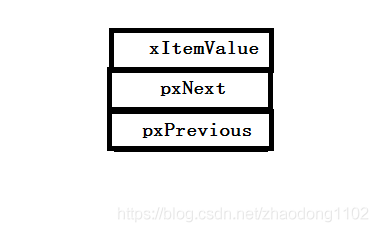
With the emergence of more and more machine learning application scenarios, the existing supervised learning with better performance requires a large amount of labeled data. Labeling data is a boring and expensive task.Therefore, transfer learning has received more and more attention.This paper shares and introduces three argument relation extraction based on transfer learning.
Data overview
Efficient Argument Structure Extraction with Transfer Learning and Active Learning
Paper address: https://arxiv.org/pdf/2204.00707
This article proposes a Transformer-based context-aware argument relation prediction model for extracting argument relations, which significantly outperforms dependent features or encoding only in five different domainsModels with limited context.To address the difficulty of data annotation, the authors utilize existing annotated data to improve model performance in new target domains through transfer learning, and identify a small number of samples for annotation through active learning.
A Large-Scale Dataset for Integrated Argument Mining Tasks(IAM: A Comprehensive and Large-Scale Dataset for Integrated Argument Mining Tasks)
Paper address: https://arxiv.org/pdf/2203.12257
In order to automate the tedious process of argumentation, this article proposes a large-scale dataset IAM that can be used for a range of argumentation mining tasks, including claim extraction, position classification, evidence extraction, etc.We then further propose two new argument mining tasks related to the argument preparation process: (1) claim extraction based on position classification, (2) claim-evidence pair extraction.Pipeline and end-to-end methods are tested separately for each ensemble task.
Does Unsupervised Knowledge Transfer in Social Discussion Help Debate Mining?(Can Unsupervised Knowledge Transfer from Social Discussions Help Argument Mining?)
Paper address: https://arxiv.org/pdf/2203.12881
While Transformer-based pretrained language models can achieve state-of-the-art results in many NLP tasks, the lack of labeled data and the highly domain-dependent nature of arguments limit the usefulness of such models.performance.This paper proposes a transfer learning strategy to solve this problem, using CMV as the dataset, fine-tuning the language model with selective masks, and proposes a prompt-based strategy to predict the relationship between arguments.