当前位置:网站首页>【图像分类】2019-MoblieNetV3 ICCV
【图像分类】2019-MoblieNetV3 ICCV
2022-08-10 19:12:00 【說詤榢】
【图像分类】2019-MoblieNetV3 ICCV
论文题目:Searching for MobileNetV3
论文地址:https://arxiv.org/abs/1905.02244
代码链接: https://github.com/xiaolai-sqlai/mobilenetv3
发表时间:2019年5月
引用:Howard A, Sandler M, Chu G, et al. Searching for mobilenetv3[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 1314-1324.
引用数:2468
1. 简介
相对重量级网络而言,轻量级网络的特点是参数少、计算量小、推理时间短。更适用于存储空间和功耗受限的场景,例如移动端嵌入式设备等边缘计算设备。因此轻量级网络受到了广泛的关注,其中MobileNet可谓是其中的佼佼者。MobileNetV3经过了V1和V2前两代的积累,性能和速度都表现优异,受到学术界和工业界的追捧,无疑是轻量级网络的“抗把子“。MobileNetV3 参数是由NAS(network architecture search)搜索获取的,又继承的V1和V2的一些实用成果,并引人SE通道注意力机制,可谓集大成者。本文以应用为主,结合代码剖析MobileNetV3的网络结构,不会对NAS以及其设计思想做过多解析。
特点
- 论文推出两个版本:Large 和 Small,分别适用于不同的场景;
- 使用NetAdapt算法获得卷积核和通道的最佳数量;
- 继承V1的深度可分离卷积;
- 继承V2的具有线性瓶颈的残差结构;
- 引入SE通道注意力结构;
- 使用了一种新的激活函数h-swish(x)代替Relu6,h的意思表示hard;
- 使用了Relu6(x + 3)/6来近似SE模块中的sigmoid;
- 修改了MobileNetV2后端输出head;
2. 网络
2.1 通道可分离卷积
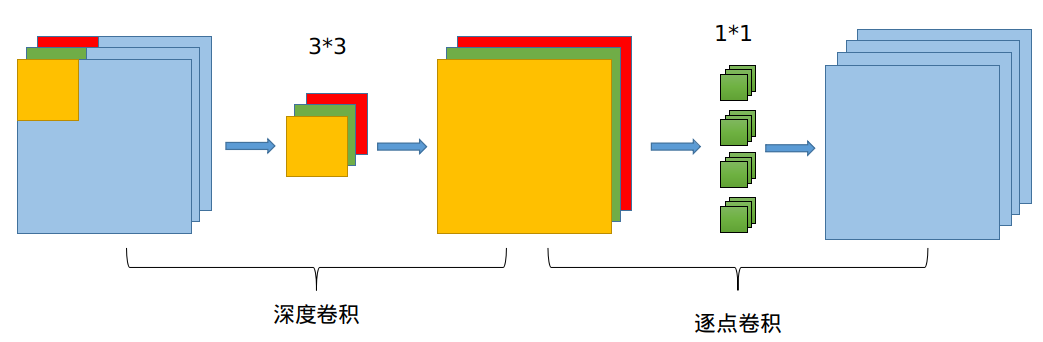
通道分离卷积是MobileNet系列的主要特点,也是其发挥轻量级作用的主要因素。如下图,通道可分离卷积分为两个过程:1.channel方向通道可分离卷积;2.正常的1X1卷积输出指定的channel个数。
代码
# 首先利用1X1卷积进行通道压缩,可以进一步压缩模型大小
self.conv1 = nn.Conv2d(in_size, expand_size, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(expand_size)
self.nolinear1 = nolinear # 激活函数,使用H-swish或H-relu
# 注意,通道可分离卷积使用分组卷积操作进行,这里分成和卷积核相同的channel组数实现。
self.conv2 = nn.Conv2d(expand_size, expand_size, kernel_size=kernel_size, stride=stride,
padding=kernel_size // 2, groups=expand_size, bias=False)
self.bn2 = nn.BatchNorm2d(expand_size)
self.nolinear2 = nolinear
# 利用1X1卷积输出指定通道个数的卷积,这一步一定要有,不然无法控制输出通道个数。也有聚合分离特征的作用
self.conv3 = nn.Conv2d(expand_size, out_size, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_size)
2.2 SE模块
