当前位置:网站首页>【文本分类案例】(4) RNN、LSTM 电影评价倾向分类,附TensorFlow完整代码
【文本分类案例】(4) RNN、LSTM 电影评价倾向分类,附TensorFlow完整代码
2022-04-23 19:30:00 【立Sir】
大家好,今天和大家分享一下如何使用训话神经网络中的 RNN 和 LSTM 方法完成影评倾向分类。数据集的解释见下文:https://blog.csdn.net/qq_23869697/article/details/86505343
1. RNN 方法
这2种循环神经网络方法在代码中差别不大,这里我就详述RNN的具体操作方法,简述LSTM在RNN基础上的改进。
1.1 导入工具包
我是用GPU加速神经网络计算,如果是CPU计算,就把设置下面GPU设置的代码删掉。
import time
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# 调用GPU加速
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
1.2 获取数据集
使用keras内置的imdb影评数据集。考虑到单词量很大,为了简化计算复杂程度,只对10000个常用单词进行逐个编码,对其他生僻的单词使用统一的符号表示,生僻词对训练结果的影响也不是很大。
此外,由于每一条影评的句子长度不一致,而网络的输是入尽量要求tensor的shape一致的,因此设置影评长度统一为80,即少于80个单词的影评通过0填充到长度80,而超过80个单词的句子只取前80个单词。
#(1)导入电影评价数据
# 只对常见单词编码,数量1w个,生僻单词用统一的符号表示
total_words = 10000
# x代表用户的评语,y代表好评还是差评,
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# 设置每个句子的长度, 统一输入网络模型的句子长度
# 处理后的shape为[b,80],有b个句子每个句子有80个单词
max_review_len = 80
# 将长度小于80的句子填充,将长度大于80的句子截断
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
序列预处理函数的参数和返回值如下
keras.preprocessing.sequence.pad_sequences()
'''
参数
sequences:浮点数或整数构成的两层嵌套列表
maxlen:None或整数,为序列的最大长度。大于此长度的将被截断,小于此长度的序列将在后面填0.
dtype:返回的numpy array的数据类型。
padding:pre或post,确定当需要补0时,在序列的起始还是结尾补。
truncating:pre或post,确定需要截断序列时,从起始还是结尾截断。
value:浮点数,用于填充序列。
返回值:2维张量,长度为maxlen
'''1.3 构造数据集
这里说一下 drop_remainder 这个参数。由于数据集总个数不一定能被 batchsize=128 整除,因此最后一个 batch 往往包含的数据个数小于128个。然而网络希望输入的是固定的shape,因此需要删除最后一个batch,使得训练时每一个 step 训练的数据个数一致。
对训练集数据随机打乱 shuffle(),避免偶然性,而测试集就没必要打乱了。构造完数据集后,使用 迭代器iter() 结合 next()函数,从训练集中取出一个batch的数据,检查划分好了的shape
#(2)构造数据集
batchsz = 128 # 每个batch处理128个句子
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # 训练集
# 打乱训练集,并设置每个step训练128个句子,并且将最后不足128的那个batch删除
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # 测试集
# 将最后一个batch大小小于batchsize的删除
db_test = db_test.batch(batchsz, drop_remainder=True)
# 查看数据集信息
sample = next(iter(db_train)) # 取出一个batch的训练集
print('x_train.shape:', sample[0].shape) # (128,80)
print('y_train.shape:', sample[1].shape) # (128,)
1.4 网络构造
这里为了便于大家理解,构建一个两层的 RNN 网络。
一个RNN单元的计算公式为:  ,
,
其中  代表当前时刻的输入,
代表当前时刻的输入, 代表上一个时刻的语境信息,
代表上一个时刻的语境信息, 代表当前时刻的输出结果,
代表当前时刻的输出结果, 代表权重项,
