当前位置:网站首页>多维度LSTM(长短期记忆)神经网络预测未来存款余额走势
多维度LSTM(长短期记忆)神经网络预测未来存款余额走势
2022-08-09 08:58:00 【寻找手艺人】
多维度LSTM(长短期记忆)神经网络预测未来客户活期存款余额
''' Created on 2020年10月26日 @author: 寻找手艺人 '''
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential # Sequential 用于初始化神经网络
from keras.layers import Dense # Dense 用于添加全连接的神经网络层
from keras.layers import LSTM # LSTM 用于添加长短期内存层
from keras.layers import Dropout # Dropout 用于添加防止过拟合的dropout层
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 构建训练数据
def train_data():
dataset_train = pd.read_excel('alive_data.xlsx', parse_dates=['date'])
training_set = dataset_train.iloc[:, 1:7].values
dataset_train.head()
sc = MinMaxScaler(feature_range=(0, 1))
training_set_scaled = sc.fit_transform(training_set)
X_train = []
y_train = []
for i in range(60, len(training_set_scaled)):
X_train.append(training_set_scaled[i - 60:i, :])
y_train.append(training_set_scaled[i, :])
X_train, y_train = np.array(X_train), np.array(y_train)
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 6))
return X_train, y_train, dataset_train, sc
# 构建测试数据
def test_data(dataset_train, sc):
df = pd.read_excel('alive_data.xlsx', parse_dates=['date'])
dataset_test = df[(df['date'] >= '2020-10-10')].loc[:,['first6', 'birthday', 'last4', 'gender', 'age', 'alive_amt']]
real_stock_price = dataset_test['alive_amt'].values
# 合并训练集和测试集
dataset_total = pd.concat((dataset_train, dataset_test), axis=0) db_all = dataset_total.iloc[:, 1:7].values inputs = db_all[len(dataset_total) - len(dataset_test) - 60:] inputs = inputs.reshape(-1, dataset_test.shape[1]) inputs = sc.transform(inputs) X_test = [] for i in range(60, 60 + len(dataset_test)):
X_test.append(inputs[i - 60:i, :])
# X_test.append(inputs[i-60:i, 0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], dataset_test.shape[1]))
return X_test, real_stock_price
# 创建股票预测模型
def stock_model(X_train, y_train):
regressor = Sequential()
# LSTM的输入为 [samples, timesteps, features],这里的timesteps为步数,features为维度 这里我们的数据是6维的
regressor.add(LSTM(units=50, return_sequences=True, input_shape=(X_train.shape[1], 6)))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units=50, return_sequences=True))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units=50, return_sequences=True))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units=50))
regressor.add(Dropout(0.2))
# 全连接,输出6个
regressor.add(Dense(units=6))
regressor.compile(optimizer='adam', loss='mean_squared_error')
regressor.fit(X_train, y_train, epochs=1000, batch_size=32)
return regressor
def main():
X_train, y_train, dataset_train, sc = train_data()
regressor = stock_model(X_train, y_train)
X_test, real_stock_price = test_data(dataset_train, sc)
predicted_stock_price = regressor.predict(X_test)
