当前位置:网站首页>正则(三剑客和文本处理工具)
正则(三剑客和文本处理工具)
2022-08-11 05:20:00 【一颗橙子lio】
正则
文章目录
引言:
正则表达式,又称规则表达式(Reqular Expression)。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本,正则表达式不只有一种,而且 Linux 中不同的程序可能会使用不同的正则表达式。
一.正则表达式定义
正则表达式,又称正规表达式、常规表达式,使用字符串来描述、匹配一些列符合某个规则的字符串
正则表达式是由普通字符与元字符组成
普通字符包括大小写字母、数字、标点符号及一些其他符号
元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
Linux 中常用的有两种正则表达式引擎
基础正则表达式:BRE
扩展正则表达式: ERE
二.正则表达式元字符
1.基础正则表达式元字符
BRE——Basic Register Express 基本的正则表达式
作用
- 匹配字符
- 匹配字数
- 位置锚定
基础正则表达式常见元字符如下:
| 元字符 | 作用 |
|---|---|
| \ | 转义字符,用于取消特殊符号的含义 |
| ^ | 尖角符,匹配字符串开始的位置 |
| $ | 美元符,匹配字符串结束的位置 |
| ^$ | 组合符,匹配空行 |
| . | 匹配除\n、\r之外的任何一个字符 |
| * | 匹配前面子表达式0次或多次,重复0次代表空,即匹配所有内容 |
| .* | 组合符,匹配所有内容 |
| ^.* | 组合符,匹配任意多个字符开头的内容 |
| .*$ | 组合福,匹配人鱼多个字符结尾的内容 |
| [list] | 匹配list列表中的一个字符,例:[abc]匹配a或b或c,也可写[a-c] |
| [^list] | 匹配任意非列表中的一个字符,表示取反。 |
注意:egrep、awk使用{}匹配时不用加\转义
2.扩展正则表达式元字符
ERE一Extend Register Express扩展的正则表达式
扩展正则表达式元子符如下:
ERE集合
| 元字符 | 作用 |
|---|---|
| + | 匹配前面子表达式一次或多次 |
| ? | 匹配前面子表达式0次或一次 |
| () | 分组过滤,将括号内的字符作为一个整体 |
| 丨 | 以或的方式匹配字符条串 |
| []+ | 匹配括号内的":"或者“/”字符1次或多次 |
| a{n} | 匹配前面一个字符正好n次 |
| a{n,} | 匹配前一个字符最少n次 |
| a{,m} | 匹配前一个字符最多m次 |
| a{n,m} | 匹配前一个字符n到m次 |
==注意:==扩展正则必须用grep -E才能生效
3.单引,双引和反撇等一些符号的区别
单引号变量和命令都不识别,当成了普通的字符串
双引号弱引用,不能识别命令,可以识别变量
反撇号 可以执行的一个结果,里面放的是命令的集合=$()
${} 引用变量
$[] 运算
[[]] 运算 处理逻辑命令 处理字符串是否相等
(()) 比较数字、支持变量计算(且不用转义<>、 计算的时候运算符与数字之间不能有空格)
$0 脚本名字 $1 位置变量 $n(n表示数字)
$# 个数 $* 一个字符串 [email protected] 单个字符串
4.脚本的思路
1、明确脚本的功能 分析脚本的作用
2、编写脚本时会使用到哪些命令?awk sed useradd find
3、把变化的数据使用变量表示
4、选择合适的流程控制语句 (循环、分支(单多))
grep
全拼:Global search REgular expression and Print out the line.
作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查,打印匹配到的行
模式:由正则表达式的元字符及文本字符所编写出的过滤条件;
语法:
grep[options] [pattern] file
命令 参数 匹配模式 文件数据
-a --text # 不要忽略二进制数据。
-A <显示行数> --after-context=<显示行数> # 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b --byte-offset # 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-B<显示行数> --before-context=<显示行数> # 除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count # 计算符合范本样式的列数。
-C<显示行数> --context=<显示行数>或-<显示行数> # 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> --directories=<动作> # 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> # 指定字符串作为查找文件内容的范本样式。
-E --extended-regexp # 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> --file=<规则文件> # 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F --fixed-regexp # 将范本样式视为固定字符串的列表。
-G --basic-regexp # 将范本样式视为普通的表示法来使用。
-h --no-filename # 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H --with-filename # 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i --ignore-case # 忽略字符大小写的差别。
-l --file-with-matches # 列出文件内容符合指定的范本样式的文件名称。
-L --files-without-match # 列出文件内容不符合指定的范本样式的文件名称。
-n --line-number # 在显示符合范本样式的那一列之前,标示出该列的编号。
-q --quiet或--silent # 不显示任何信息。
-R/-r --recursive # 此参数的效果和指定“-d recurse”参数相同。
-s --no-messages # 不显示错误信息。
-v --revert-match # 反转查找。
-V --version # 显示版本信息。
-w --word-regexp # 只显示全字符合的列。
-x --line-regexp # 只显示全列符合的列。
-y # 此参数效果跟“-i”相同。
-o # 只输出文件中匹配到的部分。
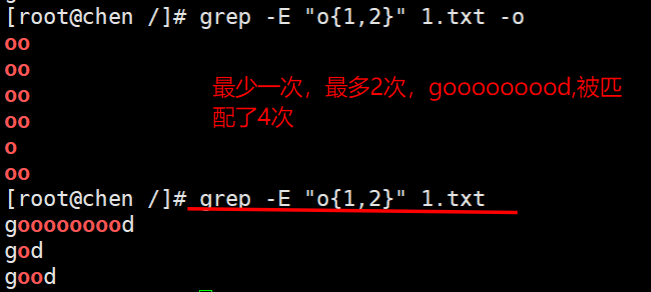
正则grep实践
1、输出所有以n开头的行

2、找出空行

3、输出以o结尾的行

4、找出所有允许登陆的用户,解释器是/bin/bash的行

tips
注意在Liux平台下,所有文件的结尾都有一个$符
可以用cat-A查看文件
5、输出所有有内容的行,不包括空行
. 表示任意一个字符

6、匹配任意一个和s连用的行

7、转义用法
grep -n -i "\." file
需要用到转义
8、贪婪匹配 .* 用法
grep -n -i ".*e" file
找出任意以e结尾的内容
9、[]中括号用法
[a-z]匹配所有小写单个字母
[A-Z]匹配所有单个大写字母
[a-zA-Z] [a-Z]匹配所有的单个大小写字母
[0-9]匹配所有单个数字
[a-zA-Z0-9]匹配所有数字和字母
扩展用法
egrep=grep -E
1、匹配n一次或多次

