当前位置:网站首页>T5: Text-to-Text Transfer Transformer
T5: Text-to-Text Transfer Transformer
2022-08-10 03:19:00 【hithithithithit】
目录
Comparing Different Model Structures
Disparate High-level Approaches
Simplifying the Bert Objective
论文
T5 https://arxiv.org/pdf/1910.10683.pdf
https://arxiv.org/pdf/1910.10683.pdf
Harvard emersionTransformer代码:
The Annotated Transformer (harvard.edu)http://nlp.seas.harvard.edu/2018/04/03/attention.html
Abstract
Transfer learning is where the model is pre-trained on a data-rich task first.,Then fine-tune on downstream tasks.The most recent transfer learning inNLPis a powerful technique.在本文中,We introduce a unified framework for transforming text-based problems into text-to-text,Thereby developing transfer learning inNLP中的应用.
Introduction
Carries on the preliminary training is to make model for general knowledge makes model“理解”文本,so as to perform better in downstream tasks.We receive the impact of the unified framework,例如QA、LM、span extractioneffects of other methods,Treat each text processing problem as a“文本-文本”的任务,Take text as input and produce new text as output,如下图所示.
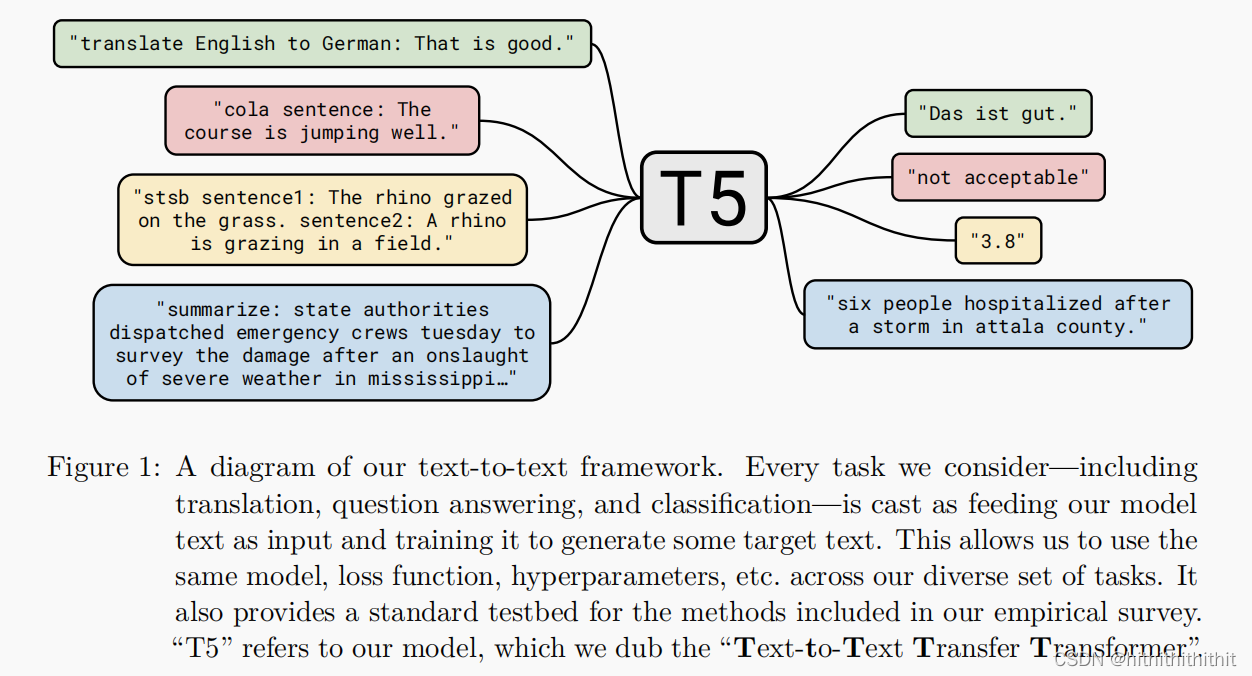
Setup
语料:Colossal Clean Crawled Corpus(C4)
Model
Transformer是一个seq2seq的结构,input by sequencetoken映射成embedding组成,然后放入到encoder里面,encoderComposed of self-attention and feed-forward network stacking.下图是原始的Transformer架构:

