当前位置:网站首页>数据标注太昂贵?这个方法可以用有限的数据训练模型实现基于文本的ReID!
数据标注太昂贵?这个方法可以用有限的数据训练模型实现基于文本的ReID!
2022-08-10 20:31:00 【FightingCV】

【写在前面】
基于文本的人物搜索(TBPS)旨在通过描述性文本查询从图像库中检索目标人物。解决这种细粒度跨模态检索任务具有挑战性,这进一步受到缺乏大规模数据集的阻碍。在本文中,作者提出了一个包含两个新组件的框架来处理有限数据带来的问题。首先,为了充分利用现有的小规模基准数据集进行更具区分性的特征学习,作者引入了跨模态动量对比学习框架来丰富给定小batch的训练数据。其次,作者提出转移从现有粗粒度大规模数据集(包含来自完全不同问题域的图像-文本对)学习的知识,以弥补TBPS训练数据的不足。作者设计了一种转移学习方法,使有用信息可以在域间隙较大的情况下转移。有了这些组件,本文的方法在CUHK-PEDES数据集上达到了最新水平,在Rank-1和map方面比现有技术有了显著改进。
1. 论文和代码地址

Text-Based Person Search with Limited Data
论文地址:https://arxiv.org/abs/2110.10807[1]
代码地址:https://github.com/BrandonHanx/TextReID[2]
2. Motivation
基于文本的人员搜索 (TBPS) 是通过描述性文本查询从图像库中检索目标人员的问题。当查询图像难以获得时,与基于图像的人员搜索相比,它更具灵活性。因此,它在研究界获得了越来越多的关注。TBPS有各种潜在的应用,如视频监控和个人相册搜索。
尽管已经做出了努力,但TBPS仍远未解决。其中一个原因是,它本质上是具有挑战性的,作为一个特定的跨模态检索任务,其中所有图像属于同一类别,即行人。这与更广泛研究的通用图像文本检索任务形成鲜明对比。细粒度特性决定了必须学习更多的判别特征来区分视觉线索和文本属性。因此这是现有TBPS方法的重点。具体来说,先前的作品通常使用双流架构进行快速推理,其中两个流都是从在大规模单峰数据上预训练的主干初始化的,例如,ResNet 和BERT。为了学习更多的区别性特征,许多方法也利用多尺度学习,其中具有不同感受野和单词/短语/句子嵌入的特征图分别用于视觉和文本流。
TBPS还面临着第二个挑战,这在很大程度上被忽略了,即缺乏训练数据。收集一个大规模的TBPS数据集并用细粒度的文本描述对其进行标注是乏味且昂贵的。因此,大多数现有的TBPS数据集比那些粗粒度的通用图像-文本对数据集小几个数量级。只有有限的数据对TBPS模型学习粒度检索的判别交叉模态特征的能力有明显的负面影响。
