当前位置:网站首页>【golang map】 深入了解map内部存储协议
【golang map】 深入了解map内部存储协议
2022-08-10 20:21:00 【平静不绝望】
1. 测试debug源码
map只是一个哈希表。数据已整理放入一个桶数组。每个存储桶最多包含 8 个键/元素对。哈希的低位是 用于选择一个桶。每个桶包含几个 每个散列的高位位以区分条目 在单个存储桶中。 如果超过 8 个键散列到一个桶,我们链上 额外的桶。 当哈希表增长时,我们分配一个新数组 两倍大的桶。桶是递增的 从旧桶数组复制到新桶数组。 映射迭代器遍历桶数组和 按遍历顺序返回键(桶#,然后溢出 链序,然后是桶索引)。保持迭代 语义上,我们永远不会在它们的桶中移动键(如果 我们这样做了,键可能会返回 0 或 2 次)。什么时候 增长表,迭代器继续迭代 旧表,如果桶必须检查新表 他们正在迭代已经被移动(“疏散”) 到新表。
package main
import (
"fmt"
"unsafe"
)
const (
// Maximum number of key/elem pairs a bucket can hold.
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
)
func showSpread(m interface{}) {
// dataOffset is where the cell data begins in a bmap
const dataOffset = unsafe.Offsetof(struct {
tophash [bucketCnt]uint8
cells uint8 // 类型随意,主要计算tophash的开始位移量
}{}.cells)
t, h := mapTypeAndValue(m)
fmt.Println()
fmt.Printf("Overflow buckets: %d", h.noverflow)
fmt.Println()
fmt.Printf("t.bucketsize: %d", t.bucketsize)
fmt.Println()
fmt.Printf("t.keysize: %d", t.keysize)
numBuckets := 1 << h.B
elementCnt := 0
for r := 0; r < numBuckets*bucketCnt; r++ {
bucketIndex := r / bucketCnt
cellIndex := r % bucketCnt
b := (*bmap)(add(h.buckets, uintptr(bucketIndex)*uintptr(t.bucketsize)))
// 行开头
if cellIndex == 0 {
fmt.Printf("\nBucket %3d:", bucketIndex)
for i := 0; i < bucketCnt ; i ++ {
tophash_i := add(unsafe.Pointer(b), uintptr(i)*uintptr(1))
//fmt.Printf(" |%d|-->|%d| ", *(*uint8)(unsafe.Pointer(uintptr(tophash_i))), b.tophash[i])
fmt.Printf("|%d|", *(*uint8)(unsafe.Pointer(uintptr(tophash_i))))
}
}
// 行末尾
if cellIndex == bucketCnt - 1 {
// 最后一个值处理
if b.tophash[cellIndex] == 0 {
// cell is empty
fmt.Printf(" 【cell %d is empty!】 ", cellIndex)
} else {
k := add(unsafe.Pointer(b), dataOffset+uintptr(cellIndex)*uintptr(t.keysize))
ei := emptyInterface{
_type: unsafe.Pointer(t.key),
value: k,
}
key := *(*interface{})(unsafe.Pointer(&ei))
fmt.Printf("%3d", key.(int))
elementCnt++
}
// 打印出后面的value
for i := 0; i < elementCnt ; i ++ {
v := add(unsafe.Pointer(b), dataOffset+uintptr(bucketCnt)*uintptr(t.keysize)+uintptr(i)*uintptr(t.elemsize))
vi := emptyInterface{
_type: unsafe.Pointer(t.elem),
value: v,
}
value := *(*interface{})(unsafe.Pointer(&vi))
fmt.Printf(" 【%d】", value.(int))
}
elementCnt = 0
continue
} else {
// lookup cell
if b.tophash[cellIndex] == 0 {
// cell is empty
fmt.Printf(" 【cell %d is empty!】 ", cellIndex)
continue
}
elementCnt++
k := add(unsafe.Pointer(b), dataOffset+uintptr(cellIndex)*uintptr(t.keysize))
ei := emptyInterface{
_type: unsafe.Pointer(t.key),
value: k,
}
key := *(*interface{})(unsafe.Pointer(&ei))
fmt.Printf(" %3d", key.(int))
}
}
fmt.Printf("\n\n")
}
func add(p unsafe.Pointer, x uintptr) unsafe.Pointer {
return unsafe.Pointer(uintptr(p) + x)
}
func main() {
fmt.Println( 1 << bucketCntBits)
m := make(map[int]int)
for i := 0; i < 50; i++ {
m[i] = i * 3
}
showSpread(m)
m = make(map[int]int)
for i := 0; i < 8; i++ {
m[i] = i * 3
}
showSpread(m)
}
// ----------指定hit B和count的统计-----------
func main_test1() {
m := make(map[int]int)
_, hm := mapTypeAndValue(m)
fmt.Printf("Elements | h.B | Buckets\n\n")
var prevB uint8
for i := 0; i < 100000000; i++ {
m[i] = i * 3
if hm.B != prevB {
fmt.Printf("%8d | %3d | %8d\n", hm.count, hm.B, 1<<hm.B)
prevB = hm.B
}
}
}
type emptyInterface struct {
_type unsafe.Pointer
value unsafe.Pointer
}
func mapTypeAndValue(m interface{}) (*maptype, *hmap) {
ei := (*emptyInterface)(unsafe.Pointer(&m))
return (*maptype)(ei._type), (*hmap)(ei.value)
}
type maptype struct {
typ _type
key *_type
elem *_type
bucket *_type // internal type representing a hash bucket
// function for hashing keys (ptr to key, seed) -> hash
hasher func(unsafe.Pointer, uintptr) uintptr
keysize uint8 // size of key slot
elemsize uint8 // size of elem slot
bucketsize uint16 // size of bucket
flags uint32
}
// Needs to be in sync with ../cmd/link/internal/ld/decodesym.go:/^func.commonsize,
// ../cmd/compile/internal/gc/reflect.go:/^func.dcommontype and
// ../reflect/type.go:/^type.rtype.
