当前位置:网站首页>梅科尔工作室——BP神经网络
梅科尔工作室——BP神经网络
2022-08-11 06:03:00 【波澜不惊!】
预备知识
感知机
感知机是作为神经网络(深度学习)的起源的算法。学习感知机的构造也就是学习神经网络和深度学习的一种重要思想。
什么是感知机
感知机接受多个输入信号,输出一个信号。像电流流过导线,向前方输送电子一样,感知机的信号也会形成流,向前方输送信息。
X 1、X 2是输入信号,y是输出信号,w 1、w 2是权重,o是“神经元”或者叫做节点,输入信号被送往神经元时,会被分别乘以固定的权重,也叫加权求和,神经元会计算传送过来的信号的总和
什么是BP神经网络
BP(BackPropagation) 算法是神经网络深度学习中最重要的算法之一,是一种按照误差逆向传播算法训练的多层前馈神经网络,是应用最广泛的神经网络模型之。了解BP算法可以让我们更深入理解神经网络深度学习模型训练的本质。
BP算法的核心思想是: 学习过程由信号的正向传播和误差的反向传播两个过程组成。
正向传播: 输入层的神经元负责接受外界发来的各种信息,并将信息传递给中间层神经元,中间隐含层神经元负责将接收到的信息进行处理变换,根据需求处理信息,实际应用中可将中间隐含层设置为一层或者多层隐含层结构,并通过最后一层的隐含层信息将信息传递到输出层,这个过程就是BP神经网络的正向传播过程。
反向传播: 当实际输出与理想输出之间的误差超过期望时,就需要进入误差的反向传播过程。它首先从输出层开始,误差按照梯度下降的方法对各层权值进行修正,并依次向隐含层、输入层传播。通过不断的信息正向传播和误差的反向传播,各层权值会不断进行调整,这就是神经网络的学习训练。当输出的误差减小到期望程度或者预先设定的学习迭代次数时,训练结束,BP神经网络完成学习。
如果隐含层中的神经元节点设置过少,结果可能会造成神经网络的训练过程收敛变慢或者不收敛。如果隐含层中节点过多,模型的预测精度会提高,但同时网络拓扑结构过大,收敛速度慢,普遍性会减弱。
隐藏神经元的设置方法:
如果BP神经网络中输入层节点数为m个,输出层节点为n个,则由下式可推出隐藏层节数为s个。其中b一般为1-9的整数。
s = m + n + b s=\sqrt{m+n}+b s=m+n+b
BP神经网络的推导
第一层是输入层,包含两个神经元i1、i2和截距项b1;第二层是隐含层,包含两个神经元h1、h2和截距项(偏置系数)b2,用于控制神经元被激活的容易程度,第三层是输出o1、o2,每条线上标的wi是层与层之间连接的权重,激活函数我们默认为sigmoid函数。
sigmoid函数: y = 1 1 + e − x y=\frac{1}{1+e^-x} y=1+e−x1
假设现在有五个数字,分别是a=0.8,b=1.5,c=1.2,d=1.9,e=10,它们的关系是a<c<d<b<e。e特别大,有可能是采样采集失误出现的错误数据,经过sigmoid变换,可以看到这几个数据的差异变小了,但大小关系仍然是a<c<d<b<e。sigmoid函数可以在保持数据大小关系不变的情况下是特别大或特别小的数变的普通,这一特性很适用于分类问题和bp网络数据的处理。
损失函数采用均方差: y = 1 N ( t a r g e t − o u t p u t ) 2 y=\frac{1}{N}(target-output)^2 y=N1(target−output)2
向前传播
计算神经元h1的输入加权和:
n e t h 1 = w 1 ∗ i 1 + w 2 ∗ i 2 + b 1 ∗ 1 net_{h1}=w_1 * i_1+w_2 * i_2+b_1 * 1 neth1=w1∗i1+w2∗i2+b1∗1
n e t h 1 = 0.15 ∗ 0.05 + 0.2 ∗ 0.1 + 0.35 ∗ 1 = 0.3775 net_{h1}=0.15 * 0.05+0.2 * 0.1+0.35 * 1=0.3775 neth1=0.15∗0.05+0.2∗0.1+0.35∗1=0.3775
神经元h1的输出o1(此处用到激活函数为sigmoid函数):
o u t h 1 = 1 1 + e − n e t h 1 = 1 1 + e − 0.3775 = 0.593269992 out_h1= \frac{1}{1+e^{-net_{h1}}}=\frac{1}{1+e^{-0.3775}}=0.593269992 outh1=1+e−neth11=1+e−0.37751=0.593269992
同理,可计算出神经元h2的输出o2:
o u t h 2 = 0.596884378 out_{h2}=0.596884378 outh2=0.596884378
计算输出层神经元o1和o2的值:
n e t o 1 = w 5 ∗ o u t h 1 + w 6 ∗ o u t h 2 + b 2 ∗ 1 net_{o1}=w_5 * out_{h1}+w_6 * out_{h2}+b_2 * 1 neto1=w5∗outh1+w6∗outh2+b2∗1
