LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:专家语言模型的异步并行训练、基于检索增强语言模型的少样本学习、保形风险控制、大型语言模型中的概念与意义、基于模块化方法的语言指令遵循、不断学习提升技能与安全的开放部署对话智能体、语言轨迹Transformer、基于人工反馈改进开放域互联网驱动对话、多标签分类新损失
1、[CL] Branch-Train-Merge: Embarrassingly Parallel Training of Expert Language Models
M Li, S Gururangan, T Dettmers, M Lewis, T Althoff, N A. Smith, L Zettlemoyer
[University of Washington]
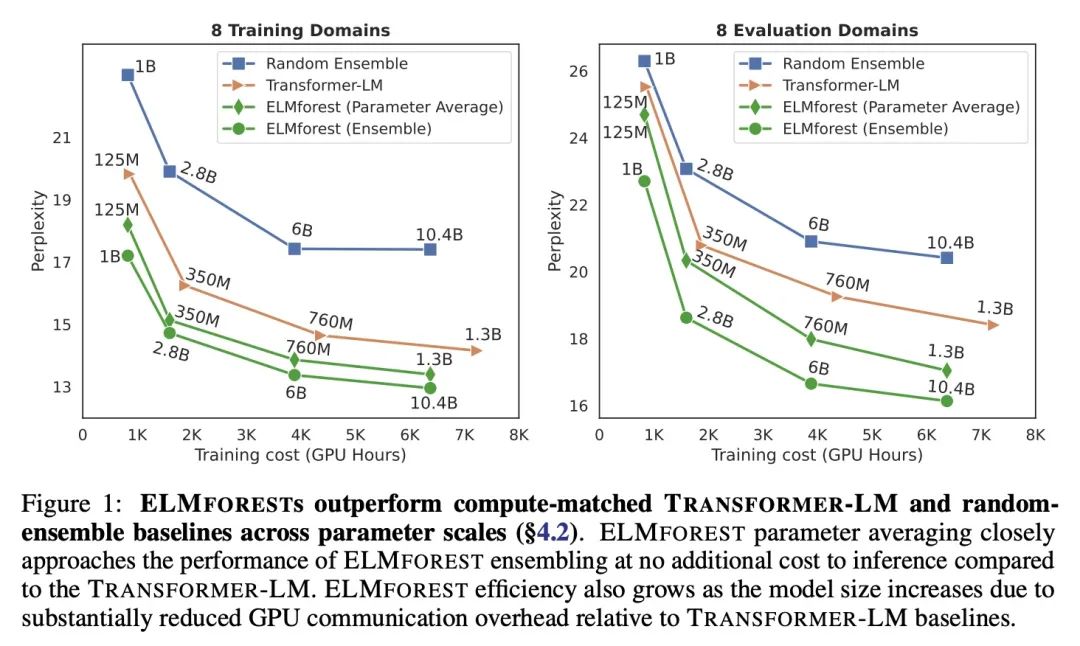
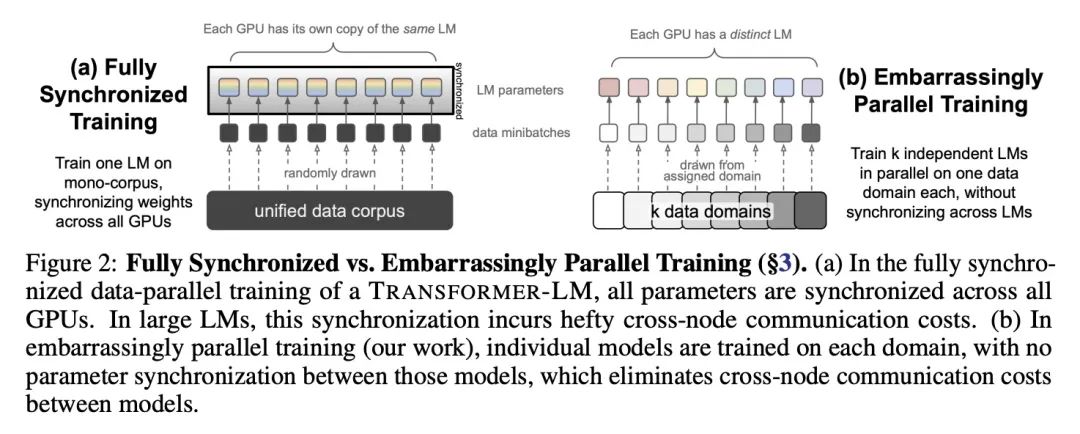
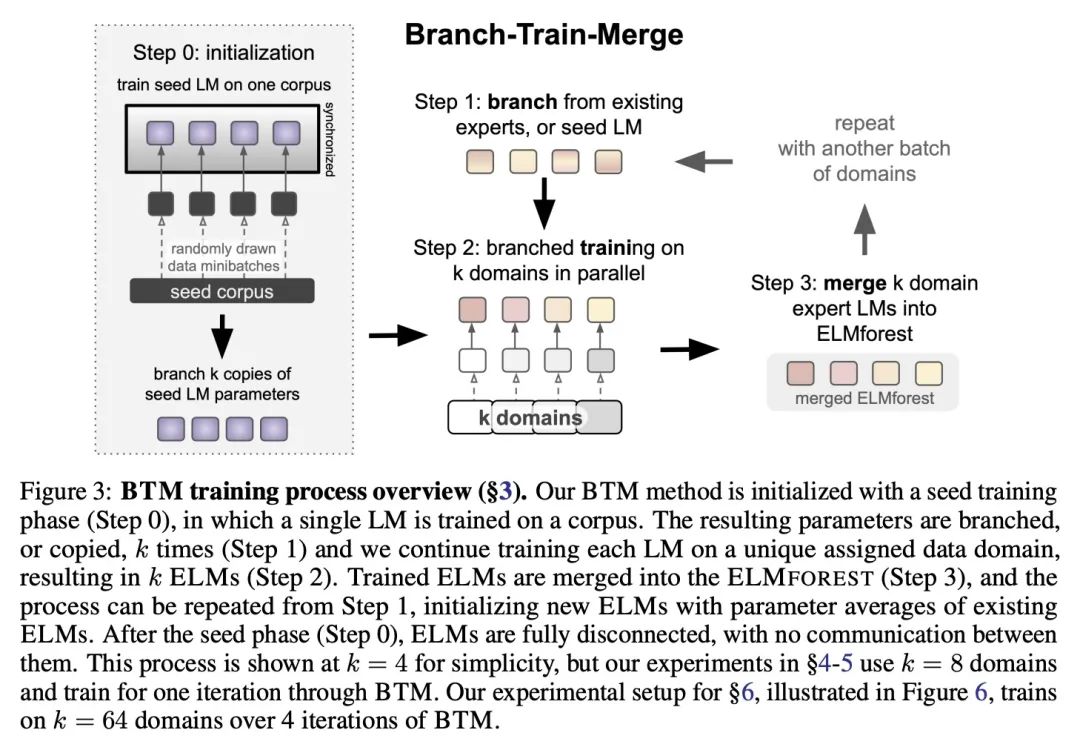
分支-训练-合并:专家语言模型的异步并行训练。本文提出Branch-Train-Merge(BTM),一种高通信效率的算法,用于对大型语言模型(LLM)进行异步并行训练,有可能在不同数据子集上独立训练一类新的语言模型的子部分,从而消除目前训练语言模型所需的大规模多节点同步。BTM学习一组独立的EXPERT LM(ELM),每个都专门用于不同的文本域,如科学或法律文本。这些ELM可以被添加和删除以更新数据覆盖率,可以组合以推广到新的域,也可以被平均化以缩减到一个单一LM以实现高效推理。新的ELM是通过从当前集合中的ELM(混合)分支学习的,在新域数据上进一步训练参数,然后将得到的模型合并到集合中供将来使用。实验表明,在控制训练成本的情况下,BTM与GPT式Transformer的LM相比,提高了域内和域外的困惑度。广泛的分析表明,这些结果对不同的ELM初始化方案是鲁棒的,但需要专家领域的特定化;具有随机数据分割的LM集合表现不佳。本文还提出一项关于将BTM扩展到64个域的新语料库中的研究(总共192B个空格分隔Token);由此产生的LM(总参数22.4B)的表现与用2.5倍的计算量训练的Transformer LM一样好。这些收益随着域数量的增加而增加,这表明在未来的工作中可以用更积极的并行性来有效地训练更大的模型。
We present Branch-Train-Merge (BTM), a communication-efficient algorithm for embarrassingly parallel training of large language models (LLMs). We show it is possible to independently train subparts of a new class of