当前位置:网站首页>本体开发日记03-理解代码
本体开发日记03-理解代码
2022-08-09 09:13:00 【「已注销」】
1.推荐一个宝藏博主
https://blog.csdn.net/javafreely(地球原住民)。
2.代码:https://blog.csdn.net/javafreely/article/details/8432522
3.博主的RDF专栏:https://blog.csdn.net/javafreely/category_1311840.html?spm=1001.2014.3001.5482
要是能有个OWL的就好了!发现大家都是毕设写这个!我OWL完全没搞懂!!!!
1.根据前面引用代码里面的内容,我自己理解了一下这个代码讲了点儿啥!因为好记性不如烂笔头,虽然是打字,但是总觉得还是应该记一下,这样估计记得牢固一点儿!
(1)第一个类Introduction根据原博说明就是简单的jena应用!
参考教材
https://max.book118.com/html/2017/0717/122715588.shtm(这个版本有点儿低,现在应该可以有相关OWL的读写操作了!)
Page4:jena的用途:a)以RDF/XML,三元组形式读写RDF;b)RDFS,OWL,DAML+OIL等本体的操作;c)利用数据库保存数据;d)查询模型;e)基于规则的推理。
ModelFactory 类是一个Model 工厂,用于创建model 对象。我们可以使用 Model 的createResource 方法在model 中创建一个资源,并可以使用资源的 addProperty 方法添加属性。
(2)StatementDemo类:Jena API 解析RDF 的Statement
StmtIterator iter = model.listStatements(); | Model 类的listStatements 返回 Statement | Iterator |
|---|---|---|
Statement stmt = iter.nextStatement(); | 遍历Statement | |
Resource subject = stmt.getSubject(); | 主语 getSubject | Resource |
Property predicate = stmt.getPredicate(); | 谓语 getPredicate | Property |
RDFNode object = stmt.getObject(); | 客体 getObject | RDFNode |
(3)RDFWriting类:输出RDF, Model 的write 方法将其model 中内容写入一个输出流
model.write(System.out); | model.write(OutputStream) | 默认的输出格式 |
|---|---|---|
model.write(System.out, "RDF/XML-ABBREV"); | model.write(OutputStream, “RDF/XML-ABBREV”) | 使用XML 缩略语法输出RDF |
model.write(System.out, "N-TRIPLE"); | model.write(OutputStream, “N-TRIPLE”) | 输出n 元组的格式 |
PS:这部分内容粘贴原博主的内容了!以我的智商是看不太懂了!
(4)RDFReading类:读取已有的RDF文件
InputStream in = FileManager.get().open( inputFileName ); | 使用 FileManager 查找文件 | import org.apache.jena.util.FileManager |
|---|---|---|
model.read(in, null); | 读取RDF/XML 文件 | Model 的read 方法可以读取RDF 输入到model 中。第二个参数可以指定格式。 |
model.write(System.out); |
(5)NSPrefix类:设置Namespace 前缀
String nsA = "http://somewhere/else#"; | ||
|---|---|---|
Resource root = m.createResource( nsA + "root" ); | 调用 Model 的createProperty 和createResource 生成属性和资源 | |
Property P = m.createProperty( nsA + "P" ); | ||
m.add( root, P, x ).add( root, P, y ).add( y, Q, z ); | 调用Model.add 向model 中增加3个Statement | add 的三个参数分别是三元组的主语、谓语和客体 |
m.write( System.out ); | ||
m.setNsPrefix( "nsA", nsA ); | Model的setNsPrefix 函数用于设置名字空间前缀 | 没有为RDF指定namespace前缀,则jena会自动为其生成名为 j.0, j.1的名字空间 |
(6)ModelAccess类:访问RDF Model的信息
Resource vcard = model.getResource(personURI); | 从 Model 获取资源 | Model 的 getResource 方法:该方法根据参数返回一个资源对象。 |
