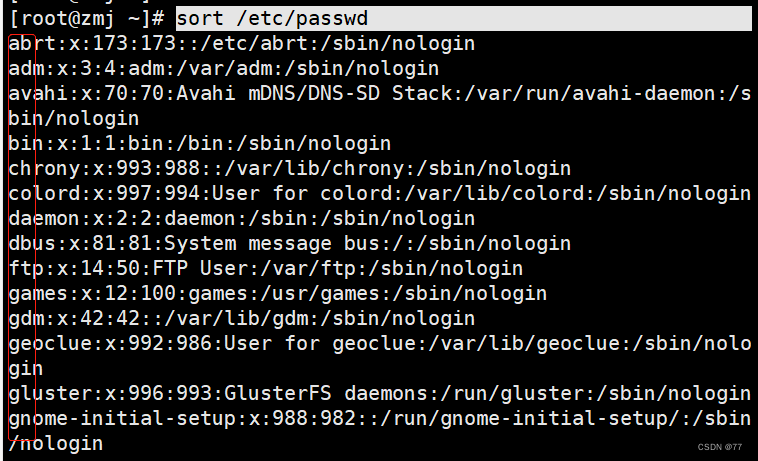
以冒号为分隔符,以数字大小对第三列排序(升序)
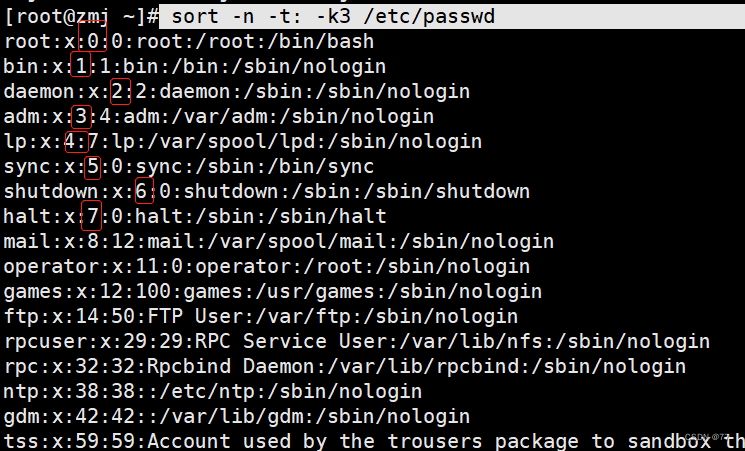
以冒号为分隔符,以数字大小对第三列排序(降序)
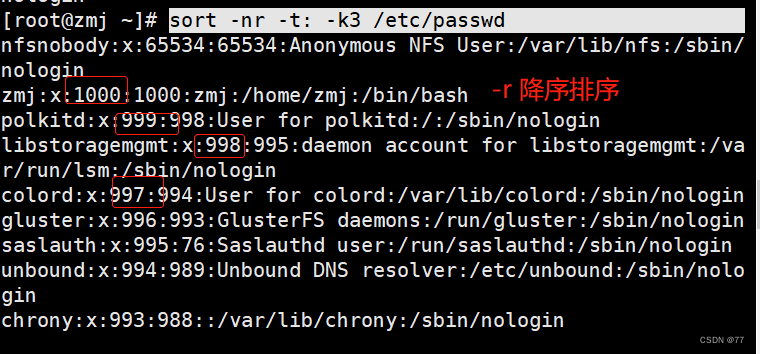 -u
-u
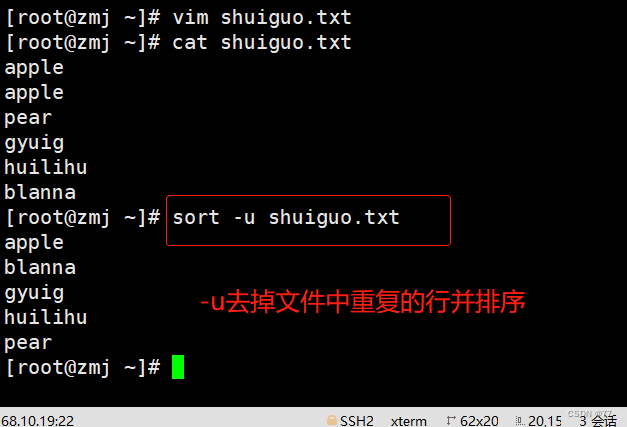
uniq 去重工具
主要用于去除连续的重复行
注意:是连续的行,所以通常和sort结合使用先排序使之变成连续的行再执行去重操作,否则不连续的重复行他不能去重
uniq [选项] 参数
| 常用选项 | |
| -c | 对重复的行进行计数 |
| -d | 仅显示重复行 |
| -u | 仅显示出现一次的行 |
案例
统计重复行的次数,不连续的重复行他不算做重复行
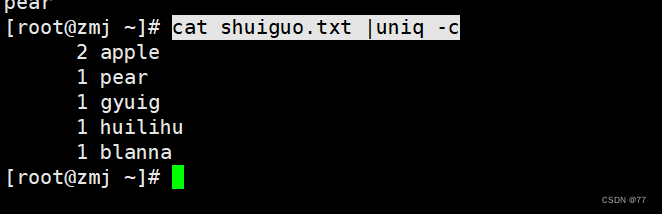
结合sort Order sorting to remove duplicates
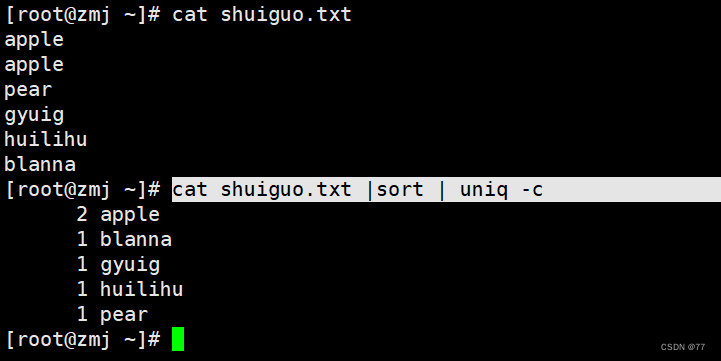
结合sort使用,过滤出重复行 (结合catSee above)

