当前位置:网站首页>大小端的理解以及宏定义实现的理解
大小端的理解以及宏定义实现的理解
2022-08-10 19:33:00 【zhangxiaio1】
大小端定义
在计算机系统中,数据存储是以字节为单位的,每个地址单元都对应着一个字节,一个字节为 8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于 8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小 端存储模式。这里的关键就在于,数据存储以及地址单元对应的最基本单位只有一个字节,8bit。
对于数据16进制数据0x1234,包含两个字节,注意左边的0x12为高位数据(不是34),右边的0x34是低位数据,假设从那个地址0x4000开始存放数据,则在大端模式(Big-endian)中,保存方式为
所谓的大端模式,是指数据的低位(就是权值较小的后面那几位)保存在内存的高地址中,而数据的高位,保存在内存的低地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;
对字符串高低位的理解:
char a[]= “12345”
这里1是最高位,5是最低位,也就是从左往右看,和数字的高低位一样,注意不是看数组下标。数组下标和高低位没关系。
从直观上来说,Big-endian的方式很符合日常对数据的解读。
Little-endian的方式为
所谓的小端模式,是指数据的低位保存在内存的低地址中,而数 据的高位保存在内存的高地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
大小端模式适用范围
大小端模式指的是16bit、32bit、64bit数据类型的保存方式,指的是多个字节的情况下哪个字节保存高位哪个字节保存低位的情况。
对于单字节,8bit,是没有大小端的说法的。至于对于0x1的二进制是00000001还是10000000,指的是位域的操作,不做过多研究。位域。
对于2字节16bit数据,数据保存方式存在上述大小端两种情况,因此对于不同的编译器相互间的通讯时需要进行数据结构的转化。
32bit和64bit的情况类似。
对于结构体,例如
typedef struct template
{
uint8_t a;
uint16_t b;
}template_t;
template_t v_template;
v_template.a = 1;//8位16进制0x01
v_template.b=1;16位16进制0x0001,高位是0x00,低位是0x01
假设template的起始地址为0x4000,那么大小端模式下结构体template的保存方式如:
大端:
小端:
也就是说对于结构体,大段模式并不是指所有的数据都从高位保存,仅仅在结构体含有的成员变量大于1个字节的情况下才会有大小端的问题。对于单个字节,不存在大小端问题。
指针、大小端、网络字节流发送
对于指针来说,不管是大端模式还是小端模式,指针总是指向低位地址,例如上述的template结构体,假设指针template_t指向该结构体,则他指向的地址是v_template.a的内存地址,而不是v_template.b的高位地址。即使地址+1,指向的也只是v_tempalte的低位地址。
typedef struct template
{
uint8_t a;
uint16_t b;
}template_t;
template_t v_template;
v_template.a = 1;//8位16进制0x01
v_template.b=1;16位16进制0x0001,高位是0x00,低位是0x01
template_t * template_t = &v_template;//
当网络发送字节流时,是不会考虑大小端的问题,网络只是单纯的将字节打包发送,发送顺序为从低位地址开始到高位地址结束。例如上述的v_template变量,先不管大小端的问题,也就是不管其中的变量,先看地址,那么首先开始发送的字节地址是0x4000,接下来分别是0x40001、0x4002。网络接受方的数据组织形式也是从低位地址到高位地址依次存放,一一对应。
发送方地址:
接收方地址
**不考虑结构体类型,也不考虑大小端的问题,只看地址发送的内容,**首先发送的地址是0x4000,数据为0x1,接下来是0x4001,数据为0x01,0x4002,数据为0x00,那么接受方接受到的地址数据也是如此。随后接收方需要定义结构体解读接受到的内容,如果是小端模式,定义相同的结构体template_t,那么成员a(uint8_t)的地址为0x3000,值为0x01,成员b(uint16_t)的地址为0x3001,0x3002,地址中的值分别为0x01,0x00,按照,小端模式的解读,最后变量a=0x01,b=0x0001。反正,如果是大端模式,那么成员a(uint8_t),占8位,因此为地址为0x3000,成员b(uint16_t)的地址为0x3001,0x3002,地址中的值分别为0x01,0x00,按照大段模式解读,a=0x01,b=0x0100(低位地址保存高位数据,高位地址保存低位数据,左边的是高位数值,右边的是低位数值)。
总结来说,不管是大段还是小端,对于地址来说,每个地址单元保存的单字节数据都是相同的,不同点在于对地址数据的解读方式。
