当前位置:网站首页>Optimizing Bloom Filter: Challenges, Solutions, and Comparisons论文总结
Optimizing Bloom Filter: Challenges, Solutions, and Comparisons论文总结
2022-08-10 18:40:00 【桐青冰蝶Kiyotaka】
Optimizing Bloom Filter: Challenges,Solutions, and Comparisons论文总结
Abstract
从两个维度调查现有的变体,即性能和泛化
I. INTRODUCTION
现有的调查主要关注 BF 的应用,但缺乏对所提出变体的优化技术的基本理解。我们的调查集中在这些变体中采用的优化技术。
从两个维度调查现有的变体,即性能和泛化。
从四个角度介绍了改进 BF 的现有技术:
减少误报的技术、实际实现中的优化、针对不同数据集的专用设计、启用更多功能的建议。

II. BLOOM FILTERS
A. Framework of Bloom Filter

false positive rate fr: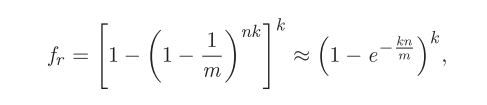
BF 长度 m、使用的散列函数数 k 、集合中的元素数 n
在给定k的情况下,为了保持固定的误报率,m的值应该随着n的值线性增加。
more accurate false positive rate of BF:

- 删除元素是不允许的。原因是直接将对应的 1 重置为 0 可能会导致其他元素的假阴性结果。
- 计数BF(CBF)通过将每个位替换为具有多个位的计数器来扩展BF。
B. Intrinsic(内在的) Characteristics of Bloom Filter
probabilistic data structure
- Space-efficient:
BF 使用 m 位向量对给定集合中的每个元素进行编程,而与元素的位表示中的位数无关。
造成的空间开销,即m的值,只与元素个数n成正比,不受元素长度的影响。 - Constant-time query:
查询U中元素的成员关系可以简化为对应k位的二进制检查。
查询一个元素的时间复杂度是 O(k),k 将是一个常数,那么插入和查询的复杂度都是 O(1)。 - One-sided error:
unavoidable false positive errors、no false negative errors(只有假阳性,没有假阴性)
C. Challenging Issues of Bloom Filter
- False positives:
通过延长 BF 的长度来降低误报率会产生边际效应。
纠正误报的元素(例如,使用白名单) - Implementation:
memory access, space utilization, computation overhead - Elasticity:弹性
BF 只能成功地表示一个静态集
参数(包括 m、n 和 k)是预定义的,使用的哈希函数一旦选择就不能更改。 - Functionality:
支持快速会员查询、插入和查询
III. APPLICATIONS OF BLOOM FILTERS
A. Content Caching 内容缓存
特定元素 x 的访问首先指向 BF。
如果 BF 指示 x 是缓存中的元素,则访问尝试从缓存中读取该元素。
如果 BFs 判断 x 没有被缓存存储,则请求会直接从主存中取出 x,而不访问缓存。
BF 消除了不必要的缓存读取
B. Packet Routing and Forwarding

BFs in Wired Networking: In traditional wired networks,BFs are widely used to speed-up IP lookups, enable multicast,support named data forwarding.
两级 BF。 建议将名称前缀拆分为 B 前缀和 T 后缀。 B-prefix 由 BFs 匹配,而 T-suffix 由小规模 trie 处理。
BFs in Wireless Networking: In wireless networking, BFs are mainly utilized to represent the routing table and support fast lookups in each node.
C. Privacy Preservation
在成员查询的支持下匿名化
通过将数据库中的记录编程为 BF 来匿名化它们,从而实现近似匹配。
- 在快速位置查询的支持下隐藏了用户的实际位置
- 使用 BF 表示这些生物特征数据,并启用基于成员资格查询的身份验证机制。
- 基于BF的方法来击败DoS攻击
D. Network Security
advanced metering infrastructure (AMI) 电网高级计量基础设施(AMI)网络
为 AMI 网络提出了基于 BF 的撤销方案,该方案可以使仪表能够识别和消除误报。
E. Gains of Using BFs
- Constant-time query (CQ)
- Space saving (SS):
- Access refinement 访问细化(AR): BF 将元素汇总为位(或单元)向量并过滤不必要的元素访问。
- Content anonymization (CA):

IV. REDUCTION OF FALSE POSITIVES
false positive proportion 假阳性比例(FPP)和 false positive rate假阳性率(FPR)
FPP 可以用作 FPR 的点估计。 FPR 是一个固定值,由 BF 框架本身决定,而 FPP 是可变的,围绕 FPR 的值波动。
S 表示由 BF 表示的集合,Q 表示要查询的元素,T 记录成员查询返回正数的元素。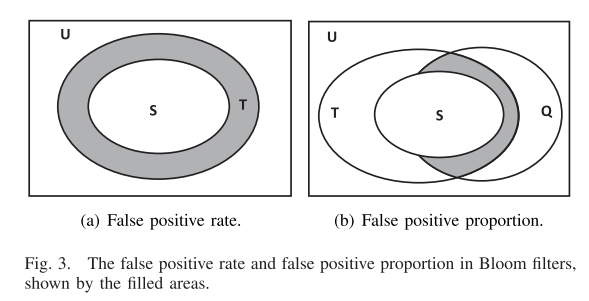
F = T−S
fr = |F|/|U| = |T − S|/|U|
fp = |(T ∩ Q) − (S ∩ Q)|/|Q|.