 是非线性激活函数。
是非线性激活函数。

举个例子,在某个RNN单元中,一个单词输入,该单词需要融合这个句子前面所有的语境信息,计算后得到一个输出,这个输出又会和下一个输入的单词进行相同计算,直到每个句子的所有单词都处理完,最终输出的就是整个句子的意思。
(1)初始化
首先构建一个RNN类,进行初始化。self.stage 代表RNN单元的起始的语境信息 
# 创建一个RNN的类,继承keras.Model父类
class MyRNN(keras.Model):
# 初始化
def __init__(self, units):
# 调用父类的初始化方法
super(MyRNN, self).__init__()
# 分配属性
# 初始化每个RNN单元的状态, b个句子的units个单词分量全都初始化为0
self.stage0 = [tf.zeros([batchsz, units])]
# 第二个RNN单元的初始化状态
self.stage1 = [tf.zeros([batchsz, units])]
'''
Embedding主要用于将一个特征转换为一个向量。只能作为模型的第一层使用
类似one-hot编码,但在实际应用当中,将特征转换为one-hot编码后维度会十分高。
所以我们会将稀疏特征转化为稠密特征,通常做法即使用Embedding。
'''
# 将文本用数值编码 [b,80]==>[b,80,100]
# 只对10000个常用单词编码,每个单词用一个100维的向量表示, 输入的句子长度都处理成80
self.embedding = layers.Embedding(10000, 100, input_length=80)
# 第一层RNN单元,展开每一个单词,即在axis=1维度上展开
# [b, 80, 100] ==> [b, units]
self.rnn_cell0 = layers.SimpleRNNCell(units, dropout=0.2) # 输入神经元个数
# 第二个RNN单元,加强特征提取
self.rnn_cell1 = layers.SimpleRNNCell(units, dropout=0.2)
# 全连接层分类
# [b, 64]==>[b, 1]
self.outlayer = layers.Dense(1)(2)前向传播
每个单词都会经过两个RNN单元,可以理解为,第一层用来提取单词是褒义词还是贬义词,第二层用来更深入的提取单词所包含的情感信息。
这里要注意一个参数 training,因为模型训练过程和测试过程某些层度处理方法是不一样的,如dropout层,在训练阶段希望随机杀死神经元防止过拟合,而在测试阶段希望能获取更多的信息,就不需要杀死神经元了。
前向传播的代码是在MyRNN类的内部的。
# 定义前向传播方法
def call(self, inputs, training=None):
'''
inputs: 做embedding之前的句子 shape=[b,80]
training: 是训练阶段还是测试阶段,有的层是不一样的比如dropout层训练时起作用,测试时不起作用
'''
x = inputs # 获取网络输入大小x_train
# embedding层单词编码处理
x = self.embedding(x) # [b,80]==>[b,80,100]
# 接收初始的RNN单元的状态分量
stage0 = self.stage0 # 第一层RNN单元的状态
stage1 = self.stage1 # 第二层RNN单元的状态
# 经过RNN层[b,80,100]==>[b,units]
# 在时间维度axis=1上展开,展开成80个
for word in tf.unstack(x, axis=1): # word:[b,100] 表示,第一个单词,在b个句子中,该单词都用100维的向量来表示
# 将每个单词送入至RNN单元中
'''
out, ht = Xt * Wxh + h(t-1) * Whh
Xt代表当前阶段的单词,h(t-1)代表上一个阶段的语境状态
out代表当前阶段RNN单元的输出, ht代表当前阶段的结果作为预警信息传到下一个阶段
'''
# 传入RNN单元是否是训练或测试阶段,对dropout不同处理
# 计算完后更新下一次循环用到的语境信息
out0, stage0 = self.rnn_cell0(word, stage0, training)
# 将第一层的输出结果传入至第二个RNN单元
out1, stage1 = self.rnn_cell1(out0, stage1, training)
# 最后的输出tensor的shape=[b,64],此时的stage0已经聚合了前80个单词的信息
# 全连接层分类 [b,64]==>[b,1]
x = self.outlayer(out1)
# 经过sigmoid函数输出概率
prob = tf.sigmoid(x)
return prob1.5 网络训练
