当前位置:网站首页>Redis源码-String:Redis String命令、Redis String存储原理、Redis字符串三种编码类型、Redis String SDS源码解析、Redis String应用场景
Redis源码-String:Redis String命令、Redis String存储原理、Redis字符串三种编码类型、Redis String SDS源码解析、Redis String应用场景
2022-08-11 05:50:00 【郝开】
Redis源码-String:Redis String命令、Redis String存储原理、Redis字符串三种编码类型、Redis String SDS源码解析、Redis String应用场景
Redis数据类型
Redis数据类型不等同与数据结构,数据结构是Redis该数据类型存储结构的存储原理,也是该数据类型的底层编码。
1.String存储原理
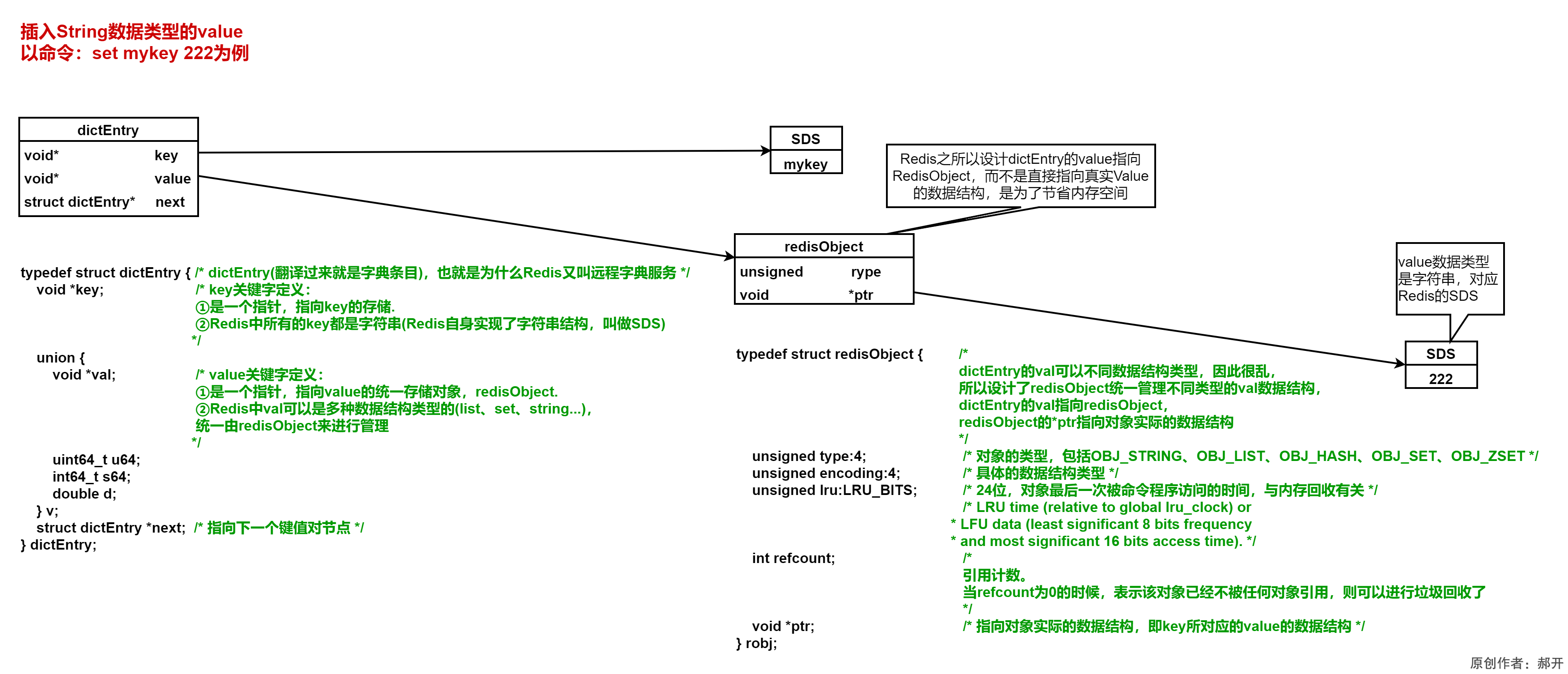
2.Redis-String数据类型:操作命令
新增修改key
# set key value:新增修改key值
127.0.0.1:6379> set mykey 1234567
OK
# get key:获得key值
127.0.0.1:6379> get mykey
"1234"
依据给定key和下标的开始结束值输出值value
# getrange key start end:依据给定key和下标的开始结束值输出值value
# 下标从0开始,如果下标end>String个数,会输出到末尾截至
127.0.0.1:6379> getrange mykey 0 3
"1234"
127.0.0.1:6379> getrange mykey 3 10
"4567"
获得key的value长度
# strlen key:获得key的value长度
127.0.0.1:6379> strlen mykey
(integer) 7
拼接key值
# append mykey abc:拼接key值,返回拼接后的长度
127.0.0.1:6379> append mykey abc
(integer) 10
key不存在,才能成功,分布式锁
# setnx key value:key不存在,才能成功,返回0或1
# 利用该特性:可以用来实现一些竞争性的操作
# 这个命令是redis实现分布式锁的关键
127.0.0.1:6379> setnx mykey 222
(integer) 0
127.0.0.1:6379> get mykey
"1234567abc"
127.0.0.1:6379> setnx mykey2 333
(integer) 1
为key设置过期时间
# expire key seconds:为key设置过期时间,单位秒,返回0或1
# 存在失败的可能性,不建议这样操作,建议在新建key的同时赋予过期时间
127.0.0.1:6379> expire existkey 3
(integer) 0
127.0.0.1:6379> expire mykey 3
(integer) 1
127.0.0.1:6379>
# set key value [EX seconds] [PX milliseconds] [NX|XX]
# EX秒,PX毫秒,以及更精确的时间,指定时间的类型需要为integer,成功返回ok
127.0.0.1:6379> set mykey 222 EX 60
OK
新增修改多个key的值
# mset key value [key value ...]:新增修改多个key的值,成功返回ok
127.0.0.1:6379> mset mykey1 111 mykey2 222 mykey3 333
OK
获取多个key的值
# mget key [key ...]:获取多个key的值
127.0.0.1:6379> mget mykey1 mykey0 mykey3