如果非零位被重置为 0,则不会发生潜在的误报错误。但这反而会引入假阴性错误的可能性。
A. Reducing FP With Prior Knowledge
如果要查询的元素 (Q) 被称为先验知识,则 BF 用户可以选择产生最少 FP 的哈希函数。
- Multi-class BF
通过设置更严格的条件以通过查询,从集合 T 中删除了一些可能导致误报概率较高的元素。 - False-positive-free multistage BF (FPF-MBF) 无误报多级 BF:
采用多级BF来记录多播树的每个阶段中的链接。
FPFMBF 的设计理念是达到 (T−S) ∩ (Q−S) = ∅ 的目标,其中 Q 是要查询的已知元素集。因此,所有查询的元素都不会被误匹配,它的表现与误报比例为 0 一样。 - Bloom paradox:
对于误报,用户仍然需要访问主存储器。
阳性查询结果为假阳性的概率可以评估为:
M、C、T分别是主存中的元素、缓存中的元素和主存中查询BF时导致肯定结果的元素
正查询结果为假正的概率几乎为 1−10^-3,BF对各种元素的阳性结果中,大部分是误报。 - Optihash:
S是在 optihash 中编码的一组元素(S 可能是多重集),散列函数 h 将 S 中的元素映射到通常较小的集合 R。逆 h-1 将散列集 R 映射到一组元素大于 S。令 Q 表示要查询的元素集合,则假阳性元素集合 F 可以导出为 F =(h−1 ∩ Q) - S。
B. Reducing FP With the One-Sided Error
BF 得出的元素 x 不是 S 的成员的结论是 100% 正确的。
C. Reducing FP via Bit Resetting
试图通过直接调制位向量来减少误报。
- Retouched修饰 BF:
通过允许以产生随机假阴性为代价去除选定的误报,从而使 BF 更加灵活
将所选位从 1 重置为 0 来清除。 - Generalized广义bf
采用两组散列函数,即{g1,… gk0}和{h1,… hk1}。将元素插入位向量时,哈希函数 {g1,… gk0 } 映射的 k0 位重置为 0,而哈希函数 {h1,… hk1} 导出的 k1 位设置为1(通过保持重置来打破平局)。广义BF查询元素x时,检查位置{g1(x),… gk0(x)}对应的位是否全为0,位{h1(x),…hk1(x)}都是1。如果至少一位反转,广义BF返回否定查询结果;否则,它返回一个肯定的结果。 - Multi-partitioned Counting 多分区计数BF (MPCBF):
为了减少内存访问次数,MPCBF 将 m 个单元划分为 l个字,以便每个字都可以在一次内存访问中获取 。不理解
为了减少误报,MPCBF 建议将每个单词重构为层次结构。
D. Reducing FP With Selected Hash Functions
BF 的误报率与位向量中 1 的数量成正比。
基本思想是使用两组(或更多)散列函数,插入将使用增加位向量中最少1的散列函数组。
代价是更多的哈希计算和查找。
E. Reducing FP by Differentiated Representation
通过微分表示减少 FP
variable-increment counting BF可变增量计数 BF 和fingerprint counting BF指纹计数 BF 寻求通过元素的差异表示来降低 FPR 的方法。
与 CBF 不同,当插入一个元素时,VI-CBF 的计数器按散列变量增量而不是单位增量来增加
VI-CBF 由两个计数器向量组成:第一个计数器向量记录散列到该位置 (C1) 的元素数量,第二个计数器向量提供这些的权重和具有不同增量的元素 (C2)
FP-CBF 用唯一指纹标记元素 。
F. Summary and Lessons Learned
用户可能会权衡误报的影响和降低 FP 的引入成本。
V. OPTIMIZATIONS OF IMPLEMENTATION MEASUREMENTS
性能还可以进一步提高,四个实际测量:
computation complexity, memory access, space efficiency, energy consumption.
