当前位置:网站首页>pytorch widedeep文档
pytorch widedeep文档
2022-08-09 10:28:00 【白十月】
某一列取值的计数
value_counts( )函数
value_counts()是一种查看表格某列中有多少个不同值的快捷方法,并计算每个不同值有在该列中有多少重复值。
value_counts(values,sort=True, ascending=False, normalize=False,bins=None,dropna=True)
data['Unit Name'].value_counts()
参数设置
sort=True: 是否要进行排序;默认进行排序
ascending=False: 默认降序排列;
normalize=False: 是否要对计算结果进行标准化并显示标准化后的结果,默认是False。
bins=None: 可以自定义分组区间,默认是否;
dropna=True:是否删除缺失值nan,默认删除
特征工程
category_encoders
category_encoders是一个离散型编码的Python库,里面封装了十几种(包括文中的所有方法)对于离散型特征的编码方法,接口接近于Sklearn通用接口,非常实用。
参考链接:https://blog.csdn.net/sinat_26917383/article/details/107851162
参考链接:https://zhuanlan.zhihu.com/p/119093636
Ordinal Encoding 序数编码
序数编码将类别变量转化为一列序数变量,包含从1到类别数量之间的整数
缺点:它随机的给特征排序了,会给这个特征增加不存在的顺序关系
from category_encoders import OrdinalEncoder
数据集划分
from sklearn.model_selection import train_test_split
df_train, df_test = train_test_split(df, test_size=0.2, stratify=df.income_label)
random_()
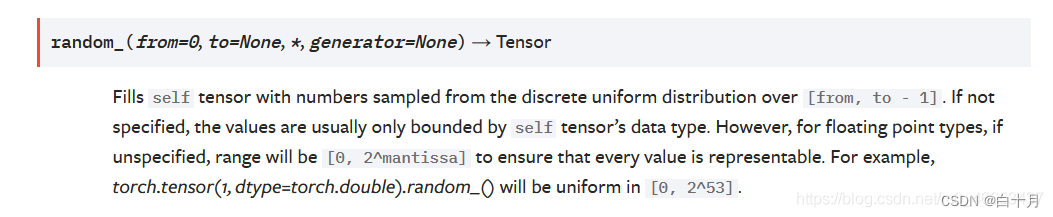
random_(from=0, to=None, *, generator=None) → Tensor
用一个离散均匀分布[from, to - 1]来填充当前自身张量.
数据集处理
WidePreprocessor
pytorch_widedeep.preprocessing.WidePreprocessor(wide_cols, crossed_cols=None)
1.参数设置:
wide_cols (List)
crossed_cols (List, default = None)
2.attributes:
wide_crossed_cols (List) – 列出将使用标签编码的所有列的名称
encoding_dict (Dict) – 字典,其中键是粘贴colname++列值的结果,值是对应的映射整数。
wide_dim (int) – 宽模型的尺寸(即线性层的dim) (i.e. dim of the linear layer)
3.函数:
fit(df)
Fits the Preprocessor and creates required attributes
Return 为BasePreprocessor
transform(df)
Returns the processed dataframe
Return 为ndarray
inverse_transform(encoded) 将transform方法的输出作为输入,它将返回原始值。
Return 为DataFrame
fit_transform(df) 结合fit 和 transform
Return 为ndarray
wide and deep
wide部分:线性模型
根据业务先验知识和特征工程方法,可以判断模型和此类特征强线性相关。
对一些one-hot特征需要进行特征组合。
deep部分:DNN
1 连续特征,如:用户年龄、装机的app数量,注意这些连续特征也要做无量纲化(特征工程链接https://zhuanlan.zhihu.com/p/245178672),Google在这个模型里将连续特征缩放到[0,1] 之间。
2 类别(one-hot)特征,这些特征需要经过embedding,其中特征从左到右、embeding的维度从10到100依次增大。
联合部分:
可以分别训练wide模型和deep模型,然后将它们组合在一起,看看wide&deep在一起的情况下精确度表现如何。
训练过程
Wide部分采用Ftrl+L1正则化训练,目的是为了让Wide部分参数稀疏化,可以回忆下Wide部分的特征,user_installed_app&impression_app,假设应用的数量有100万,那么总参数数量有1万亿!,模型将会非常庞大,而且考虑到训练数据也很稀疏,可以采用这个优化器方法进行训练减少模型参数。
Deep部分采用场景深度网络训练优化器如SGD或者Adam都成。
TabPreprocessor
pytorch_widedeep.preprocessing.TabPreprocessor(cat_embed_cols=None, continuous_cols=None, scale=True, auto_embed_dim=True, embedding_rule='fastai_new', default_embed_dim=16, already_standard=None, with_attention=False, with_cls_token=False, shared_embed=False, verbose=1)
1.参数设置
cat_embed_cols (List, default = None):包含将由嵌入表示的类别列的名称的列表(例如[education, relationship,])或包含名称和嵌入维度的元组(例如:[(education,32),(relationship,16),])
continuous_cols (List, default = None):用continuous 的col的名称列出
2.属性:
3.函数:
模型训练
wide部分
pytorch_widedeep.models.tabular.linear.wide.Wide(input_dim, pred_dim=1)
1.参数设置:
input_dim (int) :嵌入层的大小。输入dim是通过宽模型的所有特征的所有单独值的总和。例如,如果宽模型接收到2个特征,每个特征有5个单独的值,输入dim = 10
pred_dim (int, default = 1) :包含预测的输出张量的大小。注意,与所有其他模型不同的是,当用于构建一个wide和Deep模型时,wide模型是直接连接到输出神经元的。因此需要使用pred dim参数。
2.属性:
wide_linear 包含模型wide分支的线性层
3.examples
import torch
from pytorch_widedeep.models import Wide
X = torch.empty(4, 4).random_(6)
wide = Wide(input_dim=X.unique().size(0), pred_dim=1)
out = wide(X)
deep部分
TabMlp
pytorch_widedeep.models.tabular.mlp.tab_mlp.TabMlp(column_idx, cat_embed_input=None, cat_embed_dropout=0.1, use_cat_bias=False, cat_embed_activation=None, continuous_cols=None, cont_norm_layer='batchnorm', embed_continuous=False, cont_embed_dim=32, cont_embed_dropout=0.1, use_cont_bias=True, cont_embed_activation=None, mlp_hidden_dims=[200, 100], mlp_activation='relu', mlp_dropout=0.1, mlp_batchnorm=False, mlp_batchnorm_last=False, mlp_linear_first=False)
Wide & Deep model的 deeptabular 部分,
1.参数设置:
2.属性:
3.examples
ContextAttentionMLP
1.参数设置:
2.属性:
3.examples
SelfAttentionMLP
1.参数设置:
2.属性:
3.examples
TabResnet
1.参数设置:
2.属性:
3.examples
TabNet
1.参数设置:
2.属性:
3.examples
TabTransformer
1.参数设置:
2.属性:
3.examples
SAINT
1.参数设置:
2.属性:
3.examples
FTTransformer
1.参数设置:
2.属性:
3.examples
TabPerceiver
1.参数设置:
2.属性:
3.examples
TabFastFormer
1.参数设置:
2.属性:
3.examples
边栏推荐
猜你喜欢
笔记本电脑使用常见问题,持续更新
ESIM(Enhanced Sequential Inference Model)- 模型详解
antd表单
Demand side power load forecasting (Matlab code implementation)
编解码(seq2seq)+注意机制(attention) 详细讲解