LLMs on different subsets of the data, eliminating the massive multi-node synchronization currently required to train LLMs. BTM learns a set of independent EXPERT LMs (ELMs), each specialized to a different textual domain, such as scientific or legal text. These ELMs can be added and removed to update data coverage, ensembled to generalize to new domains, or averaged to collapse back to a single LM for efficient inference. New ELMs are learned by branching from (mixtures of) ELMs in the current set, further training the parameters on data for the new domain, and then merging the resulting model back into the set for future use. Experiments show that BTM improves inand out-of-domain perplexities as compared to GPT-style Transformer LMs, when controlling for training cost. Through extensive analysis, we show that these results are robust to different ELM initialization schemes, but require expert domain specialization; LM ensembles with random data splits do not perform well. We also present a study of scaling BTM into a new corpus of 64 domains (192B whitespace-separated tokens in total); the resulting LM (22.4B total parameters) performs as well as a Transformer LM trained with 2.5× more compute. These gains grow with the number of domains, suggesting more aggressive parallelism could be used to efficiently train larger models in future work.
https://arxiv.org/abs/2208.03306

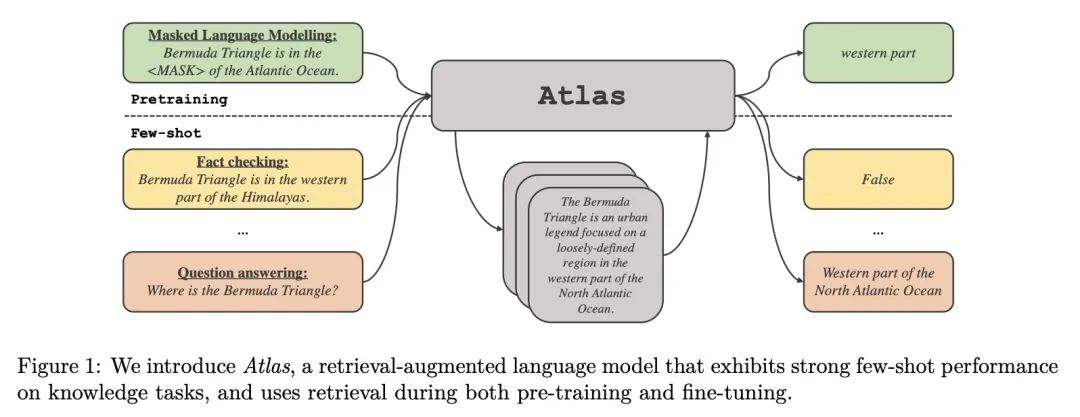
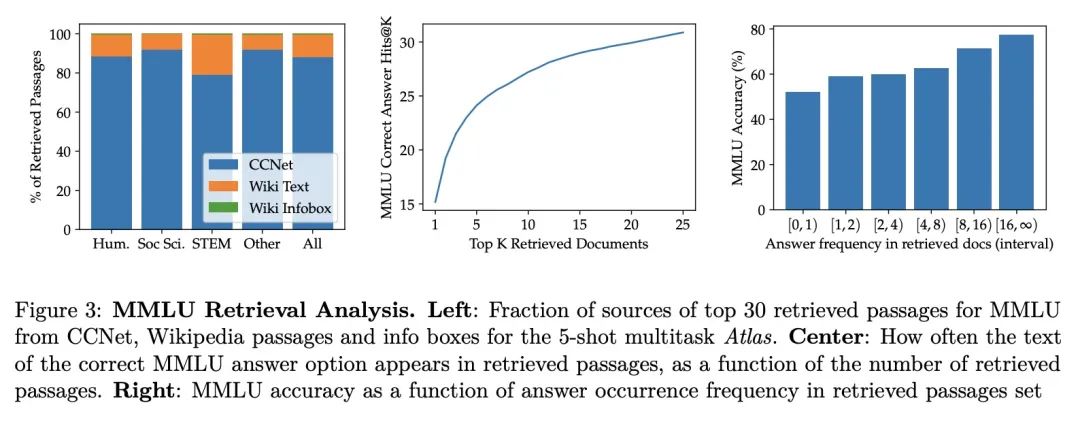
2、[CL] Few-shot Learning with Retrieval Augmented Language Model
G Izacard, P Lewis, M Lomeli, L Hosseini, F Petroni, T Schick, J Yu, A Joulin, S Riedel, E Grave
[Meta AI Research]
基于检索增强语言模型的少样本学习。大型语言模型在广泛的任务中显示出令人印象深刻的少样本结果。然而,当知识是这种结果的关键时,如问答和事实核查等任务,似乎需要大量参数来存储知识。众所周知,检索增强模型在知识密集型任务中表现出色,不需要那么多参数,但目前还不清楚它们在少样本情况下是否有效。本文提出Atlas,一种精心设计和预训练的检索增强语言模型,能用很少的训练样本学习知识密集型任务。本文对广泛的任务进行了评估,包括MMLU、KILT和NaturalQuestions,并研究了文档索引内容的影响,表明它可以很容易地更新。值得注意的是,Atlas只用了64个样本就达到了42%以上的精度,尽管参数少了50倍,却比540B参数模型的精度高出了3%。
Large language models have shown impressive few-shot results on a wide range of tasks. However, when knowledge is key for such results, as is the case for tasks such as question answering and fact checking, massive parameter counts to store knowledge seem to be needed. Retrieval augmented models are known to excel at knowledge intensive tasks without the need for as many parameters, but it is unclear whether they work in few-shot settings. In this work we present Atlas, a carefully designed and pre-trained retrieval augmented language model able to learn knowledge intensive tasks with