A. Computation Optimization
为了减少由于散列函数引起的计算开销,最先进的技术尝试仅使用一个或两个散列函数来生成多个独立的散列值。使用生成的哈希函数不会增加渐近误报率。
- OneHashBF(OHBF):
只用一个哈希函数生成 k 个哈希值。 - Distributed Load Balanced BF (DLB-BF):
分布式负载平衡 BF,专为 IP 查找(最长前缀匹配)而设计
DLB-BF 将单个 BF 向量划分为多个 BF,从而实现并行性,即 k 个 BF 可以同时访问,然后对 k 位进行按位与运算将生成查询结果。 - Combinatorial BF:
具有多个组的 S 的成员资格查询 - Ultra-Fast BF (UFBF):
直接并行化哈希函数的计算和检查过程。
与标准BF相比,UFBF被证明具有更高的误报率。
B. Memory Access
完成成员资格查询,必须读取 k 位
当数据集中的元素数量发生变化时,它们必须重新构建。缺乏可扩展性使它们无法表示动态集。
- Bloom-1:
询一个元素,只需要一次内存访问。如果所有 k 位都不为零,则 Bloom-1 得出元素属于该集合的结论 - OMASS:
专注于集合分离的问题,即识别元素 x 属于哪个集合。
只需要一次内存访问即可解决集合分离问题,而不会增加误报率。
C. Space Efficiency
为了实现最小误报率,标准BF中的比特利用率仅为50%
- Compressed BF:
压缩bf,使用更少的散列函数 k 和更多的比特 m 来保证比标准 BF 更少的误报率和更少的比特传输。 - Compacted BF:
与Compressed BF类似,Compacted BF 在传输前减少位向量的长度以节省带宽。 - d-left counting BF (dlCBF):
用 d-left 散列函数替换 CBF 中的一般散列函数
为了插入元素 x,散列函数将 x 映射为位串。生成的位串被分成 d+1 段。前 d 段提供候选位置来记录 x 的指纹。最后一段被视为 x 的剩余部分。此后,x 的其余部分将存储在 d 个候选者中负载最小的单元格中。 - Memory-optimized BF:
引入了一个额外的哈希函数来从 k 个候选单元格中选择一个单元格来存储 x
该元素将只存储一次,不再需要其他 k-1 个重复项 - Matrix BF:
- Forest-structured BF (FBF):
一旦 BF 超过 RAM 大小,辅助存储器(例如基于闪存的 SSD)将成为替代方案。
D. Energy Saving
Pipelined BFs:

Energy efficient BF (EABF):
通过自适应调整第 2 阶段哈希函数的状态来增强两阶段查询方案。L-CBF:
L-CBF 在查询速度和节能方面明显优于基于 SRAM 的实现。惩罚是 3.2 × 空间占用。
E. Summary and Lessons Learned

VI. REPRESENTATION OF DIVERSE SETS