接下来训练网络,设置Adam优化器的学习率0.01,由于目标值的好评和差评是用0和1来表示的,因此本案例是一个二分类问题,使用二元交叉熵损失。
#(4)网络训练
units = 64 # RNN单元神经元个数
epochs = 10 # 网络训练10次
t0 = time.time() # 训练前的起始时间
# 接收模型
model = MyRNN(units)
# 网络编译
model.compile(optimizer=keras.optimizers.Adam(0.001), # Adam优化器,学习了0.01
loss = tf.losses.BinaryCrossentropy(), # 二分类交叉熵损失
metrics=['accuracy']) # 准确率监控指标
# 网络训练
history = model.fit(db_train, epochs=epochs, validation_data=db_test)
t1 = time.time() # 记录训练所用的时间
print('总耗时:', t1-t0)训练过程如下:
Epoch 1/10
195/195 [==============================] - 26s 118ms/step - loss: 0.6318 - accuracy: 0.6034 - val_loss: 0.3870 - val_accuracy: 0.8289
Epoch 2/10
195/195 [==============================] - 22s 115ms/step - loss: 0.3429 - accuracy: 0.8506 - val_loss: 0.4200 - val_accuracy: 0.8308
---------------------------------------------------
---------------------------------------------------
Epoch 9/10
195/195 [==============================] - 22s 112ms/step - loss: 0.0285 - accuracy: 0.9897 - val_loss: 0.9732 - val_accuracy: 0.8100
Epoch 10/10
195/195 [==============================] - 21s 110ms/step - loss: 0.0804 - accuracy: 0.9721 - val_loss: 0.8530 - val_accuracy: 0.78411.6 测试集验证
使用 evaluate() 函数评价测试集,查看整个数据集的准确率和损失
#(5)测试集评价
model.evaluate(db_test)195/195 [==============================] - 6s 30ms/step - loss: 0.8530 - accuracy: 0.78411.7 训练过程可视化
使用RNN很容易出现梯度离散和梯度爆炸的现象,需要慢慢调参
#(6)获取训练信息
history_dict = history.history # 获取训练的数据字典
train_loss = history_dict['loss'] # 训练集损失
train_accuracy = history_dict['accuracy'] # 训练集准确率
val_loss = history_dict['val_loss'] # 验证集损失
val_accuracy = history_dict['val_accuracy'] # 验证集准确率
#(7)绘制训练损失和验证损失
plt.figure()
plt.plot(range(epochs), train_loss, label='train_loss') # 训练集损失
plt.plot(range(epochs), val_loss, label='val_loss') # 验证集损失
plt.legend() # 显示标签
plt.xlabel('epochs')
plt.ylabel('loss')
#(8)绘制训练集和验证集准确率
plt.figure()
plt.plot(range(epochs), train_accuracy, label='train_accuracy') # 训练集准确率
plt.plot(range(epochs), val_accuracy, label='val_accuracy') # 验证集准确率
plt.legend()
plt.xlabel('epochs')
plt.ylabel('accuracy')
2. LSTM
2.1 方法简介
对于传统的 RNN 网络,它的记忆时间特别短,尽管设置时是让网络记住所有单词的语境信息,但实际上只能记住最近相关的几个单词的语境。LSTM不仅解决了RNN梯度离散的问题,也解决了记忆时长的问题。
