当前位置:网站首页>Reptile exercises (1)
Reptile exercises (1)
2022-04-23 15:04:00 【Zhang Lifan】
Don't just follow the path .Make your own trail .
Don't just walk along the road , Go your own way .
This press release is of great commemorative significance , Published on birthday , Started my career of online note taking , And deepened the infinite love for reptiles , I hope you can give me support !!! Please support me for the first time !!! It will be wonderful in the future .
10.( Choose a question 1) The target site https://www.sogou.com/
requirement :
1. The user enters what to search , Start page and end page
2. Crawl the source code of relevant pages according to the content entered by the user
3. Save the acquired data to the local
import requests
word = input(" Please enter the search content ")
start = int(input(" Please enter the start page "))
end = int(input(" Please enter the end page "))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
for n in range(start, end + 1):
url = f'https://www.sogou.com/web?query={word}&page={n}'
# print(url)
response = requests.get(url, headers=headers)
with open(f'{word} Of the {n} page .html', "w", encoding="utf-8")as file:
file.write(response.content.decode("utf-8"))One 、 Analyze the web
1. Enter the website first
python - Sogou search (sogou.com) https://www.sogou.com/web?query=python&_ast=1650447467&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=7606&sst0=1650447682406&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650447682406 2. Search separately “Python”,“ China ” And compare the websites .
https://www.sogou.com/web?query=python&_ast=1650447467&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=7606&sst0=1650447682406&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650447682406 2. Search separately “Python”,“ China ” And compare the websites .


3. Put each parameter in "&" Separate the symbols
Conclusion :(1) Parameters query Is the search object , Chinese characters will be escaped ( Code after escape without memory )
(2) Parameters ie Is the escape encoding type , With "utf-8" For example , This parameter can be used in Network- Payload-ie=utf-8, Some bags can also be in Network-Response-charset='utf-8', Pictured :

4. However, these two parameters can not meet the page turning and crawling requirements of the test questions , So we have to turn the page manually and then check 
https://www.sogou.com/web?query=python&page=2&ie=utf85. Finally, it's the critical moment ! We found the law , And the meaning of important parameters , You can build a common URL 了 , Pictured :
url = f'https://www.sogou.com/web?query={word}&page={n}'
# Assign variable parameters with variables , In this way, a new URL
Two 、 Look for parameters
https://www.sogou.com/web?query=Python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=12736&sst0=1650428312860&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650428312860
https://www.sogou.com/web?query=java&_ast=1650428313&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=10734&sst0=1650428363389&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650428363389
https://www.sogou.com/web?query=C%E8%AF%AD%E8%A8%80&_ast=1650428364&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=11662&sst0=1650428406805&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650428406805
https://www.sogou.com/web?
https://www.sogou.com/web?query=Python&
https://www.sogou.com/web?query=Python&page=2&ie=utf8
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
'cookie' = "IPLOC=CN3600; SUID=191166B6364A910A00000000625F8708; SUV=1650427656976942; browerV=3; osV=1; ABTEST=0|1650428297|v17; SNUID=636A1DCD7B7EA775332A80CB7B347D43; sst0=663; ld=llllllllll2AgcuYlllllpJK6jclllllHuYSpyllllDlllllVllll5@@@@@@@@@@; LSTMV=229,37; LCLKINT=1424"
'URl' = "https://www.sogou.com/web?query=Python&_ast=1650429998&_asf=www.sogou.com&w=01029901&cid=&s_from=result_up&sut=5547&sst0=1650430005573&lkt=0,0,0&sugsuv=1650427656976942&sugtime=1650430005573"
url="https://www.sogou.com/web?query={}&page={}:# UA To be in dictionary form headers receive
1.headers Error of :
" ":" ",
# Build the format of the dictionary ,',' Never forget
# headers It's a keyword. You can't write it wrong , If you make a mistake, you will have the following error reports
import requests
url = "https://www.bxwxorg.com/"
hearders = {
'cookie':'Hm_lvt_46329db612a10d9ae3a668a40c152e0e=1650361322; mc_user={"id":"20812","name":"20220415","avatar":"0","pass":"2a5552bf13f8fa04f5ea26d15699233e","time":1650363349}; Hm_lpvt_46329db612a10d9ae3a668a40c152e0e=1650363378',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
response = requests.get(url, hearders=hearders)