原始TransformerSee the architecture for details:[1706.03762] Attention Is All You Need (arxiv.org)
Differences from the original network architecture:
Layer Normalizationoutput result applied to each submodule.这里使用的layer normalization仅用于缩放,没有偏置,且Layer normalization被Applies to the front of each submodule input.在layer normalization之后,A residual skip connection is used to sum the inputs and outputs of each submodule.
where self-attention is order-independent,So the location information must be explicitly indicated in the network,Sinusoidal positions or learned position embeddings are used in the original network,Recently started using relative positional embedding,Mainly to produce different embeddings based on the offset between the comparison key and the query in self-attention.This article USES a simplifiedposition embedding,Each positional embedding is just a scalar,It is added to the correspondinglogit中.为了提高效率,We also Shared location embedded in all layers in the model parameters,Although in a given layer,Each attention head uses a different learned position embedding.
综上所述,我们的模型与Vaswani等人(2017)The original transformer proposed is roughly the same,In addition to removing layer norm bias,Place layer normalization outside the residual path,and use different positional embedding schemes.Since these structural changes are orthogonal to the experimental factors we consider in our empirical investigation of transfer learning,We leave the ablation of its effects to future work.
Corpus
使用了Common Crwalpublic available text in.Because a large part of the obtained data is not text,So the author uses the following method to clean the network to extract the text:
1、Keep only lines ending with terminal punctuation;2、discarded less than5A sentence of the page,sentence contains at least3个单词;3、删除了Bad Words;4、 removed withJStext of warning;5、Removed all interfaces to be placeholders;6、removed with{}parenthesis interface;7、为了去重,Deleted all three consecutive sentences in the dataset with the same text.
We use heuristics to filter text that is not in English,其中使用langdetect · PyPI来检测,The probability that the text is required to be in English is at least0.99.最终获得了一个750GB的数据集,Contains reasonably clean and natural English text.
DownStream Tasks
The goal of this paper is to measure general language learning ability,In total, the following studies have beenbenchmark中的表现:机器翻译,问答,摘要总结,文本分类.具体来说,我们测量了GLUE和SuperGLUEPerformance on Text Classification Benchmarks;CNN/Daily Mail 摘要总结;answer questions broadly;以及WMT英语到德语、French and Romanian translation.

Input and Output Format
To train different tasks on one model,我们使用了“文本-文本”的格式,A task model is used by conditional“输入文本-输出文本”的生成.This framework provides continuous training targets for pre-training and fine-tuning.具体来说,using the maximum likelihood objective(teacher forcing )to train regardless of task type.To make the model aware of different tasks,We use text prefixes to denote different types of task inputs.
For example in translation tasks,The model needs to be“That is good.”translate into german,The output sample:“translate English to German:That is good. ”
在文本分类任务中:infer whether a hypothesis consists of implication、矛盾、Neutral three relationships.那么输入为“mnli premise: I hate pigeons. hypothesis: My feelings towards pigeons are fifilled with animosity.”and the corresponding target word“entailment”.If the model outputs labels other than these three relations,then we will decide that the output of the model is wrong.
Due to the description of the task(text prefix)The choice of is essentially a hyperparameter,The authors of this paper found changesThe prefix text is limited to the promotion of model performance(Is it possible that the model is larger??The small model is better than the large model?),So the text has not been extensively experimented with different prefixes.For example, the following figure is a display of hyperparameters,For the detailed prefix text, please see the appendix of the original textD部分,下图包含WMT English to Germantask prefix.