SE通道注意力机制,老生常谈的话题。这里不进行解析,直接给出代码。值得注意的是,这里利用1X1卷积实现的FC操作,本质上和FC是一样的。这里利用hsigmoid模拟sigmoid操作。
class SeModule(nn.Module):
def __init__(self, in_size, reduction=4):
super(SeModule, self).__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_size, in_size // reduction, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(in_size // reduction),
nn.ReLU(inplace=True),
nn.Conv2d(in_size // reduction, in_size, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(in_size),
hsigmoid())
def forward(self, x):
return x * self.se(x)
2.3 h-swish 和 h-sigmoid
利用近似操作模拟swish和relu,公式如下:
h − s w i s h [ x ] = x R e L U 6 ( x + 3 ) 6 h-swish[x]=x\frac{ReLU6(x+3)}{6} h−swish[x]=x6ReLU6(x+3)
代码实现
class hswish(nn.Module):
def forward(self, x):
out = x * F.relu6(x + 3, inplace=True) / 6
return out
class hsigmoid(nn.Module):
def forward(self, x):
out = F.relu6(x + 3, inplace=True) / 6
return out
2.4 bneck
核心模块,也是网络的基本模块。主要实现了通道可分离卷积+SE通道注意力机制+残差连接。结构图如下:
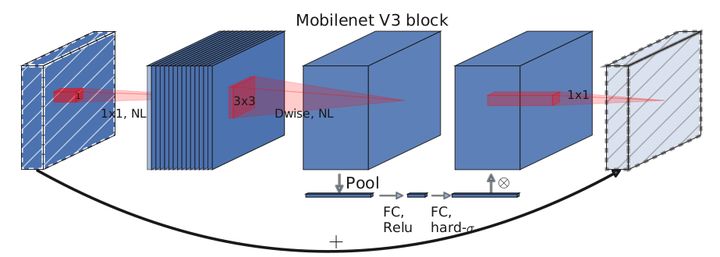
代码实现
def forward(self, x):
out = self.nolinear1(self.bn1(self.conv1(x))) # 降维
out = self.nolinear2(self.bn2(self.conv2(out))) # 通道可分离卷积
out = self.bn3(self.conv3(out)) # 1X1卷积聚合特征
if self.se != None:
out = self.se(out) # 通道注意力机制
out = out + self.shortcut(x) if self.stride == 1 else out # 残差连接
return out
2.5 总体架构
移除之前的瓶颈层连接,进一步降低网络参数。可以有效降低11%的推理耗时,而性能几乎没有损失。修改结构如下:
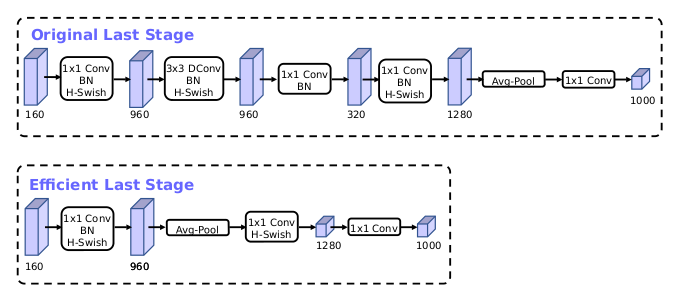
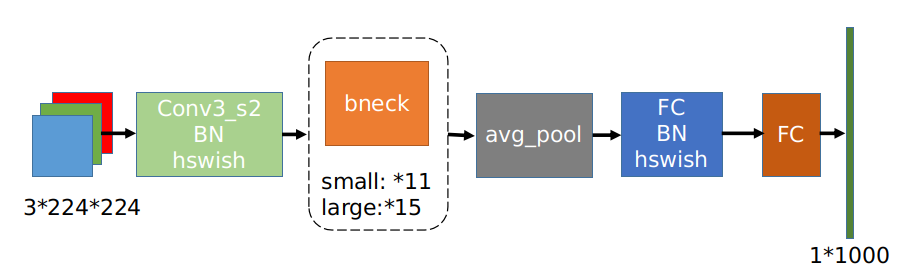
上图为MobileNetV3的网络结构图,large和small的整体结构一致,区别就是基本单元bneck的个数以及内部参数上,主要是通道数目。
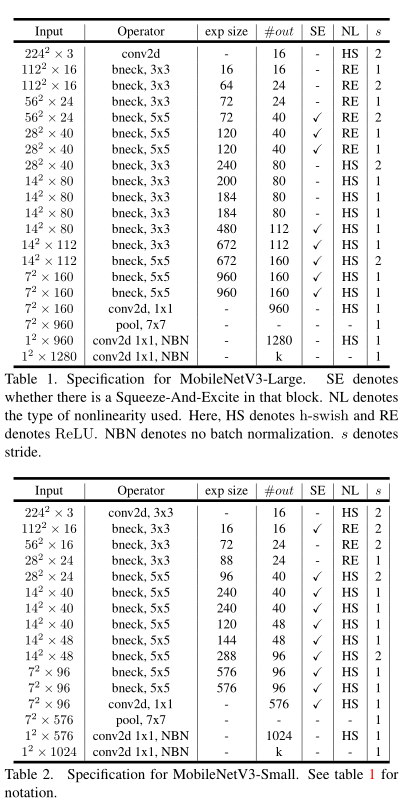
上表为具体的参数设置,其中bneck是网络的基本结构。SE代表是否使用通道注意力机制。NL代表激活函数的类型,包括HS(h-swish),RE(ReLU)。NBN 代表没有BN操作。 s 是stride的意思,网络使用卷积stride操作进行降采样,没有使用pooling操作。
3. 代码
