当前位置:网站首页>redis数据库讲解(四)主从复制、哨兵、Cluster群集
redis数据库讲解(四)主从复制、哨兵、Cluster群集
2022-04-23 14:07:00 【C和弦~】
目录
引言
前面我们了解了MySQL数据库的主从等服务、今天我们来了解一下redis的相应服务
一.redis数据库主从复制
- 通过持久化功能,redis保证了即使在服务器重启的情况下也不会丢失(或少量丢失)数据,因为持久化会把内存中的数据保存到硬盘上,重启会从硬盘上加载数据,但是由于数据是存儲在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。
- 为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务,为此, redis提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
- 在复制的概念中,数据库分为两类,一类是主数据库(master) ,另一类是从数据(slave) 。主数据可以进行读写操作,当写操作导致数据变化时会自动将数据同步给从数据库,而从数据库一般是只读的,并接受主数据同步过来的数据。一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库。
1.redis主从复制原理
① 若启动一个Slave机器进程,则它会向Master机器发送一个"sync_command"命令,请求同步连接
② 无论是第一次连接还是重新连接,Master机器都会启动一个后台进程,将数据快照(RDB)保存到 数据文件中(执行rdb操作),同时Master还会记录修改数据的所有命令并缓存在数据文件中。
③ 后台进程完成缓存操作之后,Master机器就会向Slave机器发送数据文件,Slave端机器将数据 文件保存到硬盘上,然后将其加载到内存中,接着Master机器就会将修改数据的所有操作一并发送给Slave端机器。若Slave出现故障导致宕机,则恢复正常后会自动重新连接。
④ Master机器收到slave端机器的连接后,将其完整的数据文件发送给Slave端机几器,如果Mater同时收到多个slave发来的 同步请求则Master会在后台启动一个进程以保存数据文件,然后将其发送给所有的Slave端机器,确保所有的Slave端机器都正常。
有没有觉得很多、很难记住,哈哈哈,满足你们、来看简化版
- slave向master发送sync_command同步申请
- master主进程会派生一个RDB子进程进行持久化、生成RDB文件
- 将RDB文件推送给所有slave(完成全量同步)
- 使用AOF持久化将缓存数据保存在缓冲中(主从节点都需要开启AOF)
- master使用AOF将缓冲区数据同步给slaves缓冲区数据(增量)
2.项目部署
节点名 IP地址
master 192.168.226.11
slave1 192.168.226.55
slave2 192.168.226.33注:三台服务器都需部署好redis(redis的部署请看之前的介绍、这里就不再介绍,以下部署是在redis部署完成的基础上操作)
#老配方、三台设备都关闭防火墙和安全策略
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
[root@master ~]# setenforce 0
[root@master ~]# ①master部署
[root@master ~]# vim /etc/redis/6379.conf
bind 0.0.0.0
#70行,修改监听地址为 0.0.0.0
daemonize yes
#137行,开启守护进程
logfile /var/1og/redis_6379.1og
#172行,指定日志文件目录
dir /var/lib/redis/6379
#264行,指定工作目录
appendonly yes
#700行,开启 AOF 持久化功能
[root@master ~]# /etc/init.d/redis_6379 restart