3D打印了这个杜邦线理线神器,从此桌面再也不乱了
Electron application development best practices

使用.NET简单实现一个Redis的高性能克隆版(四、五)

基于信号量与环形队列实现读写异步缓存队列

拿下跨界C1轮投资,本土Tier 1高阶智能驾驶系统迅速“出圈”
随机推荐
unix环境编程 第十五章 15.5FIFO
KMP& sunday
10000以内素数表(代码块)
Technology Sharing | Sending Requests Using cURL
机器学习-逻辑回归(logistics regression)
[贴装专题] 贴装流程中涉及到的位置关系计算
阿里神作!吃透这份资料入厂率高达99%
RTP
笔记本电脑使用常见问题,持续更新
unix系统编程 第十五章 15.2管道
1: bubble sort
WUSTOJ:n个素数构成等差数列
Throwing a question? The execution speed of the Count operation in the Mysql environment is very slow. You need to manually add an index to the primary key---MySql optimization 001
Redis + NodeJS 实现一个能处理海量数据的异步任务队列系统
libavcodec.dll导致游戏不能运行及explorer关闭
tuple dictionary collection
Demand side power load forecasting (Matlab code implementation)
Win32控件--------------------WM_DRAWITEM消息测试程序
MySQL执行过程及执行顺序
【报错记录】解决华擎J3455-ITX不插显示器无法开机的问题