n e t o 1 = 0.4 ∗ 0.593269992 + 0.45 ∗ 0.596884378 + 0.6 ∗ 1 = 1.105905967 net_{o1}=0.4 * 0.593269992+0.45 * 0.596884378+0.6 * 1=1.105905967 neto1=0.4∗0.593269992+0.45∗0.596884378+0.6∗1=1.105905967
n e t o 1 = 1 1 + e − n e t o 1 = 1 1 + e − 1.105905967 = 0.75136507 net_{o1}=\frac{1}{1+e^{-net_{o1}}}=\frac{1}{1+e^{-1.105905967}}=0.75136507 neto1=1+e−neto11=1+e−1.1059059671=0.75136507
o u t o 1 = 0.772928465 out_{o1}=0.772928465 outo1=0.772928465
这样向前传播的过程就结束了,我们得到输出值为【0.75136079,0.772928465】,与实际值【0.01,0.99】相差还很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
反向计算
E t o t a l = ∑ 1 2 ( t a r g e t − o u t p u t ) 2 E_{total}=\displaystyle\sum{\frac{1}{2}(target-output)^2} Etotal=∑21(target−output)2
但是有两个输出,所以分别计算o1和o2的误差,总误差为两者之和:
E o 1 = 1 2 ( t a r g e t − o u t o 1 ) 2 = 1 2 ( 0.01 − 0.75136507 ) 2 = 0.274811083 E_{o1}=\frac{1}{2}(target-out_{o1})^2=\frac{1}{2}(0.01-0.75136507)^2=0.274811083 Eo1=21(target−outo1)2=21(0.01−0.75136507)2=0.274811083
E o 2 = 0.23560026 E_{o2}=0.23560026 Eo2=0.23560026
E t o t a l = E o 1 + E o 2 = 0.274811083 + 0.0235560026 = 0.298371109 E_{total}=E_{o1}+E_{o2}=0.274811083+0.0235560026=0.298371109 Etotal=Eo1+Eo2=0.274811083+0.0235560026=0.298371109
以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出(链式法则):
δ E t o t a l δ w 5 = δ E t o t a l δ o u t o 1 ∗ δ o u t o 1 δ n e t o 1 ∗ δ n e t o 1 δ w 5 \frac{ {\delta}E_{total}}{ {\delta}w_5}=\frac{ {\delta}E_{total}}{ {\delta}out_{o1}} * \frac{ {\delta}out_{o1}}{ {\delta}net_{o1}} * \frac{ {\delta}net_{o1}}{ {\delta}w_5} δw5δEtotal=δouto1δEtotal∗δneto1δouto1∗δw5δneto1
计算 δ E t o t a l δ o u t o 1 \frac{ {\delta}E_{total}}{ {\delta}out_o1} δouto1δEtotal
E t o t a l = 1 2 ( t a r g e t o 1 − o u t o 1 ) 2 + 1 2 ( t a r g e t o 2 − o u t o 2 ) 2 E_{total}=\frac{1}{2}(target_{o1}-out_{o1})^2+\frac{1}{2}(target_{o2}-out_{o2})^2 Etotal=21(targeto1−outo1)2+21(targeto2−outo2)2
δ E t o t a l δ o u t o 1 = 2 ∗ 1 2 ( t a r g e t o 1 − o u t o 1 ) 2 − 1 ∗ − 1 + 0 \frac{ {\delta}E_{total}}{ {\delta}out_{o1}}=2 * \frac{1}{2}(target_{o1}-out_{o1})^{2-1} * -1 + 0 δouto1δEtotal=2∗21(targeto1−outo1)2−1∗−1+0
δ E t o t a l δ o u t o 1 = − ( t a r g e t o 1 − o u t o 1 ) = − ( 0.01 − 0.75136507 ) = 0.74136507 \frac{ {\delta}E_{total}}{ {\delta}out_{o1}}=-(target_{o1}-out_{o1})=-(0.01-0.75136507)=0.74136507 δouto1δEtotal=−(targeto1−outo1)=−(0.01−0.75136507)=0.74136507