2、匹配0次或1次

3、找出data目录下的txt文件并且路径里有l或t

4、找出包含good 和 glad 的行

5、匹配次数
sed
sed是Stream Editor(字符流编辑器)的缩写,简称流编辑器。
sed是操作、过滤和转换文本内容的强大工具。
注意sed和awk使用单引号,双引号有特殊解释
常用功能包括结合正则表达式对文件实现快速增删改查,其中查询的功能中最常用的两大功能是过滤(过滤
指定字符串)、取行(取出指定行)。


语法:
sed [选项] [sed 内置命令字符][输入文件]
| 参数选项 | 解释 |
|---|---|
| -n | 取消默认sed的输出,常与sed内置命令p一起用 |
| -i | 直接将修改结果写入文件,不用-i,sed修改的是内存数据 |
| -e | 多次编辑,不需要管道符了 |
| -r,-E | 支持正则扩展 |
| -f | 表示用指定的脚本文件来处理输入的文本文件。 |
| -s | 将多个文件视为独立文件,而不是单个连续的长文件流 |
sed 内置命令字符用于对文件的增删改查
sed 常用的内置命令提示符
| sed的内置命令字符 | 解释 |
|---|---|
| a | apper,对文本追加,在指定行后面添加一行/多行文本 |
| d | Delete,删除匹配行 |
| i | insert,表示插入文本,在指定行前添加一行/多行文本 |
| p | Print,打印匹配行的内容,通常p与-n一起用 |
| s/正则/替换内容/g | 匹配正则内容,然后替换内容(支持正则),结尾g代表全局匹配,四种匹配方式1、数字 2、p,答应与替换命令匹配的行 3、w文件,将替换的结果写到文件中 4、g ,表明新字符串将会替换所有匹配的地方 在使用 sed 命令进行替换操作时需要用到 s(字符串替换)、c(整行/整块替换)、y(字符转换)命令选项,常见的用法如下所示。 |
| l(小写L) | 打印数据流中的文本和不可打印的ASCII字符(比如结束符s、制表符\t) |
| = | 打印行号。 |
| y | 字符转换,转换前后的字符长度必须相同。 |
| c | 替换,将选定行替换为指定内容。 |
sed匹配范围
| 范围 | 解释 |
|---|---|
| 空地址 | 全文处理 |
| 单地址 | 指定文件某一行 |
| /pattern/ | 被模式匹配到的每一行 范围区间 10,20十到二十行,10,+5第10行向下5行,/pattern1/,/pattern.2/= “=”表示输出行号 |
| 步长 | 12,表示1、3、5、7、9行,22两个步长,表示2、4、6、8、10、偶数行 |
sed实践
1、输出第二和第三行


功能参数P一般和-n 连用 打印时,不输出原本内容

打印奇数行和偶数行




2、过滤出含有linux 的字符串行

3、删除有game 的行
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GOm1dpAG-1657499797508)(C:\Users\orange\AppData\Roaming\Typora\typora-user-images\image-20220706112823887.png)]
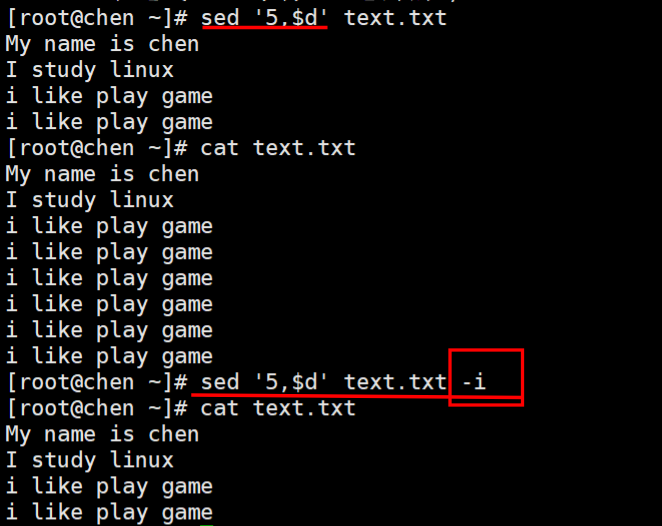
4、删除第五行到结束
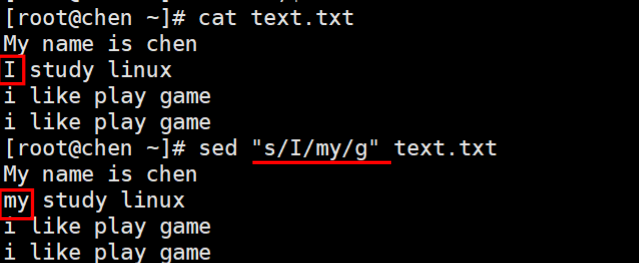
5、把I替换为MY
s/// = [email protected]@@ = s###
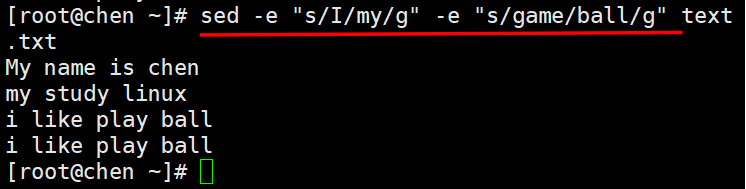
6、连续多次编辑修改
7、在上下分别添加文本
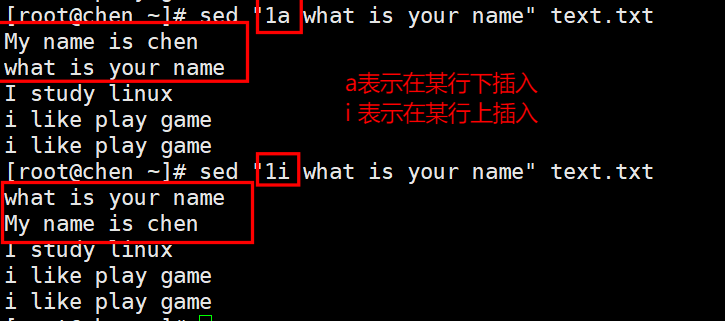
8、换行输入

