当前位置:网站首页>05 Spark on 读取内部数据分区存储策略(源码角度分析)
05 Spark on 读取内部数据分区存储策略(源码角度分析)
2022-08-08 23:31:00 【YaPengLi.】
Spark-读取内部数据分区存储策略源码角度分析
Spark-读取内部数据分区策略(源码角度分析):https://blog.csdn.net/lucklilili/article/details/115432028
针对下面代码片段源码角度进行分析,创建RDD并且调用saveAsTextFile()函数,最终执行结果为part-00000 => 1、part-00000 => 2 3、part-00003 => 4 5

Step1:
调用makeRDD函数,长度size = 5,分区数numSlices = 3。
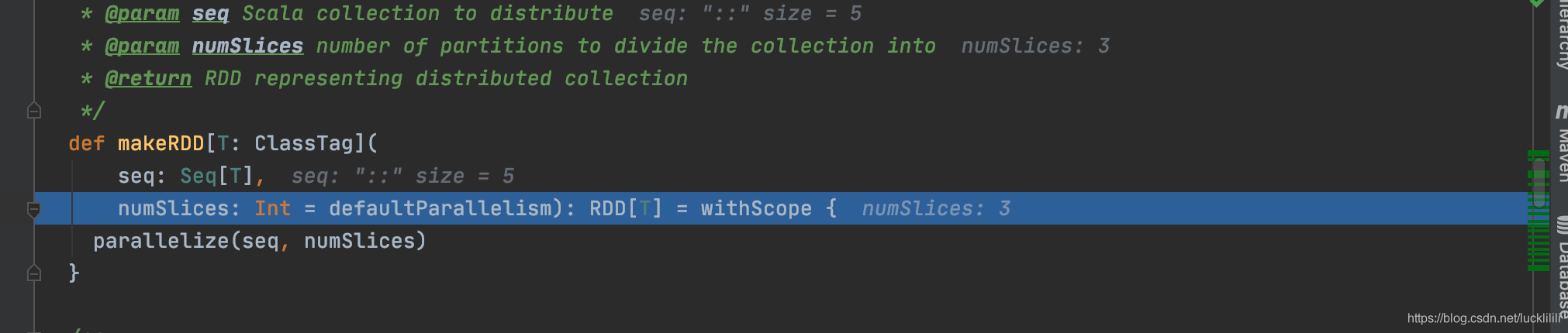
Step2:
调用parallelize函数,长度size = 5,数据1、2、3、4、5,分区数numSlices = 3。
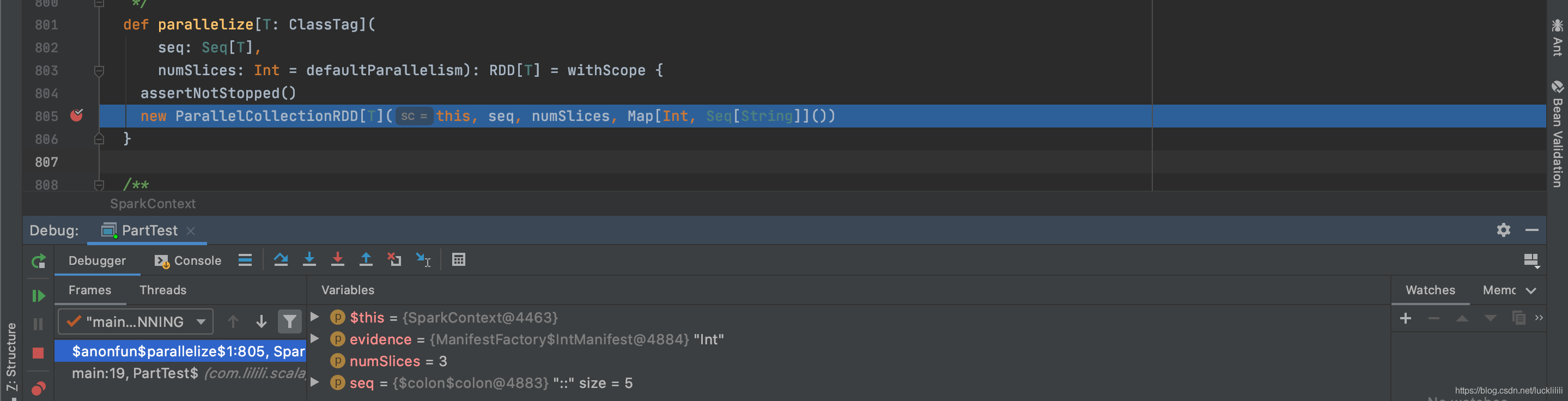
Step3:
调用parallelize的getPartitions函数,长度size = 5,数据1、2、3、4、5,分区数numSlices = 3。

Step4:
执行slice函数的case模式匹配,长度size = 5,数据1、2、3、4、5,分区数numSlices = 3。

Step5:
调用本函数里面positions方法,长度size = 5,分区数numSlices = 3 。
// Sequences need to be sliced at the same set of index positions for operations
// like RDD.zip() to behave as expected
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map { i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
}
1:
var start = (0 * 5) / 3 = 0
var end =((0 + 1) * 5) /3 = 1
2:
var start = (1 * 5) / 3 = 1
var end =((1 + 1) * 5) / 3 = 3
3:
var start = (2 * 5) / 3 = 3
var end =((2 + 1) * 5) / 3 = 5 Step6:
循环遍历调用slice函数
数据:1,2,3,4,5
每次执行slice()后得的结果(0,1),(1,3),(3,5),最终结果如:
(0,1) = 1 => part00000
(1,3) = 2,3 => part00001
(3,5) => 4,5 => part00001 
边栏推荐
猜你喜欢









随机推荐
bp神经网络的学习心得
用工具实现 Mock API 的整个流程
(2022杭电多校三)1011.Taxi(曼哈顿最值+二分)
Manacher(求解最长回文子串)
stm32使用spi1在slave 模式下 dma 读取数据
域前置通信过程和溯源思路
(2022杭电多校三)1002-Boss Rush(状压DP+二分)
从stm32移植ucos2的代码到GD32
STM8L LCD digital tube driver, thermometer LCD display
ArrayAccess 接口用处
Hi3516 use wifi module
神经网络学习笔记(1)
ndk和JNI的使用初探
【YOLOv5】6.0环境搭建(不定时更新)
(2022牛客多校三)J-Journey(dijkstra)
MES对接Simba实现展讯平台 IMEI 写号与耦合测试
Tp5 in cache cache, storage cell phone text message authentication code
牛客练习赛88 D 克鲁斯卡尔重构树
跨域请求浏览器无法显示set-cookie,坑了我一晚上
启牛商学院靠不靠谱呢?证券账户开了安全吗