现有方法不足以解决这一有限的数据问题。更具体地说,他们的大多数学习目标要求训练数据被组织成正负对。但是,以前的工作仅从某个小batch构建负对,而该小batch并未充分利用可用的TBPS数据。在较大的图像-文本对数据集上进行预训练也是弥补训练数据不足的明显选择。尽管如此,以前的作品中的视觉和文本流是从模型中初始化的,这些模型是在单峰数据而不是image-text对上分别进行预训练的。因此,没有利用对跨域匹配有用的信息。可能已经尝试过跨模式预训练。然而,如果没有仔细的设计,检测的预训练然后调整策略将导致负转移。
为了克服数据有限的学习问题,在这项工作中,作者提出了一个包含两个新组件的TBP框架。首先,为了充分利用现有的小规模基准数据集进行更具区分性的特征学习,作者引入了跨模态动量对比学习(或CM-MoCo)框架,以丰富给定小batch的训练数据。CM-MoCo将负对的数量与小batch大小解耦,以获得每个图像或描述的更多负交叉模态对应项。为了实现这样一个框架,除了两个梯度更新编码器(查询编码器)外,作者还为两种模态式引入了另外两个动量更新编码器(键编码器),并维护三个不同的队列来存储以前batch的视觉特征、文本特征和身份。此外,以交叉模态的方式制定了对比损失,它将来自查询编码器,键编码器和队列的特征分别视为锚,正样本和负样本。此外,以跨模式的方式制定了对比损失,将查询编码器、关键编码器和队列的特征分别视为锚、正样本和负样本。其次,提出了一种跨模态转移学习方法,以受益于大规模粗粒度图像-文本对数据集。作者提出冻结预训练模型的文本编码器以嵌入每个单词,然后采用一个双向GRU层(Bi GRU)来语境化单词,而不是常用的预训练+微调策略。从经验上看,这种迁移学习策略可以有效地防止朴素全模型迁移策略带来的负迁移。
本文的主要贡献是 :( 1) 提出了一种新颖的跨模态动量对比学习框架,以更好地利用现有的小规模TBPS数据集。(2) 为了有效地转移从大规模通用图像-文本对中学到的知识,作者提出执行跨模态预训练,但是对于文本模态,仅转移单词嵌入。(3) 进行了广泛的实验,以表明提出的框架在CUHK-PEDES上的性能优于现有方法。
3. 方法
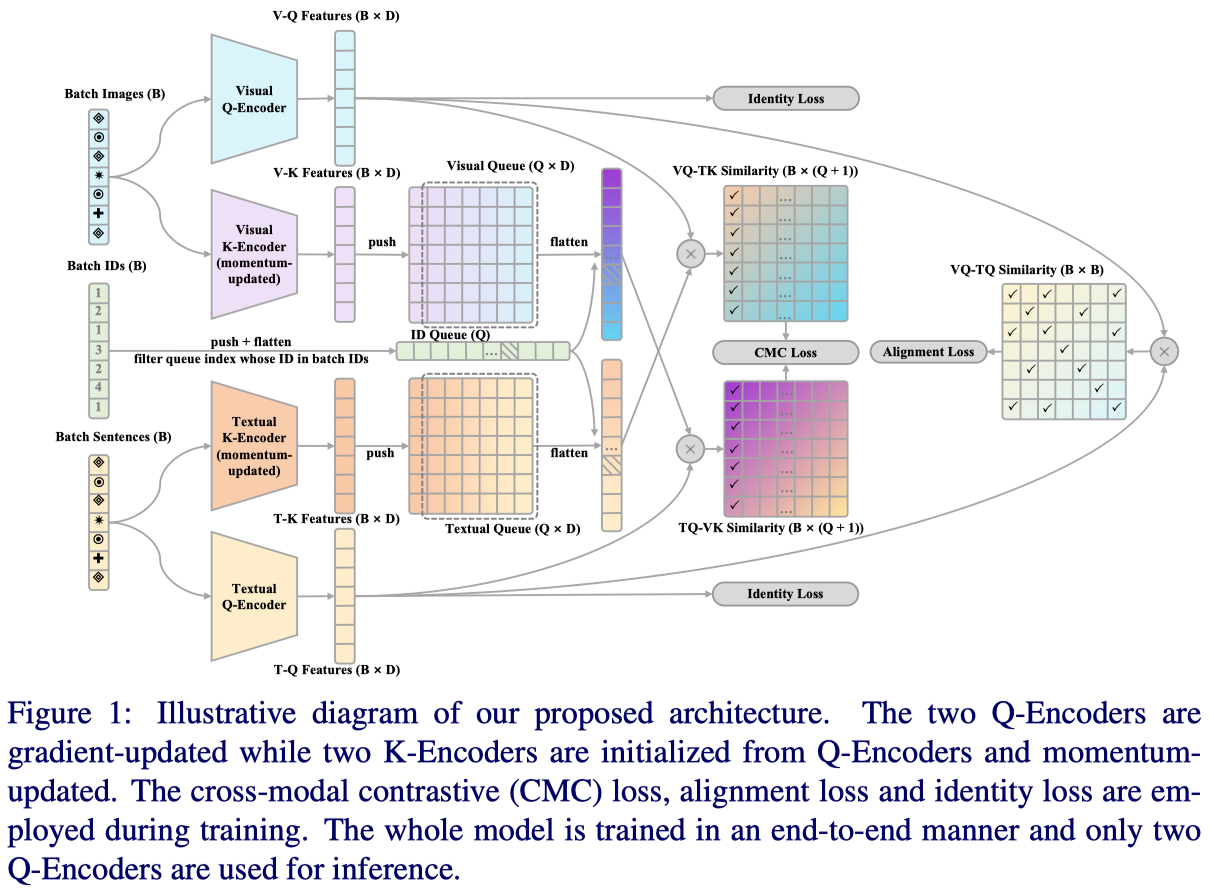
给定文本查询t,TBPS的目标是从图库中检索与t中的内容最匹配的图像v。如果t和v共享相同的身份,则检索成功。
本文提出的框架如上图所示。它由两个查询编码器和(视觉和文本q编码器)以及两个键编码器(视觉和文本k编码器),分别由参数化。在训练期间,查询和键编码器都用于处理来自其自身模态的输入。键编码器的输出被推送到队列中,队列用于构建负对以进行对比学习。在推理过程中,仅使用两个查询编码器进行特征提取。检索首先通过计算查询特征和库中所有候选特征的轮廓提取特征之间的余弦相似度来完成,然后选择相似度得分最高的候选。