LSTM结构如下,可理解为,对上一时刻的语境信息 ,当前时刻的输入信息 ,在输入网络层之前,分别有一个闸门对它们处理,当计算完成后,对输出结果 ,也有一个闸门处理。

这里的闸门就是sigmoid函数,将输出限制在0到1之间。LSTM中多了一个过去的信息,称为  。对上一时刻的语境 ,当前时刻的输入信息 ,计算后得到
。对上一时刻的语境 ,当前时刻的输入信息 ,计算后得到  。计算结果乘以过去信息,再加上过滤后的新输入的信息,得到当前时刻更新后的
。计算结果乘以过去信息,再加上过滤后的新输入的信息,得到当前时刻更新后的  。LSTM主要通过闸门过滤信息与更新过去的语境,具体的详细原理在下一篇讲解,本文主要是代码。
。LSTM主要通过闸门过滤信息与更新过去的语境,具体的详细原理在下一篇讲解,本文主要是代码。
2.2 代码展示
(1)改动部分
在代码中,LSTM相比于上文RNN,只需要将 layers.SimpleRNNCell() 改成 layers.LSTMCell() 。
# 第一层LSTM单元,展开每一个单词,即在axis=1维度上展开
# [b, 80, 100] ==> [b, units]
self.rnn_cell0 = layers.LSTMCell(units, dropout=0.2) # 输入神经元个数
# 第二个LSTM单元,加强特征提取
self.rnn_cell1 = layers.LSTMCell(units, dropout=0.2)然后需要增加初始化状态,RNN只需要对上一时刻的语境信息 用0初始化,而 LSTM 比 RNN 多了一个旧时刻的信息 ,对这个量也进行0初始化。
# 分配属性
# 初始化每个RNN单元的状态, b个句子的units个单词分量全都初始化为0,第一个时间段的旧信息为0
self.stage0 = [tf.zeros([batchsz, units]), tf.zeros([batchsz, units])] # 两个全为0的初始化量,代表c和h
# 第二个RNN单元的初始化状态
self.stage1 = [tf.zeros([batchsz, units]), tf.zeros([batchsz, units])]
(2)网络训练
其他部分和RNN都一样,就不重复赘述了。
import time
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# 调用GPU加速
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
#(1)导入电影评价数据
# 只对常见单词编码,数量1w个,生僻单词用统一的符号表示
total_words = 10000
# x代表用户的评语,y代表好评还是差评,
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# 设置每个句子的长度, 统一输入网络模型的句子长度
# 处理后的shape为[b,80],有b个句子每个句子有80个单词
max_review_len = 80
# 将长度小于80的句子填充,将长度大于80的句子截断
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
'''
参数
sequences:浮点数或整数构成的两层嵌套列表
maxlen:None或整数,为序列的最大长度。大于此长度的将被截断,小于此长度的序列将在后面填0.
dtype:返回的numpy array的数据类型。
padding:pre或post,确定当需要补0时,在序列的起始还是结尾补。
truncating:pre或post,确定需要截断序列时,从起始还是结尾截断。
value:浮点数,用于填充序列。
返回值:2维张量,长度为maxlen
'''
#(2)构造数据集
'''网络的输入希望是固定的shape,当最后的batch小于batchsize,删除它'''
batchsz = 128 # 每个batch处理128个句子
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # 训练集
# 打乱训练集,并设置每个step训练128个句子,并且将最后不足128的那个batch删除
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # 测试集
# 将最后一个batch大小小于batchsize的删除
db_test = db_test.batch(batchsz, drop_remainder=True)
# 查看数据集信息
sample = next(iter(db_train)) # 取出一个batch的训练集
print('x_train.shape:', sample[0].shape) # (128,80)
