当前位置:网站首页>Deep learning -- Summary of Feature Engineering
Deep learning -- Summary of Feature Engineering
2022-04-23 19:25:00 【Try not to lie flat】
For machine learning , General steps :
Data collection — Data cleaning — Feature Engineering — Data modeling
We know , Feature engineering includes feature construction , Feature extraction and feature selection . Feature engineering is actually transforming the original data into models , The process of training data .
Feature building
https://zhuanlan.zhihu.com/p/424518359 Other bloggers' explanations for normalization
In feature construction , First give me a pile of data , So many and messy , We must normalize its data first , Let the data be distributed as I want to see . Then after the specification , You need data preprocessing , Especially missing values 、 Classification feature processing 、 Processing of continuous features .
Data normalization : normalization : Maximum and minimum standardization 、Z-Score Standardization
So what's the biggest difference between them ? Is to change the distribution of characteristic data .
Maximum and minimum standardization : Will change the distribution of characteristic data
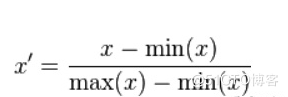
Z-Score Standardization : Do not change the distribution of characteristic data
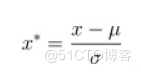
Maximum and minimum standardization :
- The linear function transforms the method of linearizing the original data into [0 1] The scope of the , The calculation result is the normalized data ,X For raw data
- This normalization method is more suitable for The values are concentrated The situation of
- defects : If max and min unstable , It's easy to make the normalization result unstable , It makes the follow-up effect unstable . Empirical constants can be used to replace max and min
- Application scenarios : When it comes to distance measurement 、 Covariance calculation 、 When the data does not conform to the positive distribution , You can use the first method or other normalization methods ( barring Z-score Method ). For example, in image processing , take RGB After the image is converted to a grayscale image, its value is limited to [0 255] The scope of the
Z-Score Standardization :
- among ,μ、σ They are the mean and method of the original data set .
- Normalize the original data set to mean 0、 variance 1 Data set of
- This normalization method requires that the distribution of the original data can be approximately Gaussian distribution , Otherwise, the effect of normalization will become very bad .
- Application scenarios : stay classification 、 clustering In the algorithm, , When distance is needed to measure similarity 、 Or use PCA technology During dimensionality reduction ,Z-score standardization Perform better .
feature extraction
So in the feature extraction method , We first learned about data partitioning : Include what the dataset is ? Give you a pile of data , What is your split method ? There are also important dimensionality reduction methods :PCA, There are other ways , such as ICA, But for my final exam , I won't focus on the record, hahaha .
Data sets : Training set 、 Verification set 、 Test set
- Training set : Training data , Adjust model parameters 、 Training model weight , Building machine learning model
- Verification set : The performance of the model is verified by the data separated from the training set , As the performance index of the evaluation model
- Test set : Enter the training set with new data , To verify the quality of the trained model
Split method : Set aside method 、K- Fold cross validation
- Set aside method : Divide the data set into mutually exclusive sets , Maintain the consistency of the split set data
- K- Fold cross validation : Split the dataset into K A mutually exclusive subset of similar size , Ensure the consistency of their data distribution
In order to convert the original data into obvious physical / Characteristics of statistical significance , You need to build new data , The methods used are usually PCA、ICA、LDA etc. .
So why do we need to reduce the dimension of features
- Eliminate noise
- Data compression
- Eliminate data redundancy
- Improve the accuracy of the algorithm
- Reduce the data dimension to 2 Dimension or 3 dimension , Maintain data visibility
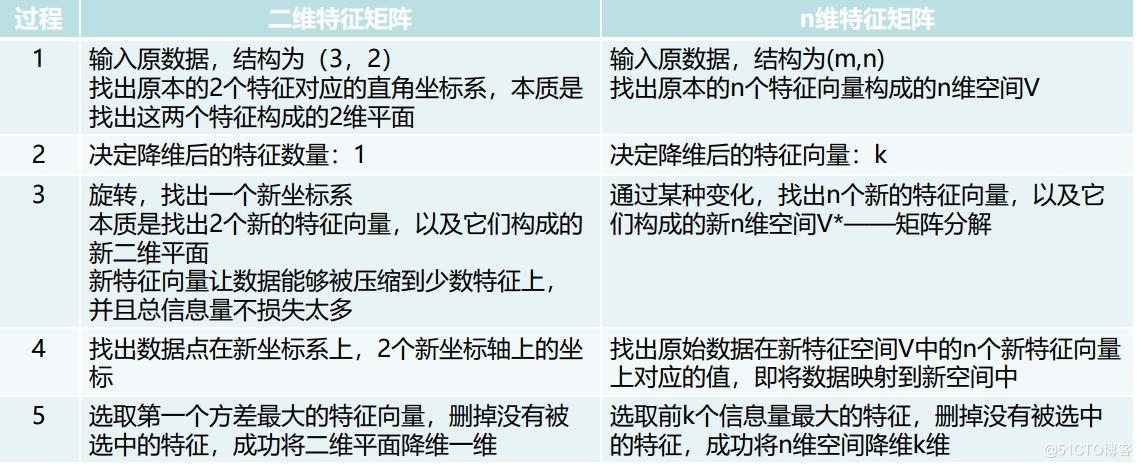
PCA( Principal component analysis ): Through the transformation of coordinate axis ; Find the optimal subspace of data distribution
- Enter the original data , The structure is (m,n), Find the original n It's made up of two eigenvectors n Dimensional space
- Determine the eigenvector after dimensionality reduction :K
- Through some kind of change , find n A new eigenvector , And the new n Dimensional space V*—— Matrix decomposition
- Find the original data in the new feature space V Medium n The value corresponding to a new eigenvector , Mapping data to a new space
- Before selection K One of the most informative features , Delete unselected features , Will succeed n Dimension reduction of dimensional space K dimension
For feature selection , There are several ways : Filter type 、 Parcel type 、 The embedded ( Understanding can )
Last , Let's look at the difference between super parameters and parameters :
- Hyperparameters : Parameters set before learning the model , Artificially set , such as padding、stride、k-means Of k、 depth 、 Number and size of convolution kernels 、 Learning rate
- Parameters : The parameters obtained through a series of model training , Such as weight w and wx+b Inside b.
版权声明
本文为[Try not to lie flat]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231859372120.html
边栏推荐
- ArcMap connecting ArcGIS Server
- Easy mock local deployment (you need to experience three times in a crowded time. Li Zao will do the same as me. Love is like a festival mock)
- 点云数据集常用处理
- 深度学习环境搭建步骤—gpu
- Strange problems in FrameLayout view hierarchy
- Parsing headless jsonarray arrays
- How to use go code to compile Pb generated by proto file with protoc Compiler Go file
- js上传文件时控制文件类型和大小
- Using oes texture + glsurfaceview + JNI to realize player picture processing based on OpenGL es
- Decompile and get the source code of any wechat applet - just read this (latest)
猜你喜欢
命令-sudo
Grafana 分享带可变参数的链接
指针数组与数组指针的区分

