当前位置:网站首页>实验记录:搭建网络过程
实验记录:搭建网络过程
2022-08-09 11:32:00 【匿名的魔术师】
一、遇到的问题
1.RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same当想要测试搭建的网络,看看各个过程的输出形状,随便创建个固定shape的输入如下
search_var = torch.FloatTensor(1, 3, 255, 255).cuda()观察报错的问题,发现是输入 是 torch.cuda.FloatTensor类型的,而 weight是 torch.FloatTensor类型的,所以,需要把 model 放到cuda上才行。
解决:
model =model.cuda()2. TypeError: 'PointTarget' object is not iterable
这个是由于在 设计 points时产生的问题,由于定义类中的
class PointTarget:
def __init__(self):
def __call__(self, target, size, neg=False):
__init__ 和 __call__ 传入参数冲突引起的,故需要做出改变。
而且在利用类时一定要首先初始化实例对象,
3.debug 时 变量若显示unable to get repr for <class ‘torch.Tensor‘
分类损失函数,用的focal loss, 所以送入之前数据需要映射到0~1之间,故需要进行一下sigmoid运算 。
4. RuntimeError: CUDA error: device-side assert triggered
5 .神经网络的输出出现nan值
这个可能由于搭建网络结构时,某层的网络的输出没有规一化或者 relu 输出,导致输出值不正常
6. config.py 与 config.yaml冲突
若config.yaml中设置的参数值同时也出现在了config.py文件中的话,一定要确保config.py文件中参数设置的值 与 config.yaml中设置的一致
7. 分布式训练卡住
可以设置
--nproc_per_node=1但第二天早上 又 设置成 2又不卡了。
二、 实现历程
1. 搭建自己的网络
首先根据设计的方法搭建模型,编写代码。 搭建模型的过程中 分部分来完成,即先完成基础的每个部分,然后将它们连接在一起。比如举例来说 分成了 backbone 和 head。
最后通过创建一个model类来完成模型的前向传播过程,这个会继承pytorch的nn.Module类
可以随便创建哥输入变量,然后一步一步看看传输过程中特征shape的变化,创建tensor变量的语句如下
template_var = torch.rand((1, 3, 127, 127))
search_var = torch.rand((1, 3, 255, 255))2. 设计以及实现损失函数的计算
搭建完网络结构之后,可以通过model得到想要的输出形式,然后接下来就是损失函数的设计与实现。首先,根据损失函数的需要,先把整个流程确定下来。在这个过程中,涉及到 标签的get,根据想要的输出怎么得到对应的标签呢?标签的shape 一般来说都是与 model 的output shape 相对应的。这里 标签一定要与 得到的预测输出一一对应,与之相联系的就是在进行标签和预测输出进行 permute 和 torch.cat 等等操作时shape变换的对应。
1) 创建points
2) 得到标签 cls 和 reg
3) 组成data 正式训练时构建 dataloader
4) 搭建模型 model
5) 数据送入model,得到预测输出
3. 嵌入模型
1) 注意data的重新设置。 data中的标签看看是否匹配了
2) 注意训练时 model 的 forward 过程,是否顺利
3) 网络中各模块学习率和优化器的设置,注意这方面的解耦学习率的设置 是通过字典来设置的,参数 和 lr 键 以及再设置对应的值
trainable_params += [{'params': filter(lambda x: x.requires_grad,
model.backbone.parameters()),
'lr': cfg.BACKBONE.LAYERS_LR * cfg.TRAIN.BASE_LR}] # <c> 可能是骨干网络和其他的部分 初始学习率不一样
if cfg.ADJUST.ADJUST: # True
trainable_params += [{'params': model.fpn.parameters(),
'lr': cfg.TRAIN.BASE_LR}] # <c>
trainable_params += [{'params': model.ban.parameters(),
'lr': cfg.TRAIN.BASE_LR}]4. 推理过程
推理过程与训练过程是两个截然不同的部分,一般推理过程和训练过程在同一个tracker类里,不过它们需要分开去定义自己的流程。
边栏推荐
猜你喜欢
C# async 和 await 理解
信号量SIGCHLD的使用,如何让父进程得知子进程执行结束,如何让父进程区分多个子进程的结束
爱可可AI前沿推介(8.9)
fork创建多个子进程
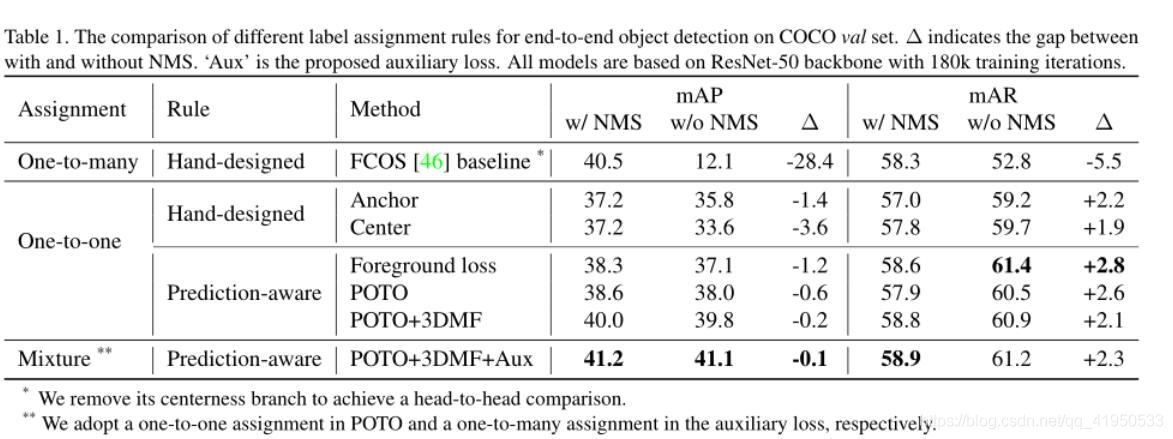
End-to-End Object Detection with Fully Convolutional Network学习笔记
Visual Studio 2017 ASP.NET Framework MVC 项目 MySQL 配置连接
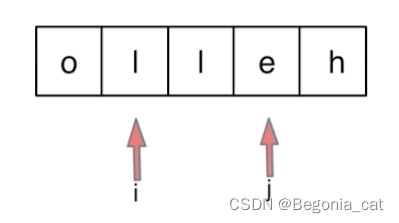
字符串 | 反转字符串 | 双指针法 | leecode刷题笔记
Chinese valentine's day?Programmers don't exist
元宇宙:下一代互联网启程(附元宇宙深度报告PDF)
【C language】动态数组的创建和使用
随机推荐
使用gdb调试多进程程序、同时调试父进程和子进程
enum in c language
ZOJ 1729 & ZOJ 2006(最小表示法模板题)
PTA 实验7-5 输出大写英文字母(10 分)
LeetCode 1413.逐步求和得到正数的最小值
【概率论】一元概率分布的平均化
C语言中信号函数(signal)的使用
百钱买鸡(一)
人体解析(Human Parse)开源数据集整理
[现代控制理论]2_state-space状态空间方程
[现代控制理论]6_稳定性_李雅普诺夫_Lyapunov
x86异常处理与中断机制(1)概述中断的来源和处理方式
JS 封装节流(后期优化)
MySQL事务隔离级别
PAT1002
PAT1013 并查集 DFS(查找联通分量的个数)
x86异常处理与中断机制(2)中断向量表
PAT1001
PAT1009
redis内存的淘汰机制