The model trained in this paper focuses on迁移学习instead of zero-shot learning,相比于span extraction的训练方式,We can also do generation tasks.For a similarity calculation task(打分),We turn this into a classification task,Use numeric intervals to represent different categories,比如1-5的相似度分数,被以0.2divided into intervals21个类,If at test time the output of the model is not1-5之间,then it will be considered that the model prediction is wrong.
Experiments
NLPRecent advances in transfer learning come from new pre-training objectives、模型结构、Development of unlabeled datasets, etc..在本节中,We conduct an empirical investigation of these techniques,Hope to sort out their contribution and significance.然后,We will combine the insights gained,in order to achieve state-of-the-art on many of the tasks we considered.由于NLPThe migration of learning is a fast developing area of research,So we cannot cover all possible in the empirical research on technology or idea.For a broader literature review,我们推荐Ruder等人(2019年)最近的一项调查.
The following will set the way from the baseline、模型架构、unsupervised goal、预训练数据集、迁移方法、Comparison of experience with scaling and other aspects.
Baseline
Baseline aims to reflect typical modern practice.We use the denoising target to de-TransformerArchitecture for pre-training,Then fine-tune each downstream task separately.
Model
We found that using the standardencoder-decoderThe structure can achieve good performance on both classification and generation tasks.We explore the performance of the different model structure.模型的encoder和decoder使用了和Bert-base相似的尺寸,encoder和decoder包含了12个堆叠块,The dimension of the output layer of the feedforward neural network is3072,The parameters of the final model are220million个,大约是Bert-base的两倍.shared self-attention12个头,每个头维度为64,隐藏层维度为768,使用了0.1的dropout.
BERT-base详见论文:[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (arxiv.org)
Training
如前面所述,All tasks are formulated as text-to-text tasks.This allows us to always use the standard maximum likelihood for training,i.e. using teacher forcing and cross-entropy loss.对于优化,我们使用AdaFactor.在测试时,We use greedy decoding(i.e. select the highest probability at each time steplogit).
AdaFactorSee optimizer concepts for details:AdaFactor优化器浅析(附开源实现) - 科学空间|Scientific Spaces
We use oh maximum sequence length512和128的batch_size,Then each model can obtain 个tokens.我们在C4last time
个tokens.我们在C4last time 步预训练.The entire model is pre-trained
步预训练.The entire model is pre-trained 个tokens.这远比BERT(137B)和RoBERT(2.2T)少.我们预训练的tokenQuantity gains a reasonable computational cost,But still need to provide enough pre-training to get acceptable performance.
个tokens.这远比BERT(137B)和RoBERT(2.2T)少.我们预训练的tokenQuantity gains a reasonable computational cost,But still need to provide enough pre-training to get acceptable performance. 个token仅仅占了C4part of the corpus,So we will not repeat the training data during pre-training.
个token仅仅占了C4part of the corpus,So we will not repeat the training data during pre-training.
我们还使用了“inverse square root”The learning rate schedule for ,其中nIndicates the number of iterations of the current training,k是warm-up步骤的数量(Set in the experiment10000).对于前10000The learning rate in steps is set to0.01.Then, in the form of index vector decay,until the end of training.Among them, the effect of using trigonometric functions is a little better when the training steps are known,But for generality, the learning rate scheduling method mentioned earlier is used..
,其中nIndicates the number of iterations of the current training,k是warm-up步骤的数量(Set in the experiment10000).对于前10000The learning rate in steps is set to0.01.Then, in the form of index vector decay,until the end of training.Among them, the effect of using trigonometric functions is a little better when the training steps are known,But for generality, the learning rate scheduling method mentioned earlier is used..
To trade off low- and high-resource tasks,Our model performed on all tasks step fine-tuning,In the fine-tuning used a length of512,batch_size为128的输入.我们使用了0.001的恒定学习率.每5000save a checkpoint and compare performance,Also select the best checkpoint for each task independently.
step fine-tuning,In the fine-tuning used a length of512,batch_size为128的输入.我们使用了0.001的恒定学习率.每5000save a checkpoint and compare performance,Also select the best checkpoint for each task independently.
Vocabulary
我们使用SentencePieceCut out the texttoken用于wordpiece.Since we ended up adapting the English model to German、French and Romanian translation,So we also require that our vocabulary must cover these non-English languages.为了解决这个问题,我们将C4The pages used in are divided into German、French and Romanian.然后,我们在10 part的英语C4Train our sentence fragment model on the data,其中1 partData is divided into German、French and Romanian.This vocabulary is shared in both the input and output of our model.请注意,Our vocabulary enables our model to only handle a predetermined set of、fixed language set.
SentencePiece 与 WordPiecesee the concept of:wordpiece和sentencepiece - 知乎 (zhihu.com)
Unsupervised Objective

Baseline Performance
在本节中,We will demonstrate the results using the baseline experimental procedure described above,to see what kind of performance we achieve on downstream tasks.理论上,We should repeat the experiment multiple times on a task to obtain a confidence interval.但是,this is very expensive,because we need to run a lot of experiments.作为代替,We train the extreme model from scratch10次(Use different random initialization and shuffle datasets),The variance on these runs of the baseline model is assumed to hold for each experimental variable as well.We do not expect most of the changes we make to have a significant effect on the variance between runs,So this should provide a reasonable indication of the importance of the different changes.另外,We also measured that without pre-training,for all downstream tasks 步(The same numbers we use for fine-tuning)The performance of the trained model.This gives us an idea of the benefits that pretraining brings to the model in the baseline setting.以下是部分实验结果:

When reporting results in the main text,We report only a subset of all benchmark scores,to save space and facilitate interpretation.对于GLUE和SuperGLUE,我们在“GLUE”和“SGLUE”All subtasks are reported under the heading of(According to official benchmarks)的平均分数.对于翻译任务,使用BLUE作为评测标准,使用expsmooth andintl.对于摘要任务(CNN/Daily),使用ROUGE-1-F,ROUGE-2-F,ROUGE-L-F作为评测标准,The image above uses onlyROUGE-2-F,SQuAD使用F1value as a criterion.
Architecture
Although the transformer was originally passed through the encoder-Introduced by the decoder architecture,But a lot aboutNLPModern work on transfer learning uses alternative architectures.在本节中,We will review and compare these architectural variants.
Model Structures
The main difference between the different architectures is that the different attention mechanisms use“mask”.Each entry of the output sequence is produced by computing the weighted average of the entries of the input sequence.例如, represents the first in the outputi个元素,
represents the first in the outputi个元素, 表示输入序列中的第j个元素.
表示输入序列中的第j个元素. ,其中
,其中 By the mechanisms as attention
By the mechanisms as attention 和The scaling weights produced by the function of.然后,Attention masks are used to remove specific weights,to limit the input entries that can be noted at a given output time step.由下图可知,The causal mask will设置为0,如果
和The scaling weights produced by the function of.然后,Attention masks are used to remove specific weights,to limit the input entries that can be noted at a given output time step.由下图可知,The causal mask will设置为0,如果 .
.