very few training examples. We perform evaluations on a wide range of tasks, including MMLU, KILT and NaturalQuestions, and study the impact of the content of the document index, showing that it can easily be updated. Notably, Atlas reaches over 42% accuracy on Natural Questions using only 64 examples, outperforming a 540B parameters model by 3% despite having 50x fewer parameters.
https://arxiv.org/abs/2208.03299

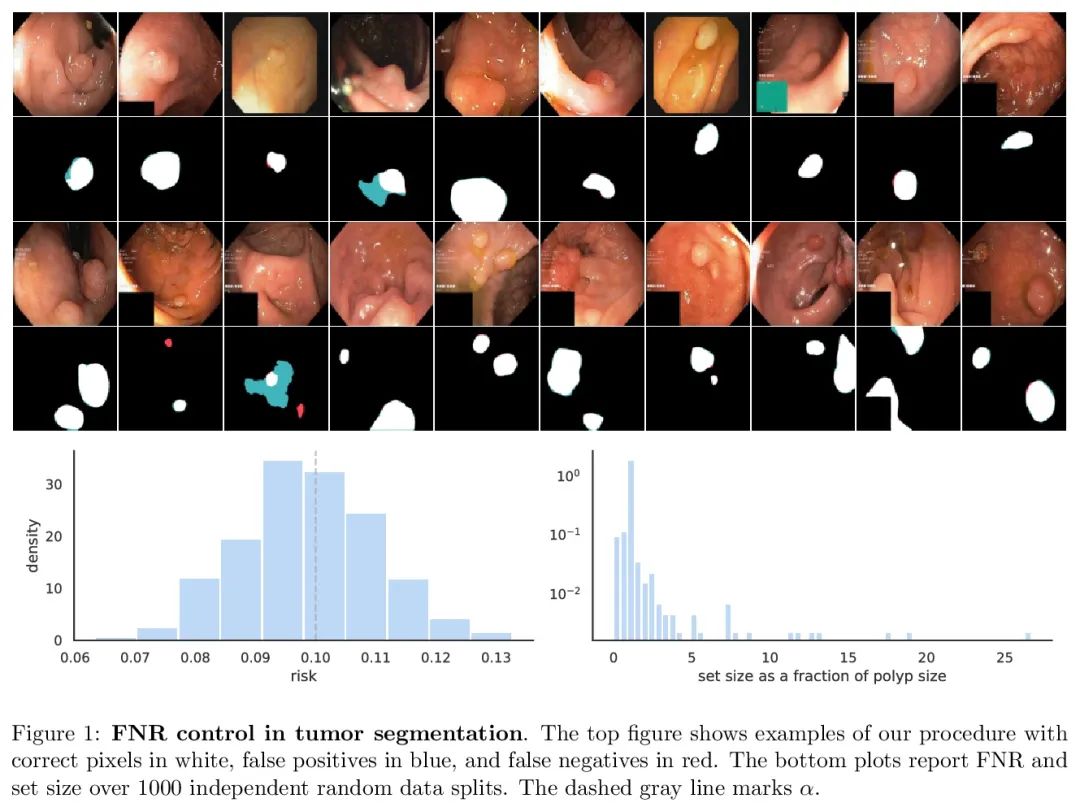
3、[LG] Conformal Risk Control
A N. Angelopoulos, S Bates, A Fisch, L Lei, T Schuster
[UC Berkeley & MIT & Stanford University & Google Research]
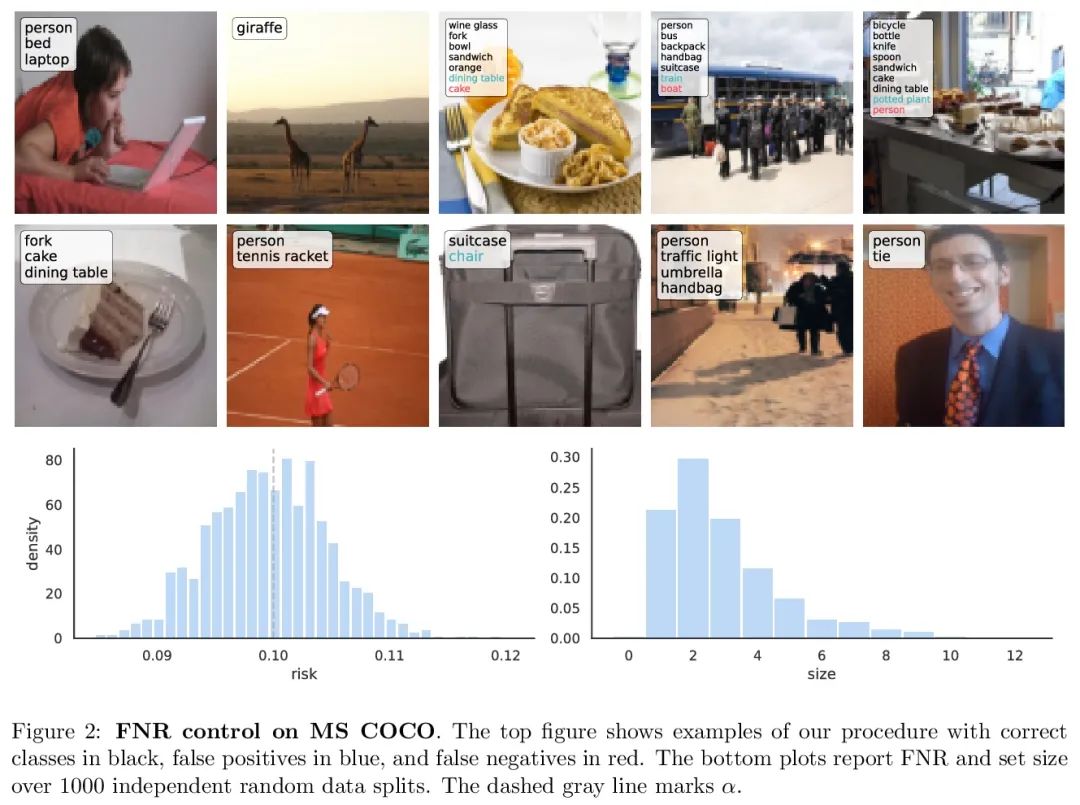
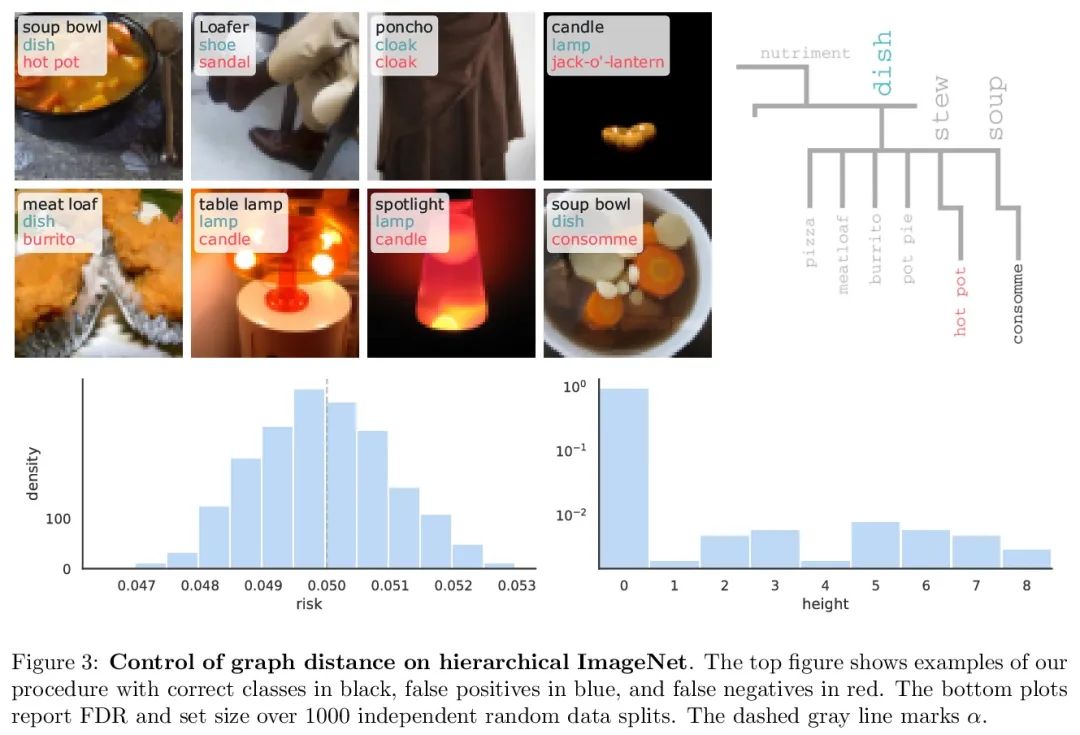
保形风险控制。本文将保形预测扩展到任意单调损失函数预期值的控制。该算法推广了分裂保形预测及其覆盖保证。与保形预测一样,保形风险控制程序的严密性达到了O(1/n)级。来自计算机视觉和自然语言处理的工作实例证明了所提出算法可广泛用于约束假阴性率、图距离和token级F1分数。
We extend conformal prediction to control the expected value of any monotone loss function. The algorithm generalizes split conformal prediction together with its coverage guarantee. Like conformal prediction, the conformal risk control procedure is tight up to an O(1/n) factor. Worked examples from computer vision and natural language processing demonstrate the usage of our algorithm to bound the false negative rate, graph distance, and token-level F1-score.