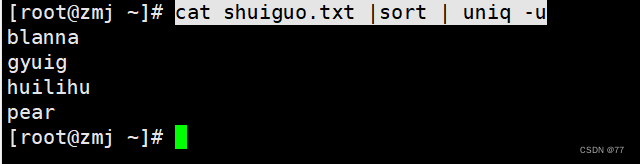
过滤出不重复的行
查看登陆用户
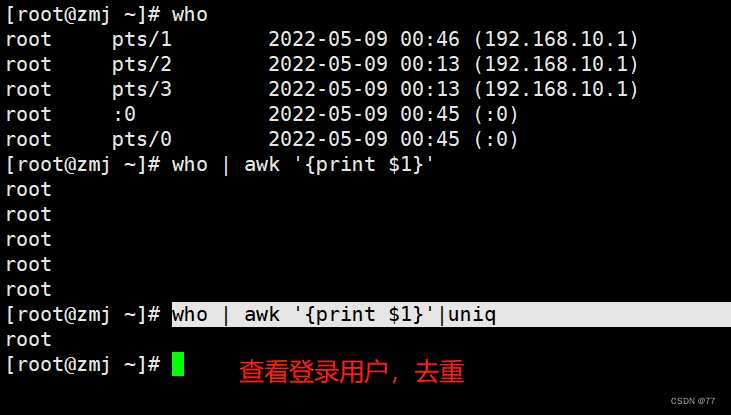
查看登陆过系统的用户