在本文中,We first considered aencoder-decoder结构的模型,The left-most diagram below represents this architecture.The encoder part uses afully-visible的注意力矩阵,A causal masking mode is used in the decoder,When generating the first part of the output sequencei个token时,Causal masking prevents models from paying attentionthe first of the input sequencej个token,Therefore the model cannot see into the future when producing the output.
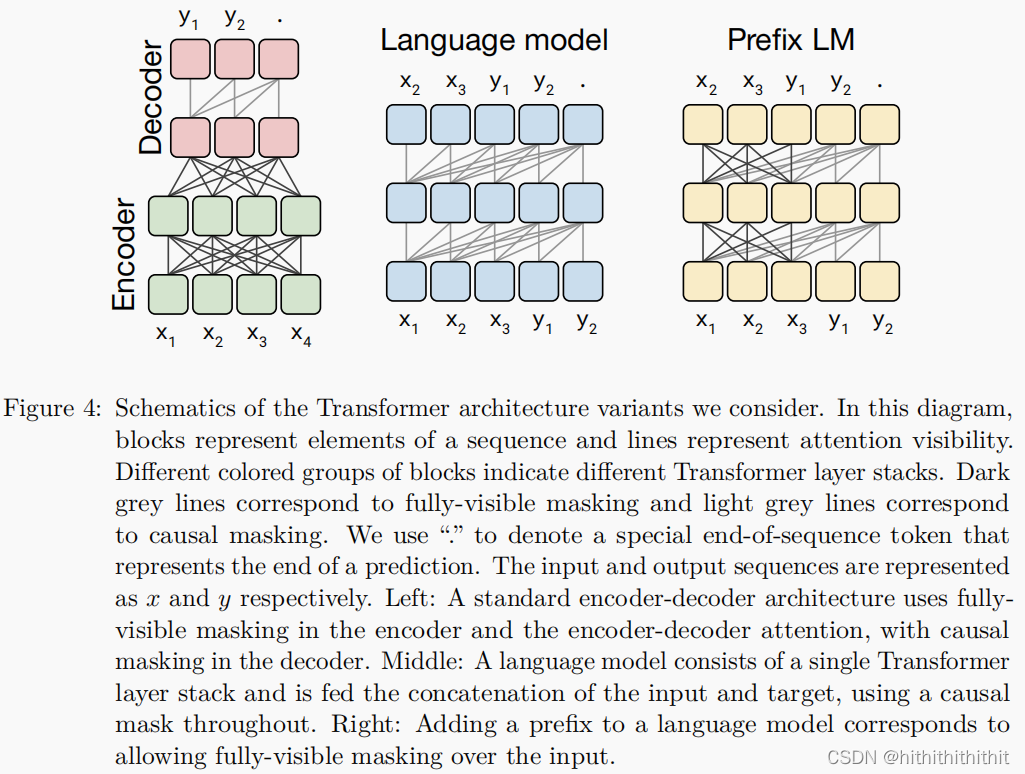
A fundamental and oft-cited disadvantage of using language models in a text-to-text setting is that,Causal masking forces the model toi个tokenThe representation of depends only on up to thei个tokenprevious entry.To understand why this could be a potential disadvantage,Consider text to text frame,before being asked to make a prediction,Model provides a prefix/上下文(例如,prefix is an english sentence,The model was asked to predict German translations).under complete causal masking,The model's representation of the prefix state can only depend on the prefix's prior entries.因此,When predicting the entry of the output,The model will notice the unnecessary restrictions prefix said.在transformer的结构中,This is completely abandoned,because we use an encoder tofully-visible 前缀/上下文.This prefixLm和Bert的区别在于,If we deal with the task of natural language inference.We generate goals based on premises and assumptions,在Bert中,We use the classifier[CLS]to classify text,然后在Prefix LMIn we directly predict the type of the word behind the target as implicit、矛盾、Neutral equivalent words to classify text.因此前缀Lm和BErtThe difference is when the classifier is integrated intotransformer的解码器中.
