当前位置:网站首页>Detailed description of MySQL index [B + tree index, hash index, full-text index, overlay index]
Detailed description of MySQL index [B + tree index, hash index, full-text index, overlay index]
2022-04-23 03:18:00 【Xiaodaoxian 97】
Some time ago, every time the interview mentioned the index , I'll just say a bunch of , Then it's time to talk about what you understand B+tree Indexes I'm so confused .
Direct said B+tree It may not be well understood , Let's start with the simplest binary search tree and gradually .
One 、B+Tree Indexes
1、 Binary search tree
When I first learned about trees , We must have learned a binary tree with such a structure The root node is larger than its left node , Smaller than its right node .

If we want to query in the above binary tree 6 , Just three steps
- Find the root node
10, Judge 6 Than 10 Small , Left seeking node - Find the node
5, Judge 6 Than 5 Big , Find the right node - Find the node
6, Judge 6 Meet the search needs
2、 Balanced binary trees (AVL Trees )
Those familiar with binary trees know , In special circumstances , The above binary tree may form the following structure

If you query nodes on this binary tree , That is to compare them one by one , Quite inefficient , At this time, we will introduce Balanced binary trees The concept of .
Balanced binary tree has the following requirements :
- The left node of each root node is smaller than it , The right node is larger than it
- The height difference between the left and right subtrees of each node cannot exceed
1
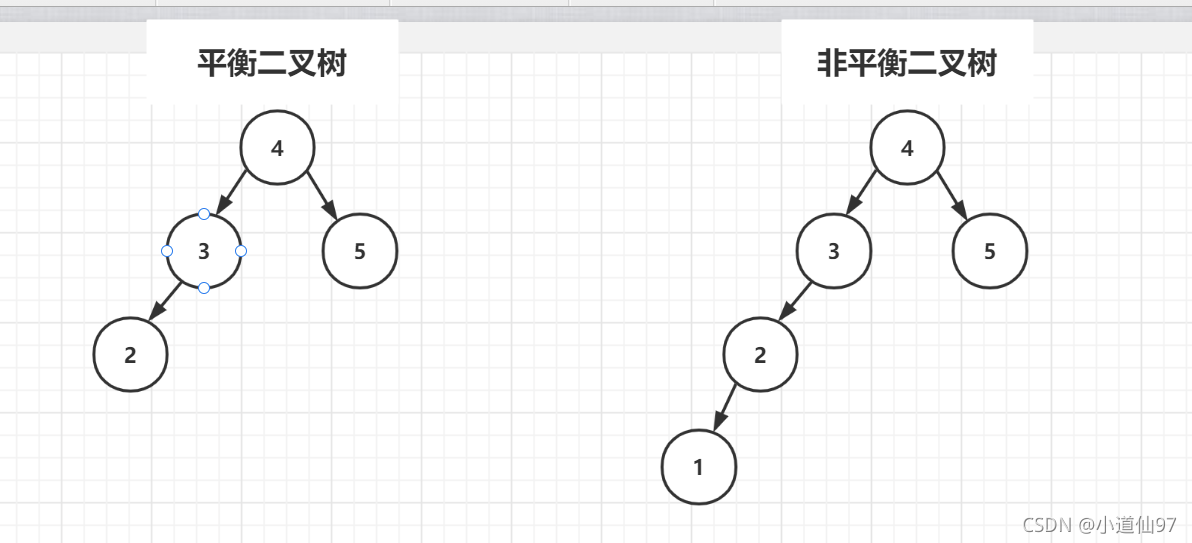
Every time you add elements , The code will judge whether the current structure is still balanced , If not, adjust . The cost of adjustment is also very high , Therefore, balanced binary tree is generally used in multi query function .
3、B-Tree
All our data is ultimately stored on disk . There is a problem with balanced binary trees , That is, if the amount of data is too large , Then the tree will be very long , This can lead to frequent disk IO, In this way, the efficiency is reduced a lot .
In the database, data is not stored one by one , Instead, store by page , One page is 16kb size .
B-Tree Can solve frequent IO problem , It stores data according to pages .
If we have such a table , There are two fields id、name,id It's the primary key
Then its storage structure is as follows :

Pages also point in both directions
From the above structure, we can see , each page It stores indexes and corresponding data , And there are multiple pieces of data , Not a single one .
Usually our root page ( page 1) It's stored in memory , Then we judge whether to read pages into memory one by one , Using this structure, you can query fewer pages , Then we can query the data we want .
4、B+Tree
There is also a problem with the above structure , Because the size of each page is fixed (16KB), If you want to store both indexes , And store data , Then we 16KB It doesn't store much index data ( Especially in big tables ), This will still happen frequently IO Handle .
If we only store the index in the node , Store data in the leaf node , In this way, we can store more indexes on each page .