9、空地址匹配,每行后面加条分割符

10、关闭核心防护
sed -i.bak 's/SELINUX=disabled/SELINUX=enable/' /etc/selinux/config
替换符合条件的文本
sed 's/the/THE/' test.txt //将每行中的第一个the 替换为 THE
sed 's/l/L/2' test.txt //将每行中的第 2 个 l 替换为 L
sed 's/the/THE/g' test.txt //将文件中的所有the 替换为 THE
sed 's/o//g' test.txt //将文件中的所有o 删除(替换为空串)
sed 's/^/#/' test.txt //在每行行首插入#号
sed '/the/s/^/#/' test.txt //在包含the 的每行行首插入#号
sed 's/$/EOF/' test.txt //在每行行尾插入字符串EOF
sed '3,5s/the/THE/g' test.txt //将第 3~5 行中的所有 the 替换为 THE
sed '/the/s/o/O/g' test.txt //将包含the 的所有行中的 o 都替换为 O
sed 正则实践
1、取出ens33 网卡IP地址
去头去尾法

2、多次编辑

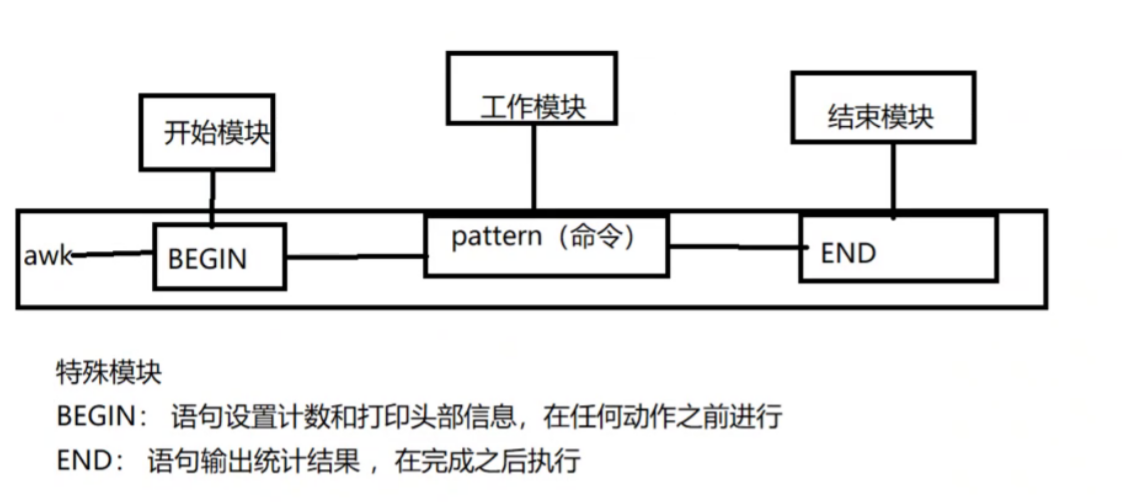
awk
概述:
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。
它是专门为文本处理设计的编程语言,也是行处理软件,通常用于扫描、过滤、统计汇总工作
数据可以来自标准输入也可以是管道或文件20世纪70年代诞生于贝尔实验室,现在centos7用的是gawk
之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
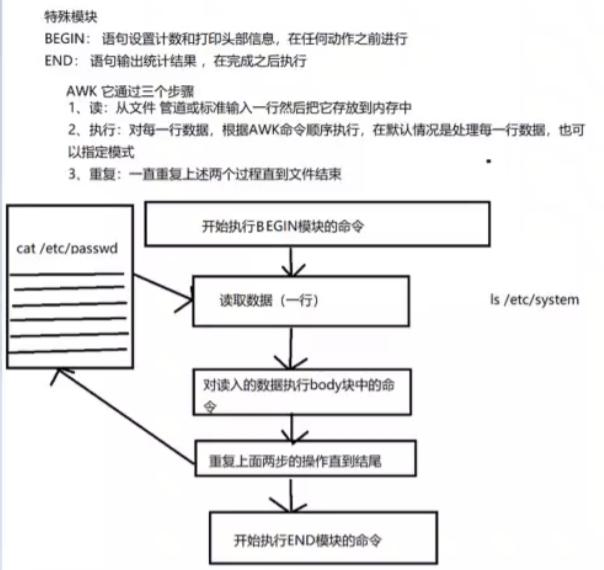
工作原理:
当读到第一行时,匹配条件,然后执行指定动作,再接着读取第二行数据处理,不会默认输出
如果没有定义匹配条件默认是匹配所有数据行,awk隐含循环,条件匹配多少次动作就会执行多少次
工作原理:
逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个"“字段"然后再进行处理。awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。在使用awk命令的过程中,可以使用逻辑操作符” &&“表示"与”、“||表示"或”、"!“表示非”;还可以进行简单的数学运算,如+、一、*、/、%、^分别表示加、减、乘、除、取余和乘方。
命令格式:
awk 选项 '模式或条件{操作}' 文件1 文件2 ...
awk -f 脚本文件 文件1 文件2 ..
格式:awk关键字 选项 命令部分 ‘{xxxx}’ 文件名
内置变量
awk 包含几个特殊的内建变量(可直接用)如下所示:
FS:指定每行文本的字段分隔符,默认为空格或制表位。
NF:当前处理的行的字段个数。
NR:当前处理的行的行号(序数)。
$0:当前处理的行的整行内容。
$n:当前处理行的第 n 个字段(第 n 列)。
FILENAME:被处理的文件名。
RS:行分隔符。awk从文件上读取资料时,将根据Rs的定义把资料切割成许多条记录, 而awk一次仅读入一条记录,以进行处理。预设值是'\n'
简说:数据记录分隔,默认为\n,即每行为一条记录
**其他内置变量的用法、**
FS、OFS、NR、FNR、RS、ORS**
0FS:输出列分隔符衡默认是空格
RS:记录行分隔符,每行记录都是以1n"为一个(换行的)标志
ORS:输出当前记录分隔符
NR:读取文件的记录数(行号),从1开始,新的文件重新从1开始计数
awk实践

