当前位置:网站首页>MySQL面试题整理
MySQL面试题整理
2022-08-10 12:36:00 【PHP白小白】
- 建表的时候需要注意什么?
- 注意使用合适的存储引擎:读多写少使用Myisam 写多读少使用InnoDB 只是用于当作临时中间表使用可以使用Memory ;
- 避免字段为空(null)的时候,可以为每个字段添加个默认值,提高查询的效率;
- 存取时间类型的字段我们可以采用一个时间戳类型存储;而不去使用date或者是datetime;
- 在SQL语句中频繁使用到的字段,或者是外键建立一个合适的索引,提高查询的效率;
- 如果使用InnoDB表一定要有个主键,避免数据库底层进行一个添加隐藏列的操作;
- 字段类型也需要注意,比如:enum使用tyint代替,身份证和手机号使用定长的char存储,如果数据不为负数的话可以采用无符号类型进行存储
- 数据类型的区别:char和varchar,int(10)和int(11)?
- Char和varchar:
- char是存储定长的,varchar是存储可变长的;
- char查询效率比varchar查询效率快;
- char存储的长度不足设定的长度时以空格补齐,varchar存储的长度不足设定的长度时只分配占用的长度;
- int(10)和int(11):int(10)和int(11)只是展示的长度不同,其实分配的大小是相同的;
- 主键索引和唯一索引?
- 一个表里只有一个主键索引,唯一索引可以有多个;
- 主键索引不能为空,唯一索引可以为空;
- 主键创建一定会创建一个唯一索引,但是唯一索引并不能创建主键索引;
- 主键索引可以是当作外键来使用,但是唯一索引不行;
- 主键索引实质是一种约束,但是主键索引是一种索引;
- 主键采用自增id(int)还是UUID(varchar)?
- 自增id在添加的过程中是顺序自增的,UUID是随机的;
- 自增id查询的效率比UUID快;
- uuid存储的空间更大容易造成内存碎片化的情况;
- UUID更加适用于分布式场景使用;
- count(*)和count(字段)区别?
- 使用聚合函数时优先考虑count(*),因为官方做过优化;
- 如果字段加了索引,可以使用count(字段)
- 脏读、幻读、不可重复读?
- 脏读对应数据库隔离级别读未提交:事务A和事务B操作同一条数据事务A修改未提交,这个时候事务B读取到一条未提交的数据,这就是脏读;
- 幻读对应读已提交:幻读注重写的操作,事务A修改所有数据的状态为1,修改完这个时候去查看数据,同时事务B新增了一条数据状态为0,造成一种幻读的现象;
- 不可重复读对应可重复读,事务A读取了一次中途数据被修改然后又读了一次发现数据不一致,这就是不可重复读
- 三大范式和事务的四大特性和四大隔离级别?
三大范式:
- 第一范式:每一列都是单一属性,不可再分割;
- 第二范式:在第一范式的基础上,其他列完全依赖于主键,不能只依赖于主键的一部分;
- 第三范式:在第二范式的基础上,消除传递依赖,只依赖于主键不依赖于其他非主键
四大特性:
- 原子性:事务全部成功否则全部失败(回滚);
- 一致性:事务的前后总量不变,比如:转账事务A有五百事务B也有五百,事务A转给事务B三百这个时候总和必须是1000,否则就不是一致性;
- 持久性:事务提交以后对数据库的改变是持久性的;
- 隔离性:多个事务同时提交互不影响
四大隔离级别:
- 读未提交:修改了数据但是数据没有提交,会造成:脏读、幻读、不可重复读
- 读已提交:修改了读已提交,会造成:幻读、不可重复读
- 可重复读:对多次读取的结果都一致,除非被事务修改,会造成:幻读(MySQL默认隔离级别)
- 串行化:最高隔离级别,事务依次执行可以避免所有读
- 索引建立的场景?联合索引?
索引建立的场景:
- 根据表的数据大小进行添加索引,通常表的数据大于三百或者是五百条的时候就可以考虑加索引了;
- SQL语句中常用与where、order by、group by查询的字段;
- 如果使用InnoDB引擎需要设置一个主键,SQL语句中需要给外键建立一个索引;
- 避免索引失效的场景;
联合索引:
- 联合索引建立时遵循最左原则(只有先命中最左边的索引才能命中之后的索引);
- 联合索引设置顺序时,把查询最多的放在最左边依次递减;
- 在遇到范围查询时联合索引会有失效的情况;
- 索引失效的场景?
- 避免模糊查询的时候%放在字段之前;
- 避免在SQL进行表达式的计算;
- 子查询的时候可以使用Exists进行替换;unin替代or
- 避免隐式类型转换;
- InnoDB和Myisam的区别?
- Innodb支持事务,myisam不支持
- Innodb支持外键,myisam不支持
- Innodb支持行级锁,myisam支持表级锁
- Innodb使用的是聚簇索引,myisam使用的是非聚簇索引
- Innodb表文件:.frm,idb,myisam表文件:.frm,.myi,.myd
- 慢查询?Explain分析SQL语句性能?
- 慢查询设置的参数:slow_query_log(开启慢查询),slow_query_time(时间,超过这个时间就被记录),log_queries_not_using_index(查询未使用索引是否记录)
- Explain主要关注的几个参数:selece_type,type,是否命中索引,rows,extra
Type:system>const>ref>range>index>all