② Slave1、Slave2节点部署
[root@slave2 ~]# vim /etc/redis/6379.conf
bind 0.0.0.0
#70行,修改监听地址为 0.0.0.0
daemonize yes
#137行,开启守护进程
logfile /var/log/redis_6379.log
#172行,指定日志文件目录
dir /var/lib/redis/6379
#264行,指定工作目录
replicaof 192.168.29.11 6379
#288行,指定要同步的 Master 节点 IP 和端口
appendonly yes
#700行,开启 AOF 持久化功能
[root@slave2 ~]# /etc/init.d/redis_6379 restart
3.验证效果
master添加一个键值
[root@master ~]# redis-cli
127.0.0.1:6379> set ceshi 100
OK
127.0.0.1:6379>
slave查看是否能查看到刚刚在主上添加的键值
[root@slave2 ~]# redis-cli
127.0.0.1:6379> get ceshi
"100"
127.0.0.1:6379>
[root@slave1 ~]# redis-cli
127.0.0.1:6379> get ceshi
"100"
127.0.0.1:6379> 二.哨兵
1、哨兵模式集群架构
- 哨兵是Redis集群架构中非常重要的一个组件,哨兵的出现主要是解决了主从复制出现故障时需要认为干预的问题
2、哨兵模式主要功能
【1】集群监控:负责监控 Redis master 和 slave 进程是否正常工作
【2】消息通知:如果某个 Redis 实例出现故障,那么哨兵负责发送消息作为报警通知给管理员
【3】故障转移:如果 master node 挂掉了,会自动转移到 slave node 上
【4】配置中心:如果故障转移发生了,通知 client 客户端习新的 master 地址
3 结构
- 哨兵结构由两部分组成,哨兵节点和数据节点:
- 哨兵节点 :哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的 redis 节点,不存储数据
- 数据节点: 主节点和从节点都是数据节点
4 工作过程
- 哨兵的启动依赖于主从模式,所以须把主从模式安装好的情况下再去做哨兵模式,所以节点上都需要部署哨兵模式,哨兵模式会监控所有的 Redis 工作节点是否正常
- 当 Master 出现问题的时候,因为其他节点与主节点失去联系,因此会投票,投票过半就认为这个 Master 的确出现问题,然后会通知哨兵间会推选出一个哨兵来进行故障转移工作(由该哨兵来指定哪个 slave 来做新的 master),然后从 Slaves 中选取一个作为新的 Master
- 筛选方式是哨兵互相发送消息,并且参与投票,票多者当选 需要特别注意的是,客观下线是主节点才有的概念,即如果从节点和哨兵节点发生故障,被哨兵主观下线后,将不会再有后续的客观下线和故障转移操作(及哨兵模式只负责 Master 的方面,而不管 Slaves)
- 当某个哨兵发现主服务器挂掉了,会将 master 中的 SentinelRedistance 中的 master 改为SRI_S_DOWN(主观下线),并通知其他哨兵,告诉他们发现 master 挂掉了 其他哨兵在接收到该哨兵发送的信息后,也会尝试去连接 master,如果超过半数(配置文件中设置的)确认 master 挂掉后,会将 master 中的 SentinelRedistance 中的 master 改为 SRI_O_DOWN(客观下线)
是不是又感觉太多了(斜眼笑),精简版又来了
- 三个哨兵之间建立连接,周期性检测队友是否存货(ping命令)
- 哨兵会向master节点发送命令连接和订阅连接(为了周期性的获取master节点数据)
- 哨兵向master周期性发送info命令,master存活的情况下会返回master节点信息和节点位置