我们将相关建议分类为多集、动态数据集、带加权元素的数据集、键值系统、序列数据和空间数据。
A. Multisets
多集
简单集合是多重集合的一种特殊情况,其中所有元素最多只出现一次。
表示多重集的主要挑战是不仅要正确记录元素的存在,还要正确记录相关的多重性。
- Space-Code BF (SCBF):
采用 g 组散列函数将元素映射到共享位向量。
SCBF 可能适合空间稀缺但计算能力充足的设备。 - Spectral BF:
光谱bf,支持多集元素的近似多重性查询。
插入类似于 CBF,查询时Spectral BF 使用 k 个计数器中的最小值作为 x 的多重性的估计量。 - Invertible Counting BF (ICBF):
可逆计数 BF ,实现两个给定多集之间的快速有效同步。 - Loglog BF:
日志记录bf, 引入了概率计数策略来估计每个记忆多集元素的频率。
除了成员查询的显式误报率外,Loglog BF 还通过引入概率计数策略为 BF 范式引入了额外的计算成本。 - Adaptive BF:
自适应bf,通过散列函数的数量来判断元素的多重性。
Adaptive BF 不支持删除 - Shifting BF:
移位 BF 使用其他 k 位来存储辅助信息,例如多重性或从属关系。
变体中总是存在权衡,用计数器重新编码多重性会产生额外的空间开销,而将额外的位设置为 1 会影响成员资格查询的准确性。
B. Dynamic Sets
BF 设计用于静态数据集的表示和成员查询
为了克服在动态数据集中使用 BF 的障碍,提出了几个紧凑的变体。
- Variable length signatures:
与BF不同的是,可变长度签名仅在插入时将t≤k位设置为1,并且如果至少q≤t≤k位不为零,则得出x∈S。
要删除流 x,至少将其签名的 k-d 设置为 0,其中 d<q,因此 x 不会被声明为流集 S 的成员。 - Dynamic BF (DBF):
最初,只有一个 BF 处于活动状态,一旦当前 BF 已满,另一个未开发的 BF 将被激活。
除了删除之外,DBF 还支持通过联合操作合并两个活动 BF 的功能。
高误报率 - Scalable BF:
由一系列异构 BF 组成。可以区分每个子BF的参数。 - Dynamic BF Array (DBA):
DBA 致力于为存储系统实现可扩展且节省空间的近似数据结构。 - Par-BF:
Par-BF 支持成员查询的并行性。
C. Weighted Sets
有些元素可能会被频繁查询,而有些则可能不会。
- Weighted BF:
加权 BF建议根据查询频率和成为集合 S 成员的可能性来调整不同元素使用的哈希函数的数量。 - Popularity Conscious BF:
Popularity Conscious BF为散列函数的数量预先定义了 kmax,然后将散列函数分配给每个元素的问题描述为非线性整数规划问题。
D. Key-Values
键值(KV)存储系统处理大量的键和对应的值,支持密钥查找和 KV 对插入。
- BloomStore:
键的空间被划分为多个不相交的范围,每个范围都映射到一个专用的 BloomStore 实例。