|---|---|---|
Resource name = (Resource) vcard.getProperty(VCARD.N).getObject(); | 获取N 属性的值(用属性的 getObject()方法) | Resource 的 getProperty 方法:根据参数返回一个属性对象。Property 的 getObject 方法:返回属性值。使用时根据实际类型是 Resource 还是 literal 进行强制转换。 |
Resource name = vcard.getProperty(VCARD.N).getResource(); | 如果知道属性的值是资源,可以使用属性的getResource 方法 | Property 的 getResource 方法:返回属性值的资源。如果属性值不是Resource,则报错。 |
fullName = vcard.getProperty(VCARD.FN).getString(); | 属性的值若是 literal,则使用 getString 方法 | Property 的 getString 方法:返回属性值的文本内容。如果属性值不是文本,则报错。 |
vcard.addProperty(VCARD.NICKNAME, "Smithy").addProperty(VCARD.NICKNAME, "Adman"); | 增加两个 NICKNAME 属性 | |
StmtIterator iter = vcard.listProperties(VCARD.NICKNAME); | 列出两个NICKNAME 属性,使用资源的 listProperties 方法 | Resource 的 listProperties 方法:列出所找到符合条件的属性。 |
(7)RDFQuery类&RDFQuery1类
model.read(in, null); | 读 |
|---|---|
ResIterator iter = model.listResourcesWithProperty(VCARD.FN); | Model.listSubjectsWithProperty(Property p, RDFNode o): 列出所有具有属性p且其值为o的资源。 |
System.out.println(" "+iter.nextResource().getProperty(VCARD.FN).getString()); | |
StmtIterator iter = model.listStatements(new SimpleSelector(null, VCARD.FN, (RDFNode)null)); | Model.listStatements(): 列出Model 所有的Statements。 |
System.out.println(" "+iter.nextStatement().getString()); | |
| Model.listSubjects(): 列出所有具有属性的资源。 | |
Model.listStatements(Selector s) | Selector selector = new SimpleSelector(subject, predicate, object)。这个选择器选择所有主语符合 subject、谓语符合 predicate、客体符合 object 的Statement。 |
PS:没看懂!
(8)AddDelete类:对model的增删操作!(我突然发现我忘记什么是model了!)
model.remove(model.listStatements(null, VCARD.N, (RDFNode)null)); | Model.remove 方法可以实现statement 的删除操作 |
|---|---|
model.removeAll(null, VCARD.Given, (RDFNode)null); | |
model.add(johnSmith, VCARD.N, model.createResource().addProperty(VCARD.Given, givenName).addProperty(VCARD.Family, familyName)); | Model.add 可以实现statement 的增加 |
| Model 中的Resource(资源)或Property(属性,实际上也继承自Resource)进行增删操作 |
2.https://max.book118.com/html/2017/0717/122715588.shtm的解读
该教材的版本为Jena2.4。
1)Jena框架包含了一个本体子系统(Ontology Subsystem),它提供的API允许处理基于RDF的本体数据,支持?OWL DAML+OIL RDFS。本体API与推理子系统结合可以从特定本体中提取信息,提供文档管理器支持对导入本体的文档管理。
2)允许将数据存储到硬盘,或者是OWL文件中!(??可以导入到OWL文件中!!)
3)ARQ查询引擎,实现SPARQL查询语言,后面那个RDQL估计我也用不上,就不写了!(写给我自己的!用不到了就不写了!)
4)之前怎么会出错的呢!不是已经写了吗!全部加入CLASSPATH中去!
5)Eclipse的方法
6)我突然又看到了好东西http://jena.apache.org/documentation/ontology/,但是还不行,我得把这个文档看完才行!
