当前位置:网站首页>BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection Paper Notes
BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection Paper Notes
2022-08-10 13:07:00 【byzy】
原文链接:https://arxiv.org/pdf/2203.17054.pdf
1.引言
The current visual detection methods have large errors in the estimation of speed,Therefore, this paper introduces time information to improve the accuracy.
BEVDet4DBy keeping the middle of past framesBEVfeatures to expandBEVDet,The features are then fused by aligning and stitching with the current frame,Thus, temporal clues can be obtained by querying the two candidate features,Rather, only a negligible computational increase is required.BEVDet4D的其余部分与BEVDet相同.
2.相关工作
2.2 视频目标检测
Current methods mainly use temporal cues at both outcomes or intermediate features.The former uses post-processing methods,Optimize detection results in a tracking manner;后者利用LSTM、Attention or optical flow repurposes image features from past frames.
3.方法
3.1 网络结构
如下图所示,BEVDet4D仍包含BEVDet的4个基本结构.此外,Considering that the output features of the view transformer are sparse,增加了额外的BEV编码器(It consists of two residual units).

3.2 Simplify speed learning tasks
Predict the translation of the target between adjacent frames instead of directly predicting the speed,In this way, the task is transformed into predicting the displacement of the target in two adjacent frames,这可根据BEVThe difference in feature maps is measured.
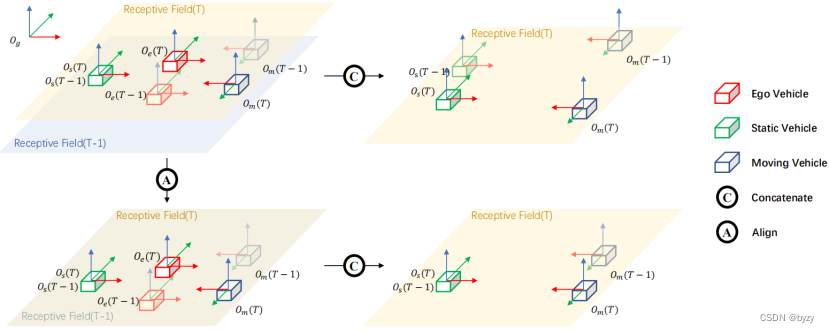
Let the coordinates of an object in two adjacent frames in the global coordinate system be  和
和 ,It is due to the movement of the vehicle,Directly concatenate feature maps(As shown in the upper right subgraph of the above figure)The resulting position difference is
,It is due to the movement of the vehicle,Directly concatenate feature maps(As shown in the upper right subgraph of the above figure)The resulting position difference is

其中上标 表示
表示 The ego vehicle coordinate system at time,non-superscripted
The ego vehicle coordinate system at time,non-superscripted 表示时刻的物体;
表示时刻的物体;Represents the transformation from the source coordinate system to the destination coordinate system.可见,If the two feature maps are directly spliced,It will cause the target shift to be related to the ego-vehicle motion.
If used firstto move the previous frame to the vehicle coordinate system of the current frame and then splicing(As shown in the lower right subgraph of the above figure),Then the target position difference is

At this time, the position difference of the target is equal to the actual target displacement.
In fact, the above formula is realized by feature alignment,即若 表示The feature map at time in the ego vehicle coordinate system,Then the aligned features are :
表示The feature map at time in the ego vehicle coordinate system,Then the aligned features are :