悲观锁和乐观锁:乐观锁的CAS和ABA问题以及应用场景?
悲观锁阻塞事务,乐观锁回滚重试
悲观锁:多个事务争抢同一个资源时,加上悲观锁,一个事物争抢到只有等事务提交,否则其他事物处于一个阻塞的状态。
适用于写多读少的场景下
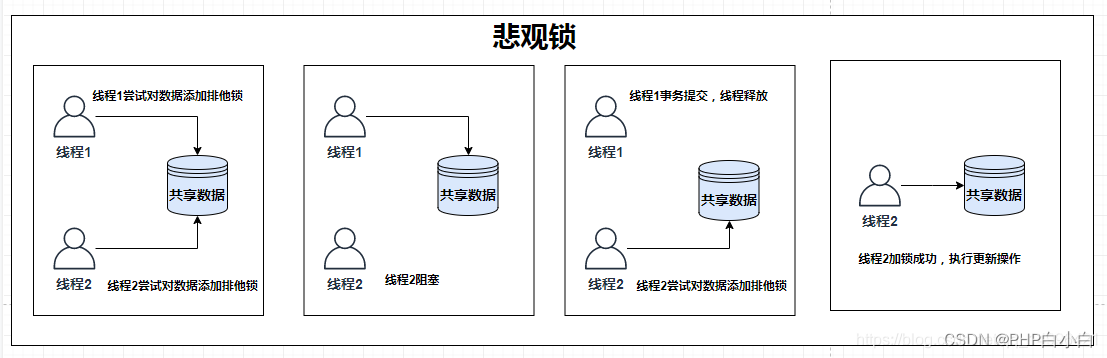
乐观锁:多个事务在读的时候互不影响,如果想要修改数据需要先进行读取,读取玩数据然后根据读取的数据进行修改,然后在提交的时候判断版本号是否一致,一致提交,不一致回滚重试;
适用于读多写少的场景下