2、输出一行

3、

4、schme=“http”
IP_ADD=192.168.226.128
PATH=/usr/local/httpd/htdocs/install/index.html
要求:组合为一个标准的URL
5、扩展生产
网卡IP和流量
ifconfig ens33 | awk '/netmask/{print "本机的ip地址是"$2}'
ifconfig ens33 | awk '/RX p/{print $5"字节"}'

根分区的可用量
df -h | awk 'NR==2{print $4}'

awk扩展
逐行执行开始之前执行什么任务,结束之后再执行什么任务,用BEGIN、END
BEGIN一般用来做初始化操作,仅在读取数据记录之前执行一次
END一般用来做汇总操作,仅在读取完数据记录之后执行一次
awk的运算:
[[email protected] ~]# awk 'BEGIN{x=10;print x}' #如果不用引号awk就当作一个变量来输出了,所以不需要加$了
10
[[email protected] ~]# awk 'BEGIN{x=10;print x+1}' //BEGIN在处理文件之前,所以后面不跟文件名也不影响
11
[[email protected] ~]# awk 'BEGIN{x=10;x++;print x}'
11
[[email protected] ~]# awk 'BEGIN{print x+1}' //不指定初始值,初始值就为0,如果是字符串,则默认为空
1
[[email protected] ~]# awk 'BEGIN{print 2.5+3.5}' //小数也可以运算
6
[[email protected] ~]# awk 'BEGIN{print 2-1}'
1
[[email protected] ~]# awk 'BEGIN{print 3*4}'
12
[[email protected] ~]# awk 'BEGIN{print 3**2}'
9
[[email protected] ~]# awk 'BEGIN{print 2^3}' //^和都是幂运算
8
[[email protected] ~]# awk 'BEGIN{print 1/2}'
0.5
[[email protected] ~]# awk 'BEGIN{print 5%2}'

==小结:==awk运算支持加减乘除取余次方
[[email protected] ~]# awk -F: ‘/root/’ /etc/passwd //如果后面有具体打印多少列就没法省略print了

模糊匹配,用表示包含,!表示不包含
[[email protected] ~]# awk -F: ‘$1~/root/’ /etc/passwd
[[email protected] ~]# awk -F: ‘$1~/ro/’ /etc/passwd //模糊匹配,只要有ro就匹配上

[[email protected] ~]# awk -F: ‘ 7 ! / n o l o g i n 7!~/nologin 7! /nologin/{print $1,$7}’ /etc/passwd

关于数值与字符串的比较
比较符号:== != <= >= < >
[[email protected] ~]# awk ‘NR==5{print}’ /etc/passwd

[[email protected] ~]# awk ‘NR==5’ /etc/passwd

[[email protected] ~]# awk ‘NR<5’ /etc/passwd

[[email protected] ~]# awk -F: ‘$3==0’ /etc/passwd

[[email protected] ~]# awk -F: ‘$1==root’ /etc/passwd
[[email protected] ~]# awk -F: ‘$1==“root”’ /etc/passwd //精确匹配一定是root
[[email protected] ~]# awk -F: ‘$3>=1000’ /etc/passwd UID 大于1000
逻辑运算 && ||
[[email protected] ~]# awk -F: ‘$3<10 || $3>=1000’ /etc/passwd
[[email protected] ~]# awk -F: ‘$3>10 && $3<1000’ /etc/passwd

[[email protected] ~]# awk -F: ‘NR>4 && NR<10’ /etc/passwd

案列:
打印1-200之间所有能被7整除并且包含数字7的整数数字
[[email protected] ~]# seq 200 | awk ‘$1%7==0 && $1~/7/’
[[email protected] ~]# awk ‘BEGIN{FS=“:”}{print $1}’ pass.txt //在打印之前定义字段分隔符为冒号
[[email protected] ~]# awk ‘BEGIN{FS=“:”;OFS=“—”}{print $1,$2}’ pass.txt //OFS定义了输出时以什么分隔,$1$2中间要用逗号分隔,因为逗号默认被映射为OFS变量,而这个变量默认是空格

[[email protected] ~]# awk ‘{print FNR,$0}’ /etc/resolv.conf /etc/hosts
可以看出FNR的行号在追加当有多个文件时
[[email protected] ~]# awk ‘{print NR,$0}’ /etc/resolv.conf /etc/hosts

[[email protected] ~]# awk ‘BEGIN{RS=“:”}{print $0}’ /etc/passwd
RS:指定以什么为换行符,这里指定是冒号,你指定的肯定是原文里存在的字符
[[email protected] ~]# awk ‘BEGIN{ORS=" "}{print $0}’ /etc/passwd
把多行合并成一行输出,输出的时候自定义以空格分隔每行,本来默认的是回车键

awk高级用法
定义引用变量
[[email protected] ~]# a=100
[[email protected] ~]# awk -v b=“$a” ‘BEGIN{print b}’
将系统的变量a,在awk里赋值为变量b,然后调用变量b

[[email protected] ~]# awk ‘BEGIN{print "’$a’"}’
直接调用的话需要先用双引号再用单引号
[[email protected] ~]# awk -v c=1 ‘BEGIN{print c}’
awk直接定义变量并引用
调用函数getline,读取一行数据的时候并不是得到当前行而是当前行的下一行
[[email protected] ~]# seq 10 | awk ‘{getline;print $0}’ //显示偶数行
[[email protected] ~]# seq 10 | awk ‘{print $0;getline}’ //显示奇数行