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
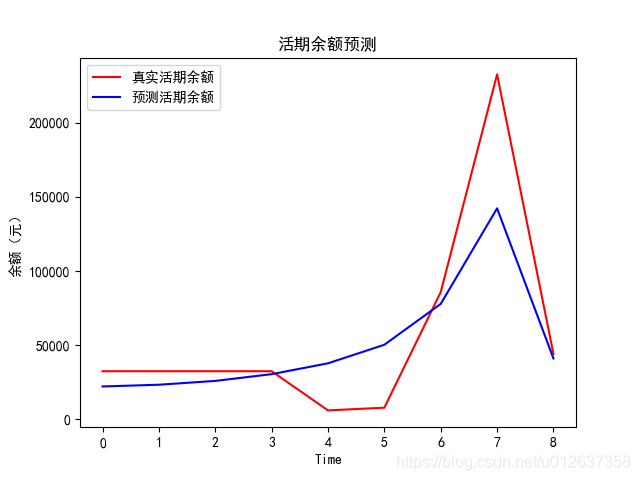
plt.plot(real_stock_price, color='red', label='Real Alive amt')
# 显示活期余额
plt.plot(predicted_stock_price[:, 5], color='green', label='Predicted Alive amt')
plt.title('Alive amt Prediction')
plt.xlabel('Time')
plt.ylabel('Alive amt Price')
plt.legend()
plt.show()
if __name__ == '__main__':
main()
requirements.txt
absl-py==0.10.0
asgiref==3.2.10
astor==0.8.1
astunparse==1.6.3
beautifulsoup4==4.9.1
bs4==0.0.1
cachetools==4.1.1
certifi==2020.6.20
chardet==3.0.4
cycler==0.10.0
Django==3.1.1
django-bootstrap4==2.2.0
et-xmlfile==1.0.1
gast==0.2.2
google-auth==1.22.1
google-auth-oauthlib==0.4.1
google-pasta==0.2.0
grpcio==1.33.1
h5py==2.10.0
idna==2.10
importlib-metadata==1.7.0
jdcal==1.4.1
Jinja2==2.11.2
joblib==0.16.0
Keras==2.3.1
Keras-Applications==1.0.8
Keras-Preprocessing==1.1.2
kiwisolver==1.2.0
lxml==4.5.2
Markdown==3.3.2
MarkupSafe==1.1.1
matplotlib==3.3.2
mpl-finance==0.10.1
mplfinance==0.12.7a0
numpy==1.18.5
oauthlib==3.1.0
openpyxl==3.0.5
opt-einsum==3.3.0
pandas==1.1.3
Pillow==7.2.0
prettytable==0.7.2
protobuf==3.13.0
pyasn1==0.4.8
pyasn1-modules==0.2.8
pyecharts==1.8.1
PyMySQL==0.10.1
pyparsing==2.4.7
python-dateutil==2.8.1
pytz==2020.1
PyYAML==5.3.1
requests==2.24.0
requests-oauthlib==1.3.0
rsa==4.6
scikit-learn==0.23.2
scipy==1.4.1
seaborn==0.11.0
sequential==1.0.0
simplejson==3.17.2
six==1.15.0
soupsieve==2.0.1
sqlparse==0.3.1
tensorboard==2.0.2
tensorboard-plugin-wit==1.7.0
tensorflow==2.0.0
tensorflow-estimator==2.0.1
termcolor==1.1.0
threadpoolctl==2.1.0
tushare==1.2.61
urllib3==1.25.10
websocket-client==0.57.0
Werkzeug==1.0.1
wrapt==1.12.1
xlrd==1.2.0
zipp==3.1.0
边栏推荐
- 医院智能3D蓝牙导航导诊系统
- canvas 文字垂直居中
- leetcode 35. 搜索插入位置(二分法+找性质也很关键)
- Venture DAO 行业研报:宏观和经典案例分析、模式总结、未来建议
- Calendar类和Date类转换时区 && 部分时区城市列表
- parse <compoN> error: Custom Component‘name should be form of my-component, not myComponent or MyCom
- How does STM32 know the usage of FLASH
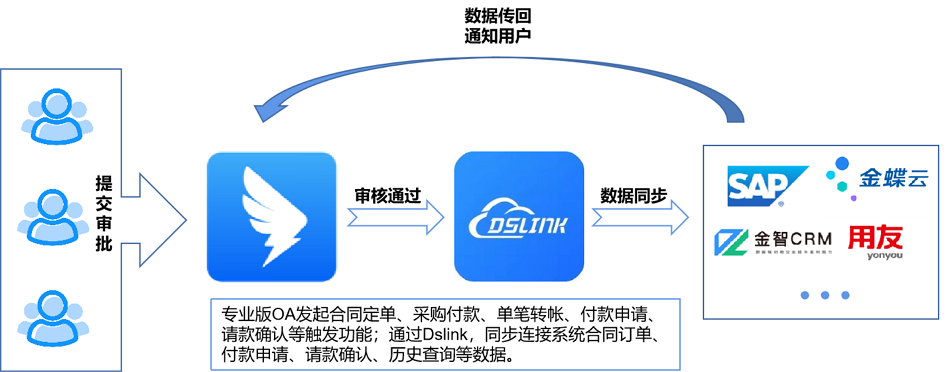
- 【场景化解决方案】搭建数据桥梁,Dslink打通泛微系统连接流
- BUUCTF MISC brush notes (2)
- PoPW代币分配机制或将点燃下一个牛市
猜你喜欢




随机推荐
gin中模型中增删改查+搜索分页
leetcode 34. 在排序数组中查找元素的第一个和最后一个位置(二分经典题)
uniapp编译到小程序后丢失static文件夹问题
js在for循环中按照顺序响应请求
leetcode 37. 解数独 (困难)
The embedded serial port interrupt can only receive one byte
nyoj306 走迷宫(搜索+二分)
数据解析之bs4学习
nyoj58 最少步数(DFS)
[漏洞复现]CVE-2018-7490(路径遍历)
正则表达式基础介绍
bs4的使用基础学习
黑马2022最新redis课程笔记知识点(面试用)
Some of the topics in VNCTF2021 are reproduced
Dark Horse 2022 latest redis course notes and knowledge points (for interview)
ctfshow-web入门 文件上传篇部分题解
Module模块化编程的优点有哪些
QT program generates independent exe program (pit-avoiding version)
内存监控以及优化
【场景化解决方案】构建设备通讯录,制造业设备上钉实现设备高效管理