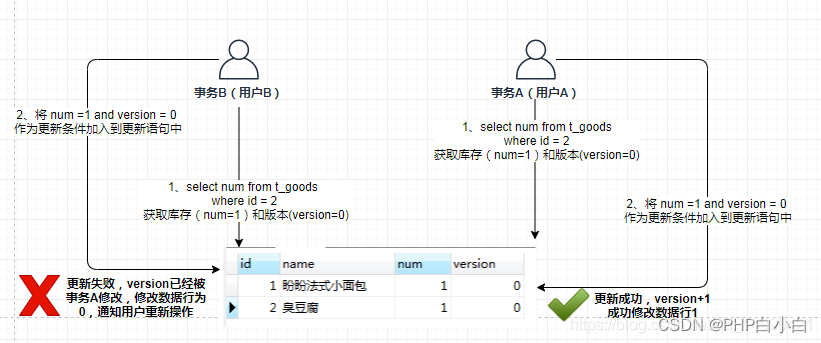
乐观锁的CAS?即比较并替换,在CPU看来是一瞬间的事情
ABA问题?所谓的ABA问题其实也是乐观锁的问题,事务在提交的时候发现和原本的信息一致,这个时候我们认为可以提交,但在提交的过程中有可能数据被更改这就是所谓的ABA问题;解决的方法就是加一个version版本号
- 聚簇索引和非聚簇索引?
Mysql底层使用b+tree当作索引的方式,聚簇索引和非聚簇索引是具体索引的实现;
innodb引擎采用的就是聚簇索引,因为每创建一个表生成的文件可以看出:.frm(表结构),.idb(索引和数据)
myisam引擎采用的是非聚簇索引,因为每创建一个表生成的文件是:.frm,.myi(存储索引),.myd(存储数据)
- 聚簇索引在叶子点存储的索引和数据;
- 非聚簇索引存储的是索引,要想得到具体数据需要先拿到索引,在通过索引取出数据(回表);
- B-tree和B+tree的区别?
b-tree(单向链表):
- 键值分布在叶子和非叶子上;
- 遇到范围查询时,需要每次都要从根节点出发一次一次查找,增加了I/O的内存消耗;
- 查询速度最快是O(1);
B+tree(双向链表):
- 值存储在叶子结点,非叶子结点存储的是键;
- 查询速度相同,都需要在叶子结点上查找;
- 叶子结点同时存储一个指向相邻叶子结点的值,也就是说B+tree天然支持范围查询;
- Mysql的日志?
Mysql日志:二进制日志,回滚日志,普通日志,中继日志,重做日志;
- 分库分表的操作和应用场景?
- 分库分表通常分为:水平拆分和垂直拆分
水平拆分:表(库)结构相同,数据不同,没有交集,并集是全量数据
垂直拆分:表结构不同,数据不同,交集是关联的外键,并集是全量数据
- 拆分的方法:id取模,或者是范围性插入
Id取模会导致后期扩展困难,假设id原本是%5,后续想扩展表的话,需要%8这个时候数据就会出现问题;
范围查询也有一定问题,新插入的数据在新的表中,不会像取模一样均匀的分到每一个表中;
- 什么是死锁?怎么避免?(解决)
- 两个事务争夺同一条资源,并请求锁定对方资源造成相互等待的情况;事务A修改数据id1和2,事务B修改数据id2和1,事务A修改完1等待事务B修改完2才可以提交,而这个时候事务B 也出现了等待事务A这种情况然后就会出现死锁;
- 怎么解决:
- 约定相同的顺序访问表;
- 事务开始的时候争取一次性锁定所有所需的资源;
- 使用乐观锁或者是分布式锁;
- 升级锁粒度;
- MVCC机制?
MVCC全称叫做多版本并发控制,主要是基于Innodb引擎和可重复读以及读已提交的隔离级别实现;
核心逻辑:判断所有未提交事务中哪个事务是当前事务可见处理;
Trx_id:表的隐藏列记载了修改事务的id
Roll_pointer:记录了上个地址的指针
快照:事务执行查询时,生成的未提交事务的列表
根据快照列表进行比对,是否能够读取到事务,如果访问不到根据回滚指针取上一次读取到的地址;
规则:
当前事务id<事务列表的最小事务id,说明在生成快照前就已经提交可以被访问到;
当前事务id>事务列表的最大事务id+1,说明在生成快照后提交的事务访问不到;
当前事务id在事务列表中,判断是否已经提交如果提交了可以被访问,如果没有提交那就访问不到;
注:读已提交的隔离级别下,每次查询的时候都会生成一次快照,
可重复读的隔离级别下,只有第一次查询生成的快照,之后的读取都复用第一次生成的快照
- 主从复制:GTID?半同步模式?主从延迟?