awk支持判断和循环
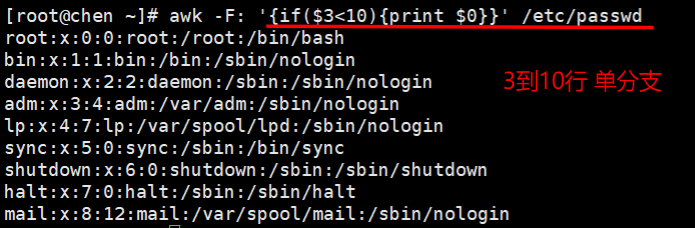
if语句:awk的if语句也分为单分支、双分支和多分支
单分支为if(){}
双分支为if(){}else{}
多分支为if(){}else if(){}else{}
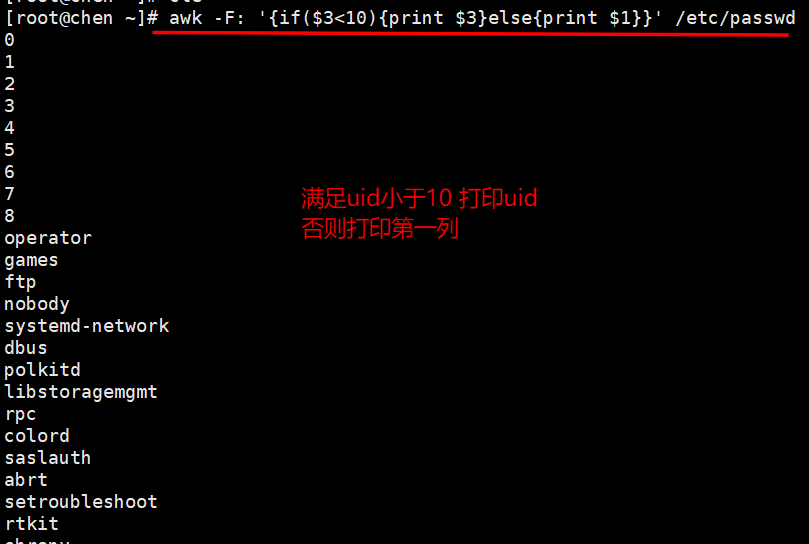
[[email protected] ~]# awk -F: ‘{if($3<10){print $0}}’ /etc/passwd //第三列小于10的打印整行
[[email protected] ~]# awk -F: ‘{if($3<10){print $3}else{print $1}}’ /etc/passwd
第三列小于10的打印第三列,否则打印第一列
awk还支持for循环、while循环、函数、数组等
其他
awk 'BEGIN{x=0};//bin/bash$/ {x++;print x,KaTeX parse error: Expected 'EOF', got '}' at position 2: 0}̲;END {print x}'…" /etc/passwd==


BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中指定的动作; awk再处理指定的文本,之后再执行END模式中指定的动作,END{}语句块中,往往会放入打印结果等语句
awk -F “:” '! ($3<200){print} ’ /etc/passwd#输出第3个字段的值不小于200的行

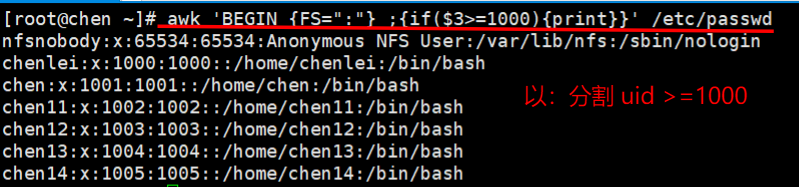
awk ‘BEGIN {FS=“:”} ;{if($3>=1000){print}}’ /etc/passwd #先处理完BEGIN的内容,再打印文本里面的内容
awk -F “:” ’ {max=($3>=$4) ?$3:$4; {print max}} ’ /etc/passwd (了解)
#($3>$4)?$3:$4三元运算符,如果第3个字段的值大于等于第4个字段的值,则把第3个字段的值赋给max,否则第4个字段的值赋给max

awk -F “:” ‘{print NR,$0}’ /etc/passwd
#输出每行内容和行号,每处理完一条记录,NR值加1
和“sed -n ‘=;p’ /etc/passwd”相似。

awk -F “:” ‘$7~“bash”{print $1}’ /etc/passwd#输出以冒号分隔且第7个字段中包含/bash的行的第1个字段 = awk -F: ‘/bash/ {print $1}’ /etc/passwd

awk -F: ‘($1~“root”)&&(NF==7){print $1, 2 , 2, 2,NF}’ /etc/passwd
第1个字段中包含root且有7个字段的行的第1、2个字段

awk -F “:”'($7!=“/bin/bash”)&&($7!=“/sbin/nologin”){print} ’ /etc/passwd
输出第7个字段既不为/bin/bash,也不为/sbin/nologin的所有行
#输出第7个字段既不为/bin/bash,也不为/sbin/nologin的所有行
awk -F:‘(KaTeX parse error: Expected 'EOF', got '&' at position 19: …!=" /bin/bash")&̲&(NF !=" /sbin/nologin" ) {print NR, $0}’ passwd
通过管道、双引号调用shell 命令:
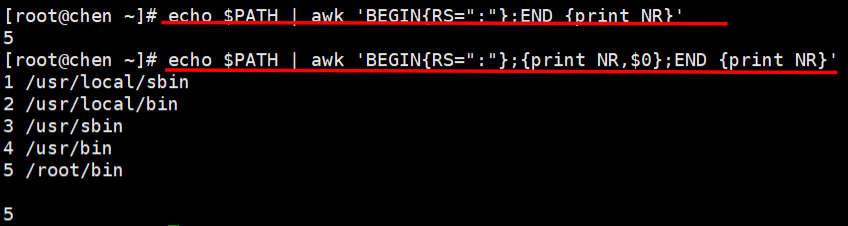
echo $PATH | awk ‘BEGIN{RS=“:”};END {print NR}’
#统计以冒号分隔的文本段落数,END{ }语句块中,往往会放入打印结果等语句
echo $PATH | awk ‘BEGIN{RS=“:”};{print NR,$0};END {print NR}’
awk -F: '/bashKaTeX parse error: Expected 'EOF', got '#' at position 36: …/etc/passwd #̲调用wc -l命令统计使用ba…" etc/passwd