1) "111"
2) (nil)
3) "333"
对于数字类型(整型、浮点型)的增减、递增减操作
# 对于数字类型(整型、浮点型)的增减、递增减操作:返回的是操作后的值
127.0.0.1:6379> set mykey 22
OK
127.0.0.1:6379> incr mykey
(integer) 23
# incrby key increment:增加指定整型值
127.0.0.1:6379> incrby mykey 100
(integer) 123
127.0.0.1:6379> decr mykey
(integer) 122
127.0.0.1:6379> decrby mykey 100
(integer) 22
# incrbyfloat key increment:增加指定浮点型值
127.0.0.1:6379> incrbyfloat mykey 0.5
"22.5"
查看Redis内部的数据结构类型
当你插入Redis一个字符串数据时,会根据你插入的值,Redis再进行内部的数据转换。
可以先看本文目录:3.存储原理(底层编码)
可以用object encoding key名查看key的value再Redis的内部数据类型。
127.0.0.1:6379> set key1 11
OK
127.0.0.1:6379> set key2 dhasjkkshljashfklsahkjfjkashaskhdlsahjlvnajhjsdaldhasjkhdjashjkdhask
OK
127.0.0.1:6379> set key3 abc
OK
# 查看key在Redis的对外数据类型
127.0.0.1:6379> type key1
string
127.0.0.1:6379> type key2
string
127.0.0.1:6379> type key3
string
# 查看key在Redis的对内数据类型
127.0.0.1:6379> object encoding key1
"int"
127.0.0.1:6379> object encoding key2
"raw"
127.0.0.1:6379> object encoding key3
"embstr"
可以看到Redis对外类型都为String(type命令查看),但是对内的不一样。
3.存储原理(底层编码)
Redis源码:Redis源码怎么查看入门、Redis外部数据结构到Redis内部数据结构查看源码顺序、Redis源码查看顺序
Redis String存储结构:编码类型
Redis String存储结构、Redis字符串的三种编码
Redis字符串存储类型的内部编码有三种:
- int,存储8个字节的长整型(long,2^63-1)
- embstr,embstr格式的SDS,存储小于44个字节的字符串,之前存的一长串字母,一个字母就是一个字节
- raw,raw格式的SDS,存储大于44个字节的字符串
不同编码方式1个英文字母占的字节是不同的,具体如下:
不同编码方式1个英文字母占的字节是不同的,具体如下
1,ASCII码:一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。
2,UTF-8编码:一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。中文标点占三个字节,英文标点占一个字节。
3,Unicode编码:一个英文等于两个字节,一个中文(含繁体)等于两个字节。中文标点占两个字节,英文标点占两个字节。
编码转换问题:int和embstr什么时候转化为raw?
- int数据不再是整数→raw
- int大小超过了long的范围(2^63-1)→embstr
- embstr长度超过了44个字节→raw
编码转换问题:会还原吗?