print(response.content.decode("UTF-8"))
Traceback (most recent call last):
File "D:/pythonproject/ The second assignment .py", line 141, in <module>
response = requests.get(url, hearders=hearders)
File "D:\python37\lib\site-packages\requests\api.py", line 75, in get
return request('get', url, params=params, **kwargs)
File "D:\python37\lib\site-packages\requests\api.py", line 61, in request
return session.request(method=method, url=url, **kwargs)
TypeError: request() got an unexpected keyword argument 'hearders'
# reason : Three hearders Write consistently , however headers Is the key word , So the report type is wrong
# But it's written heades There will be another form of error reporting
import requests
word = input(" Please enter the search content ")
start = int(input(" Please enter the start page "))
end = int(input(" Please enter the end page "))
heades = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
for n in range(start, end + 1):
url = f'https://www.sogou.com/web?query={word}&page={n}'
# print(url)
response = requests.get(url, headers=headers)
with open(f'{word} Of the {n} page .html', "w", encoding="utf-8")as file:
file.write(response.content.decode("utf-8"))
Traceback (most recent call last):
File "D:/pythonproject/ The second assignment .py", line 117, in <module>
response = requests.get(url, headers=headers)
NameError: name 'headers' is not defined
# reason : Three hearders Inconsistent writing , So the registration is wrong
# The correct way of writing is , You'd better not make a mistake !
import requests
url = "https://www.bxwxorg.com/"
headers = {
'cookie':'Hm_lvt_46329db612a10d9ae3a668a40c152e0e=1650361322; mc_user={"id":"20812","name":"20220415","avatar":"0","pass":"2a5552bf13f8fa04f5ea26d15699233e","time":1650363349}; Hm_lpvt_46329db612a10d9ae3a668a40c152e0e=1650363378',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
response = requests.get(url, headers=headers)
print(response.content.decode("UTF-8"))
3、 ... and 、 loop
for n in range(start, end + 1):# Why 'end+1' Well : because range The range of a function is left closed and right open, so it's true end It's not worth it , Add at the back 1 You can get the previous real value
Because it's crawling through the pages , Need to use every page URL, So we should build URL Call into the loop
Four 、requests Basic introduction of :( Jianghu people "urllib3" )
1. install :Win + R --> cmd --> Input pip install requests
# If it cannot be called after downloading, it is because : The module is installed in Python In its own environment , The virtual environment you use doesn't have this Databases , To specify the environment
# Specify the environment : The input terminal where python Find the installation path --> File --> setting --> project --> project interpreter --> Find the settings Icon --> Add --> system interpreter --> ... --> (where python In the path ) --> OK --> Apply application --> OK
2. The request module of the crawler urllib.request modular (urllib3)
(1) Common methods :
urllib.request.urlopen(" website ")
effect : Make a request to the website , And get the corresponding
Byte stream = response.read().decode('utf-8')
urllib.request request(" website ", headers=" Dictionaries ")
# because urlopen() Refactoring is not supported User-Agent
(2)requests modular
(2-1)request Common usage of :
requsts.get( website )
(2-2) The object of the response response Methods :
response.text return Unicode Formatted data (str)
response.content Return byte stream data ( Binary system )
response.conten.decode('utf-8') Decode manually
response.url return url
response.encode() = " code "
(3). adopt requsts Module to send POST request :
cookie:
cookie The user identity is determined by the information recorded on the client
HTTP Is a kind of connection protocol. The interaction between client and server is limited to “ request / Respond to ” Disconnect when finished , Next time, please Time finding , The server will think of it as a new client , In order to maintain the connection between them , Let the server know that this is Request initiated by the previous user , Client information must be saved in one place
session;
session It is to determine the user identity through the information recorded on the server , there session It means a conversation


In this way, you can get the page source code !!!
Don't worry , The best things come when you least expect them to . So what we're going to do is : Try with hope , Wait for the good to come . May your world always be full of sunshine , There will be no unnecessary sadness . May you be on the road of life , Reach the place you want , With you , It's your favorite look .