BloomStore 具有天然的可扩展性,并且支持通过在相应的 BF 位中的键中插入空值来进行删除。当然,聚合的误报可能性相对较高。 - kBF:
kBF不是直接保存 KV 对,而是根据给定的约束将值转换为固定长度的字符串位。 - Invertible Bloom lookup table (IBLT):
IBLT 不仅支持键值对的插入、删除和查找,还允许其包含的键值对的完整列表,只要包含的键值对的数量低于设计的阈值.
E. Sequence Sets and Spatial Sets
序列集和空间集
- k-mer BF:
映射子序列之间的内部依赖关系可以用来降低成员查询的误报率。
两个相邻的 k-mer 共享 k-1 个公共字符。因此,可以利用邻居的存在信息来进一步判断查询子串的成员资格。 - Spatial BF:
考虑位置信息,考虑隐私保护。为此,将用户的位置划分为不同的兴趣区域。
F. Summary and Lessons Learned
BF 范式可以扩展到表示和支持对多集 、动态集、倾斜数据集、KV 对 、序列集、空间数据 等。
VII. FUNCTIONALITY ENRICHMENTS
在BF框架下,通过输入集,可以在不同的场景下丰富输出功能。
A. Element Deletion
元素删除
标准 BF 的一个普遍缺点是它无法从位向量中删除元素
- Deletable BF (DlBF):
Deletable BF跟踪插入元素时发生哈希冲突的位置。那么在删除一个元素时,只有无碰撞区域的位会从 1 重置为 0。 - Ternary BF (TBF):
TBF 中的每个计数器都具有三个不同的值:0、1 和 X。如果将 2 个或更多元素映射到一个计数器中,则该值被编程为 X,并且具有值 X 的计数器在查询中不被引用。
B. Element Decay
元素衰减
BF 还应该支持衰减操作,这样可以消除那些陈旧的信息,为即将到来的元素留出空间。
衰减是主动操作,由BF周期性或非周期性执行,而删除是用户调用的非主动函数。
- Stable BF:
用于重复消除连续到达的流数据流 - Temporal Counting BF (TCBF):
在插入一个元素时,k 个对应的计数器将被设置为一个给定的值,称为初始计数器值 (ICV) - Double Buffering:
以先进先出的方式驱逐过时的元素。 - A^2 Buffering:
active1 存储最近插入的元素,而 active2 记录以前插入的元素。当 active1 变满时,active2 被刷新,两个 BF 交换角色。 - Forgetful BF:
同时维护了几个活动的 BF,包括一个未来的 BF、一个现在的 BF 和一个或多个过去的 BF。
C. Approximate Membership Query
近似成员查询是回答“x 是否接近 S 中的某个元素?”的查询。
- Distance-sensitive BF:距离敏感
采用基于距离的局部敏感哈希函数将元素映射到向量中 - Locality-sensitive BF (LSBF):局部敏感
