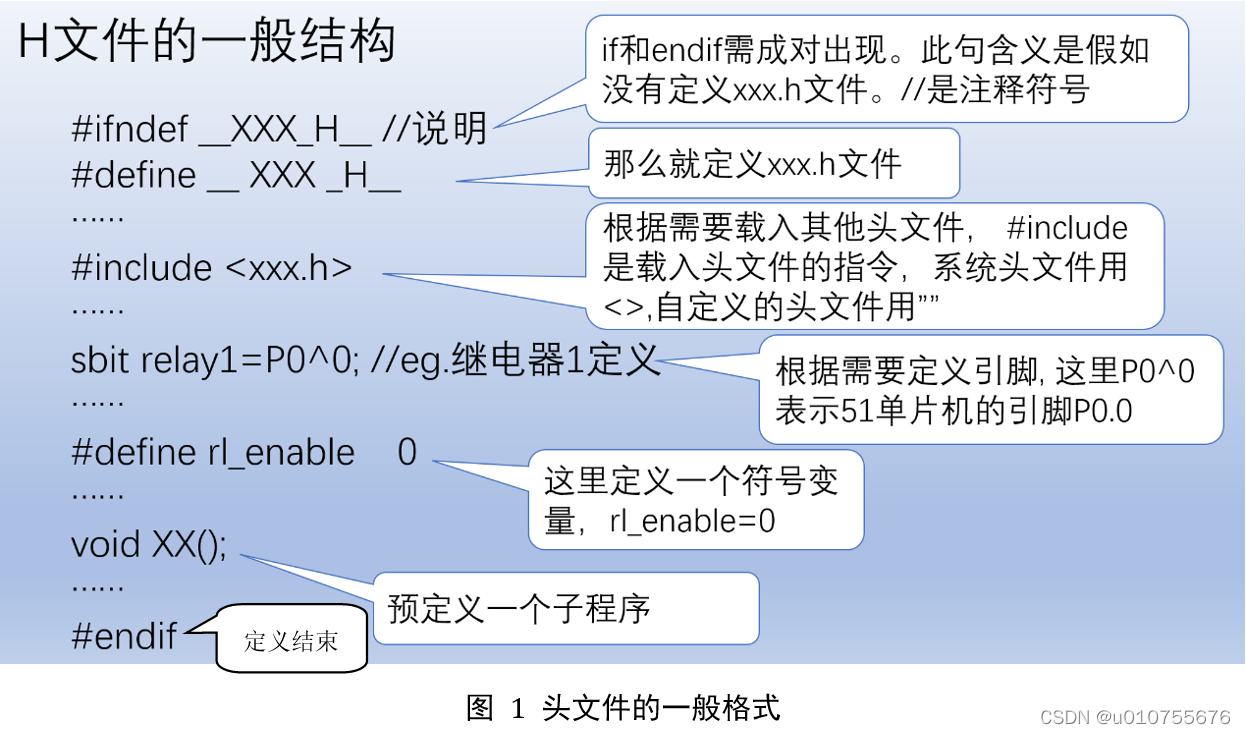
2、Redis It's a key-value The storage system , It supports storage value There are more types , Include string、list、set、zset(sorted set -- Ordered set ) and hash. These data structures support push/pop、add/remove And take intersection, union and difference sets and more abundant operations , And these operations are atomic . On this basis ,Redis Support various sorts of sorting . To ensure efficiency , The data is cached in memory ,Redis Periodically, updated data is written to disk or changes are written to an appended log file , And on this basis to achieve master-slave( Master-slave ) Sync .
3、Redis Provides java、C/C++、PHP、JavaScript、Perl、Object-C、Python、Ruby、Erlang Such as the client , Easy to use .
4、Reids Support master-slave synchronization . Data can be synchronized from the master server to any number of slaves , The slave server can be the master server associated with other servers . This makes Redis Single layer number replication can be performed . The disk can write to the data intentionally or unintentionally . Due to the full implementation of the release / Subscribe mechanism , Enables trees to be synchronized anywhere from the database , Subscribe to a channel and receive a complete record of message publication from the master server . Synchronization helps with scalability and data redundancy for read operations .