内存
free -m |awk '/Mem:/ {print int($3/($3+$4)100)“%”}’
#查看当前内存使用百分比
free -m | awk '/Mem:/ {print $3/$2}'
free -m | awk '/Mem:/ {print $3/$2*100}'
free -m | awk '/Mem:/ {print int($3/$2*100)"%"}'

cpu
top -b -n 1 | grep Cpu | awk -F ‘,’ ‘{print $4}’| awk ‘{print $1}’
#查看当前CPU空闲率,(-b -n 1表示只需要1次的输出结果)

date -d "$(awk -F “.” '{print KaTeX parse error: Expected 'EOF', got '}' at position 2: 1}̲'/proc/uptime) …” 选日:3N:3S等同于+"3Y-n-%d 3日:8N:8S"的时间格式
date -d "$(awk -F “.” ‘{iprint $1}’/proc/uptime) second ago”+“号F%H:%M:%S”
#显示上次系统重启时间,等同于uptime; second ago为显示多少秒前的时间,+“F悉日:M::S"等同于+”%1-tm-d 日: 38:8S"的时间格式
awk ‘BEGIN {n=0 ; while (“w” | getline) n++ ; {print n-2}}’
#调用w命令,并用来统计在线用户数

awk ‘BEGIN { “hostname” | getline ; {print $0}}’
#调用hostname,并输出当前的主机名

当getline左右无重定向符"<“或"I"时,awk首先读取到了第一行,就是1,然后getline,就得到了1下面的第二行,就是2,因为getline之后,awk会改变对应的NE,NR,FNR和$0等内部变量,所以此时的$0的值就不再是1,而是2了,然后将它打印出来。
当getline左右有重定向符”<"或"I"时,getline则作用于定向输入文件,由于该文件是刚打开,并没有被awk读入一行,只是getline读入,那么getline返回的是该文件的第一行,而不是隔行。
seq 10 | awk ’ {getline; print $0 }’
seq 10 | awk ’ { print $0 ; getline } ’
CPU使用率 (us用户占用、sy内核占用)
-b 以批处理的方式进行
-n 次数
cpu_us=`top -b -n 1 | grep Cpu | awk '{print $2}'`
cpu_sy=`top -b -n 1 | grep Cpu | awk -F ',' '{print $2}' | awk '{print $1} '`
cpu_sum=$(($cpu_us+$cpu_sy))
echo $cpu_sum
echo "A B C D" | awk '{OFS="|"; print $0;$1=$1;print $0}'
echo "A B C D" | awk 'BEGIN{OFS="|"};{print $0;$1=$1;print $0}'
echo "A B C D" | awk 'BEGIN{OFS="|"};{print $0;$1=$1;print $1,$2}'
echo "A B C D" | awk 'BEGIN{OFS="|"};{$2=$2;print $1,$2}'
$1=$1是用来激活$0的重新赋值,也就是说
字段$1…和字段数NF的改变会促使awk重新计算$0的值,通常是在改变OFS后而需要输出$0时这样做

awk 'BEGIN{a[0]=10;a[1]=20;print a[1]}'
awk 'BEGIN{a[0]=10;a[1]=20;print a[0]}'
awk 'BEGIN{a["abc"]=10;a["xyz"]=20;print a["abc"]}'
awk 'BEGIN{a["abc"]=10;a["xyz"]=20;print a["xyz"]}'
awk 'BEGIN{a["abc"]="aabbcc";a["xyz"]="xxyyzz";print a["xyz"]}'
awk 'BEGIN{a[0]=10;a[1]=20;a[2]=30;for(i in a){print i,a[i]}}'
PS1:BEGIN中的命令只执行一次
PS2: awk数组的下标除了可以使用数字,也可以使用字符串,字符串需要使用双引号

使用awk统计httpd 访问日志中每个客户端IP的出现次数?
答案:
awk '{ip[$1]++}END{for(i in ip)(print ip[i],i}' /var/log/httpd/access_log | sort -r
备注:定义数组,数组名称为ip,数字的下标为日志文件的第1列(也就是客户端的IP地址),++的目的在于对客户端进行统计计数,客户端IP出现一次计数器就加1。END中的指令在读取完文件后执行,通过循环将所有统计信息输出,for循环遍历的是数组名ip的下标。
awk '/Failed password/ {print $0} ’ /var/log/secure #日志每行
awk '/Failed password/ {print $11} ’ /var/log/secure #日志11列
awk ‘/Failed/{ip[$11]++}END{for(i in ip){print i","ip[i]}}’ /var/log/secure
awk ‘/Failed/{ip[$11]++}END{for(i in ip){print i","ip[i]}}’ /var/log/secure
awk ‘/Failed password/{ip[$11]++}END{for(i in ip){print i","ip[i]}}’ /var/log/secure
脚本编写
#!/bin/ bash
x=awk '/Failed password/{ip[$11]++}END{for(i in ip){print i","ip[i]}}' /var/log/secure
#190.168.80.13 3
for j in $x
do
ip=echo $j | awk -F "," '{print $1}'
num=echo $j | awk -F "," '{print $2}'
if [ $num -ge 3 ];then
echo “警告! i p 访 问 本 机 失 败 了 ip访问本机失败了 ip访问本机失败了num次,请速速处理!”
fi
done
三.文本处理工具
cut命令
在文件的每一行中提取片段
在每个文件file的各行中,把提取的片段显示在标准输出
语法
cut 【参数】【数值区间】文件
-b #以字节为单位分割
-n #取消分割多字节字符,与-b一起用
-C #以字符为单位
-d #自定义分隔符,默认以tab为分隔符
-f #与-d一起使用,指定显示哪个区域
N #第N个字节,字符或字段,从1计数起
N- #从第N个字节,字符或字段直至行尾
N-M #从第N到第M(并包括第M)个字节,字符或字段
-M #从第1到第M(并包括第M)个字节,字符或字段
案例
1.截取每行第四个字符
cut -c 4 demo.txt
2.截取4到6个字符
cut -c 4-6 demo.txt
3.截取第5和7的字符
cut -c 5,7 file.txt
4,截取一个范围的字符,如第四个到结尾
cut -c 4- file.txt
5.截取一个范围的字符,如开头到第六个字符
cut -c -6 file.txt
6,指定分隔符号,进行截取
cut -d ":" date-f 区域范围 file.txt
找出第三个区域的内容
cut -d ":" -f 3 file.txt
找出开头到第三个区域的内容
cut -d ":" -f -3 file.txt
cut -d ":"-f -4 password | head -5(还没理解)
1、-d -f用法