编码转换在Redis写入数据时完成,且转换过程不可逆,只能从小内存编码向大内存编码转换(不包括重新set),重新set虽然在值上是修改或插入,但在Redis看来是重新赋值,这里的编码转换指的修改比如说拼接字符串、自增这种,非set的改值操作。
embstr和raw的区别
embstr:只分配一次内存空间:RedisObject和SDS连续
raw:需要分配两次内存空间

embstr优点
它将 RedisObject 对象头和 SDS 对象连续存在一起,使用 malloc 方法一次分配,它的计算会更快。
embstr的最小占用空间为19(16+3),而64-19-1(结尾的\0)=44,所以empstr只能容纳44字节。
当字节数小于44时,分配的大小一直都是64个字节。
一旦超过44个字节,整体的大小超过64个字节,
在Redis中将认为是一个大的字符串,不再使用 emdstr 形式存储,存储结构将变为raw。
embstr的缺点
- 如果你的value的长度增加的话,那么RedisObject对象头和SDS对象需要重新分配内存空间,所以Redis设计的embstr是只读的
- 由于embstr是只读的,它的内容是不能修改的,因此一旦修改会使embstr编码直接变成raw编码,即使字节数小于44时
127.0.0.1:6379> set key a
OK
127.0.0.1:6379> object encoding key
"embstr"
127.0.0.1:6379> append key 2
(integer) 2
# 可以看到,append后长度为2,字节数小于44,修改会使embstr编码直接变成raw编码
127.0.0.1:6379> object encoding key
"raw"
sds.h源码文件:Redis自己实现了它的字符串结构
sds.h源码文件在解压后的src目录下
SDS是什么:简单动态字符串
SDS(Simple Dynamic String):简单动态字符串,Redis会根据String类型的value长度,去选择合适的sdshdr数结构来存储这个value,这样的设计可以节省内存空间。

# 换算:
2^10=1024byte=1kb
2^20=1MB
2^30=1GB
2^40=1TB
2^50=1PB
2^60=1EB
sdshdr5:2^5=32byte(不用)
sdshdr8:2^8=256byte
sdshdr16:2^16=65536byte=64kb
sdshdr32:2^32=4GB
sdshdr64:2^64=16EB
Redis的key是字符类型,即String,最大可以用得到是512M,那么它的value字符类型,也是String,最大也是512M。
sdshdr32,sdshdr64定义的这么大,但你未必能用得到全部,这也是Redis预留的一种思想,给你足够多的空间,未来可能就用的到这么大了。
sds.h文件的sdshdr8的源码截取
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
/* 当前字符数组的长度,有这个值使得获取字符长度的复杂度变为O(1),不用向C语言的字符数组那样从头至尾遍历O(N) */
uint8_t alloc; /* excluding the header and null terminator */
/* 当前字符数组总共分配的内存大小 */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
/* 当前字符数组的属性、用来标识到底是sdshdr8还是sdshdr16等 */
char buf[]; /* 字符串真正的值,它是用字符数组来进行存储的 */
};
Redis为什么要用SDS来实现字符串?
C语言里面也是没有字符串的,它有的是字符数组,有以下特点:
- 内存空间预先分配
- 获取字符长度(即字符数组的长度)需要从头到尾先遍历一遍,时间复杂度O(n)
- C语言的字符数组内存分配是固定的,长度变更引起内存重新分配
- 用’\0’判断字符串结束(如果你存的内容恰好包含,也会认为是结束)
所以Redis基于字符数组实现了自己的字符串SDS:简单动态字符串
| C字符数组 | SDS |
|---|---|
| 获取字符长度的复杂度O(N) | 获取字符长度的复杂度O(1),因为SDS中uint8_t len存储当前字符数组的长度 |
| API是不安全的,可能会造成称缓冲区溢出 | API是安全的,不会造成称缓冲区溢出,简单动态字符串可以扩容,而且不需要预先分配,因此不会产生内存溢出 |
| 修改字符长度N次必然需要执行N次内存重新分配 | 修改字符长度N次最多需要执行N次内存重新分配,SDS里面有一个特殊的设计,叫做空间的预分配和惰性的空间释放,不管是获取内存还是释放内存都不是及时的,所以性能会提升 |
| 只能保存文本数据 | 可以保存文本数据或者二进制数据 |
| 可以使用所有<string.h>库中的函数 | 可以使用部分<string.h>库中的函数 |
4.应用场景
- 缓存: 查询、计算过的数据直接放入Redis里面,然后应用直接从Redis中拿数据,而不是再次去数据库查值,既可以提升应用的查询速度,又可以起到保护数据库的作用
- 分布式Session: 在spring和spring boot里面,其实是有一个包,叫spring session,引入之后,会直接将session写入到Redis中,为什么可以实现这个功能呢,因为它是一个基于分布式环境的服务,也就是大家都连接到它,就能够实现数据的共享(Session共享)
- 分布式锁 set NX EX: 如果存在就不成功,以此来实现竞争,同时提供了这个的过期时间,来保证会定时释放锁
- 分布式全局ID incr: 这个其实有很多方法:比如数据库、UUID、雪花算法,而Redis之所以也可以,是因为它的String类型可以存储整型,并且提供了incr、incrby这种增长的设计
- 计数器 incr: 网页访问数、微博点赞数这种实时性不是很高的,可以先存在Redis中,之后在同步给数据库
- 限流 incr: 对于某一个用户、IP在一段时间限制操作次数
- 位操作: 是因为Redis里面它的字符是以8位二进制来存储的
- …
String怎么存储表格式的数据?