计算 δ E t o t a l δ n e t o 1 \frac{ {\delta}E_{total}}{ {\delta}net_o1} δneto1δEtotal
sigmoid函数对x求导
f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x}} f(x)=1+e−x1
d f ( x ) d x = e − x ( 1 + e − x ) 2 = 1 1 + e − x ∗ e − x 1 + e − x = f ( x ) ( 1 − f ( x ) ) \frac{df(x)}{dx}=\frac{e^{-x}}{(1+e^{-x})^2}=\frac{1}{1+e^{-x}} * \frac{e^{-x}}{1+e^{-x}}=f(x)(1-f(x)) dxdf(x)=(1+e−x)2e−x=1+e−x1∗1+e−xe−x=f(x)(1−f(x))
o u t o 1 = 1 1 + e − n e t o 1 out_{o1}=\frac{1}{1+e^{-net_{o1}}} outo1=1+e−neto11
δ o u t o 1 δ n e t o 1 = o u t o 1 ( 1 − o u t o 1 ) = 0.75136507 ( 1 − 0.75136507 ) = 0.186815602 \frac{ {\delta}out_{o1}}{ {\delta}net_{o1}}=out_{o1}(1-out_{o1})=0.75136507(1-0.75136507)=0.186815602 δneto1δouto1=outo1(1−outo1)=0.75136507(1−0.75136507)=0.186815602
计算 δ n e t o 1 δ w 5 \frac{ {\delta}net_{o1}}{ {\delta}w_5} δw5δneto1
n e t o 1 = w 5 ∗ o u t h 1 + w 6 ∗ o u t h 2 + b 2 ∗ 1 net_{o1}=w_5 * out_{h1} + w_6 * out_{h2} + b_2 * 1 neto1=w5∗outh1+w6∗outh2+b2∗1
δ n e t o 1 δ w 5 = 1 ∗ o u t h 1 + w 5 ( 1 − 1 ) + 0 + 0 = o u t h 1 = 0.593269992 \frac{ {\delta}net_{o1}}{ {\delta}w_5} = 1 * out_{h1} + w^{(1-1)}_5+0+0=out_{h1}=0.593269992 δw5δneto1=1∗outh1+w5(1−1)+0+0=outh1=0.593269992
计算 δ E t o t a l δ w 5 \frac{ {\delta}E_{total}}{ {\delta}w_5} δw5δEtotal
δ E t o t a l δ w 5 = δ E t o t a l δ o u t o 1 ∗ δ o u t o 1 δ n e t o 1 ∗ δ n e t o 1 δ w 5 \frac{ {\delta}E_{total}}{ {\delta}w_5}=\frac{ {\delta}E_{total}}{ {\delta}out_{o1}} * \frac{ {\delta}out_{o1}}{ {\delta}net_{o1}} * \frac{ {\delta}net_{o1}}{ {\delta}w_{5}} δw5δEtotal=δouto1δEtotal∗δneto1δouto1∗δw5δneto1
δ E t o t a l δ w 5 = 0.74136507 ∗ 0.186815602 ∗ 0.593269992 = 0.082167041 \frac{ {\delta}E_{total}}{ {\delta}w_{5}}=0.74136507 * 0.186815602 * 0.593269992=0.082167041 δw5δEtotal=0.74136507∗0.186815602∗0.593269992=0.082167041
这样我们就计算出整体误差E(total)对w5的偏导值。
最后我们来更新w5的值
w 5 + = w 5 − η ∗ δ E t o t a l δ w 5 = 0.4 − 0.5 ∗ 0.082167041 = 0.35891648 w^+_5=w_5-\eta * \frac{ {\delta}E_{total}}{ {\delta}w_{5}}=0.4-0.5 * 0.082167041=0.35891648 w5+=w5−η∗δw5δEtotal=0.4−0.5∗0.082167041=0.35891648
η \eta η为学习率,设置为0.5,合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。学习率设置太小,结果收敛缓慢;学习率设置太大,结果在最优值附近徘徊,难以收敛,一般选取为0.01-0.8
同理更新其他参数:
w 6 + = 0.408666186 w^+_6=0.408666186 w6+=0.408666186