5、 In our daily Java Web In development , All use database to store data , Because there is usually no high concurrency in general system tasks , So that doesn't seem to be a problem , But when it comes to the need for large amounts of data , For example, the scene of some commodities being snapped up , Or when the page traffic is large in an instant , A single system that uses a database to hold data is disk oriented , Disk read / Writing speed is relatively slow and there are serious performance drawbacks , In a flash thousands of requests came , It needs the system to complete thousands of times of reading in a very short time / Write operations , This time is often not the database can bear , Extremely easy to cause database system paralysis , Serious production problems that eventually lead to service downtime .

[](()
Two 、NoSQL technology
In order to overcome the above problems ,java web Projects usually introduce NoSQL technology , This is a
《 A big factory Java Analysis of interview questions + Back end development learning notes + The latest architecture explanation video + Practical project source code handout 》 Free open source Prestige search official account 【 Advanced programming 】
A memory based database , And provide some persistence function .
Redis and MongoDB Is currently the most widely used NoSQL,? And just Redis In terms of technology, , It has excellent performance , It can support more than 100000 read and write operations per second , Its performance is much better than that of database , And it also supports clustering 、. Distributed 、 Master slave synchronization and other configurations , In principle, it can be expanded infinitely , Let more data be stored in memory , What's more gratifying is that it also supports certain transactional capabilities , This ensures the high security of the data in this scenario .
3、 ... and 、Redis High concurrency and fast reasons for
Redis Using multiplexing technology , Can handle concurrent connections . Not IO Internal implementation adoption epoll, Adopted epoll Simple event framework implemented by ourselves .epoll Read and write 、 close 、 All connections are converted into events , And then use it epoll Multiplexing characteristics of , Never in IO Waste a little time .
Four 、Redis Why single threaded
1、 Official answer
Redis Is a memory based operation ,CPU No Redis Bottleneck ,Redis The most likely bottleneck is the size of machine memory or network bandwidth . Since a single thread is easy to implement , and CPU Not a bottleneck , So it's natural to adopt the single thread scheme .
2、 Detailed reasons
(1) No performance consumption of various locks required
Redis The data structures are not all key-value Formal , also list,hash And so on , These structures are likely to perform very fine-grained operations , Like adding an element after a long list , stay hash Add or remove an object from , These operations may require a lot of locks , The result is a significant increase in synchronization overhead .
All in all , In the case of a single thread , You don't have to think about locks , There is no operation of locking and releasing locks , No performance consumption due to possible deadlocks .
(2) Single thread and multi process cluster scheme
The power of single thread is actually very powerful , Every core efficiency is also very high , Multithreading naturally has a higher performance limit than single threading , But in today's computing environment , Even the upper limit of single machine multithreading is often not enough , What needs to be further explored is the scheme of multi server clustering , The multithreading technology in these schemes is still useless .
So single thread 、 Multi process clustering is a fashionable solution .
(3)CPU Consume
Using single thread , Unnecessary context switches and race conditions are avoided , There is also no switching consumption caused by multiple processes or multiple threads CPU.
But if CPU be called Redis Bottleneck , Or you don't want the server to CPU Nuclear idle , What to do with that ?
Consider more Redis process ,Redis yes key-value database , It's not a relational database , No constraints between data . As long as the client knows which key In which Redis Just in the process .
5、 ... and 、 Advantages and disadvantages of single thread
1、 advantage
2、 Inferiority
Can't play multi-core CPU Performance advantages , However, you can open multiple... By clicking Redis Examples to improve .
6、 ... and 、Redis High concurrency summary
1、Redis Is a pure memory database , It's usually a simple access operation , Threads take up a lot of time , The time spent is mainly focused on IO On , So the reading speed is fast ;
2、Redis Use non blocking IO,IO Multiplexing , Single thread used to poll descriptor , Open database 、 Turn off 、 read 、 All writes are converted into events , Reduces context switching and contention during thread switching .
3、Redis Single thread model is adopted , Ensure the atomicity of each operation , It also reduces context switching and competition of threads .
4、Redis Full use hash structure , Fast reading speed , There are also some special data structures , Optimized data storage , For example, compressed table , Compress and store short data , Another example is jump watch , Use ordered data structures to speed up reading and writing .
5、Redis Using the event separator realized by ourselves , High efficiency , Non blocking internal execution , Large throughput .