'''MobileNetV3 in PyTorch. See the paper "Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation" for more details. '''
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import init
class hswish(nn.Module):
def forward(self, x):
out = x * F.relu6(x + 3, inplace=True) / 6
return out
class hsigmoid(nn.Module):
def forward(self, x):
out = F.relu6(x + 3, inplace=True) / 6
return out
class SeModule(nn.Module):
def __init__(self, in_size, reduction=4):
super(SeModule, self).__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_size, in_size // reduction, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(in_size // reduction),
nn.ReLU(inplace=True),
nn.Conv2d(in_size // reduction, in_size, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(in_size),
hsigmoid()
)
def forward(self, x):
return x * self.se(x)
class Block(nn.Module):
'''expand + depthwise + pointwise'''
def __init__(self, kernel_size, in_size, expand_size, out_size, nolinear, semodule, stride):
super(Block, self).__init__()
self.stride = stride
self.se = semodule
self.conv1 = nn.Conv2d(in_size, expand_size, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(expand_size)
self.nolinear1 = nolinear
self.conv2 = nn.Conv2d(expand_size, expand_size, kernel_size=kernel_size, stride=stride, padding=kernel_size//2, groups=expand_size, bias=False)
self.bn2 = nn.BatchNorm2d(expand_size)
self.nolinear2 = nolinear
self.conv3 = nn.Conv2d(expand_size, out_size, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_size)
self.shortcut = nn.Sequential()
if stride == 1 and in_size != out_size:
self.shortcut = nn.Sequential(
nn.Conv2d(in_size, out_size, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_size),
)
def forward(self, x):
out = self.nolinear1(self.bn1(self.conv1(x)))