https://arxiv.org/abs/2208.02814

4、[CL] Meaning without reference in large language models
S T. Piantasodi, F Hill
[UC Berkeley & DeepMind]
大型语言模型中的概念与意义。大型语言模型(LLM)的广泛成功遭到了质疑,认为它们没有类似人类的概念或意义。与认为LLM不具备任何意义的说法相反,本文认为它们很可能捕捉到了意义的重要方面,其工作方式接近于人类认知的一种令人信服的说法,即意义产生于概念模型。因为概念模型是由内部表示状态间的关系定义的,所以意义不能从模型的结构、训练数据或目标函数中确定,而只能通过检查其内部状态如何相互关联来确定。这种方法可能会澄清LLM为什么和如何如此成功,并建议如何使它们更像人类。
The widespread success of large language models (LLMs) has been met with skepticism that they possess anything like human concepts or meanings. Contrary to claims that LLMs possess no meaning whatsoever, we argue that they likely capture important aspects of meaning, and moreover work in a way that approximates a compelling account of human cognition in which meaning arises from conceptual role. Because conceptual role is defined by the relationships between internal representational states, meaning cannot be determined from a model’s architecture, training data, or objective function, but only by examination of how its internal states relate to each other. This approach may clarify why and how LLMs are so successful and suggest how they can be made more human-like.