只有当所有相应的位都非零时,x 才接近 S 中的一个元素。 - Multi-granularity locality-sensitive BF (MLBF):多粒度局部敏感
通过启用多个距离粒度,在MLBF 中进一步改进了局部敏感哈希函数的使用。
D. Enrichment of BF Semantics
BF语义的丰富
BF 的一个先天缺点是它只保存了成员信息,而缺少元素的其他特征。因此,需要丰富BF语义来支持更多类型的查询。
- Invertible BF (IBF):
可逆bf,每个元素都有一个唯一的二进制标识符,数据集的 IBF [145] 向量包含 m 个单元,每个单元有三个字段。 idSum 记录映射到该单元格的元素标识符的异或结果。计数计算映射到此单元格的元素数。
尝试从单元向量中反向解码元素。他们都选择一个只记录一个元素的单元格作为锚点,从而一个一个地返回元素。 - Bloomier filter:
Bloomier 过滤器扩展了 BF 理论,不仅可以存储成员信息,还可以存储以 S 中的元素为输入的函数值。因此,Bloomier 过滤器还支持对与元素关联的函数值的恒定时间查询。 - Parallel BF:
Parallel BF 是一个 CBF 矩阵,由 P 个子矩阵组成,独立表示 P 个属性。
多属性元素的表示是以更多的哈希计算、空间占用和内存访问为代价的。
E. Summary and Lessons Learned
BF 只保存了成员信息,缺少元素的其他特征。这个缺点限制了BF的功能。因此,需要丰富 BF 语义来支持更复杂的功能
VIII. CLASSIFICATION AND COMPARISON
A. Techniques Towards Elements
BF 无法判断 1 是否由专用元素引起,方法是对每个元素施加唯一的指纹。
- Imposing Fingerprints to Elements:
通过将元素映射为具有哈希函数的二进制字符串来生成元素的指纹。此后,指纹可以直接存储在向量中。
- Imposing Fingerprints to Elements:
- Dividing Elements Into Independent Groups:
将集合中的元素分为多个组,然后每组元素由一个相应的 BF 表示。这将有效地隔离元素,以便它们在查询时不会相互影响。
- Dividing Elements Into Independent Groups:
B. Techniques Towards Hash Functions

1) Leveraging the Number of Hash Functions:
在给定元素数量 n 和位向量长度 m 的情况下,散列函数的最佳数量是 k = m n ln 2。
- One additional hash function:
ICBF 和 FP-CBF为每个元素生成一个指纹,该指纹具有来自给定范围的额外哈希函数。 - Multiple groups of hash functions:
建立多个分离的辅助 BF,因此在不允许共享哈希值时,它们需要多组独立的哈希函数。 - Hash functions on demand:
查询频率较高或成为 S 成员的概率较低的元素应该与更多的散列函数相关联。更多的哈希函数意味着通过检查的约束更强。
2) Optimization ofHash Implementation:
使用一个或两个散列函数生成 k 个独立的散列值。
3) Application of Advanced Hash Techniques:
d-left CBF [101] 使用 d-left 散列函数将元素的索引存储在负载最少的单元格中
Distance-sensitive BF局部敏感散列也被用来代替传统的散列函数。
C. Techniques Towards the Bit Vector
用一个单元替换每个位以存储更多信息的扩展方案,以及实现更多 BF 向量以获得更高容量的扩展方案。
- Scale-Up (Beyond One Single Bit):
支持元素删除
- Scale-Up (Beyond One Single Bit):
- Scale-Out (More BF Vectors):
当一个BF向量不够用,或者用户有多个集合要表示时,一种很自然的方式是建立多个BF。
- Scale-Out (More BF Vectors):
- The Power of Partition:
一个简单的分区方法是将位向量分成k个段,每个散列函数负责一个段。这种调整是实现并行访问的一种自然方式,代价是误报率略有增加。
- The Power of Partition:
- The Game Between 0s and 1s:
调整向量的另一种显式方法是更改位(或单元格)中的值。
- The Game Between 0s and 1s:
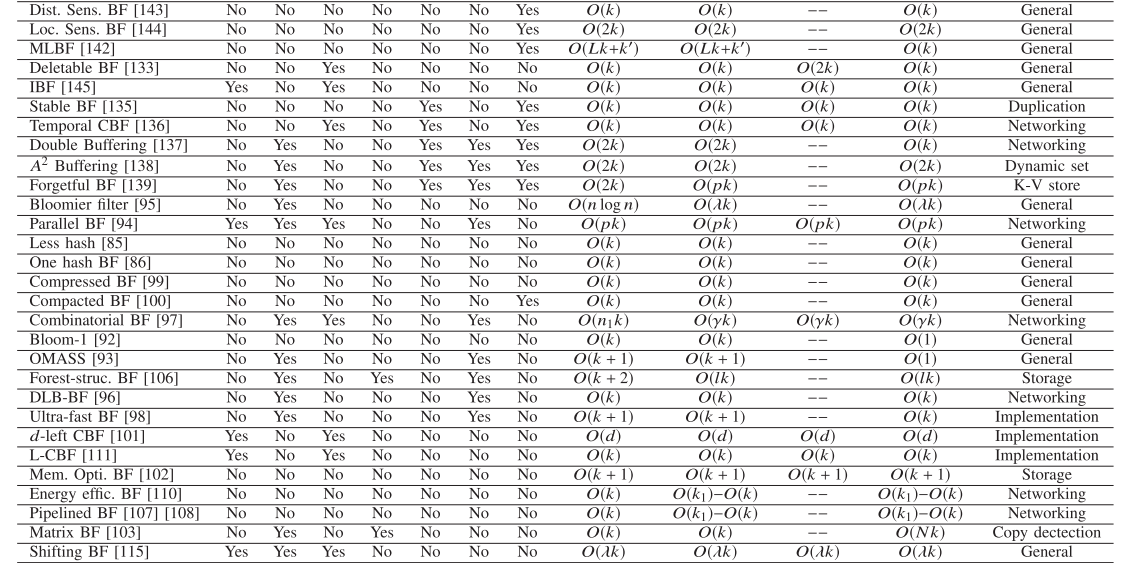
D. Qualitative Comparison

IX. SUMMARY AND OPEN ISSUES
- Implementation in extreme hardware:
F 易于部署,但是在极端硬件中实现 BF 仍然存在问题。 - Extension or downsizing at arbitrary scale:
支持容量扩展或缩减的现有变体只能在子BF的级别。 - Representation of inter-element relationships:
标准BF及其大多数变体独立地表示元素,而不考虑它们之间的内部关系。
除了元素之间的距离之外,其他类型的关系仍然超出了现有变体的能力。 - Alternates of BFs:
Cuckoo 滤波器 [150]、商数滤波器直接存储元素的指纹。 - Extensive applications of BFs:
BF 已广泛应用于各种系统中
X. CONCLUSION
为了提高性能,数十种变体致力于减少误报和实施成本。
为了减少误报,现有的 BF 变体利用先验知识、选择最佳散列函数、生成多个 BF 和查询、重置向量中的位或以差异方式表示元素。
为了进一步简化 BF 的实现,提出了十几种变体来优化其计算成本、内存访问、空间效率和能源使用。