tr 修改工具
它可以用一个字符来替换另一个字符,或者可以完全除去一些字符,也可以用它来除去重复字符
语法 tr [选项] .. SET1 [SET2]
从标准输入中替换、缩减和/或删除字符,并将结果写到标准输出.
| 常用选项 | |
| -d | 删除字符 |
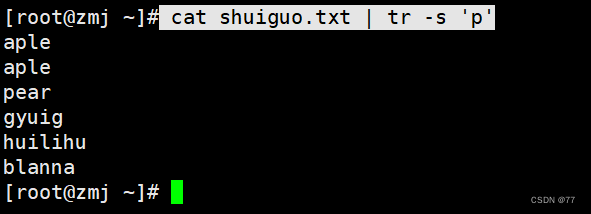
| -s | 删除所有重复出现的字符,只保留第一个 |
将所有小写改成大写
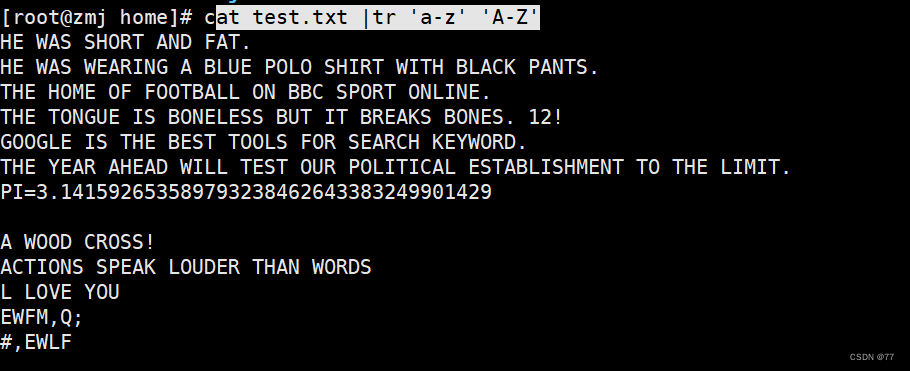
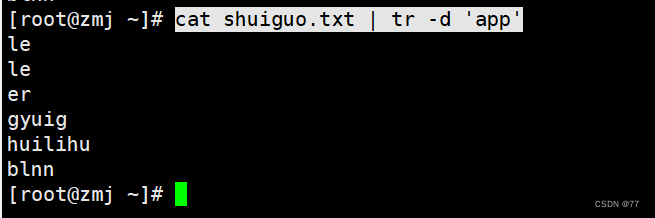
When the number of characters is not equal,相同字符只识别后一个,剩下未对应的全是最后替换字符
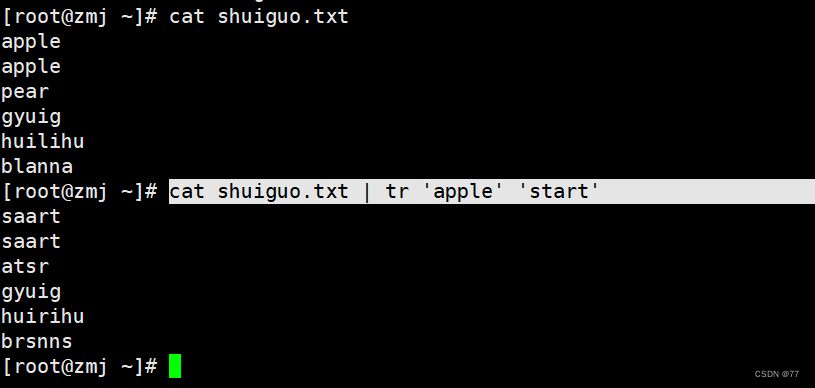
即a-s p-a(ppSame goes for the latter onea) le-r
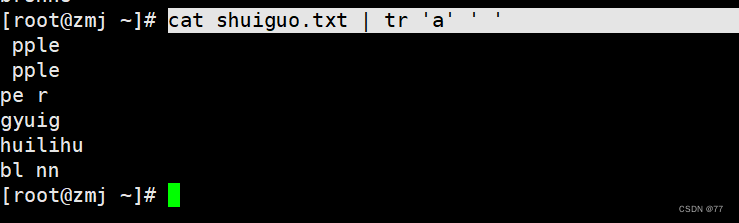
把替换的字符用单引号引起来,包括特殊字符
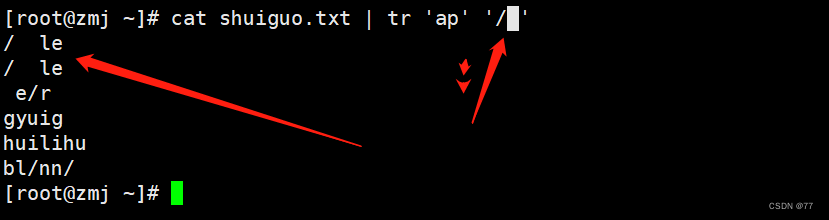
多个字符替换成一个/
删除字符a
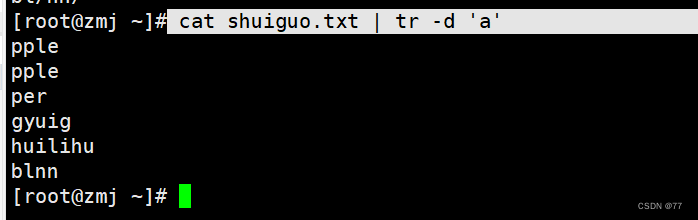
delete all charactersappl
对p字符去重,只保留第一个
查看登陆ip和使用者个数