print('y_train.shape:', sample[1].shape) # (128,)
#(3)构建RNN网络模型
# 创建一个RNN的类,继承keras.Model父类
class MyRNN(keras.Model):
# 初始化
def __init__(self, units):
# 调用父类的初始化方法
super(MyRNN, self).__init__()
# 分配属性
# 初始化每个RNN单元的状态, b个句子的units个单词分量全都初始化为0,第一个时间段的旧信息为0
self.stage0 = [tf.zeros([batchsz, units]), tf.zeros([batchsz, units])] # 两个全为0的初始化量,代表c和h
# 第二个RNN单元的初始化状态
self.stage1 = [tf.zeros([batchsz, units]), tf.zeros([batchsz, units])]
'''
Embedding主要用于将一个特征转换为一个向量。只能作为模型的第一层使用
类似one-hot编码,但在实际应用当中,将特征转换为one-hot编码后维度会十分高。
所以我们会将稀疏特征转化为稠密特征,通常做法即使用Embedding。
'''
# 将文本用数值编码 [b,80]==>[b,80,100]
# 只对10000个常用单词编码,每个单词用一个100维的向量表示, 输入的句子长度都处理成80
self.embedding = layers.Embedding(10000, 100, input_length=80)
# 第一层LSTM单元,展开每一个单词,即在axis=1维度上展开
# [b, 80, 100] ==> [b, units]
self.rnn_cell0 = layers.LSTMCell(units, dropout=0.2) # 输入神经元个数
# 第二个LSTM单元,加强特征提取
self.rnn_cell1 = layers.LSTMCell(units, dropout=0.2)
# 全连接层分类
# [b, 64]==>[b, 1]
self.outlayer = layers.Dense(1)
# 定义前向传播方法
def call(self, inputs, training=None):
'''
inputs: 做embedding之前的句子 shape=[b,80]
training: 是训练阶段还是测试阶段,有的层是不一样的比如dropout层训练时起作用,测试时不起作用
'''
x = inputs # 获取网络输入大小x_train
# embedding层单词编码处理
x = self.embedding(x) # [b,80]==>[b,80,100]
# 接收初始的RNN单元的状态分量
stage0 = self.stage0 # 第一层RNN单元的状态
stage1 = self.stage1 # 第二层RNN单元的状态
# 经过RNN层[b,80,100]==>[b,units]
# 在时间维度axis=1上展开,展开成80个
for word in tf.unstack(x, axis=1): # word:[b,100] 表示,第一个单词,在b个句子中,该单词都用100维的向量来表示
# 将每个单词送入至RNN单元中
'''
out, ht = Xt * Wxh + h(t-1) * Whh
Xt代表当前阶段的单词,h(t-1)代表上一个阶段的语境状态
out代表当前阶段RNN单元的输出, ht代表当前阶段的结果作为预警信息传到下一个阶段
'''
# 传入RNN单元是否是训练或测试阶段,对dropout不同处理
# 计算完后更新下一次循环用到的语境信息
out0, stage0 = self.rnn_cell0(word, stage0, training)
# 将第一层的输出结果传入至第二个RNN单元
out1, stage1 = self.rnn_cell1(out0, stage1, training)
# 最后的输出tensor的shape=[b,64],此时的stage0已经聚合了前80个单词的信息
# 全连接层分类 [b,64]==>[b,1]
x = self.outlayer(out1)
# 经过sigmoid函数输出概率
prob = tf.sigmoid(x)
return prob
#(4)网络训练
units = 64 # RNN单元神经元个数
epochs = 10 # 网络训练10次
t0 = time.time() # 训练前的起始时间
# 接收模型
model = MyRNN(units)
# 网络编译
model.compile(optimizer=keras.optimizers.Adam(0.001), # Adam优化器,学习了0.01
loss = tf.losses.BinaryCrossentropy(), # 二分类交叉熵损失
metrics=['accuracy']) # 准确率监控指标