This article uses bilinear interpolation from  中获取特征,But this method is suboptimal,会导致性能下降,And the degree of decline and BEVFeature resolution inverse correlation.A more precise approach is to adjust the point cloud coordinates generated by the lift operation in the view transformer,But doing so will breakBEVDetA prerequisite for the acceleration method used in (见BEVDet 4.3节最后).
中获取特征,But this method is suboptimal,会导致性能下降,And the degree of decline and BEVFeature resolution inverse correlation.A more precise approach is to adjust the point cloud coordinates generated by the lift operation in the view transformer,But doing so will breakBEVDetA prerequisite for the acceleration method used in (见BEVDet 4.3节最后).
4.实验
Data augmentation methods and BEVDet相同.
4.2 结果
在nuScenes验证集上,BEVDet4D的高速版本BEVDet4D-Tiny就超过了BEVDet的性能,Mainly in the direction、Estimates of speed and properties,Even the estimation accuracy of velocity exceeds that of methods based on fusion of camera and radarCenterFusion.总的来说,BEVDet4DLarge performance gains come at the cost of negligible extra inference time.
在nuScenes测试集上,BEVDet4DExceeds some methods that require additional data for training;此外,The performance difference between validation and test sets shows,Introducing temporal cues can improve the generalization performance of the model.
4.3 消融研究
4.3.1 建立BEVDet4D的过程
在BEVDet的基础上,First, the adjacent frames are directly splicedBEV特征图.This action can cause performance degradation,Especially on position and velocity estimation.This may be because the displacement of the object caused by the movement of the ego vehicle will confuse the subsequent module's judgment of the position of the object,And the judgment of the speed needs to find the actual displacement that is not related to the movement of the ego vehicle from the position difference of the object.
After adding the alignment operation,Both position and velocity errors are reduced,And the position error is less than BEVDet,But the speed error is still greater than BEVDet.This may be due to the inconsistency of adjacent frame times resulting in different object position distributions and velocity distributions.
Changed from predicting velocity directly to predicting offset,Speed prediction task is simplified、Greatly improves the speed estimation accuracy,And make the training results more robust.
Use extra before splicingBEVEncoders can trade further performance gains at very little computational cost.
In addition, tuning the speed weights in the loss function can also improve performance.
4.3.3 The location of the time fusion
If in extraBEVTemporal fusion is performed before the encoder,performance compared to the extraBEVTemporal fusion before the encoder will drop,This shows that the output features of the view transformer are relatively coarse,不适合直接使用.如果在原来的BEVTemporal fusion is performed after the encoder,Then performance and BEVDet几乎相同(Among them, the speed accuracy is slightly improved,But the positional accuracy drops slightly).这说明BEVThe encoder is resistant to position misleading from past frames,and estimate the velocity from the position offset.
边栏推荐
- 专有云ABC Stack,真正的实力派!
- LeetCode中等题之搜索二维矩阵
- Loudi Sewage Treatment Plant Laboratory Construction Management
- 「企业架构」应用架构概述
- 基础 | batchnorm原理及代码详解
- How to do foreign media publicity to grasp the key points
- ArcMAP出现-15的问题无法访问[Provide your license server administrator with the following information:Err-15]
- 把相亲角搬到海外,不愧是咱爸妈
- 表中存在多个索引问题? - 聚集索引,回表,覆盖索引
- Inventory of Loudi Agricultural Products Inspection Laboratory Construction Guidelines
猜你喜欢

【论文+代码】PEBAL/Pixel-wise Energy-biased Abstention Learning for Anomaly Segmentation on Complex Urban Driving Scenes(复杂城市驾驶场景异常分割的像素级能量偏置弃权学习)

想通这点,治好 AI 打工人的精神内耗

Jenkins修改端口号, jenkins容器修改默认端口号

StarRocks on AWS 回顾 | Data Everywhere 系列活动深圳站圆满结束

Guidelines for Sending Overseas Mail (2)

解决 idea 单元测试不能使用Scanner

郭晶晶家的象棋私教,好家伙是个机器人

G1和CMS的三色标记法及漏标问题
Guo Jingjing's personal chess teaching, the good guy is a robot

mSystems | 中农汪杰组揭示影响土壤“塑料际”微生物群落的机制
随机推荐
瑞幸「翻身」?恐言之尚早
表中存在多个索引问题? - 聚集索引,回表,覆盖索引
CURRENT_TIMESTAMP(6) 函数是否存在问题?
Nanodlp v2.2/v3.0光固化电路板,机械开关/光电开关/接近开关的接法和系统状态电平设置
爱可可AI前沿推介(8.10)
48 the mysql database
Is there a problem with the CURRENT_TIMESTAMP(6) function?
odps sql 不支持 unsupported feature CREATE TEMPORARY
Shell:数组
教育Codeforces轮41(额定Div。2)大肠Tufurama
Mysql—— 内连接、左连接、右连接以及全连接查询
「网络架构」网络代理第一部分: 代理概述
广东10个项目入选工信部2021年物联网示范项目名单
漏洞管理计划的未来趋势
漏洞管理计划的未来趋势
ASP.NET Core依赖注入系统学习教程:ServiceDescriptor(服务注册描述类型)
MySQL相关问题整理
Blast!ByteDance successfully landed, only because the interview questions of LeetCode algorithm were exhausted
Nanodlp v2.2/v3.0 light curing circuit board, connection method of mechanical switch/photoelectric switch/proximity switch and system state level setting
How to do foreign media publicity to grasp the key points