out = self.nolinear2(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
if self.se != None:
out = self.se(out)
out = out + self.shortcut(x) if self.stride==1 else out
return out
class MobileNetV3_Large(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV3_Large, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.hs1 = hswish()
self.bneck = nn.Sequential(
Block(3, 16, 16, 16, nn.ReLU(inplace=True), None, 1),
Block(3, 16, 64, 24, nn.ReLU(inplace=True), None, 2),
Block(3, 24, 72, 24, nn.ReLU(inplace=True), None, 1),
Block(5, 24, 72, 40, nn.ReLU(inplace=True), SeModule(40), 2),
Block(5, 40, 120, 40, nn.ReLU(inplace=True), SeModule(40), 1),
Block(5, 40, 120, 40, nn.ReLU(inplace=True), SeModule(40), 1),
Block(3, 40, 240, 80, hswish(), None, 2),
Block(3, 80, 200, 80, hswish(), None, 1),
Block(3, 80, 184, 80, hswish(), None, 1),
Block(3, 80, 184, 80, hswish(), None, 1),
Block(3, 80, 480, 112, hswish(), SeModule(112), 1),
Block(3, 112, 672, 112, hswish(), SeModule(112), 1),
Block(5, 112, 672, 160, hswish(), SeModule(160), 1),
Block(5, 160, 672, 160, hswish(), SeModule(160), 2),
Block(5, 160, 960, 160, hswish(), SeModule(160), 1),
)
self.conv2 = nn.Conv2d(160, 960, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(960)
self.hs2 = hswish()
self.linear3 = nn.Linear(960, 1280)
self.bn3 = nn.BatchNorm1d(1280)
self.hs3 = hswish()
self.linear4 = nn.Linear(1280, num_classes)
self.init_params()
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
out = self.hs1(self.bn1(self.conv1(x)))
out = self.bneck(out)
out = self.hs2(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 7)
out = out.view(out.size(0), -1)
out = self.hs3(self.bn3(self.linear3(out)))
out = self.linear4(out)
return out