7)java类或者接口
- 本体模型OntModel:Jena通过model包中的ModelFactory创建本体模型,该类可创建各种模型,类中定义了具体实现模型的成员以及创建模型的二十多种方法。
OntModel ontModel = ModelFactory.createOntologyModel();使用OWL语言,基于内存,支持RDFS推理;可通过创建时应用模型类别OntModelSpec参数创建不同的模型;OntMode ontModel = ModelFactory.createOntologyModel(OntModelSpec.DAML_MEM);创建了一个使用DAML语言内存本体模型;内存模型就是只在程序运行时存在的模型。- 读取OWL文件的方法:调用jena OntoModel提供的Read方法;
ontModel.read("file:D:/temp/Creature/Creature.owl");(如果这样的话,我要想读取owl文件,岂不是要弄个2.4来用了!);read(String url); read(Reader reader,String base); read(InputStream reader,String base); read(String url,String lang); read(Reader reader,String base,String lang); read(InputStream reader,String base,String lang);。 - 本体文档管理器OntDocumentManager;每个本体模型都有一个相关联的文档管理器;
OntModel m = ModelFactory.createOntologyModel();OntDocumentManager dm = m.getDocumentMananger();创建了一个文档管理器并将它与创建的本体模型关联;
8)Web Ontology Language或OWL:明确表示词汇表中词语的意义以及那些词语之间的关系。与RDF Schema一起,OWL提供了一种正式地描述RDF模型的机制;可定义资源可以属于的层次结构类,允许表达资源的属性特征。Jena中,本体被看作一种特殊类型的RDF模型OntModel,此接口允许程序化地对本体进行操作,使用便利方法创建类、属性限制等等。
9)可将本体看作特殊RDF模型,仅添加定义其语义规则的语句,还可将本体语句添加到现有数据模型中,或使用Model.union()将本体模型与数据模型合并。
//创建一个新的model,创建WordNet的OWL本体模型
OntModel wnOntology = ModelFactory.createOntologyModel();
//使用OntModel的方法
wnOntology.createTransitiveProperty(WordnetVocab.hyponymOf.getURI());
wnOntolgy.add(WordnetVocab.hyponymOf,RDF.type,OWL.TransitiveProperyt);
10)使用Jena推理:给定了本体和模型后,jena的推理引擎可以派生模型未明确表达的其他语句;jena提供了多个Reasoner类型来使用不同类型的本体。
11)将OWL本体与WordNet模型一起使用,所以为OWLReasoner。首先从ReasonerRegistry中获得OWLReasoner---->ReasonerRegistry.getOWLReasoner();下一步将reasoner与WordNet本体绑定,返回的结果为可以应用本体规则的reasoner;然后,使用绑定的reasoner从WordNet模型创建InfModel。
//WordNet的推理模型
ModelMaker maker = ModelFactory.createModelRDBMaker(connection);
Model model = maker.openModel("wordnet-plants",true);
//创建OWL reasoner
Reasoner owlReasoner = ReasonerRegistry.getOWLReasoner();
//绑定reasoner到WordNet本体模型
Reasoner wnReasoner = owlReasoner.bindSchema(wnOntology);
//使用该reasoner创建推理模型
InfModel infModel = ModelFactory.createInfModel(wnReasoner,model);
//设置推理模型
query query.setSource(infModel);
//指定查询
QueryEngine qe = new QueryEngine(query);
QueryResults results = qe.exec(initialBinding);
12)代码清单截图


















PS:这个好像过时了!因为是2.4版本,我现在都用4的版本了!刚才突然发生了一件事情,把我心情整不好了!
边栏推荐
- Difference: char* and char[]
- Onnx - environment build 】 【 tensorrt
- MySQL lock
- 多维度LSTM(长短期记忆)神经网络预测未来存款余额走势
- Venture DAO Industry Research Report: Macro and Classic Case Analysis, Model Summary, Future Suggestions
- MySQL Leak Detection and Filling (3) Calculated Fields
- 算术表达式求值演示
- 上帝视角看高清村庄卫星地图,附下载高清卫星地图最新方法
- 智慧图书馆的导航方案-定位导航导览-只用一个方案全部实现
- gin清晰简化版curd接口例子
猜你喜欢
【场景化解决方案】OA审批与用友U9数据集成

MySQL索引

微信小程序转支付宝小程序注意事项
【场景化解决方案】构建门店通讯录,“门店通”实现零售门店标准化运营
The era of Google Maps is over, how to view high-definition satellite image maps?