使用Redis存储一张表的数据,比如下表student:
| id | name | age |
|---|---|---|
| 12 | aaa | 25 |
| 13 | bbb | 36 |
你使用String数据结构也可以实现:
key特殊处理一下(key前缀+“自定义分隔符”+“表的唯一键约束”+“自定义分隔符”+属性名),然后获取值使用mget来批量获取属性
# 自定义分隔符_:key名(student_12_id:key前缀+"自定义分隔符"+"表的唯一键约束"+"自定义分隔符"+属性名)
127.0.0.1:6379> mset student_12_id 12 student_12_name aaa student_12_age 25
OK
127.0.0.1:6379> mget student_12_id student_12_name student_12_age
1) "12"
2) "aaa"
3) "25"
那么如果这样做很好,还要Hash干嘛?
String这样做,key已经占了很大的存储空间(真实场景你拼接的这个key很长),还有value,有点得不偿失,于是Redis提供了存储表格式的数据类型Hash。
String每个key是单独存储,利用这个特性,因此可以更方便的拆分,所以如果一个key的数据量很大,可以考虑用String来接
Hash 哈希
存储多个无序的键值对,最大存储数量2^32-1(40亿个左右)
Redis本身就是KV存储的,这个存储方式是Redis外层的Hash,那么Hash数据结构存储KV结构的数据,这个叫做Redis内层的Hash。
内层的Hash中的value是不能够再次嵌套其它的数据类型(比如list、set、hash等),它的value只能是String。
String与Hash的区别
Hash特点:
- 节省内存空间: 因为只存一个key
- 减少key冲突: 因为只存一个key
- 取值减少性能消耗: 一次性就可以取出所有属性,不需要用mget命令,或者get向Redis服务端多次交互进行取值
Hash不适合的场景:
- Field不能单独设置过期时间: String可以单独设置过期时间
- 需要考虑数据量分布的问题: 内容是不能拆分的,大数据量的key会使Redis多个节点的内存分布不均衡。比如一个key有10亿个Field,但是一个key只能存储在Redis的一个服务节点上,你想拆成两个5亿的,Hash做不到;而String每个key是单独存储,因此可以更方便的拆分,所以如果一个key的数据量很大,可以考虑用String来接
边栏推荐
- 《Show and Tell: A Neural Image Caption Generator》论文解读
- JD.com product details API call example explanation
- ROS 话题通信理论模型
- HCIP experiments (pap, chap, HDLC, MGRE, RIP)
- 每日sql:求好友申请通过率
- Douyin share password url API tool
- 从 dpdk-20.11 移植 intel E810 百 G 网卡 pmd 驱动到 dpdk-16.04 中
- HCIP OSPF动态路由协议
- 什么是Inductive learning和Transductive learning
- daily sql - query for managers and elections with at least 5 subordinates
猜你喜欢


随机推荐
Taobao API common interface and acquisition method
Pinduoduo api interface application example
My approval of OA project (inquiry & meeting signature)
numpy和tensor增加或删除一个维度
Shell:三剑客之awk
HCIP BGP neighbor building, federation, and aggregation experiments
下一代 无线局域网--强健性
My meeting of the OA project (meeting seating & review)
HCIP experiments (pap, chap, HDLC, MGRE, RIP)
八股文之redis
unable to extend table xxx by 1024 in tablespace xxxx
MySQL01
TOP2两数相加
每日sql-找到每个学校gpa最低的同学(开窗)
unable to extend table xxx by 1024 in tablespace xxxx
姿态解算-陀螺仪+欧拉法
每日sql--统计员工近三个月的总薪水(不包括最新一个月)
Coordinate system in navigation and positioning
强烈推荐一款好用的API接口
已解决EROR 1064 (42000): You have an error in. your SOL syntax. check the manual that corresponds to yo