主从复制的工作原理:
对主节点进行的增删改的操作会记录到binlog日志中,然后发送一个dump通知slave结点,
Slave结点去读取binlog日志转储到relay log(中继日志)中,然后slave结点开启一个SQL线程去执行中继日志的文件,达到一个主从复制的效果;
什么是GTID?即全局事务id
Gtid是在mysql5.6版本之后发布的一个重量级特性,与传统的主从复制不同,从库在复制的时候不需要去找master文件,只需要知道事务的id,根据这个id的结点去执行,可以保证每个事务只会被执行一次;
半同步策略:mysql默认是异步策略,半同步是基于同步与异步之间的一种,只需要等待一个slave结点写入到中继日志中就可以返回;
发生主从延迟的原因?
- 网络延迟;
- 数据库负载过高;
- 硬件设施不好;
如何解决主从延迟问题?
- 主从复制串行复制改为并行复制;
- 采用半同步复制策略;
- 提升硬件设施;
(3条消息) MySQL八股文连环45问,你能坚持第几问?_IT邦德的博客-CSDN博客_mysql45问
小白都能懂的Mysql主从复制原理(原理+实操) - 知乎 (zhihu.com)
- 如何避免回表?什么是索引覆盖?
假设查询name值为lisi,需要先定位到主键,在通过主键定位到所在的数据,这就是回表查询;
索引覆盖可以避免回表,索引覆盖指的是查询的字段都设置有索引,如果查询多字段可以设置联合索引
如何避免回表查询?什么是索引覆盖? | 1分钟MySQL优化系列 (qq.com)
- 查询优化器?
- 实际应用场景:大分页?
大分页场景:
比如执行SQL的时候执行了一条select * from users limit 100000,10这样的SQL语句;
为了保证查询的优化情况我们可以进行一个SQL语句的优化,记录上次分页时候的位置,在分页的时候直接从上次分页的位置开始取
Select * from users where id>=100000 limit 10
边栏推荐
- Twikoo腾讯云函数部署转移到私有部署
- 10 款更先进的开源命令行工具
- BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection 论文笔记
- Loudi Sewage Treatment Plant Laboratory Construction Management
- [Advanced Digital IC Verification] Difference and focus analysis between SoC system verification and IP module verification
- 漏洞管理计划的未来趋势
- 燃炸!字节跳动成功上岸,只因刷爆LeetCode算法面试题
- 数字藏品,“赌”字当头
- 友邦人寿可观测体系设计与落地
- Guidelines for Sending Overseas Mail (2)
猜你喜欢

LeetCode中等题之搜索二维矩阵

Open Office XML 格式里如何描述多段具有不同字体设置的段落
What are the five common data types of Redis?What is the corresponding data storage space?Take you to learn from scratch
wirshark 常用操作及 tcp 三次握手过程实例分析

九宫格抽奖动效

Nanodlp v2.2/v3.0 light curing circuit board, connection method of mechanical switch/photoelectric switch/proximity switch and system state level setting

BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection Paper Notes

Redis 定长队列的探索和实践
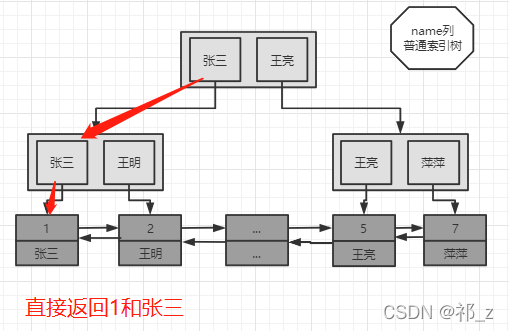
表中存在多个索引问题? - 聚集索引,回表,覆盖索引

Guidelines for Sending Overseas Mail (2)

随机推荐
M²BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation
Ethernet channel 以太信道
AICOCO AI Frontier Promotion (8.10)
C# 当前上下文中不存在InitializeComponent()
想问下大佬们 ,cdc oracle初始化一张300万的表任务运行着后面就这个错 怎么解决哇
[Advanced Digital IC Verification] Difference and focus analysis between SoC system verification and IP module verification
实践为主,理论为辅!腾讯大佬MySQL高阶宝典震撼来袭!
MYSQL误删数据恢复
Solve the idea that unit tests cannot use Scanner
ASP.NET Core依赖注入系统学习教程:ServiceDescriptor(服务注册描述类型)
Codeforces Round #276 (Div. 1) D. Kindergarten
G1和CMS的三色标记法及漏标问题
Educational Codeforces Round 41 (Rated for Div. 2) E. Tufurama
娄底妆品实验室建设规划构思
协程与任务
The basic components of Loudi plant cell laboratory construction
bgp dual plane experiment routing strategy to control traffic
kubernetes介绍
商汤自研机械臂,首款产品是AI下棋机器人:还请郭晶晶作代言
大佬们有遇到过这个问题吗? MySQL 2.2 和 2.3-SNAPSHOT 都这样,貌似是