Comparing Different Model Structures
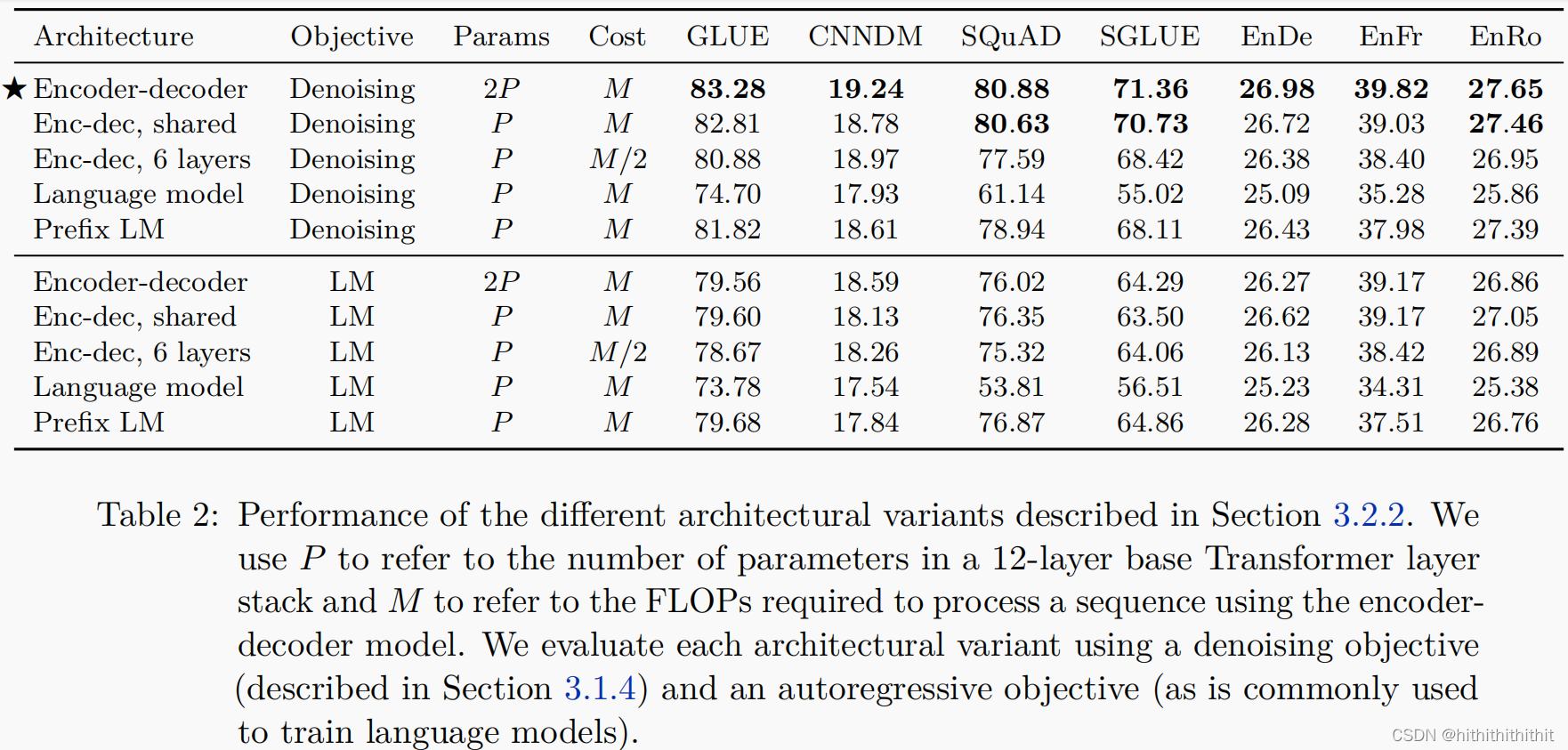
我们对encoder-decoder、encoder-decoder shared、encoder-decoder, 6 layers、Language Model、Prefix LMSeveral models with different structures were compared.对比结果如下图所示,其中PIndicates the amount of parameters,MSaid computational cost.我们分别在MLM和LMTwo training objectives trained the language model.
从上图中,We came to the following series of conclusions:
1、在所有的任务中,去噪的encoder-decoderArchitecture performs best;
2、encoder-decoderAlthough the parameter quantity is2P,However, the computational cost and the amount of parameters areP的模型一样;
3、共享参数的encoder-decoderalmost normalencoder-decoder一样好;
4、相比之下,Halving the number of layers in the encoder and decoder stack can significantly impact performance;
5、Sharing parameters between different blocks can be an efficient way to reduce the total parameters without sacrificing a lot of performance;
6、Shared parameter codecs are preferred over decoder prefixesLM,This shows the explicit encoder-Decoder Attention is Beneficial.
7、Denoising training targets perform better than language model targets;
Unsupervised Objectives
The choice of unsupervised target is very important,Because it provides a mechanism for the model to acquire generic knowledge to apply to downstream tasks.
Disparate High-level Approaches
This paper compares three different training objectives:1、LM;2、MLM(BERT-style);3、deshuffling objective:This method uses a scrambled sequencetoken,disrupt it,Then use the original marker sequence as the target.For details, see the first three lines in the figure below..