2、-b用法 取字节

3、-c用法
ls | cut -c 2
-c适用于中文,取字符
sort命令-排序工具
sort命令将输入的文件内容按照规则排序,然后输出结果
用法:sort【选项】...【文件】...
或:sort【选项】...--file80-from=F
串联排序所有指定文件并将结果写到标准输出。
-b,--ignore-leading-blanks #忽略前导的空白区域
-n,--numeric-sort #根据字符串数值比较 升序从小到大
-r,--reverse #逆序输出排序结果
-u,--unique #配合-c,严格校验排序;不配合-C,则只输出一次排序结果
-t,--field-separator=分隔符 #使用指定的分隔符代替非空格到空格的转换
-k,--key=[位置1,位置2] #在位置1开始一个ky,在位置2终止(默认为行尾)
-o,将排序后的结果转存至制定文件
案例
1,对文件第一个字符进行排序,默认从小到大
sort -n file.txt
2.对排序结果反转,从大到小排序
sort -n -r file.txt
3.对排序结果去重
sort -u file.txt
4.指定分割符号,进行排序,从小到大排序
sort -n -t ".” -k 4 ip.txt



uniq命令-去重工具
uniq命令可以输出或者忽略文件中的重复行,常与sort排序结合使用
用法:unig[选项]...[文件]
从输入文件或者标准输入中筛选相邻的匹配行并写入到输出文件或标准输出。
不附加任何选项时匹配行将在首次出现处被合并。
-c,--count #在每行前加上表示相应行目出现次数的前缀编号
-d,--repeated #只输出重复的行
-u,--unique #只显示出现过一次的行,注意了,unig的只出现过一次,是针对-c统计之后的结果
案例
1.去除连续重复的行
uniq file.txt
2.结合sort实用,去重更精准
sort -n file.txt|uniq
3.统计每一行重复次数
sort -n file.txt |uniq -c
4.之找出文件中重复行,且统计出现次数
sort -n file.txt |uniq -c -u
1、-c用法

2、-d 用法 -显示重复行

3、-u 用法 -显示只出现1次的行

面试题:
查看当前终端中是连接状态的网络信息(要求统计已连接、listen timeout 等状态的进程个数)

netstat -natpl | awk ‘NR>2{print $6}’ | sort | uniq -c

tr命令–修改工具
tr命令从标准期入中替换、缩减或别除字符,将结果写入到标准输出
用法:tr[选项]...SET1[SET2]
从标准输入中替换、缩减和/或别除字符,并将结果写到标准输出。
字符集1:指定要转换或制除的原字符集。
当执行转换操作时,必须使用参数“字符集2“指定转换的目标字符集。
但执行削除操作时,不需要参数“字符集2”:
字符集2:指定要转换成的目标字符集。
-c或一complerment #取代所有不属于第一字符集的字符;
-d或一delete #削除所有属于第一字符集的字符;
-s或--squeeze-repeats #把连续重复的字符以单独一个字符表示:
-t或--truncate-setl #先别除第一字符集较第二字符集多出的字符。
案例
1.替换标准输入中的大小写
[[email protected] ~]# echo "HELLO WORLD" | tr 'A-Z' 'a-z'
hello world
2.使用-d 删除参数
[[email protected] ~]# echo "my name is file and i am 9999 years old" | tr -d 'a-z'
9999
[[email protected] ~]# echo "my name is file and i am 9999 years old" | tr -d 'a'
my nme is file nd i m 9999 yers old
3.把文件当做标准输入,进行字符替换
tr'a''A'< file.txt my nAme is file 。 i like leArning python And linux. 4.把连续重复字符以单独字符表示 [[email protected] ~]# echo "iiiii am aaaaaalllllexxxx" | tr -s 'iax'
i am alllllex

面试组合使用
1.统计当前连接主机数
ss -nt tr -s "cut -d "-f5|cut -d “:”-f1 Isortluniq -cl
2.统计当前主机的连接状态
99797526)]
netstat -natpl | awk ‘NR>2{print $6}’ | sort | uniq -c
[外链图片转存中…(img-CqgbF6o7-1657499797526)]
tr命令–修改工具
tr命令从标准期入中替换、缩减或别除字符,将结果写入到标准输出
用法:tr[选项]...SET1[SET2]
从标准输入中替换、缩减和/或别除字符,并将结果写到标准输出。
字符集1:指定要转换或制除的原字符集。
当执行转换操作时,必须使用参数“字符集2“指定转换的目标字符集。
但执行削除操作时,不需要参数“字符集2”:
字符集2:指定要转换成的目标字符集。
-c或一complerment #取代所有不属于第一字符集的字符;
-d或一delete #削除所有属于第一字符集的字符;
-s或--squeeze-repeats #把连续重复的字符以单独一个字符表示:
-t或--truncate-setl #先别除第一字符集较第二字符集多出的字符。
案例
1.替换标准输入中的大小写
[[email protected] ~]# echo "HELLO WORLD" | tr 'A-Z' 'a-z'
hello world
2.使用-d 删除参数
[[email protected] ~]# echo "my name is file and i am 9999 years old" | tr -d 'a-z'
9999
[[email protected] ~]# echo "my name is file and i am 9999 years old" | tr -d 'a'
my nme is file nd i m 9999 yers old
3.把文件当做标准输入,进行字符替换
tr'a''A'< file.txt my nAme is file 。 i like leArning python And linux. 4.把连续重复字符以单独字符表示 [[email protected] ~]# echo "iiiii am aaaaaalllllexxxx" | tr -s 'iax'
i am alllllex
[外链图片转存中…(img-rDniwKPB-1657499797526)]
面试组合使用
1.统计当前连接主机数
ss -nt tr -s “cut -d “-f5|cut -d “:”-f1 Isortluniq -cl
2.统计当前主机的连接状态
ss -nta I grep -v 'State’Icut -d””-f1lsort luniq -c
边栏推荐
猜你喜欢
C语言结构体——位段概念的讲解