除了元素插入和查询之外,还启用了更多的BF功能,例如元素删除、元素衰减、近似隶属度查询和语义丰富。
边栏推荐
猜你喜欢
API 网关的功能
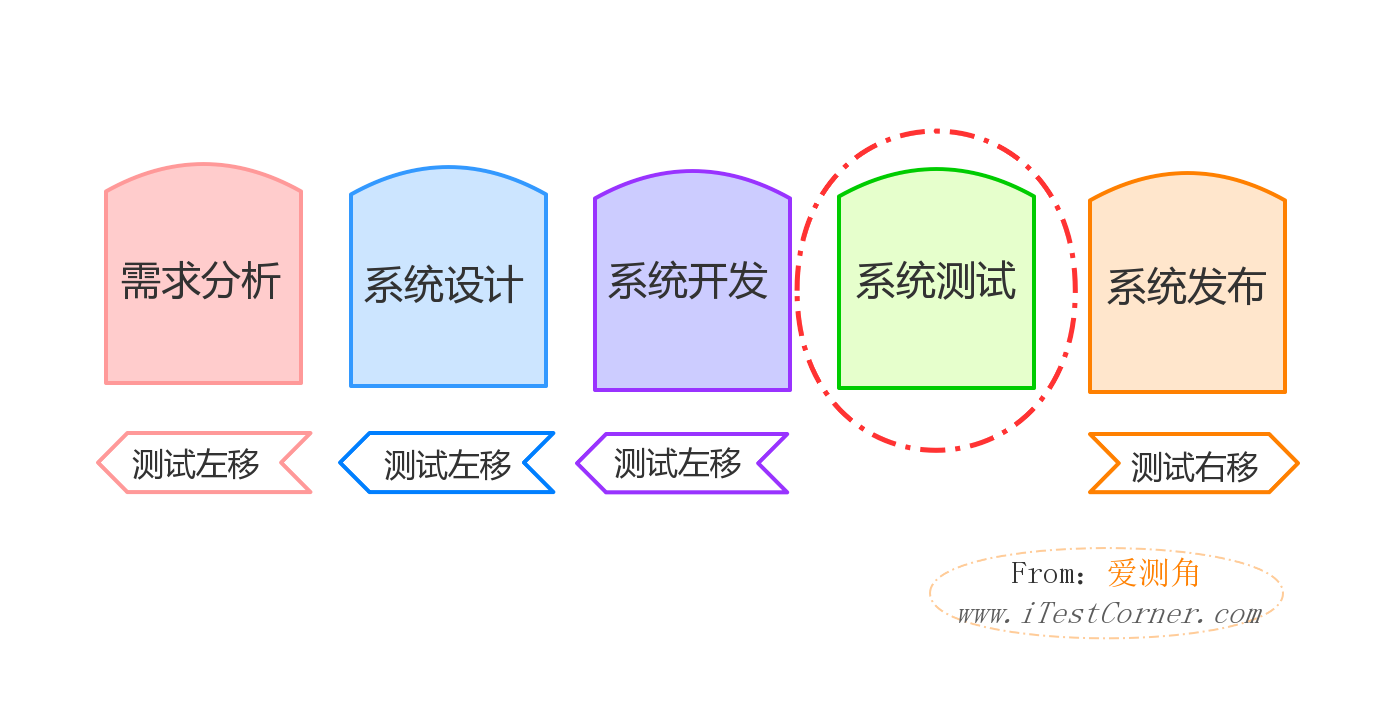
漫谈测试成长之探索——测试文档
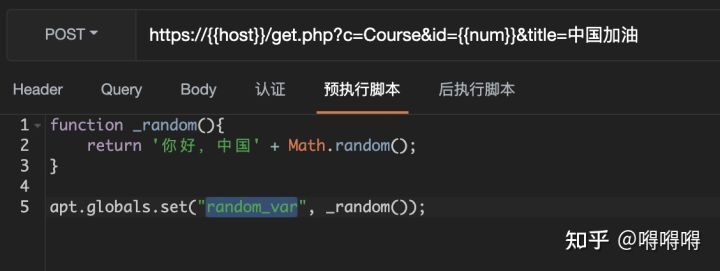
Interface test advanced interface script using -apipost (pre/post execution script)
[教你做小游戏] 斗地主的手牌,如何布局?看25万粉游戏区UP主怎么说
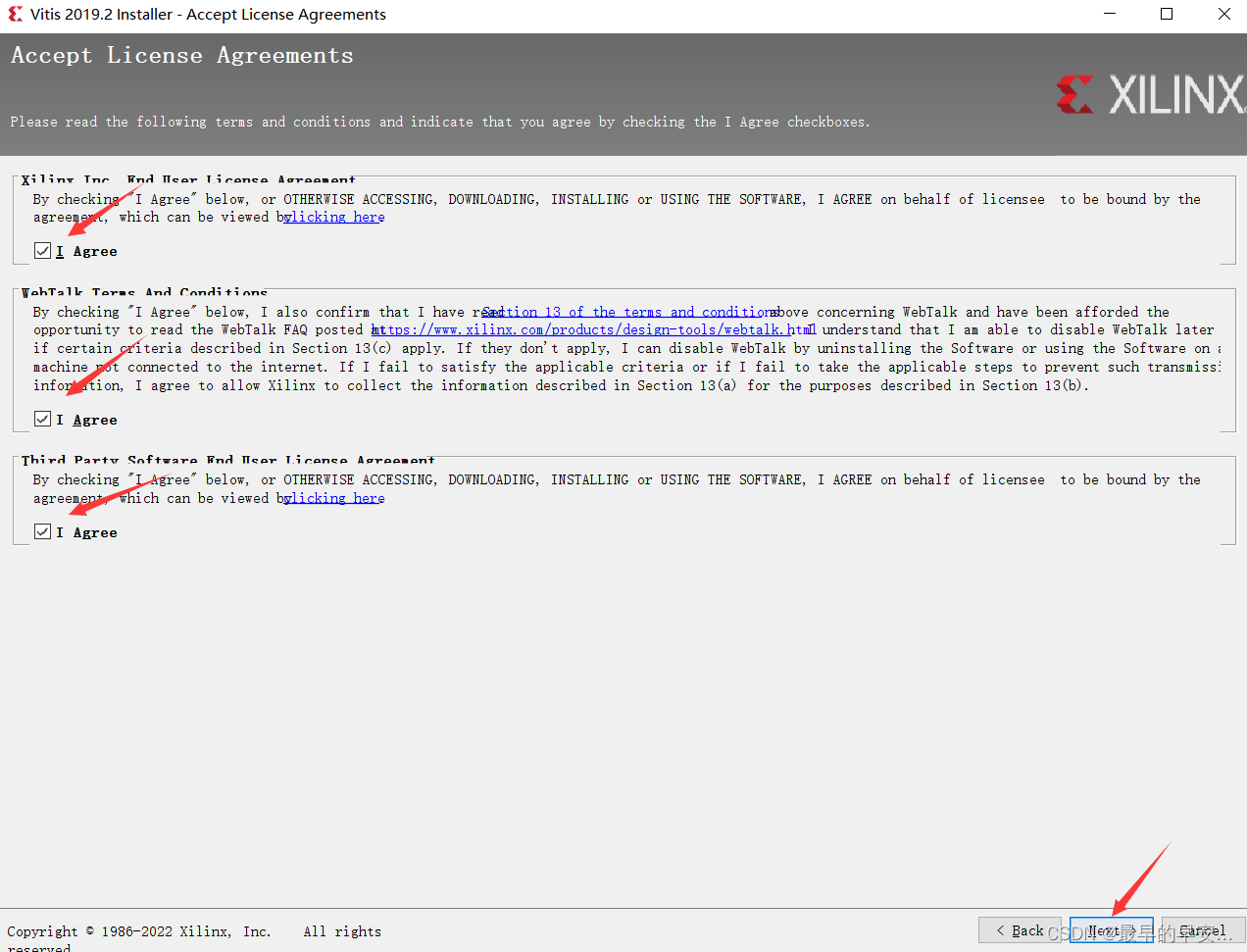
FPGA:从0开始(安装开发环境)加破解
我们用48h,合作创造了一款Web游戏:Dice Crush,参加国际赛事
Optimization is a habit The starting point is to 'stand close to the critical'
「POJ 3666」Making the Grade 题解(两种做法)
MySQL安装步骤

开发模式对测试的影响
![[教你做小游戏] 斗地主的手牌,如何布局?看25万粉游戏区UP主怎么说](/img/11/eb7278ac9ebdfbd5835d147320efe7)

随机推荐
6-11 Preorder output leaf nodes (15 points)
魔方电池如何“躺赢”?解锁荣威iMAX8 EV“头等舱”安全密码
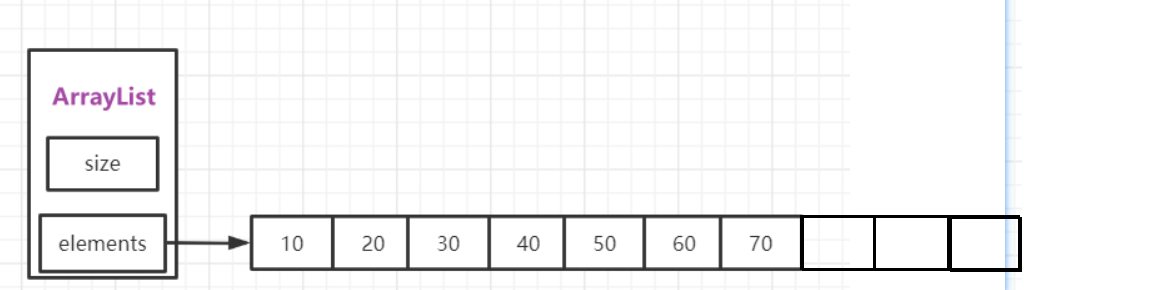
LeetCode·27.移除元素·双指针
从企业的视角来看,数据中台到底意味着什么?
FPGA:生成固化文件(将代码固化到板子上面)
关于技术分享的思考
[Image dehazing] Image dehazing based on color attenuation prior with matlab code
Scala中使用 Jackson API 进行JSON序列化和反序列化
6-10 二分查找(20分)
2022-08-09 Study Notes day32-IO Stream
【知识分享】在音视频开发领域中SEI到底是个啥?
剑指 Offer II 034. 外星语言是否排序-辅助数组法
dumpsys meminfo 详解
企业即时通讯是什么?可以应用在哪些场景?
优化是一种习惯●出发点是'站在靠近临界'的地方
FPGA工程师面试试题集锦71~80
Keras deep learning combat (17) - image segmentation using U-Net architecture
第14章_MySQL事务日志
websocket校验token:使用threadlocal存放和获取当前登录用户
[Image segmentation] Image segmentation based on cellular automata with matlab code