// ../internal/reflectlite/type.go:/^type.rtype.
type _type struct {
size uintptr
ptrdata uintptr // size of memory prefix holding all pointers
hash uint32
tflag tflag
align uint8
fieldAlign uint8
kind uint8
// function for comparing objects of this type
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
// gcdata stores the GC type data for the garbage collector.
// If the KindGCProg bit is set in kind, gcdata is a GC program.
// Otherwise it is a ptrmask bitmap. See mbitmap.go for details.
gcdata *byte
str nameOff
ptrToThis typeOff
}
type nameOff int32
type typeOff int32
// tflag is documented in reflect/type.go.
//
// tflag values must be kept in sync with copies in:
// cmd/compile/internal/gc/reflect.go
// cmd/link/internal/ld/decodesym.go
// reflect/type.go
// internal/reflectlite/type.go
type tflag uint8
const (
tflagUncommon tflag = 1 << 0
tflagExtraStar tflag = 1 << 1
tflagNamed tflag = 1 << 2
tflagRegularMemory tflag = 1 << 3 // equal and hash can treat values of this type as a single region of t.size bytes
)
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and elem do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and elem do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
2. 上面可以直接运行,部分函数直接copy 自 runtime/map.go 运行结果如下:
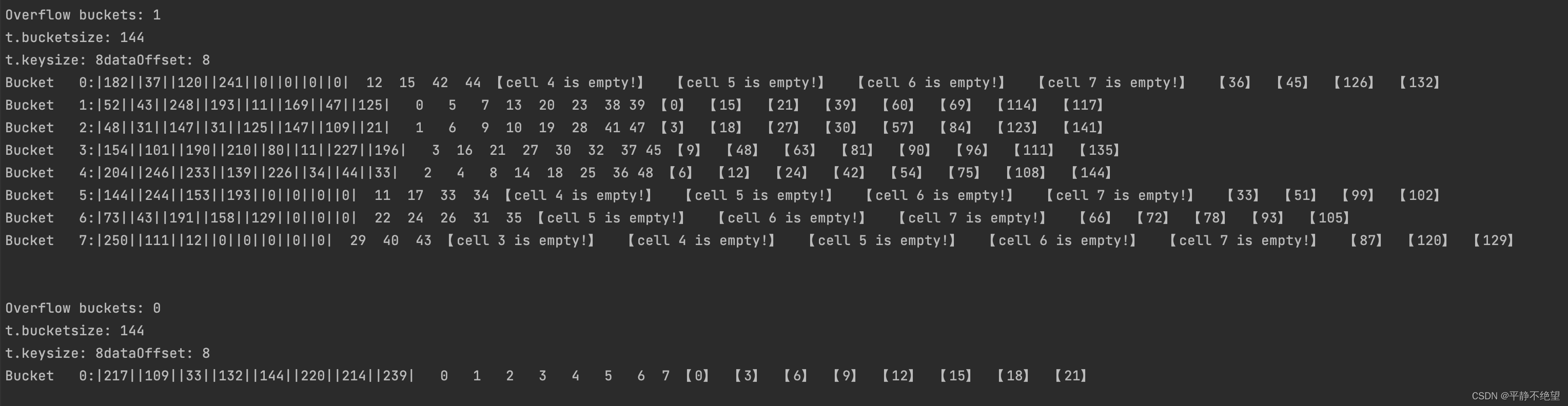
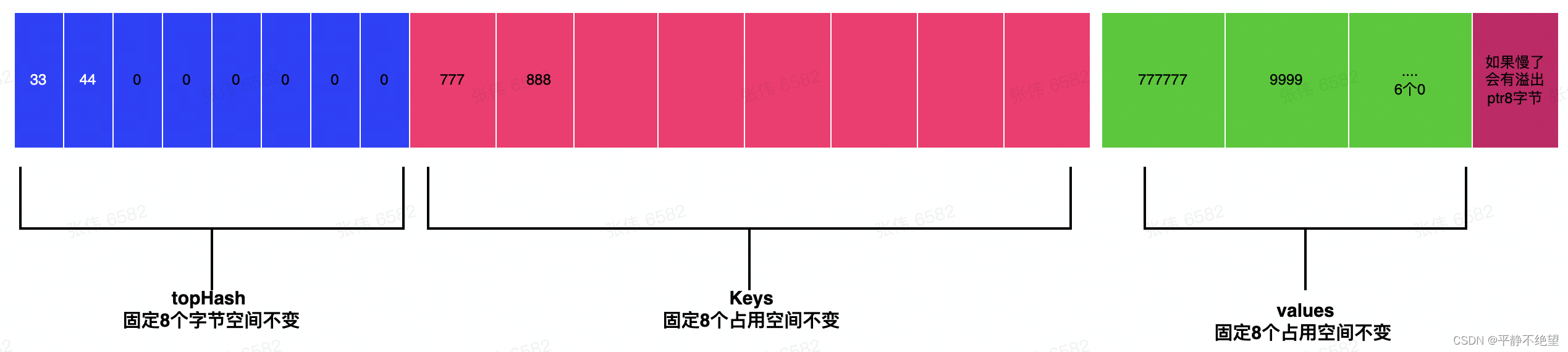
3. 小结 直接上图 希望你能理解
- 每个bucket的存储结构如下:1+8+8+1 = 18*8 = 144B (示例中的int 类型键值对)
- bucket和count的关系可以通过上面的源码 第二个main方法可以端倪下
- 负载因子6.5
- bucket固定大小8
边栏推荐
- 二级指针的简单理解