- 哨兵收到master返回的信息后会再向slave节点发送info命令,slaves会返回数据,从而哨兵就可以获取redis所有集群信息
- 哨兵会服务器发送命令连接,建立自己的Hello频道,哨兵会向这个Hello频道建立订阅,用于哨兵之间的消息共享
5、主观下线
哨兵节点会每秒一次的频率向建立了命令节点的实例发送ping命令,如果在 down-after-milliseconds 毫秒内没有做出有效响应包括(pong/loading/masterdown)以外的响应,哨兵就会将该实例在本结构体中的状态标记为 sri_s_down 主观下线
6、客观下线
当一个哨兵节点发现主节点处于主观下线状态时,就会向其他的哨兵节点发出询问,该节点是否已经主观下线。如果超过配置参数 quorum 个节点认为是主观下线时,该哨兵节点就会将自己维护的结构体中该主节点标记为 sri_o_down 客观下线
7、master 选举
在认为主节点客观下线的情况下,哨兵节点间会发起一次选举,命令为: SENTINEL is-master-down-by-addr,只是 run_id 这次会将自己的 run_id 带进去,希望接受者将自己设置为主节点。如果超过半数以上的节点返回将该节点标记为 leader 的情况下,会有该 leader 对故障进行迁移
8.项目部署
节点名 IP地址
master 192.168.226.11
slave1 192.168.226.55
slave2 192.168.226.33[root@master ~]# vim /opt/redis-5.0.7/sentinel.conf
#17行,关闭保护模式
protected-mode no
#21行,Redis哨 兵默认的监听端口
port 26379
#26行 开启守护进程
daemonize yes
#36行,指定日志存放路径
logfile "/var/log/sentinel.log"
#65行,指定数据库存放路径
dir "/var/lib/redis/6379"
#84行,指定哨兵节点
#2表示,至少需要 2 个哨兵节点同意,才能判定主节点故障并进行故障转移
sentinel monitor mymaster 192.168.29.11 6379 2
#113行,判定服务器down掉的时间周期,默认30000毫秒 (30秒 )
sentinel down-after-milliseconds mymaster 3000
#146行,故障节点的最大超时时间为180000 (180秒)
sentinel failover-timeout mymaster 180000
6 启动哨兵模式
先启动主节点在启动从节点
cd /opt/redis-5.0.9/
redis-sentinel sentinel.conf &三、Cluster集群
主节点负责读写请求和集群信息的维护,从节点只进行主节点数据和状态信息的复制
1. 作用
(1) 数据分区
数据分区(或称数据分片)是集群最核心的功能 集群将数据分散到多个节点,一方面突破了 Redis 单机内存大小的限制,存储容量大大增加,另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力 Redis 单机内存大小受限问题,在介绍持久化和主从复制时都有提及 例如,如果单机内存太大,bgsave 和 bgrewriteaof 的 fork 操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出
(2) 高可用
集群支持主从复制和主节点的自动故障转移(与哨兵类似),当任意节点发送故障时,集群仍然可以对外提供服务
(3) 数据分片
Redis 集群引入了哈希槽的概念,有 16384 个哈希槽(编号 0~16383) 集群的每个节点负责一部分哈希槽,每个 Key 通过 CRC16 校验后对 16384 取余来决定放置哪个哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作 以 3 个节点组成的集群为例: 节点 A 包含 0~5469 号的哈希槽 节点 B 包含 5461~10922 号的哈希槽 节点 C 包含 10923~16383 号的哈希槽