7、 ... and 、 stay java Use in Redis
[](()
1、 add to Jedis rely on
Want to be in Java Use in Redis cache , Need to add related Jar Packet dependency , open Maven Warehouse website :[https://mvnrepository.com/](()?, Search for Jedis:
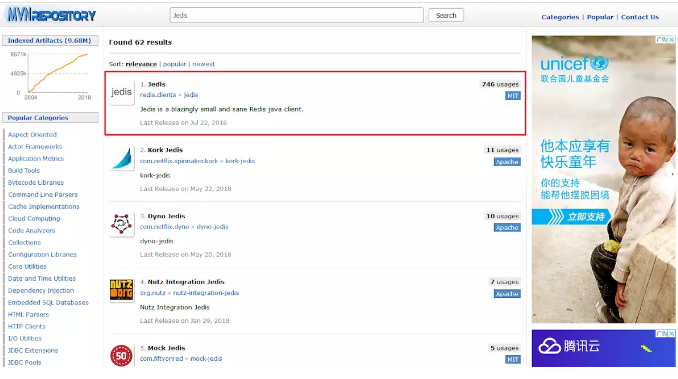
Just import it into the project , Let's get right Redis Test the write performance of :
@Test
public void redisTester() {
Jedis jedis = new Jedis("localhost", 6379, 100000);
int i = 0;
try {
long start = System.currentTimeMillis();// Start milliseconds
while (true) {
long end = System.currentTimeMillis();
if (end - start >= 1000) {// When it is greater than or equal to 1000 millisecond ( amount to 1 second ) when , End operation
break;
}
i++;
jedis.set("test" + i, i + "");
}
} finally {// Close the connection
jedis.close();
}
// Print 1 Seconds, right Redis The number of operations
System.out.println("redis Operations per second :" + i + " Time ");
}
----------- test result -----------
redis Operations per second :10734 Time
[](()
2、 Use Redis Connection pool
Same as database connection pool ,Java Redis Classes are also provided ?
redis.clients.jedis.JedisPool
To manage us Reids Connect pool objects , And we can use ?
redis.clients.jedis.JedisPoolConfig
To configure the connection pool , The code is as follows :
JedisPoolConfig poolConfig = new JedisPoolConfig();
// Maximum free number
poolConfig.setMaxIdle(50);
// maximum connection
poolConfig.setMaxTotal(100);
// Maximum waiting milliseconds
poolConfig.setMaxWaitMillis(20000);
// Create a connection pool using configuration
JedisPool pool = new JedisPool(poolConfig, "localhost");
// Get a single connection from the connection pool
Jedis jedis = pool.getResource();
// If you need a password
//jedis.auth("password");
Redis Only six data structures can be supported ?(string/hash/list/set/zset/hyperloglog) The operation of ?, But in Java In, we usually focus on class objects , So in Redis Stored data structure month java Convert between objects , Such as writing some tool classes by yourself ? For example, changing the role of an object , It's easy , But when it comes to many objects , Both the workload and the difficulty of the work are very big , So in general ,? In terms of operands , Use Redis It's still hard , Fortunately spring These are encapsulated and supported .?
8、 ... and 、Redis stay Java Web Application in
Redis stay Java Web There are two main application scenarios :
[](()
1、 Store data for caching ?
In the daily access to the database , The number of read operations far exceeds the number of write operations , The proportion is about ?1:9? To ?3:7, So it's much more possible to read than to write . When we use SQL Statement to the database for read-write operations , The database will go to the disk and retrieve the corresponding data index , It's a relatively slow process .?
If you put it in Redis in , That is, put it in memory , Let the server directly read the data in memory , Then the speed will be much faster , And it will greatly reduce the pressure on the database , But using memory for data storage is also relatively expensive , Limited to cost reasons , Generally we just use Redis Store some common and main data , Such as user login information .
Generally speaking, in use Redis When it comes to storage , We need to consider... From the following aspects :
[](()
(1) Is business data commonly used ? How is the utilization rate ?
If the utilization rate is low , There is no need to write to the cache .
[](()
(2) This service is read operation , Or write more operations ?
If there are many write operations , Frequent need to write to database , There is no need to use caching .
[](()
(3) What is the size of the business data ?
If you want to store hundreds of megabytes of files , It will put a lot of pressure on the cache , It's not necessary .