- [SemiDrive source code analysis] [MailBox inter-core communication] 51 - DCF_IPCC_Property implementation principle analysis and code combat
- 多功能纳米酶Ag/PANI|柔性衬底纳米ZnO酶|铑片纳米酶|Ag-Rh合金纳米颗粒纳米酶|铱钌合金/氧化铱仿生纳米酶
- "POJ 3666" Making the Grade problem solution (two methods)
- [CNN] Brush SOTA's trick
- Linux服务器安装Redis,详细步骤。
- 常用Anaconda安装错误解决办法Traceback (most recent call last):[通俗易懂]
- (十二)STM32——NVIC中断优先级管理
- (12) findContours function hierarchy explanation
- Common ports and services
猜你喜欢
巧用RoaringBitMap处理海量数据内存diff问题

Public Key Retrieval is not allowed(不允许公钥检索)【解决办法】
2019河北省大学生程序设计竞赛部分题题解

参天生长大模型:昇腾AI如何强壮模型开发与创新之根?
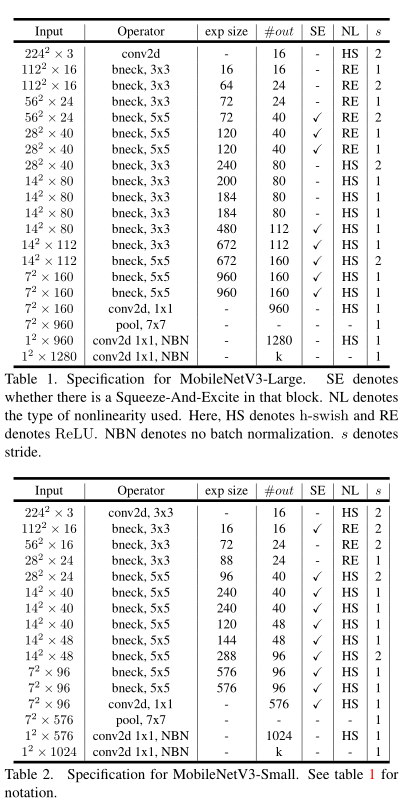
【图像分类】2019-MoblieNetV3 ICCV
Site Architecture Detection & Chrome Plugin for Information Gathering
赎金信问题答记
史上最全GIS相关软件(CAD、FME、Arcgis、ArcgisPro)
爬虫基本原理介绍、实现以及问题解决
@Autowired注解 --required a single bean, but 2 were found出现的原因以及解决方法
随机推荐
详叙c中的分支与循环
Transferrin-modified vincristine-tetrandrine liposomes | transferrin-modified co-loaded paclitaxel and genistein liposomes (reagents)
【ACM】dp专场训练
mysql踩坑----case when then用法
大小端的理解以及宏定义实现的理解
(十)图像数据的序列与反序列化
Linux服务器安装Redis,详细步骤。
uni-app 数据上拉加载更多功能
redis如何查看key的有效期
argparse——命令行参数解析
【CMU博士论文】视频多模态学习:探索模型和任务复杂性,152页pdf
线性结构----链表
idea插件 协议 。。 公司申请软件用
【毕业设计】基于STM32的天气预报盒子 - 嵌入式 单片机 物联网
keepalived:故障检测自动修复脚本
一次由groovy引起的fullGC问题排查
Ferritin particle-loaded raltitrexed/pemetrexed/sulfadesoxine/adamantane (scientific research reagent)
导入FontForge生成字体
【图像分类】2019-MoblieNetV3 ICCV
MySQL数据库的主从复制部署详解