w 7 + = 0.511301270 w^+_7=0.511301270 w7+=0.511301270
w 8 + = 0.561370121 w^+_8=0.561370121 w8+=0.561370121
计算 ∂ E t o t a l ∂ o u t h 1 \frac{ {\partial}E_{total}}{ {\partial}out_{h1}} ∂outh1∂Etotal
先计算 ∂ E o 1 ∂ o u t h 1 \frac{ {\partial}E_{o1}}{ {\partial}out_{h1}} ∂outh1∂Eo1
同理,计算出:
两者相加得到总值:
再计算 ∂ o u t h 1 ∂ n e t h 1 \frac{ {\partial}out_{h1}}{ {\partial}net_{h1}} ∂neth1∂outh1
再计算 ∂ n e t h 1 ∂ w 1 \frac{ {\partial}net_{h1}}{ {\partial}w_{1}} ∂w1∂neth1
计算 ∂ E t o t a l ∂ w 1 \frac{ {\partial}E_{total}}{ {\partial}w_{1}} ∂w1∂Etotal
最后,更新 w 1 w_1 w1的权值
同理,更新 w 2 、 w 3 、 w 4 w_2、w_3、w_4 w2、w3、w4的权值
把更新的权值重新进行计算,在这次迭代中,总误差 E ( t o t a l ) E(total) E(total)由0.298371109下降至0.291027924。迭代10000次后,总误差为0.000035085,输出为【0.015912196,0.984065734】(原输入为【0.01,0.99】)
训练到什么时候结束
- 设置最大迭代次数,比如使用数据集迭代100次后停止训练
- 计算训练集在网络上的预测准确率,达到一定门限值后停止训练
Written with StackEdit中文版.
边栏推荐
猜你喜欢
Douyin API interface
Daily sql--statistics the total salary of employees in the past three months (excluding the latest month)
When MySQL uses GROUP BY to group the query, the SELECT query field contains non-grouping fields

亚马逊API接口大全
姿态解算-陀螺仪+欧拉法
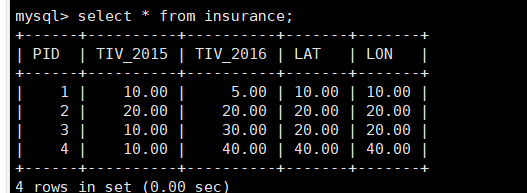
每日sql-求2016年成功的投资总和
详解BLEU的原理和计算

Daily sql-statistics of the number of professionals (including the number of professionals is 0)

radix-4 FFT principle and C language code implementation
Taobao sku API interface (PHP example)
随机推荐
软件测试基本流程有哪些?北京专业第三方软件检测机构安利
每日sql-求2016年成功的投资总和
SQL sliding window
NTT的Another Me技术助力创造歌舞伎演员中村狮童的数字孪生体,将在 “Cho Kabuki 2022 Powered by NTT”舞台剧中首次亮相
抖音关键词搜索商品-API工具
淘宝API接口参考
unable to extend table xxx by 1024 in tablespace xxxx
【推荐系统】:协同过滤和基于内容过滤概述
矩阵分析——Jordan标准形
Go语言实现Etcd服务发现(Etcd & Service Discovery & Go)
HCIP Republish/Routing Policy Experiment
抖音API接口大全
Pinduoduo api interface application example
Taobao sku API interface (PHP example)
Resolved EROR 1064 (42000): You have an error in. your SOL syntax. check the manual that corresponds to yo
【预约观看】Ambire 智能钱包 AMA 活动第四期即将举行
OA project meeting notice (query & whether attending & feedback for details)
JD.com product details API call example explanation
《猪猪1984》NFT 作品集将上线 The Sandbox 市场平台
Redis源码-String:Redis String命令、Redis String存储原理、Redis字符串三种编码类型、Redis String SDS源码解析、Redis String应用场景