公司从零开发微信小程序流程
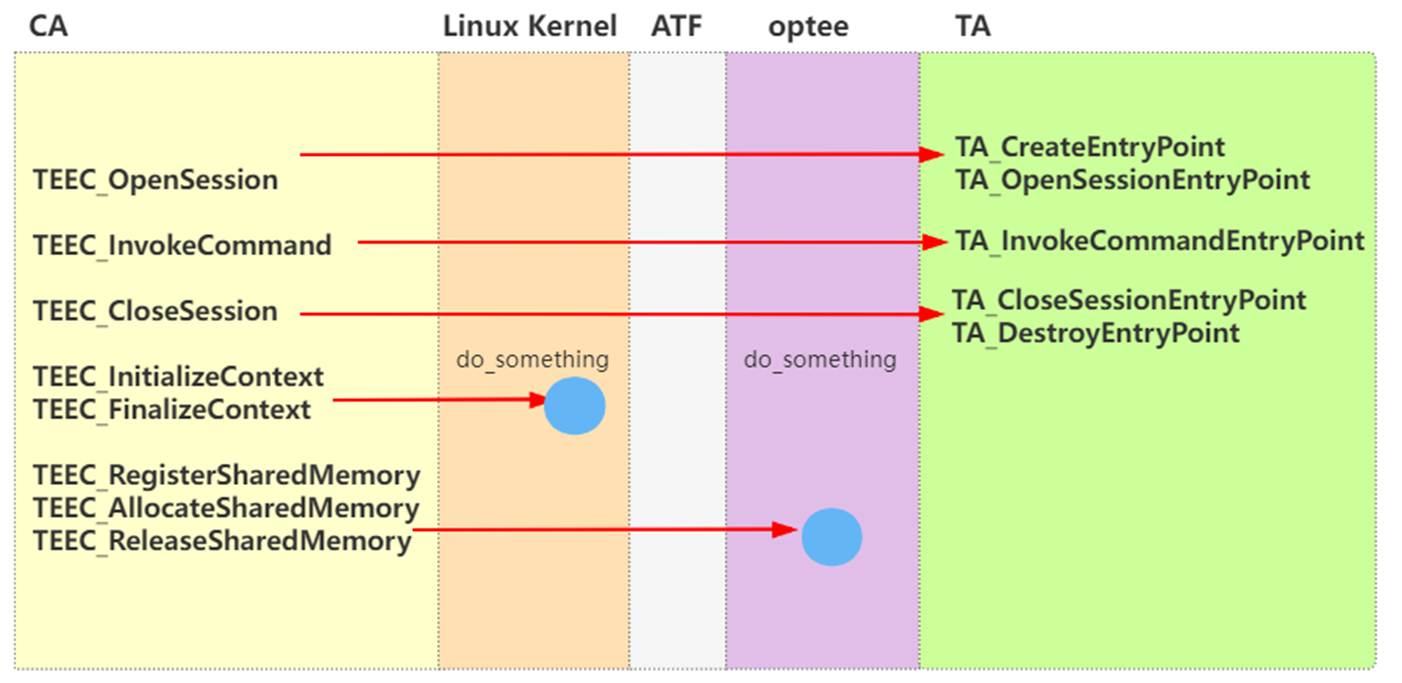
【培训课程专用】CA/TA调用模型-代码导读
Global 19 Google Satellite Map Free View Download
Read file by byte and character_load configuration file
These 12 GIS software are better than the other
随机推荐
Jfinal loading configuration file principle
法院3D导航系统-轻松实现室内实时定位导航
MySQL transaction isolation
使用图新地球无法加载谷歌地球的完美解决方法(附软件下载)
.net 控件calendar 基础用法
上帝视角看高清村庄卫星地图,附下载高清卫星地图最新方法
mysql进阶(三十一)常用命令汇总
Module模块化编程的优点有哪些
gin中改进版curd接口例子
历史遗留问题
location.href用法
js实现看板全屏功能
Django实现对数据库数据增删改查(一)
fastadmin图片上传方法改造
JS报错-Uncaught TypeError: 'caller', 'callee', and 'arguments' properties may not be accessed on...
往二维数组追加键值
代码导读-目录
数据库期末复习这一篇就够了(期末预习大概也行)
大学四年不努力,出社会后浑浑噩噩深感无力,辞去工作,从头开始
js在for循环中按照顺序响应请求