After considering these problems , If you think it's necessary to use caching , Then use it ! Use Redis The read logic as a cache is shown in the figure below :
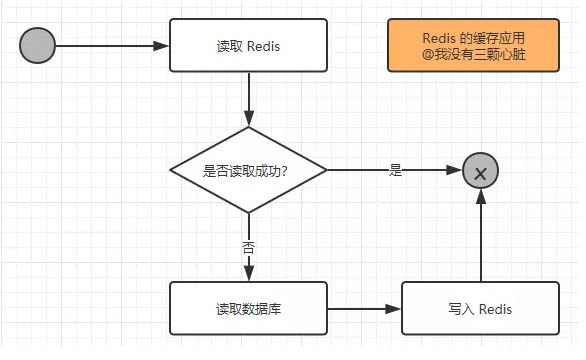
From the picture above, we can see the following two points :
(1) When reading data for the first time , Read Redis The data will fail , This triggers the program to read the database , Read the data out , And write Redis in
(2) When data needs to be read for the second time and later , It will read directly Redis, After reading the data, the process ends , This greatly improves the speed .
From the above analysis, we can know , Read operations are far more likely than write operations , So use Redis To handle the data that needs to be read frequently in daily life , The increase in speed is obvious , It also reduces the dependence on the database , So that the pressure of the database is greatly reduced .
The logic of read operation is analyzed , Now let's look at the write operation process :
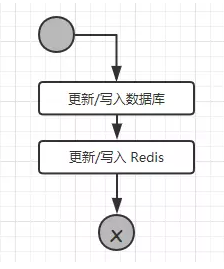
As can be seen from the process , Update or write operations , Multiple required Redis The operation of , If the number of business data writes is much greater than the number of reads, there is no need to use Redis.
[](()
2、 High speed reading and writing occasions
In today's Internet , There are more and more high concurrency situations , For example, tmall double 11、 Grab a red envelope 、 Grab concert tickets, etc , In these cases, thousands of requests arrive at the server at a certain moment or a short time , If you simply use the database to process , Even if it doesn't collapse , It's going to be slow , If it is light, the user experience is very poor, and the number of users is running , Again, the database is paralyzed , The service outage , And such occasions are not allowed !
So we need to use Redis To cope with such a high concurrency situation , Let's first look at the flow of a request operation :
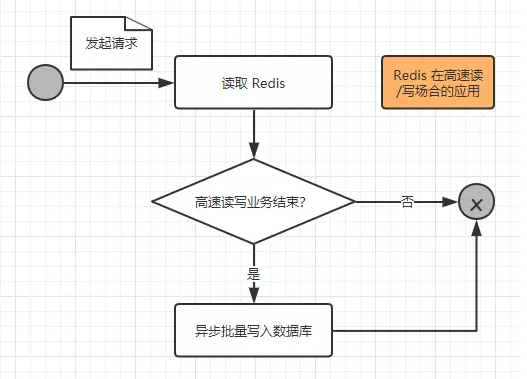
Let's elaborate on this process further :
(1) When a request arrives at the server , Just put the business data in Redis Read and write on , Without any operation on the database , This can greatly improve the speed of reading and writing , So as to meet the corresponding needs of high-speed .
(2) But these cached data still need to be persistent , It's stored in the database , So after a request operation Redis After reading and writing , Will judge whether the high-speed read-write business is over , This judgment is usually made when the second kill commodity is 0, The amount of the red envelope is 0 It was established , If not , The database will not be manipulated ; If set up , The trigger event will Redis The cached data is written to the database in batch at one time , So as to complete the work of persistence .
Nine 、 stay spring Use in Redis
It says Redis Unable to manipulate the object , Can't be used in those base types and Java Easy conversion between objects , But in Spring in , These problems can be solved by using RedisTemplate Be solved !
I want to do that , except Jedis In addition to the package, you need to Spring introduce spring-data-redis package .
[](()
1、 Use spring To configure JedisPoolConfig object
Most of the time , We'll still use connection pooling , So I used it first Spring To configure a JedisPoolConfig object :
<bean id="poolConfig" class="redis.clients.jedis.JedisPoolConfig">
<property name="maxIdle" value="50"/>
<property name="maxTotal" value="100"/>
<property name="maxWaitMillis" value="20000"/>
</bean>
2、 Configure the factory model for the connection pool
Okay , We have now configured the related properties of the connection pool , So what kind of factory is used to realize it ? stay Spring Data Redis There are four factory models for us to choose from , They are :
Here we simply configure it as JedisConnectionFactory:
<bean id="connectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory">
<property name="hostName" value="localhost"/>
<property name="port" value="6379"/>
版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231416491043.html