# 网络训练
history = model.fit(db_train, epochs=epochs, validation_data=db_test)
t1 = time.time() # 记录训练所用的时间
print('总耗时:', t1-t0)查看训练过程
Epoch 1/10
195/195 [==============================] - 63s 286ms/step - loss: 0.5425 - accuracy: 0.7036 - val_loss: 0.3783 - val_accuracy: 0.8317
Epoch 2/10
195/195 [==============================] - 53s 275ms/step - loss: 0.3030 - accuracy: 0.8735 - val_loss: 0.3891 - val_accuracy: 0.8333
------------------------------------------------
------------------------------------------------
Epoch 9/10
195/195 [==============================] - 53s 271ms/step - loss: 0.0785 - accuracy: 0.9731 - val_loss: 0.8818 - val_accuracy: 0.8058
Epoch 10/10
195/195 [==============================] - 53s 272ms/step - loss: 0.0592 - accuracy: 0.9813 - val_loss: 0.8983 - val_accuracy: 0.8060(3)模型评价
首先查看整个测试集的评价指标,损失值和准确率。
#(5)测试集评价
model.evaluate(db_test)
195/195 [==============================] - 14s 72ms/step - loss: 0.8983 - accuracy: 0.8060history变量中保存了训练阶段的所有信息,绘制训练阶段的损失和准确率曲线。
#(6)绘制训练曲线
history_dict = history.history # 获取训练的数据字典
train_loss = history_dict['loss'] # 训练集损失
train_accuracy = history_dict['accuracy'] # 训练集准确率
val_loss = history_dict['val_loss'] # 验证集损失
val_accuracy = history_dict['val_accuracy'] # 验证集准确率
#(7)绘制训练损失和验证损失
plt.figure()
plt.plot(range(epochs), train_loss, label='train_loss') # 训练集损失
plt.plot(range(epochs), val_loss, label='val_loss') # 验证集损失
plt.legend() # 显示标签
plt.xlabel('epochs')
plt.ylabel('loss')
#(8)绘制训练集和验证集准确率
plt.figure()
plt.plot(range(epochs), train_accuracy, label='train_accuracy') # 训练集准确率
plt.plot(range(epochs), val_accuracy, label='val_accuracy') # 验证集准确率
plt.legend()
plt.xlabel('epochs')
plt.ylabel('accuracy')
版权声明
本文为[立Sir]所创,转载请带上原文链接,感谢
https://blog.csdn.net/dgvv4/article/details/124361107
边栏推荐
- Distinction between pointer array and array pointer
- Physical meaning of FFT: 1024 point FFT is 1024 real numbers. The actual input to FFT is 1024 complex numbers (imaginary part is 0), and the output is also 1024 complex numbers. The effective data is
- The usage of slice and the difference between slice and array
- Machine learning catalog
