当前位置:网站首页>shell数组
shell数组
2022-08-09 22:03:00 【花生味花生米】
一.数组
变量:存储单个元素的内存空间
数组:存储多个元素的连续的内存空间,相当于多个变量的集合
二.数组的作用
1.多个元素的组合,变量的集合,将相同特性的一类数据存进数组中。
2.在数组中怎么区分每个数据,给每个元素编上号。
3.数组的分类
普通、关联
三.数组名和索引
索引的编号(下标)从0开始,属于数值索引
索引可支持使用自定义的格式,而不仅是数值格式,即为关联索引,bash 4.0版本之后开始支持
bash的数组支持稀疏格式(索引不连续)
四.声明数组
普通数组可以不事先声明,直接使用
declare -a
关联数组必须先声明,再使用
declare -A
普通数组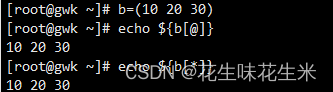


关联数组
1.先申明 2.在赋值
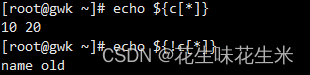
![]()
五.数组遍历
循环输出定义值
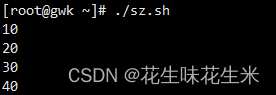
六.数组切片
获取需要的结果(表示1到3,0和其他不输出)
七.数组替换
/10/80:将前定义的值更改为后面的值![]()
八.冒泡排序
数组排序算法
冒泡排序
类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断的向前移动。
基本思想
冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,
把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),
这样较小的元素就像气泡一样从底部上升到顶部。
算法思路
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了。而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少。

![]()
#定义数组
read -p "定义数组:" shu
a=($shu)
#假设定义最大数
b=${a[0]}
#循环(取值范围从0到a的定义的最大数,i++:给跳出条件,避免死循环)
for ((i=0;i<${#a[*]};i++))
#第一个值小于第二个值,直到找打最大的数循环结束
do
if [[ $b -lt ${a[$i+1]} ]];then
c=${a[$i+1]}
fi
done
echo "$c"
边栏推荐
- 【EF】 更新条目时出错。有关详细信息,请参见内部异常。[通俗易懂]
- 一本通2074:【21CSPJ普及组】分糖果(candy)
- R语言ggstatsplot包grouped_ggscatterstats函数可视化分组散点图、并添加假设检验结果(包含样本数、统计量、效应大小及其置信区间、显著性、组间两两比较、贝叶斯假设)
- leetcode:323. 无向图中连通分量的数目
- 一文让你快速了解隐式类型转换【整型提升】!
- 迅为瑞芯微RK3399开发板设置Buildroot文件系统测试MYSQL允许远程访问
- js十五道面试题(含答案)
- 【LaTex】 Font “FandolSong-Regular“ does not contain requested(fontspec)Script “CJK“.如何抑制此种警告?
- MLOps的演进历程
- 开发者必备:一文快速熟记【数据库系统】和【软件开发模型】常用知识点
猜你喜欢







随机推荐
leetcode 39. 组合总和(完全背包问题)
Rust 解引用
金山云地震,震源在字节?
Blender程序化建模简明教程【PCG】
leetcode 38. 外观数列
Flask introductory learning tutorial
小程序+自定义插件的关键性
Activiti7审批流
p5.js实现的炫酷星体旋转动画
NodeJS使用JWT
好未来,想成为第二个新东方
Flask之路由(app.route)详解
C. Mere Array
Tencent continues to wield the "big knife" to reduce costs and increase efficiency, and free catering benefits for outsourced employees have been cut
R语言patchwork包将多个可视化结果组合起来、使用plot_annotation函数以及tag_level参数将组合图用大写字母进行顺序编码、为组合图的标签添加自定义前缀信息
请讲一讲JS中的 for...in 与 for...of (上)
OKR 锦囊妙计
Postgresql源码(68)virtualxid锁的原理和应用场景
Cesium渐变色3dtiles白模(视频)
JuiceFS 在多云存储架构中的应用 | 深势科技分享