Experimental results of the three training target as shown in the figure below,MLM取得了最好的效果.

Simplifying the Bert Objective
To further improve the performance of the pre-training stage,The best results we obtained based on the above,继续在BERT-styleimprovements on the model.We consider using a simplifiedBERT-style的训练目标,which does not include random exchangetoken.The resulting goal is simply to replace the15%的标记,and train the model to reconstruct the original sequence.Song等人(2019年)Similar masking targets are also used,并将其称为“MASS”,So we call this variant as“MASS风格”目标.其次,We are very interested in,And see if it is possible to avoid predict text span the whole is not damaged,Because this requires self-attention on long sequences in the decoder.We used two strategies to achieve:首先,we used a unique masktokento replace each successive damagedspan,而不是使用mask tokento replace a damagedtoken.其次,其次,We also considered a variant,where we simply completely remove the broken tokens from the input sequence,and reconstruct the removed marked model in order.具体如上图Table3Five or six lines.
The image below shows the originalbertAn empirical comparison of style goals with these three alternatives.我们发现,在我们的设置中,All of these variants perform similarly.But both variants do not require the complete original sequence,All their target sequences are shorter during training、训练速度更快.

Varying the Corruption Rate
We compared the effect of different destruction rates on model performance,具体如下图所示,Ultimately we believe that changes in the destruction rate have limited impact on experimental performance.50%The destruction rate results in a significant drop in performance,Using a larger ground breaking rate will result in the target sequence being too long,thereby reducing the speed of training,In the end we took andBERT一样的15%damage rate.

Corrupting Spans
Now we intend to speed up training by predicting short sequences.对于每个token我们使用iiddecide whether to sabotage.当多个连续的token被破坏时,We use the only singlemask token去代替它.So that we will get a shorter input sequence.由于我们使用iid决策,All consecutive large amounts of damagetoken的情况比较少,So we will use destroyspan的方式来加速,predict the destructionspanCan speed up performance.We use parameterized goals to destroy15%的tokenand destroyedspan总数.例如,对于500个token的序列,random destruction15%的token,也就是75个token,然后破坏25个span,then destroyedspan的平均长度为3.如下图所示,我们使用了2、3、5、10The destroyed averagespan长度.Destroyed in different lengthsspan性能如下:

通过上表可以看出,Different lengths are destroyedspanThere is little performance difference between,but longspanwill speed up the training time.
Disscussion
如下图所示,Our goal for training,sabotage strategy,Destruction Rate and DestructionspanThe length of a series of comparisons.

图5A flowchart showing the choices we made in exploring the unsupervised target. The most obvious change we observed is that the training target for denoising is better than the language model and the way to shuffle.We did not observe a significant difference across many of the variants we explored for denoising objectives.然而,不同的目标(or parameterization of the target)may result in different sequence lengths,resulting in different training speeds.This means that the choice among the denoising targets we consider here should be made mainly on the basis of their computational cost.我们的研究结果还表明,Additional exploration of goals similar to those we consider here may not bring significant benefits to the tasks and models we consider.相反,Exploring completely different ways of exploiting unlabeled data may be accidental.
Pre-training Data set
And unsupervised training goals,The pretraining dataset itself is also a key part of the transfer learning process.But new pre-training training sets are often overlooked,Usually we only consider the dataset when proving the effectiveness of a new method or model.因此,There are relatively few comparisons between different training sets,Also lacks a standard training set for pre-training.For a more in-depth look at the impact of the pre-trained training set on performance,在本节中,we are tiredC4Variants of the training set and other potential sources of pretraining data.
Unlabelled data sets
在创建C4的时候,We used different heuristics to get fromCommon CrawlFilter the extracted web text from.我们感兴趣的是,In addition to comparisons with other filtering methods and common pre-training datasets,We also need to measure whether this filtering improves the performance of downstream tasks.为此,We compare the performance of pretrained baseline models:

Pre-Training Data Set Size
同时,This paper also considers the impact of different sizes of data on performance.

Training Strategy
到目前为止,We have considered a setup,i.e. all parameters of the model are pre-trained on the unsupervised task,Then fine-tune on a single supervised task.虽然这种方法很简单,But downstream of various training models have been proposed/Alternatives to Supervised Tasks.在本节中,In addition to our approach to simultaneously train models on multiple tasks,Different schemes for fine-tuning the model are also compared.
Fine-tune Methods
Transfer learning results for text classification tasks advocate fine-tuning only the parameters of the classifier,This classifier is fed into the sentence embeddings produced by the pretrained model.This method is not very suitable for our encoder-解码器模型,Because the entire decoder must be trained to output the target sequence for a given task.相反,We will focus on two alternative fine-tuning methods,They only update our encoder-a subset of the parameters of the decoder model.
The first optional method is to useadapter learning,Add to the original pretrained network aadapter layer,Then we just updateadapter的部分参数.具体做法是对TransformerAdd a middle prefix after the neural networkdense-ReLU-dense块.
The second optional method is“gradual unfreezing”,随着时间的推移,More and more parameters will be updated.The strategy taken is gradually thawed from the network block at the end to the entire model.To adapt this approach to our encoder-解码器模型,We start to unfreeze all the layers in the encoder and decoder step by step starting from the top.Since the parameters of our input embedding matrix and output classification matrix are shared,So we update them throughout fine-tuning.实验结果如下图所示:

实验结果表明,像SQuADsuch low-resource tasks in smallerdThe value below works fine,While high-resource tasks require larger dimensions to achieve better performance.在实验中,Although it is true that the thawing accelerated the speed of training,But it caused a slight drop in performance.
Multi-Task Learning
到目前为止,We have pretrained our model on a single unsupervised learning task,Then fine-tune on each downstream task individually.另一种方法,被称为“多任务学习”,Train a model on multiple tasks at once.This approach shares the parameters of the model in each task,Train all tasks at once.Since we are using a unified generative framework,Multi-task learning is simply mixing all datasets together.因此,When using multi-task learning,We can do this by mixing the unsupervised task as one of the tasks,Can still train on unlabeled data.相比之下,multi-task learning pairNLPApplications of adding task-specific classification networks or using different loss functions for each task.An important factor in multi-task learning is how much data the model should train from each task.Our goal is to make the model perform well on each task,rather than overtraining or undertraining,It's not that the model has seen too much data.How exactly to set the scale of data from each task may depend on various factors,Include the size of the dataset、learning task“难度”,正则化等等.Another potential factor is“task reasoning”或者“消极迁移”,perform well on a certain task,May affect performance on other tasks.
Examples-proportional mixing Model fitting speed for a given mission of a major factor is the size of the data set.因此,A common practice is to set the scale of each task dataset.但是,请注意,We include our unsupervised denoising task,It uses datasets that are orders of magnitude larger than those for other tasks.由此可见,If we simply sampling according to the size of each data set,The vast majority of data the model sees will be unlabeled,and will be undertrained on all supervised tasks.even without unsupervised tasks,The training set for some tasks is still very large,so that other tasks are not trained enough.为了解决这个问题,We set up an artificial one before we start calculating the scale“limit”above the size of the dataset.例如,If the example of each task has 个,我们对第mThe probability of a task setting sampling
个,我们对第mThe probability of a task setting sampling ,其中KRepresents a manually set dataset size limit.K越大,More inclined to full sampling or equal proportion sampling,KYue xiaoyue tend to equal sampling.
,其中KRepresents a manually set dataset size limit.K越大,More inclined to full sampling or equal proportion sampling,KYue xiaoyue tend to equal sampling.
 设置为
设置为 ,and adjust the ratio so that their sum is1.当T=1的时候,Equivalent to the previous proportional mixing sampling,T越大,more equivalent to uniform sampling.At the same time keep a limit on the data setK,使用
,and adjust the ratio so that their sum is1.当T=1的时候,Equivalent to the previous proportional mixing sampling,T越大,more equivalent to uniform sampling.At the same time keep a limit on the data setK,使用 ,Ensure that the sampling ratio of large data sets will not be reduced too much when the temperature is too high.
,Ensure that the sampling ratio of large data sets will not be reduced too much when the temperature is too high.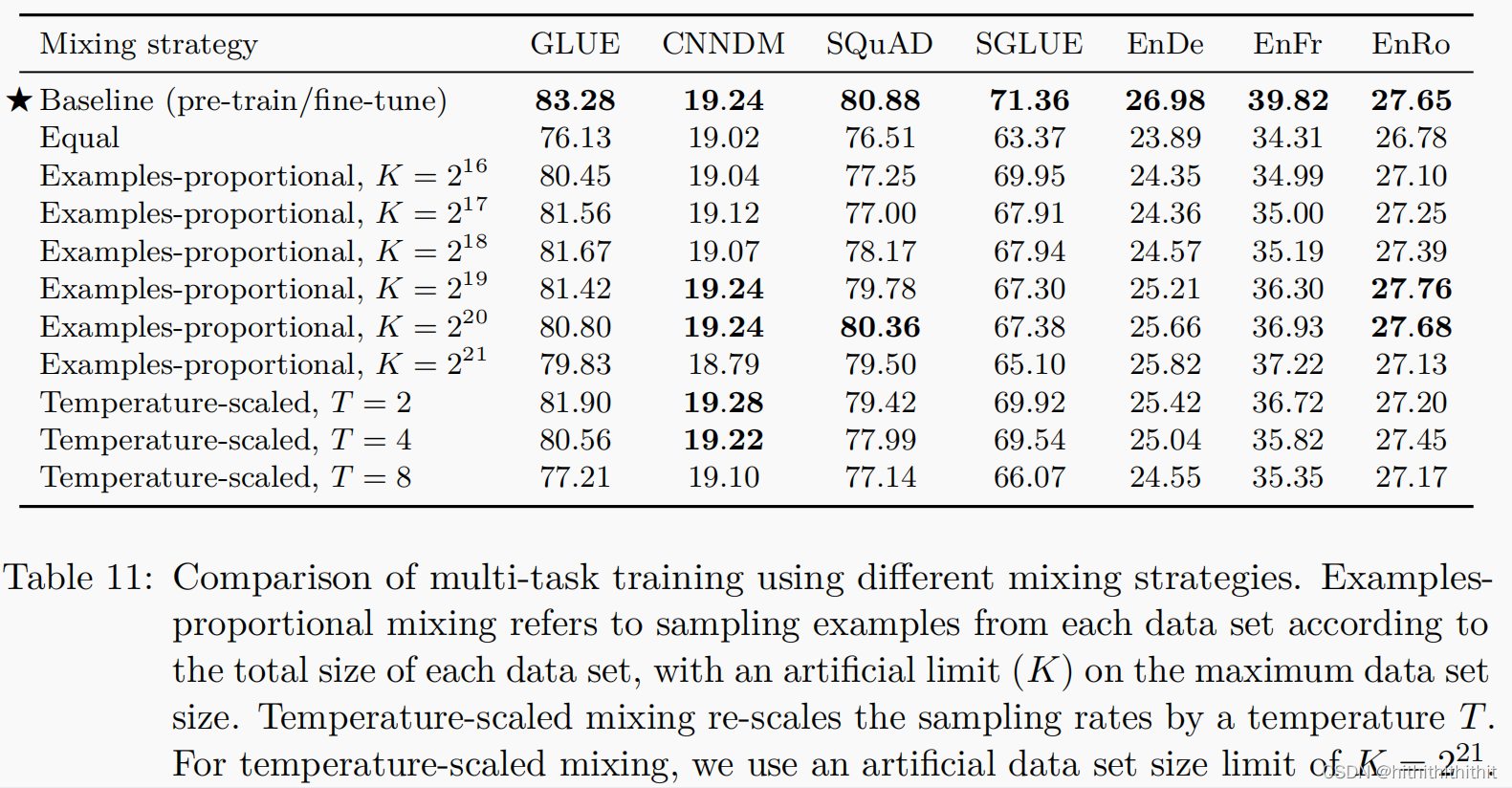
Scaling
机器学习的“Painful lessons”Think that methods that utilize extra computation will outperform methods that use human expertise.Recent research has shown that thisNLPis still true in transfer learning.也就是说,it has been proven many times,compared to more carefully designed methods,Extensions can yield better performance.Ways to scale include using larger models,多次训练模型,and the ensemble model.在这个部分,We conduct4Comparing different approaches with twice the computational performance.本实验中,We used a larger size model, Steps more training and morebatch_size和4integrated model.实验结果如下:

Putting It All Together
Through systematic research,Start with the base model and make the following changes:
Objective:我们使用了IID来对span进行破坏.具体来说,The average span length we use is3,and destroys the original sequence of15%.我们发现,This goal yields slightly better performance,However, due to the short length of the target sequence,Computational efficiency is slightly higher.
Longer training:Our model uses a relatively small amount of pre-training computation.The extra training is really useful for the performance of the model,Also increasing batch size and increasing training steps can both increase performance.使用较小的C4Variation for repetitive training is detrimental,Datasets are also important.
Model sizes:A larger model can effectively improve the performance.在计算资源有限的情况下,Use a smaller model may help.基于这些因素,We trained a model of the following dimensions:
| 尺寸 | desc | d_model | d_ff | d_kv | head | layers |
| Base | bert-base(2.2亿) | 768 | 64 | 12 | 12 | |
| Small | 6千万 | 512 | 2048 | 64 | 8 | 6 |
| Large | bert-large(7.7亿) | 1024 | 4096 | 64 | 16 | 24 |
| 3B and 11B(30亿,110亿) | 1024, | 16384,65536 | 128 | 32,128 | 24 |
边栏推荐
猜你喜欢





随机推荐
数据库治理利器:动态读写分离
idea 删除文件空行
[网鼎杯 2020 青龙组]AreUSerialz
sqlmap dolog外带数据
Initial attempt at UI traversal
组件的使用
Janus实际生产案例
ImportError: Unable to import required dependencies: numpy
Algorithm and voice dialogue direction interview question bank
web开发概述
c# 解决CS8602告警 解引用可能出现空引用
如何让数据库中的数据同步
3dmax如何制作模型走路动画
已备案域名用国外服务器会不会掉备案?
Janus actual production case
2022强网杯 Quals Reverse 部分writeup
FusionCompute产品介绍
2022.8.8考试区域链接(district)题解
Golang nil的妙用
【论文粗读】(NeurIPS 2020) SwAV:对比聚类结果的无监督视觉特征学习