Keysight has chosen what equipment to buy for you
ArcMap connecting ArcGIS Server

RuntimeError: Providing a bool or integral fill value without setting the optional `dtype` or `out`

Using oes texture + glsurfaceview + JNI to realize player picture processing based on OpenGL es
On the forced conversion of C language pointer
redis优化系列(三)解决主从配置后的常见问题
The most detailed network counting experiment in history (2) -- rip experiment of layer 3 switch
随机推荐
ArcMap连接 arcgis server
Regular expressions for judging positive integers
Zero base to build profit taking away CPS platform official account
I just want to leave a note for myself
Problems caused by flutter initialroute and home
ESP8266-入门第一篇
Openlayers 5.0 two centering methods
Garbage collector and memory allocation strategy
Openharmony open source developer growth plan, looking for new open source forces that change the world!
Core concepts of rest
C1000k TCP connection upper limit test
No, some people can't do the National Day avatar applet (you can open the traffic master and earn pocket money)
js上传文件时控制文件类型和大小
FFT物理意义: 1024点FFT就是1024个实数,实际进入fft的输入是1024个复数(虚部为0),输出也是1024个复数,有效的数据是前512个复数
为何PostgreSQL即将超越SQL Server?
Strange problems in FrameLayout view hierarchy
深度学习——特征工程小总结
ArcMap publishing slicing service
A brief explanation of golang's keyword "competence"
Common SQL commands