class MobileNetV3_Small(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV3_Small, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.hs1 = hswish()
self.bneck = nn.Sequential(
Block(3, 16, 16, 16, nn.ReLU(inplace=True), SeModule(16), 2),
Block(3, 16, 72, 24, nn.ReLU(inplace=True), None, 2),
Block(3, 24, 88, 24, nn.ReLU(inplace=True), None, 1),
Block(5, 24, 96, 40, hswish(), SeModule(40), 2),
Block(5, 40, 240, 40, hswish(), SeModule(40), 1),
Block(5, 40, 240, 40, hswish(), SeModule(40), 1),
Block(5, 40, 120, 48, hswish(), SeModule(48), 1),
Block(5, 48, 144, 48, hswish(), SeModule(48), 1),
Block(5, 48, 288, 96, hswish(), SeModule(96), 2),
Block(5, 96, 576, 96, hswish(), SeModule(96), 1),
Block(5, 96, 576, 96, hswish(), SeModule(96), 1),
)
self.conv2 = nn.Conv2d(96, 576, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(576)
self.hs2 = hswish()
self.linear3 = nn.Linear(576, 1280)
self.bn3 = nn.BatchNorm1d(1280)
self.hs3 = hswish()
self.linear4 = nn.Linear(1280, num_classes)
self.init_params()
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
out = self.hs1(self.bn1(self.conv1(x)))
out = self.bneck(out)
out = self.hs2(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 7)
out = out.view(out.size(0), -1)
out = self.hs3(self.bn3(self.linear3(out)))
out = self.linear4(out)
return out
def test():
net = MobileNetV3_Small()
x = torch.randn(2,3,224,224)
y = net(x)
print(y.size())
# test()
参考资料
边栏推荐
- mysql踩坑----case when then用法
- Leetcode 200.岛屿数量 BFS
- flask生成路由的2种方式和反向生成url
- 30分钟使用百度EasyDL实现健康码/行程码智能识别
- [Teach you how to make a small game] Write a function with only a few lines of native JS to play sound effects, play BGM, and switch BGM
- Keras deep learning combat (17) - image segmentation using U-Net architecture