04-开发自己的npm包及发布流程详细讲解
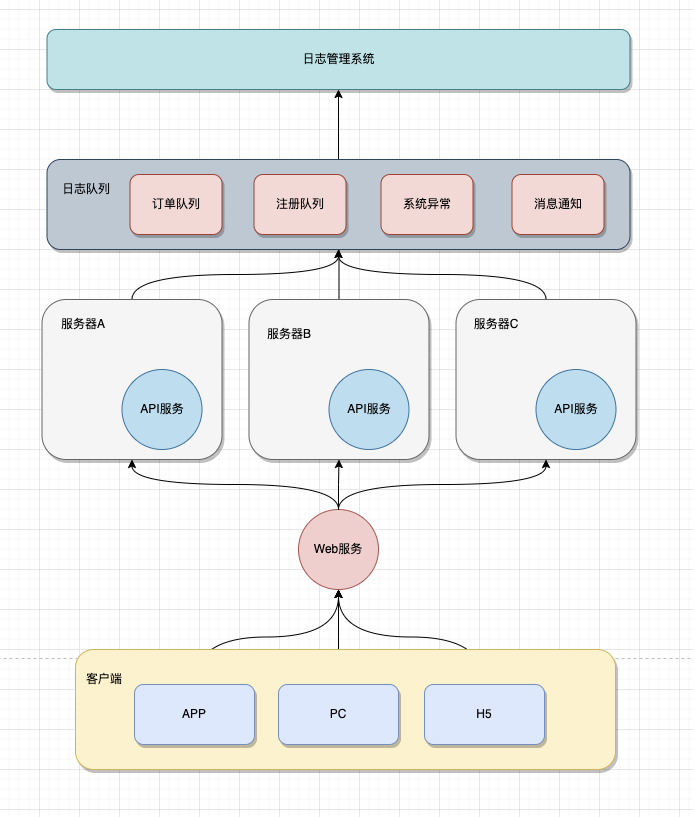
分布式日志存储架构设计方案

C语言——文件操作函数 fseek、ftell、rewind详解
09-ES6语法:变量、箭头函数、类语法、静态属性及非静态属性
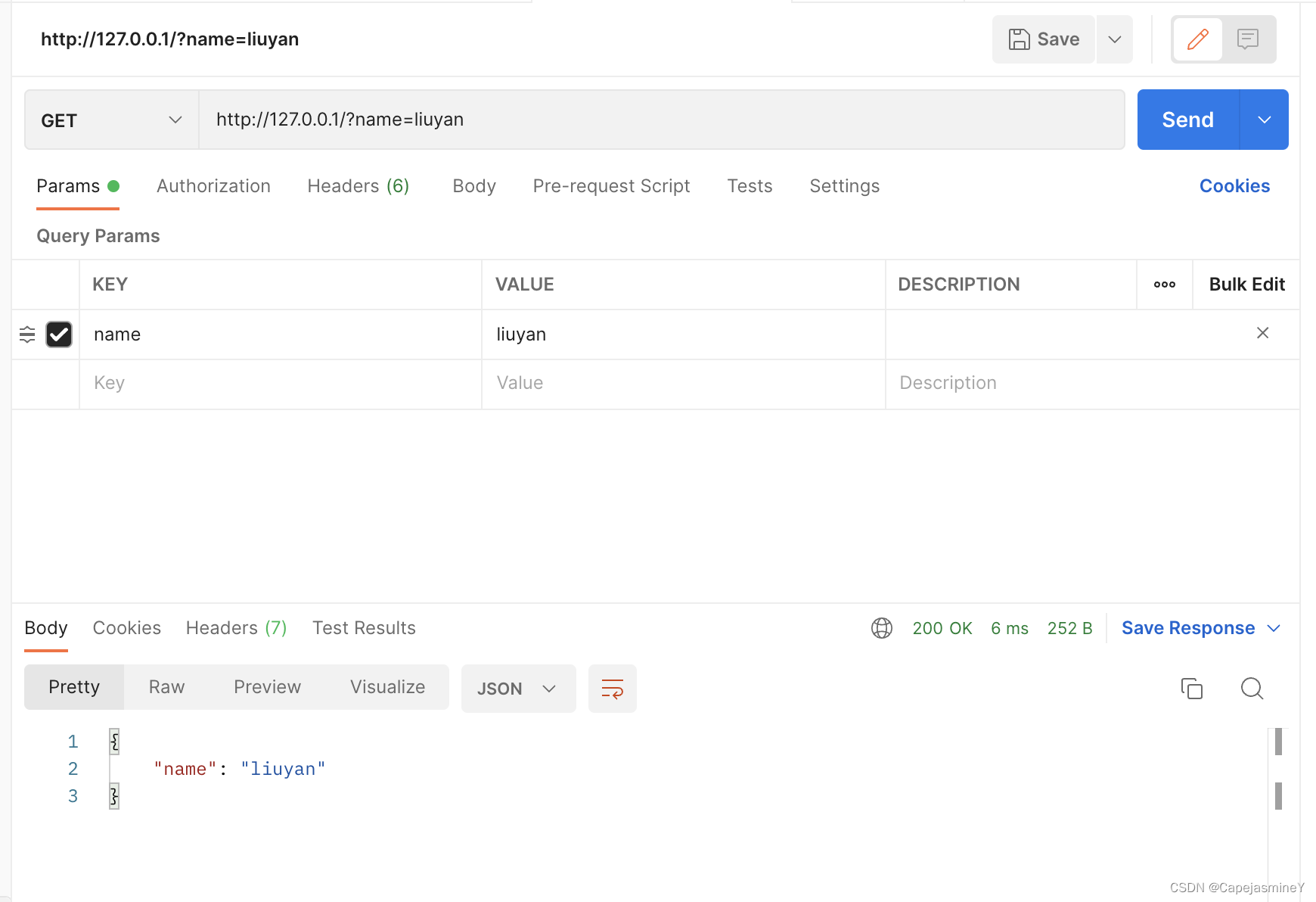
06-引入Express创建web服务器、接口封装并使用postman测试,静态资源托管

使用Go语言开发的低代码应用引擎
error: The following untracked working tree files would be overwritten by merge: .hbuilderx/launch
Windows64位MySQL配置式安装(绿色版)

vscode插件
随机推荐
最全总结Redis数据类型使用场景
Object.defineProperty新增/修改属性数据代理
C language learning record--variable basic type and memory size
vscode插件
[C language from elementary to advanced] Part 1 Initial C language (1)
Promise
C language version - advanced address book (file version)
云计算学习笔记——第三章 计算虚拟化[二]
C语言动态内存分配(1)三种函数讲解
ENS是机会吗?
常用的转义字符
mysql基本概念之存储引擎
代币标准--ERC1155协议源码解析
C语言——逆序输出字符串的函数实现
C语言版——通讯录进阶(文件版本)
PHP提高并发能力有哪些方案
leetcode21.合并两个有序链表
C语言结构体详解 (2) 结构体内存对齐,默认对齐数
BoredApeYachtClub 无聊猿-NFT 源码解析第一节
信息学奥赛