https://arxiv.org/abs/2208.02957

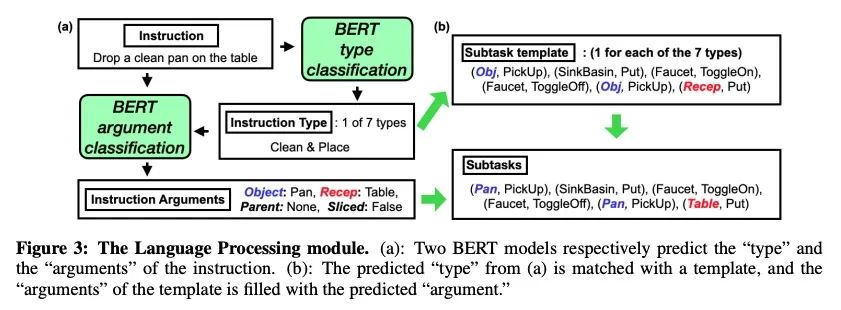
5、[CL] FILM: Following Instructions in Language with Modular Methods
S Y Min, D S Chaplot, P Ravikumar, Y Bisk, R Salakhutdinov
[CMU & Facebook AI Research]
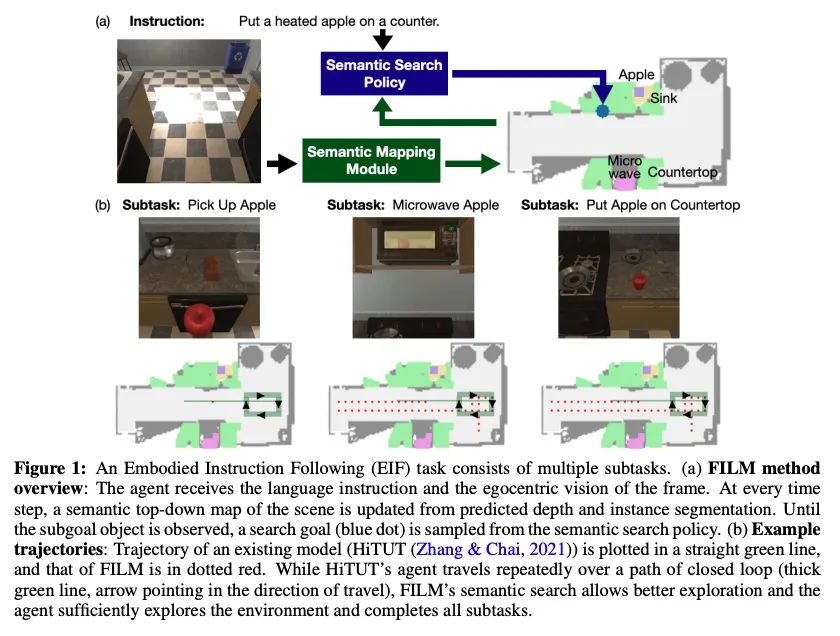
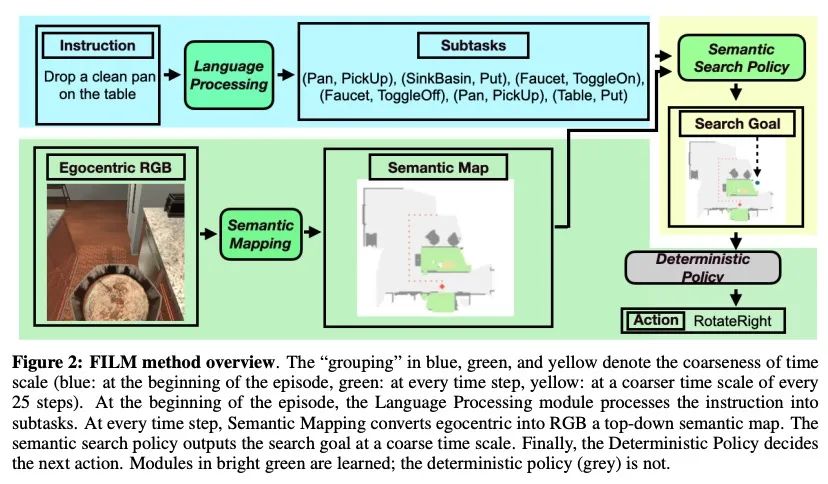
FILM:基于模块化方法的语言指令遵循。最近用于具身指令遵循的方法通常是用模仿学习进行端到端训练。这往往需要使用专家轨迹和低级语言指令,这些方法假设神经状态将整合多模态语义来进行状态跟踪,建立空间记忆,探索和长程规划。相比之下,本文提出一种具有结构化表示的模块化方法,(1) 建立场景语义图,(2) 用语义搜索策略进行探索,以实现自然语言目标。所提出的模块化方法实现了SOTA性能(24.46%),与之前工作相比有很大差距(绝对值提升8.17%),同时通过放弃专家轨迹和低级指令,使用更少的数据。然而,利用低级语言可以进一步提高所提出方法的性能(26.49%)。研究结果表明,即使在没有专家轨迹或低级指令的情况下,明确的空间记忆和语义搜索策略可以为状态跟踪与指导提供更强大和更通用的表示。
Recent methods for embodied instruction following are typically trained end-to-end using imitation learning. This often requires the use of expert trajectories and low-level language instructions. Such approaches assume that neural states will