Today is a happy day ,4 month 21 Number , It's not just my birthday , It's also my first time CSDN Draft , As a cute new , Please give me your support , In the afternoon, I will post a link , Please join us for three times !!!
2002/4/21
Happy birthday to Xiao Fanfan

版权声明
本文为[Zhang Lifan]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231410193450.html
边栏推荐
- 【thymeleaf】处理空值和使用安全操作符
- Leetcode162 - find peak - dichotomy - array
- How to design a good API interface?
- LeetCode 练习——396. 旋转函数
- What is the main purpose of PCIe X1 slot?
- Detailed analysis of SQL combat of Niuke database (26-30)
- I/O复用的高级应用之一:非阻塞 connect———使用 select 实现(也可以用 poll 实现)
- 编程哲学——自动加载、依赖注入与控制反转
- nuxt项目:全局获取process.env信息
- Introduction to distributed transaction Seata
猜你喜欢

Leetcode167 - sum of two numbers II - double pointer - bisection - array - Search
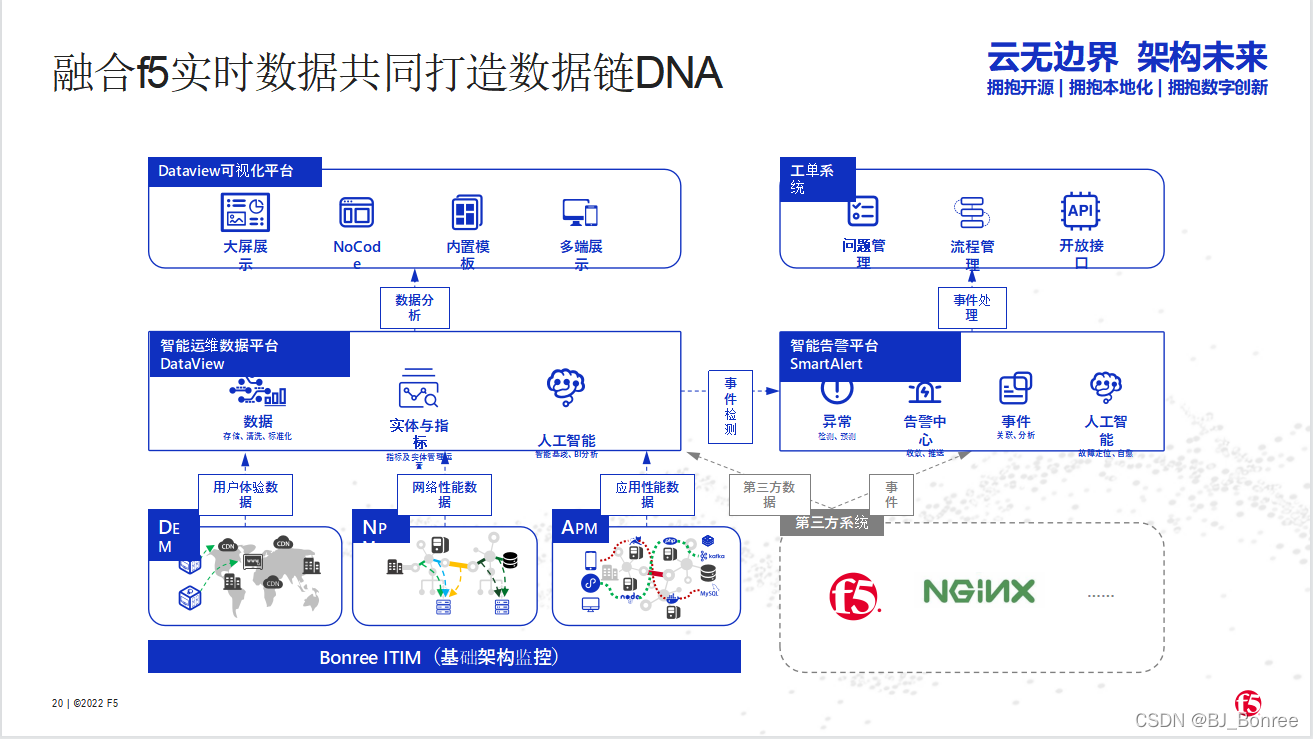
博睿数据携手F5共同构建金融科技从代码到用户的全数据链DNA
LeetCode167-两数之和II-双指针-二分-数组-查找
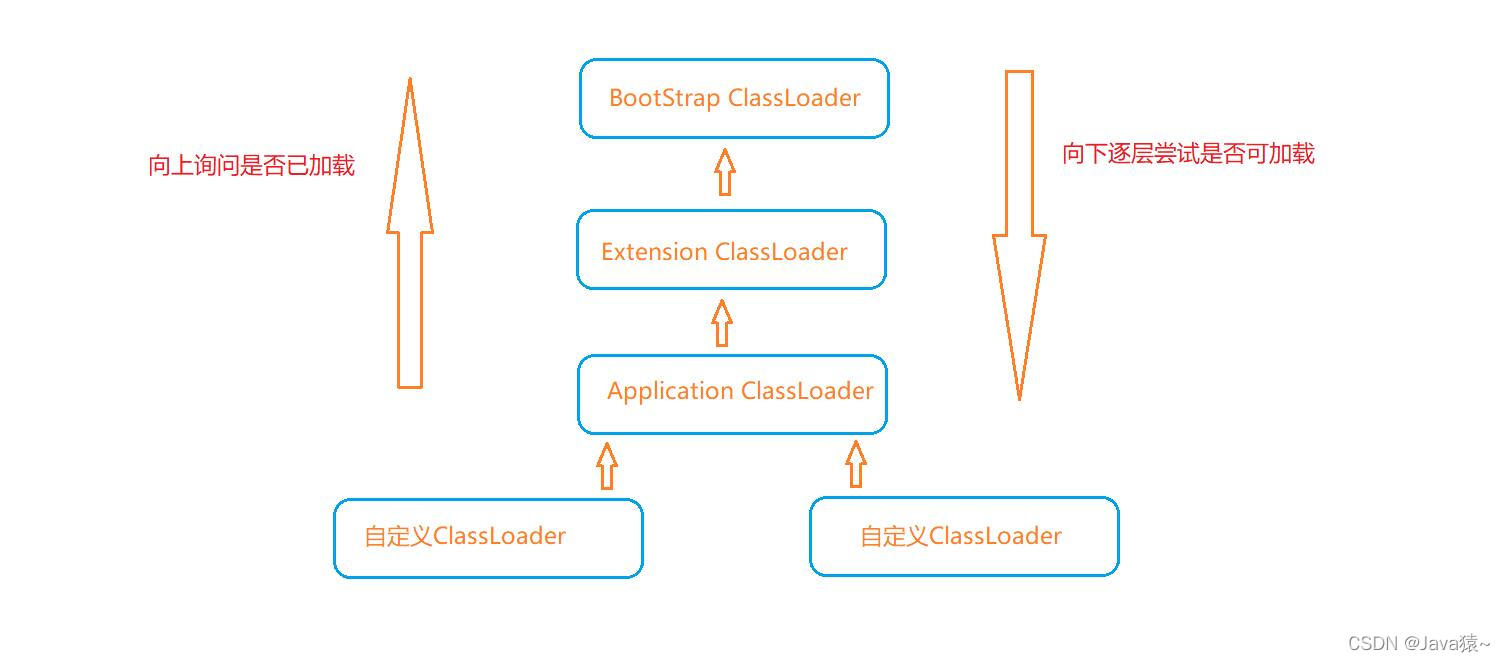
Interviewer: let's talk about the process of class loading and the mechanism of class loading (parental delegation mechanism)
中富金石财富班29800效果如何?与专业投资者同行让投资更简单
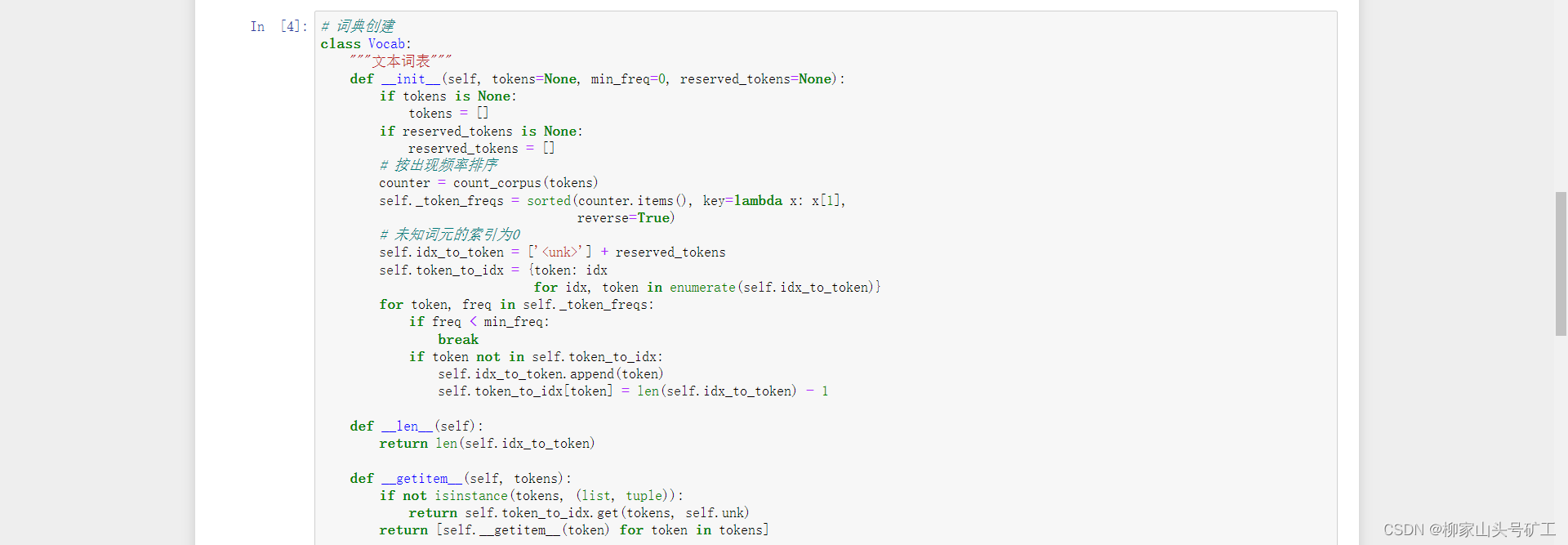
8.2 text preprocessing
Tencent has written a few words, Ali has written them all for a month
![[stc8g2k64s4] introduction of comparator and sample program of comparator power down detection](/img/8c/e72e628a44a36bfc7406a002d00215.png)
[stc8g2k64s4] introduction of comparator and sample program of comparator power down detection
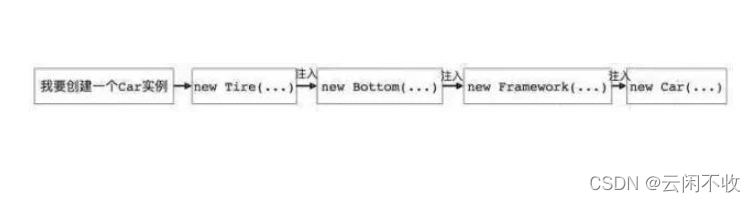
Programming philosophy - automatic loading, dependency injection and control inversion
we引用My97DatePicker 实现时间插件使用
随机推荐
How does eolink help telecommuting
Frame synchronization implementation
Comment eolink facilite le télétravail
When splicing HQL, the new field does not appear in the construction method
OC to swift conditional compilation, marking, macro, log, version detection, expiration prompt
在游戏世界组建一支AI团队,超参数的多智能体「大乱斗」开赛
do(Local scope)、初始化器、内存冲突、Swift指针、inout、unsafepointer、unsafeBitCast、successor、
Difference between like and regexp
The difference between having and where in SQL
we引用My97DatePicker 实现时间插件使用
牛客网数据库SQL实战详细剖析(26-30)
22年了你还不知道文件包含漏洞?
8.2 text preprocessing
How to upload large files quickly?
win10 任务栏通知区图标不见了
Vous ne connaissez pas encore les scénarios d'utilisation du modèle de chaîne de responsabilité?
QT Detailed explanation of pro file
Async void caused the program to crash
select 同时接收普通数据 和 带外数据
capacitance