- @Autowired annotation --required a single bean, but 2 were found causes and solutions
- 铁蛋白-AHLL纳米颗粒|人表皮生长因子-铁蛋白重链亚基纳米粒子(EGF-5Cys-FTH1)|铁蛋白颗粒包载氯霉素Chloramphenicol-Ferritin
- (12) findContours function hierarchy explanation
- 多线程与高并发(五)—— 源码解析 ReentrantLock
猜你喜欢
苹果字体查找
你不知道的浏览器页面渲染机制
烟雾、空气质量、温湿度…自己徒手做个环境检测设备
WCF and TCP message communication practice, c # 】 【 realize group chat function
@Autowired注解 --required a single bean, but 2 were found出现的原因以及解决方法
【C#】WCF和TCP消息通信练习,实现群聊功能
ARouter使用自定义注解处理器,自动生成跳转Activity的代码,避免手动填写和管理path
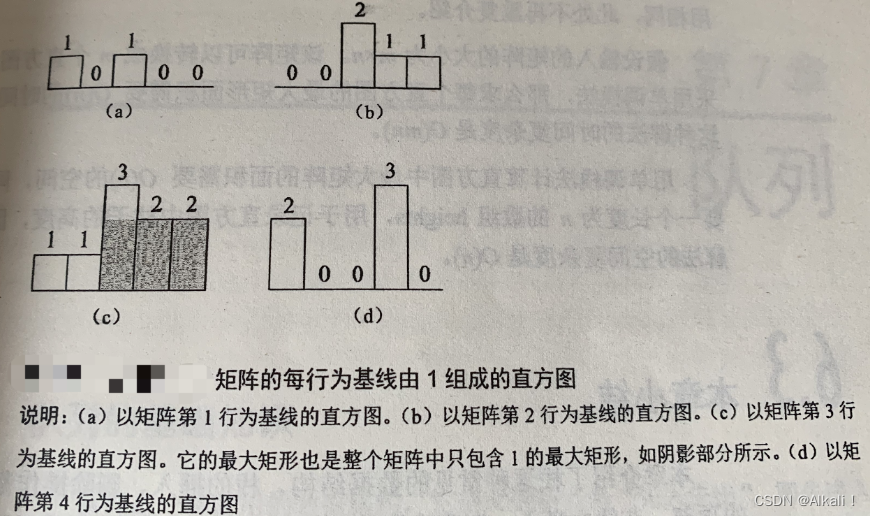
leetcode 85.最大矩形 单调栈应用
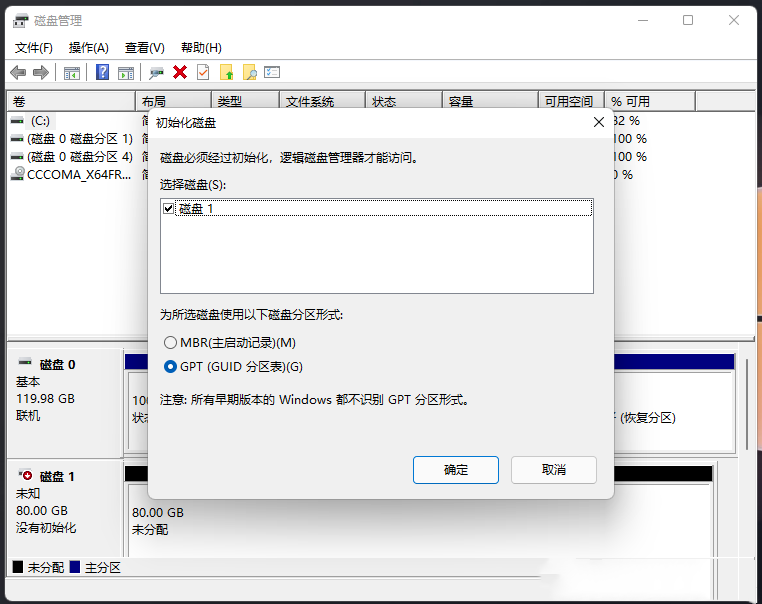
电脑重装系统Win11格式化硬盘的详细方法
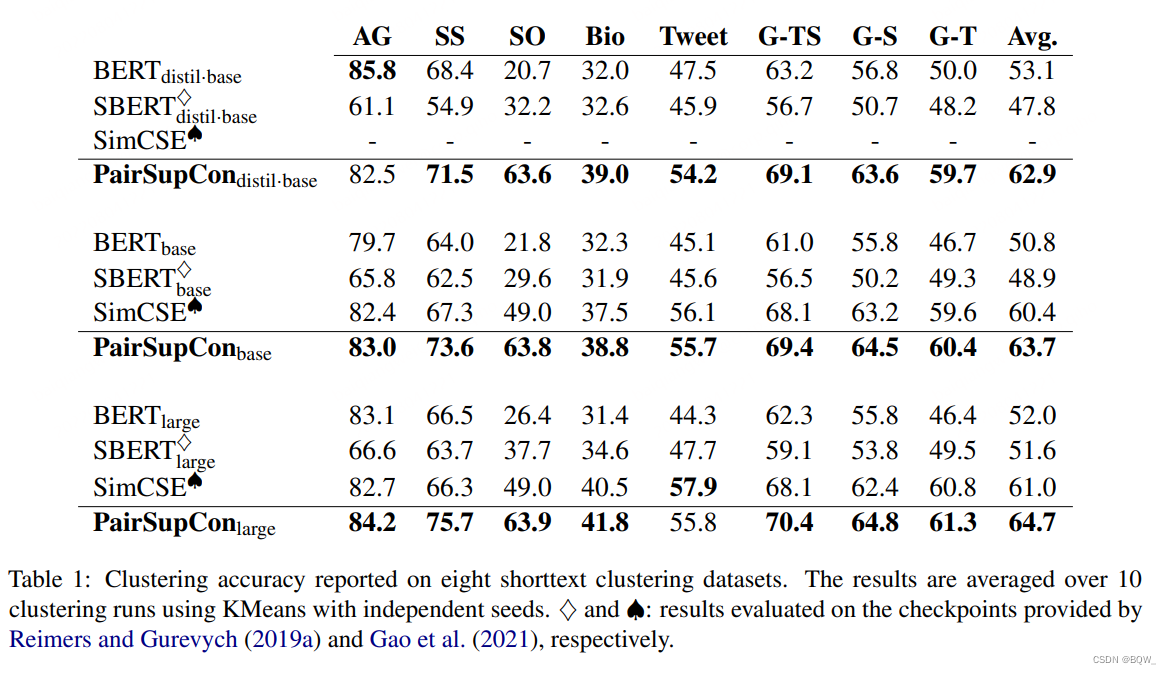
【自然语言处理】【向量表示】PairSupCon:用于句子表示的成对监督对比学习
随机推荐
The 2021 ICPC Asia Shanghai Regional Programming Contest D、E
mysql----group by、where以及聚合函数需要注意事项
When selecting a data destination when creating an offline synchronization node - an error is reported in the table, the database type is adb pg, what should I do?
力扣150-逆波兰表达式求值——栈实现
C语言写数据库
多功能纳米酶Ag/PANI|柔性衬底纳米ZnO酶|铑片纳米酶|Ag-Rh合金纳米颗粒纳米酶|铱钌合金/氧化铱仿生纳米酶
Optimizing Bloom Filter: Challenges, Solutions, and Comparisons论文总结
Optimization is a habit The starting point is to 'stand close to the critical'
铁蛋白颗粒负载雷替曲塞/培美曲塞/磺胺地索辛/金刚烷(科研试剂)
【Knowledge Sharing】What is SEI in the field of audio and video development?
3D Game Modeling Learning Route
不止跑路,拯救误操作rm -rf /*的小伙儿
The servlet mapping path matching resolution
About npm/cnpm/npx/pnpm and yarn
idea插件 协议 。。 公司申请软件用
【毕业设计】基于STM32的天气预报盒子 - 嵌入式 单片机 物联网
力扣18-四数之和——双指针法
MATLAB设计,FPGA实现,联合ISE和Modelsim仿真的FIR滤波器设计
常用Anaconda安装错误解决办法Traceback (most recent call last):[通俗易懂]
CMU博士论文 | 视频多模态学习:探索模型和任务复杂性