2.项目搭建
redis的集群一般需要6个节点,3主3从。方便起见,这里所有节点在同一台服务器上模拟:以端口号进行区分:3个主节点端口号:6001/6002/6003, 对应的从节点端口号:6004/ 6005/ 6006。
#创建redis 6个端口的工作目录
cd /etc/redis/
mkdir -p redis-cluster/redis600{1..6}
vim /opt/redis.sh
#!/bin/bash
for i in {1..6}
do
cp /opt/redis-5.0.7/redis.conf /etc/redis/redis-cluster/redis600$i
cp /opt/redis-5.0.7/src/redis-cli /opt/redis-5.0.7/src/redis-server /etc/redis/redis-cluster/redis600$i
done
sh -x /opt/redis.sh
cd /etc/redis/redis-cluster/redis 6001
vim redis.conf
bind 127.0.0.1
#69行,注释掉bind项或不修改,默认监听所有网卡
protected-mode no
#88行,修改,关闭保护模式
port 6001
#92行,修改,redis监听端口,
daemonize yes
#136行,开启守护进程,以独立进程启动
cluster-enabled yes
#832行,取消注释,开启群集功能
cluster-config-file nodes-6001.conf
#840行,取消注释,群集名称文件设置
cluster-node-timeout 15000
#846行,取消注释群集超时时间设置
appendonly yes
#700行,修改,开启AOF持久化
其他5个配置文件除端口号外改动相同
cp redis.conf ../redis6002/
--->yes
#启动服务
cd /etc/redis/redis-cluster/redis6001
redis-server redis.conf
#根据对应配置文件启动redis
vim /opt/redis_start.sh
#!/bin/bash
for d in {1..6}
do
cd /etc/redis/redis-cluster/redis600$d
redis-server redis.conf
done
ps -ef | grep redis
sh -x /opt/redis_start.sh
加入集群
redis-cli --cluster create 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 --cluster-replicas 13.测试
redis-cli -p 6001 -c #加-c参数,节点之,间就可以互相跳转
127.0.0.1:6001> cluster slots #查看节点的哈希槽编号范围
1) 1) (integer) 5461
2) (integer) 10922 #哈希槽编号范围
3) 1) "127.0.0.1"
2) (integer) 6003 #主节点IP和端口号
3) " fdca661922216dd69a63a7c9d3c4540cd6baef44"
4) 1) "127.0.0.1"
2) (integer) 6004 #从节点IP和端口号
3) " a2c0c32aff0f38980accd2b63d6d952812e44740"
2) 1) (integer) 0
2) (integer) 5460
3) 1) "127.0.0.1"
2) (integer) 6001
3) "0e5873747a2e26bdc935bc76c2bafb19d0a54b11"
4) 1) "127.0.0.1"
2) (integer) 6006
3) "8842ef5584a85005e135fd0ee59e5a0d67b0cf8e"
3) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 6002