View the number of clients and listening servers

总结
This article mainly describes the usage of basic regular expression metacharacters and the usage of extended regular expression metacharacters,还有grepHow to use the command and some parameters and cases,There are also some examples of common methods used by text processors(cut、sort、uniq、tr)
边栏推荐
- TCL:事务的特点,语法,测试例——《mysql 从入门到内卷再到入土》
- 找的笔试题的复盘(一)
- 流程控制结构——《mysql 从入门到内卷再到入土》
- C. Rotation Matching
- Live Classroom System 08 Supplement - Tencent Cloud Object Storage and Course Classification Management
- 2021 GKCTF X DASCTF应急挑战杯
- 为什么一般公司面试结束后会说「回去等消息」,而不是直接告诉面试者结果?
- C. Even Picture
- Redis Command Manual
- 3D model reconstruction of UAV images based on motion structure restoration method based on Pix4Dmapper
猜你喜欢
Using SylixOS virtual serial port, serial port free implementation system

C. Even Picture
直播课堂系统09--腾讯云点播管理模块(一)

快消品行业经销商协同系统:实现经销商可视化管理,提高沟通执行效率

财务年报怎样翻译,为什么要选择专业翻译公司?
【SQL刷题】Day3----SQL必会的常用函数专项练习
【Maui正式版】创建可跨平台的Maui程序,以及有关依赖注入、MVVM双向绑定的实现和演示

TCL:事务的特点,语法,测试例——《mysql 从入门到内卷再到入土》
阿里巴巴、蚂蚁集团推出分布式数据库 OceanBase 4.0,单机部署性能超 MySQL
【Windows】你不能访问此共享文件夹,因为你组织的安全策略阻止未经身份验证的来宾访问,这些策略可帮助保护你的电脑
随机推荐
Redis Command Manual
黑猫带你学Makefile第12篇:常见Makefile问题汇总
【实用软件】【VSCode】使用技巧大全(持续更新)
微擎盲盒交友变现-vp_ph打开慢优化
ACM模板笔记:最长不下降/上升子序列
These must-know JVM knowledge, I have sorted it out with a mind map
ENVI感兴趣区ROI文件由XML格式转为ROI格式
每次打开chrome会跳出What's new
Mark!画出漂亮的神经网络图!神经网络可视化工具集锦搜集
异常的了解
黑猫带你学Makefile第11篇:当头文件a.h改变时,如何将所有依赖头文件a.h的.c文件都重新编译
函数:函数删除操作语法&使用例——《mysql 从入门到内卷再到入土》
RADIUS Authentication Server Deployment Costs That Administrators Must Know
LeetCode每日一题(1573. Number of Ways to Split a String)
ACM模板笔记:八数码问题——使用BFS+康托展开打表解决
数字化转型:如何引导创新领导者
第五届“强网杯”全国网络安全挑战赛(线上赛)
labelme-5.0.1版本编辑多边形闪退
C. Rotation Matching
C. Even Picture