3.1 Learning from limited TBPS data
Cross-modal momentum contrastive learning
在以前的工作中,学习更多区分特征的限制之一是由于训练阶段的有限负对。MoCo提供了一种构建与batch大小解耦的动态队列的机制,这使得可以从特定batch之外的更多负样本中学习。受此启发,作者提出了跨膜台动量对比学习,以充分利用当前TBPS数据。
具体来说,给定一批人物图像,一批描述,以及它们的身份,将V和T馈送到它们相应的查询编码器和键编码器中,以获得它们的归一化特征:
其中,。和ID将被推入三个队列,即视觉队列()、文本队列()和身份队列(),用于负对构造。
为了学习区分性跨模态特征,对于每个图像查询,作者定义了其查询特征(作为锚)、其对应的文本键特征(作为正键)和存储在文本队列中的键(作为负键)之间的跨模态对比损失,其中指示其标识的ID不在当前batch中。同时,当将每个描述视为一个查询时,作者还以对称的方式应用了跨模态对比学习。整体交叉模态对比损失按下式计算,其中表示可调温度:
在计算跨模态对比损失后,使用反向传播梯度更新两个查询编码器。根据MoCo,两个键编码器的参数和根据下式中给出的规则进行更新,其中m是动量参数。
Joint training
作者还将广泛使用的对齐损失和身份损失纳入了本文的端到端训练pipeline。总损失L是三个损失的总和:
Post-processing
在推理阶段,作者采用了交叉模态k-reciprocal rerank算法来进一步提高性能。通过k最近的单峰邻居和k最近的跨模态邻居的Jaccard距离计算成对的rerank相似度,然后将其添加到原始余弦相似度中。
3.2 Transferring knowledge from generic image-text pairs
TBP的传统方法是初始化视觉和文本编码器,主干分别在单峰数据上预训练,例如,在ImageNet上预训练的ResNet50和在大型语料库上预训练的BERT。然而,这种初始化带来了一个巨大的结构差距,很难用TBP的当前有限数据来弥补。为了解决这个问题,一种简单的方法是初始化我们在大规模通用图像-文本对上预先训练的编码器,例如MSCOCO字幕、Flickr30k和WIT,然后微调TBP的整个模型。
然而,实验发现,这种直观的转移策略产生了较差的性能。这种负迁移可能是由TBPS域和通用数据集之间的域差距引起的。即使在模态预训练场景下,这种领域差距也特别存在于文本方面。由于TBP的高度细粒度特性,TBP中的描述句比一般数据中的描述句长得多,每个词都很重要。然而,在泛型数据上预训练的文本主干可能会获得更粗粒度的信息,并忽略一些详细的单词,因此会发生负迁移。尽管如此,由于大规模对比学习,作者相信对泛型数据的预训练仍然可以为每个单词提供更有意义的嵌入。