3) "81 6ddaa3d1469540b2ffbcaaf9aa867646846b30"
4) 1) "127.0.0.1"
2) (integer) 6005
3) " f847077bfe6722466e96178ae8cbb09dc8b4d5eb"
总结
① 主从复制
主从复制是高可用Redis的基础,哨兵和集群都是在主从复制基础上实现高可用的。主从复制主要实现了数据的多机备份, 以及对于读操作的负载均衡和简单的故障恢复。 缺陷:故障恢复无法自动化:写操作无法负载均衡:存储能力受到单机的限制。
② 哨兵
在主从复制的基础上,哨兵实现了自动化的故障恢复。 缺陷:写操作无法负载均衡:存储能力受到单机的限制。
③ 集群
通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
版权声明
本文为[C和弦~]所创,转载请带上原文链接,感谢
https://blog.csdn.net/Ab960311/article/details/121344354
边栏推荐
猜你喜欢
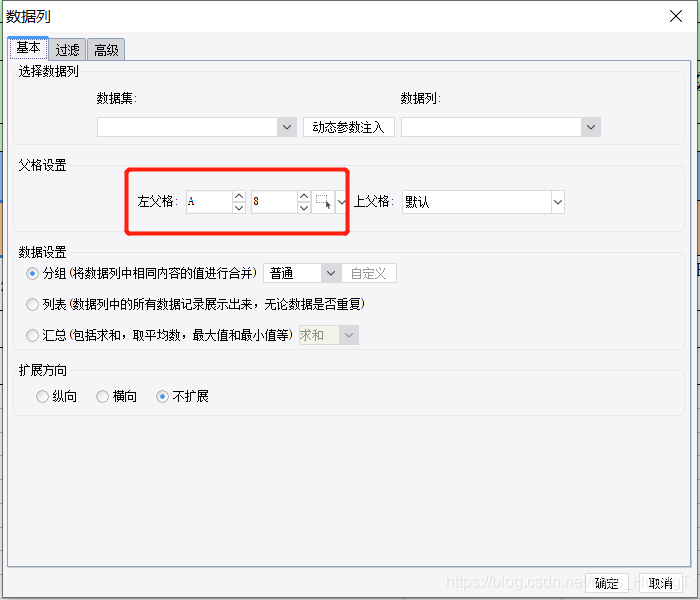
按实际取,每三级分类汇总一次,看图知需求

什么是云迁移?云迁移的四种模式分别是?

帆软之单元格部分字体变颜色
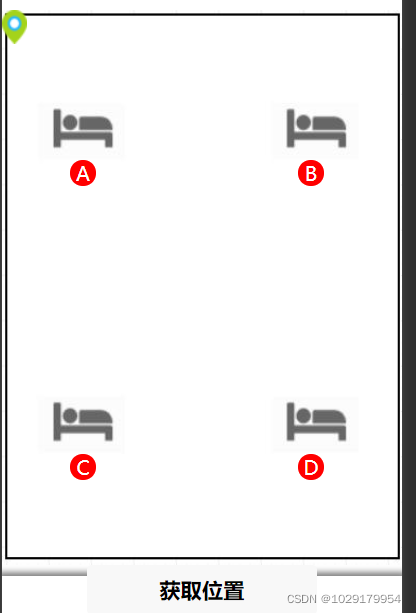
室内外地图切换(室内基于ibeacons三点定位)

Detailed tutorial on the use of smoke sensor (mq-2) (based on raspberry pie 3B +)
Cdh6 based on CM management 3.2 cluster integration atlas 2 one
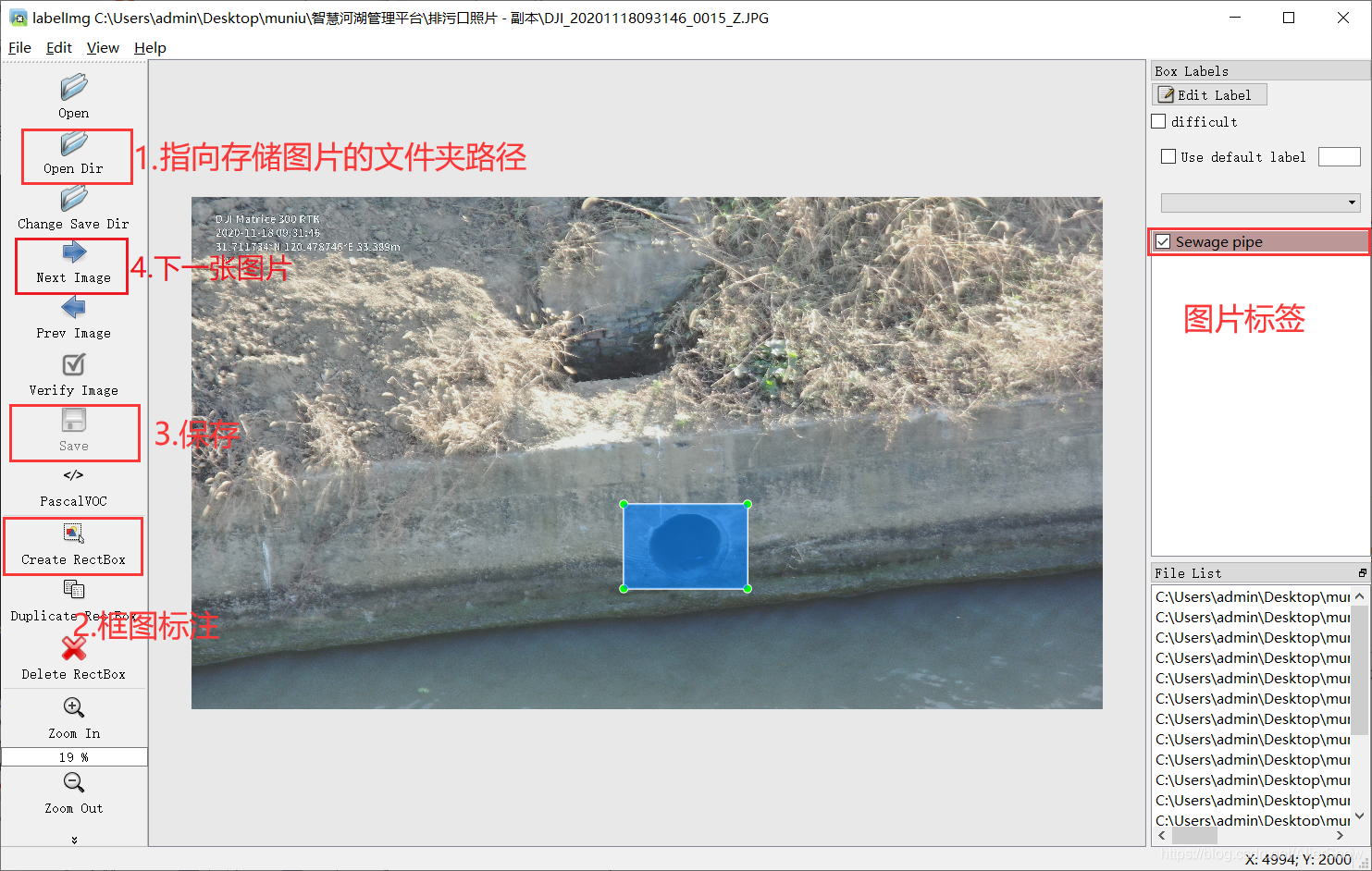
Windos中安装labellmg教程

Detailed tutorial on the use of setinterval timing function of wechat applet

多云数据流转?云上容灾?年前最后的价值内容分享
烟雾传感器(mq-2)使用详细教程(基于树莓派3b+实现)
随机推荐
Detailed tutorial on the use of setinterval timing function of wechat applet
不同时间类型的执行计划计算
帆软报表设置单元格填报以及根据值的大小进行排名方法
RobotFramework 之 项目框架
基於CM管理的CDH集群集成Phoenix
什么是云迁移?云迁移的四种模式分别是?
win10自带Groove音乐不能播放CUE和APE文件的一种曲线救国办法,自己创建aimppack插件包,AIMP安装DSP插件
RobotFramework 之 公共变量
9月8日,临去松山湖的前夜
POI operation word template replaces data and exports word
Can I compile the header file and source file of the template separately
Mysql个人学习总结
Jacob print word
帆软之单元格部分字体变颜色
HyperBDR云容灾V3.2.1版本发布|支持更多云平台,新增监控告警功能
Understand the concepts of virtual base class, virtual function and pure virtual function (turn)
Prediction of tomorrow's trading limit of Low Frequency Quantization
leetcode--380. O (1) time insertion, deletion and acquisition of random elements
Check in system based on ibeacons
PySide2