integrate multimodal semantics to perform state tracking, building spatial memory, exploration, and long-term planning. In contrast, we propose a modular method with structured representations that (1) builds a semantic map of the scene and (2) performs exploration with a semantic search policy, to achieve the natural language goal. Our modular method achieves SOTA performance (24.46 %) with a substantial (8.17 % absolute) gap from previous work while using less data by eschewing both expert trajectories and low-level instructions. Leveraging low-level language, however, can further increase our performance (26.49 %). Our findings suggest that an explicit spatial memory and a semantic search policy can provide a stronger and more general representation for state-tracking and guidance, even in the absence of expert trajectories or low-level instructions.
https://arxiv.org/abs/2110.07342

另外几篇值得关注的论文:
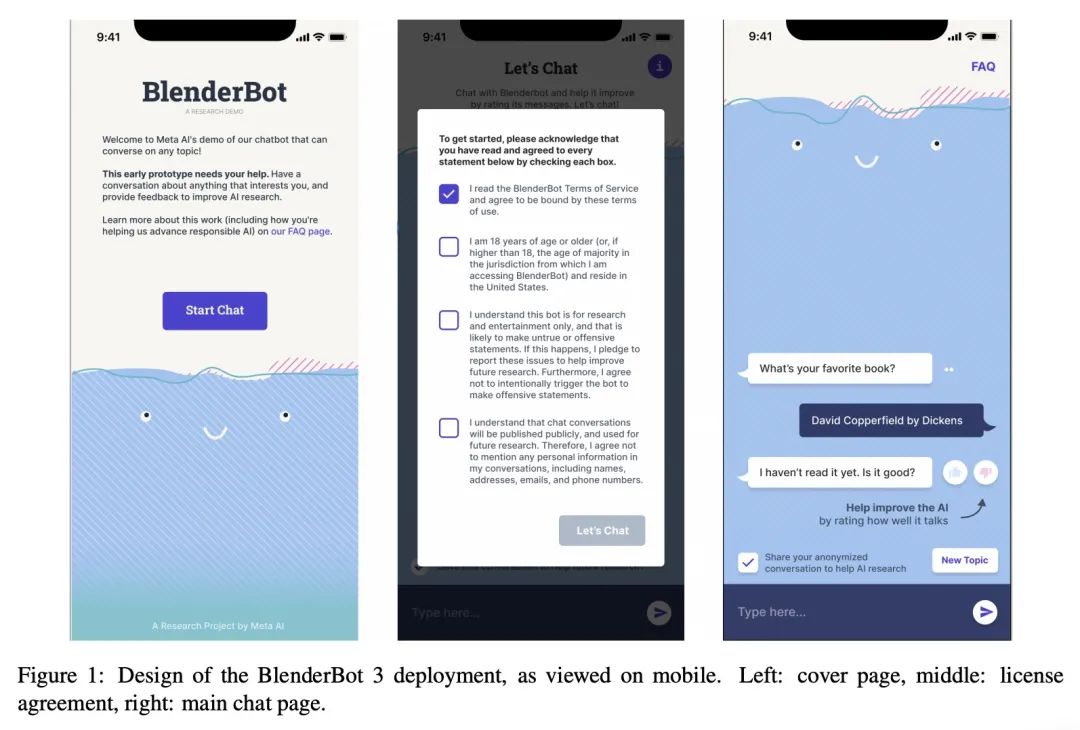
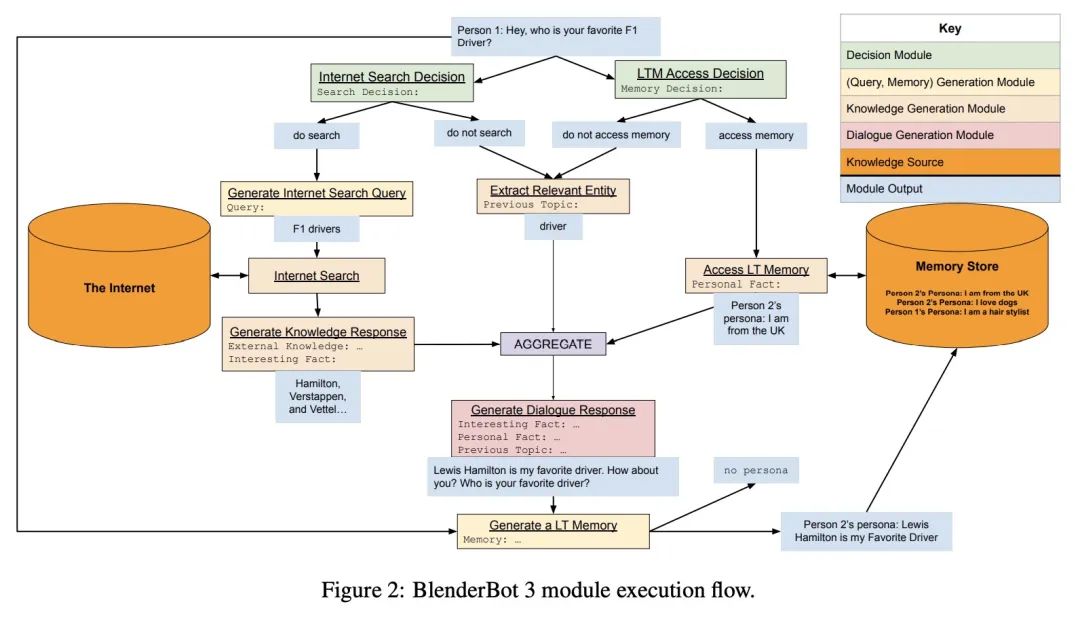
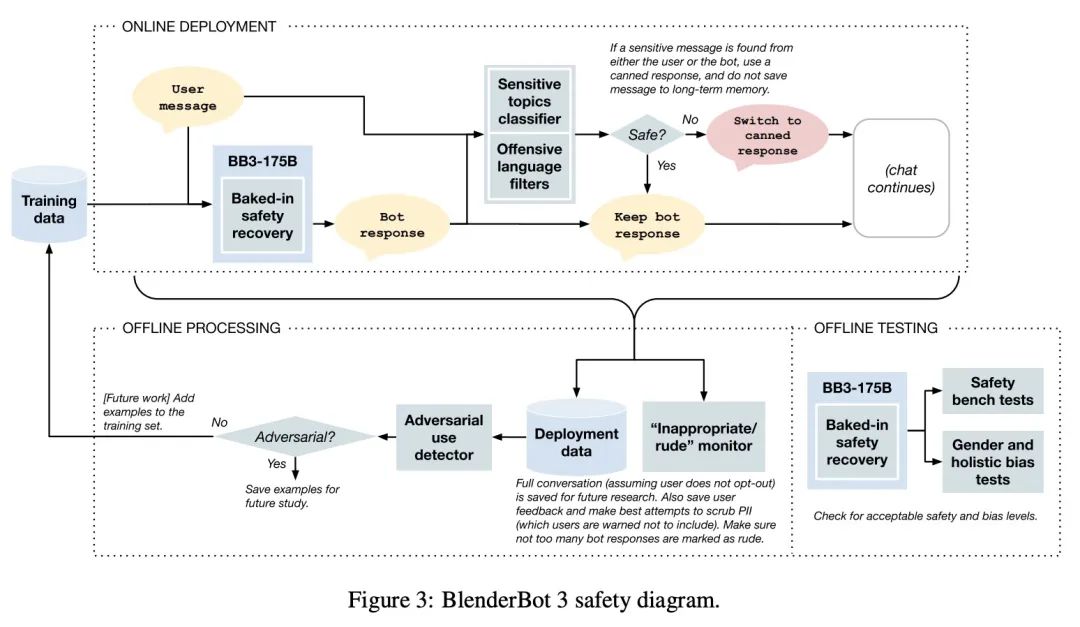