为了解决这个问题,作者提出了一种前一学习策略,在保持视觉流不变的情况下,对文本流进行三次修改。具体来说,如上图所示,作者以预先训练过的CLIP文本编码器(CLIP-TE)为例来演示本文的修改。首先,一个改动是以逐字的方式将整个句子输入CLIP-TE,以获得字型嵌入。对于每个单词,其单词类型嵌入由CLIP-TE最后一层的[EOS] token表示。其次,将CLIP-TE冻结在整个训练阶段。在实际实现中,预先计算存储所有单词嵌入的字典,并从训练过程中删除冻结的CLIP-TE。第三,为了弥补句子级语义信息的不足,作者添加了一个Bi-GRU,然后使用max-pooling对句子中嵌入的所有单词类型进行语境化。从实验上看,采用我们提出的转移学习策略的模型产生了显著的性能提升。该策略允许文本流有效地传递从大规模通用图像-文本对中学习的知识。
4.实验

上表展示了本文方法相比于SOTA方法的性能对比。

上表展示了本文方法不同模块的消融实验结果。

上表展示了本文方法在不同text encoder下的实验结果。

上表展示了本文方法在不同队列长度下的实验结果。

上图展示了本文方法的检索结果。
5. 总结
本文提出了一种新的基于文本的人物搜索方法。本文的模型通过使用提出的跨膜台动量对比学习策略学习更多的判别特征,并有效地传递从通用图文对学习到的知识,以弥补数据稀缺的问题。事实证明,本文的方法在CUHK-PEED上的表现明显优于现有技术。
已建立深度学习公众号——FightingCV,欢迎大家关注!!!
ICCV、CVPR、NeurIPS、ICML论文解析汇总:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading
面向小白的Attention、重参数、MLP、卷积核心代码学习:https://github.com/xmu-xiaoma666/External-Attention-pytorch
加入交流群,请添加小助手wx:FightngCV666
参考资料
https://arxiv.org/abs/2110.10807: https://arxiv.org/abs/2110.10807
[2]https://github.com/BrandonHanx/TextReID: https://github.com/BrandonHanx/TextReID
边栏推荐
- Are you hungry - Institution tree radio
- 测试开发【Mock 平台】08 开发:项目管理(四)编辑功能和Component抽离
- OPPO Enco X2 迎来秋季产品升级 旗舰体验全面拉满
- PostgreSQL — Installation and Common Commands
- How to submit a PR?【OpenHarmony Growth Plan】【OpenHarmony Open Source Community】
- 2021 CybricsCTF
- 二级指针的简单理解
- YOLOv3 SPP source analysis
- 【图像分类】2019-MoblieNetV3 ICCV
- 2019河北省大学生程序设计竞赛部分题题解
猜你喜欢


随机推荐
"POJ 3666" Making the Grade problem solution (two methods)
ansible各个模块的详解和使用
将视图模型转换为使用 Hilt 依赖注入
双 TL431 级联振荡器
2021DozerCTF
用汇编带你看Golang里到底有没有值类型、引用类型
[Golang]如何优雅管理系统中的几十个UDF(API)
"Distributed Microservice E-commerce" Topic (1) - Project Introduction
[Golang]用反射让你的代码变优美
[Golang]从0到1写一个web服务(上)
《分布式微服务电商》专题(一)-项目简介
面向未来的 IT 基础设施管理架构——融合云(Unified IaaS)
【图像分类】2019-MoblieNetV3 ICCV
The most complete GIS related software in history (CAD, FME, ArcGIS, ArcGISPro)
七月券商金工精选
(10) Sequence and deserialization of image data
PostgreSQL 介绍
每日一R「03」Borrow 语义与引用
leetcode 85.最大矩形 单调栈应用
Echart饼状图标注遮盖解决方案汇总