- Possible root causes include a too low setting for -Xss and illegal cyclic inheritance dependencies
- Kubernetes入门到精通-KtConnect(全称Kubernetes Toolkit Connect)是一款基于Kubernetes环境用于提高本地测试联调效率的小工具。
- Gossip: on greed
- Audio signal processing and coding - 2.5.3 the discrete cosine transform
- 视频理解-Video Understanding
- Kubernetes入门到精通-在 Kubernetes 上安装 OpenELB
猜你喜欢

深度分析数据恢复原理——那些数据可以恢复那些不可以数据恢复软件
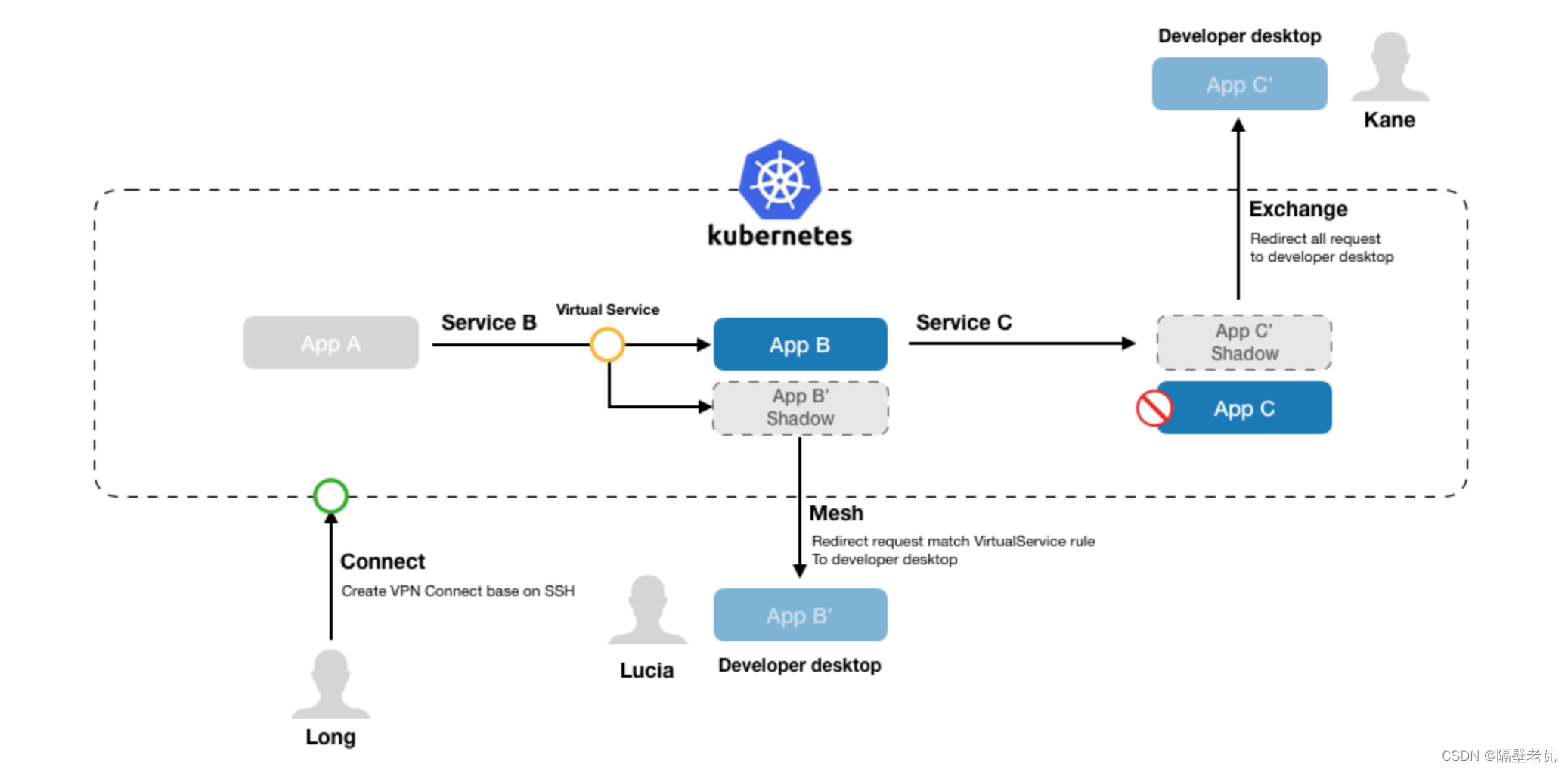
Kubernetes入门到精通-KtConnect(全称Kubernetes Toolkit Connect)是一款基于Kubernetes环境用于提高本地测试联调效率的小工具。
Is meituan, a profit-making company with zero foundation, hungry? Coupon CPS applet (with source code)
Deep learning -- Summary of Feature Engineering

MySQL lock
Mfcc: Mel frequency cepstrum coefficient calculation of perceived frequency and actual frequency conversion
Pdf reference learning notes
Zero cost, zero foundation, build profitable film and television applet
【webrtc】Add x264 encoder for CEF/Chromium

Possible root causes include a too low setting for -Xss and illegal cyclic inheritance dependencies
随机推荐
Redis core technology and practice 1 - start with building a simple key value database simplekv
ArcMap publishing slicing service
Kubernetes入门到精通-裸机LoadBalence 80 443 端口暴露注意事项
MFC获取本机IP(网络通讯时用得多)
Why is PostgreSQL about to surpass SQL Server?
Problems caused by flutter initialroute and home
Speculation on the way to realize the smooth drag preview of video editing software
Garbage collector and memory allocation strategy
RuntimeError: Providing a bool or integral fill value without setting the optional `dtype` or `out`
HTTP cache - HTTP authoritative guide Chapter VII
MySQL数据库 - 单表查询(三)
【webrtc】Add x264 encoder for CEF/Chromium
Zero cost, zero foundation, build profitable film and television applet
Possible root causes include a too low setting for -Xss and illegal cyclic inheritance dependencies
MySQL syntax collation (5) -- functions, stored procedures and triggers
SQL of contention for system time plus time in ocrale database
@Mapperscan and @ mapper
MySQL syntax collation (3)
Openlayers 5.0 reload the map when the map container size changes
【webrtc】Add x264 encoder for CEF/Chromium