4-1、 Accurate search
If we want to check 1, Find the page first 1, Find another page 2, Finally, find the corresponding data from the leaf node .
4-2、 Range queries
If we want to find WHERE id > 2 AND id < 5
As above, we will find out exactly 2, Leaf nodes have bidirectional pointers up, down, left and right , Go down one by one , When looking for a fight 5 Found that id < 5 It's not enough , Just finish searching .
5、 summary
- B+Tree Store all the data on the leaf node , Non leaf nodes only store indexes , This ensures a minimum number of IO Improve the performance of index query .
- The storage time is not a node by node , Instead, it is stored as a page , The size of each page is 16KB.
Two 、Hash Indexes
Hash An index is based on a given field , Create Hash value .Hash The index can quickly query a single matching degree , But you can't do range query .
If you create a composite index (A、B), It is based on AB Two fields for Hash Of , So when you use it alone A When performing conditional screening , You can't use indexes .
3、 ... and 、 Full-text index
Full text index is a special index , Generally, it is rarely used . It looks for keywords in the text , Instead of comparing the values in the index . Full text indexing is more similar to what search engines do .
Four 、 Clustered index and non clustered index
Cluster index is not a separate index type , It's a way of storing data . stay InnoDB The cluster index of is actually stored in the same structure B+Tree Index and data rows . When a table has a clustered index , Its data rows are actually stored in the leaf pages of the index .
Because you can't put rows in two different places at the same time , So a table can only have one clustered index .( however , Overlay index can simulate the situation of multiple clustered indexes , The following instructions )
stay InnoDB The primary key will be selected as the cluster index , If there is no primary key defined ,InnoDB Will choose a unique non empty index instead of . If there is no such index ,InnoDB A primary key is implicitly defined as a clustered index .
Cluster index : Its non leaf nodes store , primary key ( Most of them are ), Leaf nodes are stored row data .
Nonclustered index : Its non leaf nodes store , Index value , The leaf node stores the primary key index corresponding to this index .
So when we use non clustered index to query data , It will be queried twice, and the cluster index will be queried first , Then find the relevant data through the cluster index , This process is called Back to the table .
5、 ... and 、 Other
5-1、 Why is the primary key index faster than other indexes
Because the non primary key index corresponds to the non clustered index , Therefore, you need to perform the operation of returning to the table when querying , First find the corresponding primary key index in the query , Then query the real data through the primary key index .
But not all primary key indexes are faster than other indexes , For example, we will talk about the overlay index .
5-2、 Overlay index
Suppose we have such a table
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT ' Primary key id',
`name` varchar(50) DEFAULT NULL COMMENT ' full name ',
`age` int(3) DEFAULT NULL COMMENT ' Age ',
`sex` tinyint(1) DEFAULT NULL COMMENT ' Gender ',
PRIMARY KEY (`id`),
KEY `name_age` (`name`,`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
We need to check name and age,sql as follows
SELECT name, age FROM t_user
Because we established name,age The index of , And the data we query is these two , So we don't need to go back to the table .
Overlay index : If an index contains ( Or coverage ) The value of all the fields that need to be queried , We call it “ Overlay index ”.
notes : The overlay index must store the value of the index column , And hash index 、 Spatial index and full-text index do not store the value of index column , therefore MySQL Only use B+Tree Index to do overlay index . in addition , Different storage engines implement overlay indexes in different ways , And not all engines support overlay indexes .
版权声明
本文为[Xiaodaoxian 97]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230315096084.html
边栏推荐
- js 中,为一个里面带有input 的label 绑定事件后在父元素绑定单机事件,事件执行两次,求解
- 幂等性实践操作,基于业务讲解幂等性
- poi根据数据创建导出excel
- Yes Redis using distributed cache in NE6 webapi
- Course design of Database Principle -- material distribution management system
- ASP. Net 6 middleware series - conditional Middleware
- JS inheritance
- [mock data] fastmock dynamically returns the mock content according to the incoming parameters
- Experiment 6 input / output stream
- Tencent video VIP member, weekly card special price of 9 yuan! Tencent official direct charging, members take effect immediately!
猜你喜欢
Quartz. Www. 18fu Used in net core
Maui initial experience: Cool

IDEA查看历史记录【文件历史和项目历史】

Chapter 7 of C language programming (fifth edition of Tan Haoqiang) analysis and answer of modular programming exercises with functions

Charles uses three ways to modify requests and responses

12.<tag-链表和常考点综合>-lt.234-回文链表
Xutils3 corrected a bug I reported. Happy
![[Mysql] LEFT函數 | RIGHT函數](/img/26/82e0f2280de011636c26931a74e749.png)
[Mysql] LEFT函數 | RIGHT函數

在.NE6 WebApi中使用分布式缓存Redis

《C语言程序设计》(谭浩强第五版) 第9章 用户自己建立数据类型 习题解析与答案
随机推荐
Swap the left and right of each node in a binary tree
Why is bi so important to enterprises?
JS implementation of new
ASP. Net 6 middleware series - Custom middleware classes
2022年做跨境电商五大技巧小分享
ThreadLocal 测试多线程变量实例
超好用的Excel异步导出功能
Find the number of leaf nodes of binary tree
2022 Shandong Province safety officer C certificate work certificate question bank and online simulation examination
Blazor University (12) - component lifecycle
[Mysql] LEFT函数 | RIGHT函数
Miniapi of. Net7 (special section): NET7 Preview3
ASP. Net 6 middleware series - execution sequence
Impact of AOT and single file release on program performance
Utgard connection opcserver reported an error caused by: org jinterop. dcom. common. JIRuntimeException: Access is denied. [0x800
. net core current limiting control - aspnetcoreratelimit
Configure automatic implementation of curd projects
Tencent video price rise: earn more than 7.4 billion a year! Pay attention to me to receive Tencent VIP members, and the weekly card is as low as 7 yuan
General test technology [II] test method
Advanced sorting - fast sorting