[CL] BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
BlenderBot 3:不断学习提升技能与安全的开放部署对话智能体
K Shuster, J Xu, M Komeili, D Ju, E M Smith, S Roller, M Ung, M Chen…
[Meta AI & Mila / McGill University]
https://arxiv.org/abs/2208.03188

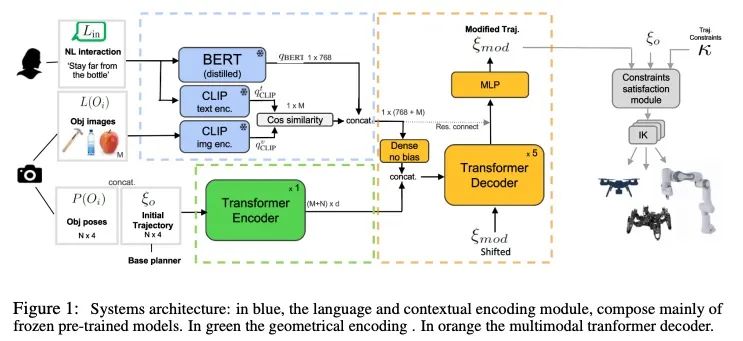
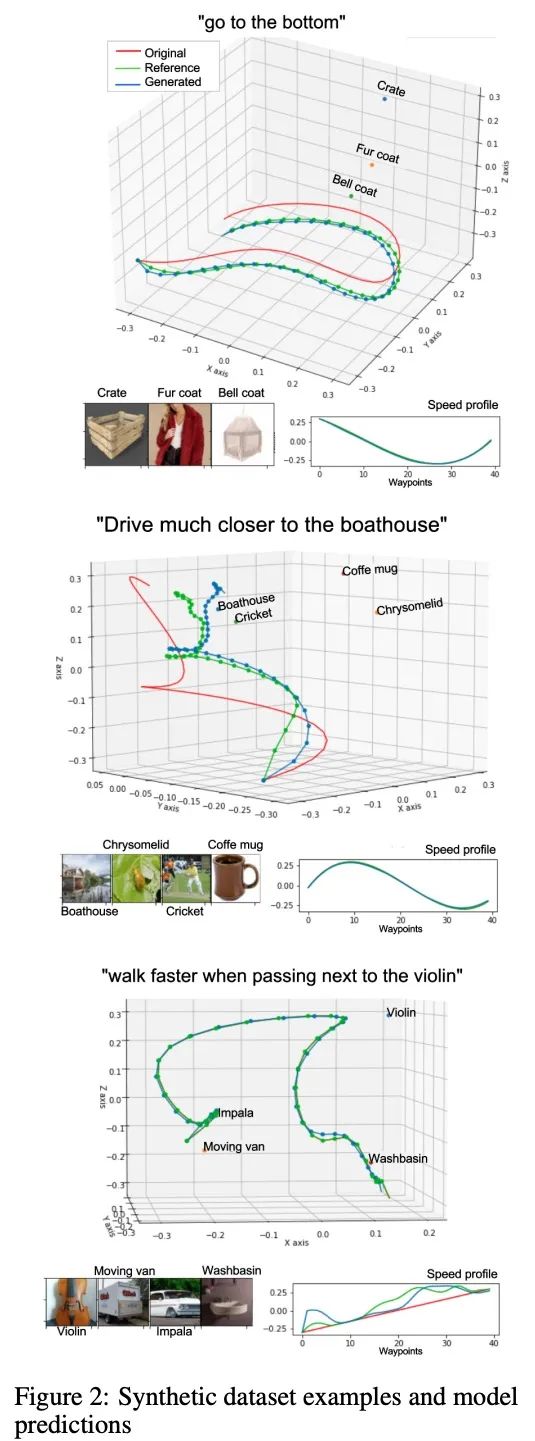
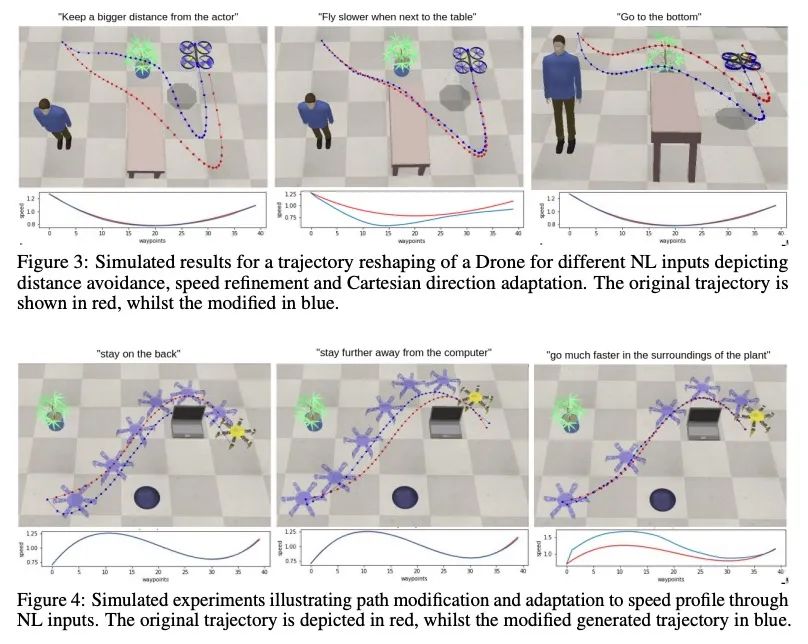
[RO] LaTTe: Language Trajectory TransformEr
LaTTe:语言轨迹Transformer
A Bucker, L Figueredo, S Haddadin, A Kapoor, S Ma, R Bonatti
[Technische Universitat Munchen & Microsoft Corporation]
https://arxiv.org/abs/2208.02918
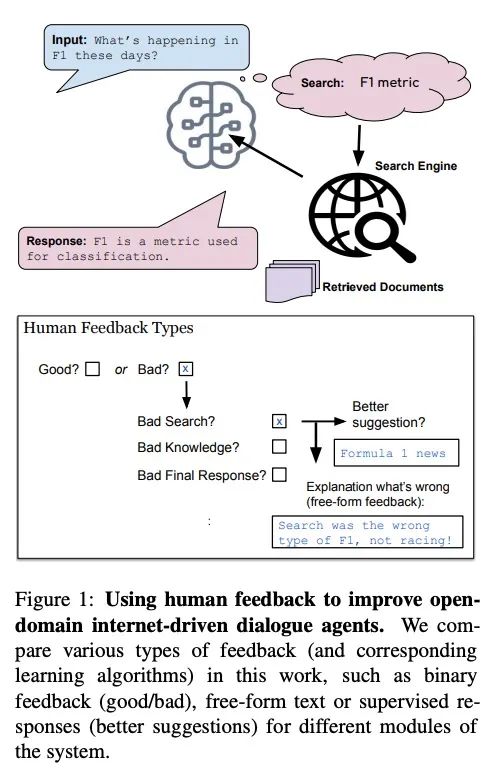
[CL] Learning New Skills after Deployment: Improving open-domain internet-driven dialogue with human feedback
部署后新技能学习:基于人工反馈改进开放域互联网驱动对话
J Xu, M Ung, M Komeili, K Arora, Y Boureau, J Weston
[Meta AI]
https://arxiv.org/abs/2208.03270

[LG] ZLPR: A Novel Loss for Multi-label Classification
ZLPR:多标签分类新损失
J Su, M Zhu, A Murtadha, S Pan, B Wen, Y Liu
[Zhuiyi Technology Co.]
https://arxiv.org/abs/2208.02955