Linux中大小端宏定义以及实现,自定义实现
gcc中预定义宏__BYTE_ORDER__、ORDER_LITTLE_ENDIAN、ORDER_BIG_ENDIAN。可以在代码中直接使用。
6.58 Other Built-in Functions Provided by GCC(点击打开链接)
这个页面最后面三个函数就是我们需要的:
— Built-in Function: uint16_t __builtin_bswap16 (uint16_t x)
Returns x with the order of the bytes reversed; for example, 0xaabb becomes 0xbbaa. Byte here always means exactly 8 bits.//返回x的反序字节,例如:0xaabb变成0xbbaa,下面类同。
— Built-in Function: uint32_t __builtin_bswap32 (uint32_t x)
Similar to __builtin_bswap16, except the argument and return types are 32 bit.
— Built-in Function: uint64_t __builtin_bswap64 (uint64_t x)
Similar to __builtin_bswap32, except the argument and return types are 64 bit.
参考:https://blog.csdn.net/10km/article/details/49021499
大小端对移位运算有没有影响? 大小端是内存存储数据高位和数据低位的不同顺序;而移位移的是寄存器中的内存,与内存是无关的。
左移代表低位向高位移动,右移代表高位向地位移动。 宏定义实现:,先移位后保留,先保留后移位,两种方式不同。
#define sw16(A) ((((u16)(A) & 0xff00) >> 8) | (((u16)(A) & 0x00ff) << 8))
//这里为什么是0xff00而不是0x00ff呢?((u16)(A) & 0xff00)先保留高位,在做移到低位,
//另一个类似。也可以写成
//#define sw16(A) (((((u16)(A) >>8)& 0x00ff)) | (((u16)(A) <<8) & 0xff00))
#define sw32(A) ((((u32)(A) & 0xff000000) >> 24) | (((u32)(A) & 0x00ff0000) >> 8) | (((u32)(A) & 0x0000ff00) << 8) | (((u32)(A) & 0x000000ff) << 24))
#define sw64(A) ((uint64_t)(\ (((uint64_t)(A)& (uint64_t)0x00000000000000ffULL) << 56) | \ (((uint64_t)(A)& (uint64_t)0x000000000000ff00ULL) << 40) | \ (((uint64_t)(A)& (uint64_t)0x0000000000ff0000ULL) << 24) | \ (((uint64_t)(A)& (uint64_t)0x00000000ff000000ULL) << 8) | \ (((uint64_t)(A)& (uint64_t)0x000000ff00000000ULL) >> 8) | \ (((uint64_t)(A)& (uint64_t)0x0000ff0000000000ULL) >> 24) | \ (((uint64_t)(A)& (uint64_t)0x00ff000000000000ULL) >> 40) | \ (((uint64_t)(A)& (uint64_t)0xff00000000000000ULL) >> 56) ))
自定义实现:根据地址连续的条件,可以利用union或者指针强转的方式实现。
static void endian_check()
{
union
{
uint32_t val_int;
uint8_t val_char;
} val_union;
val_union.val_int = 1U;
if (val_union.val_char != 1U)
{
g_endian_check = TIME_BIG_ENDIAN;
}
else
{
// do nothing
}
}
边栏推荐
- opengrok搭建[通俗易懂]
- YOLOv3 SPP source analysis
- The most complete GIS related software in history (CAD, FME, ArcGIS, ArcGISPro)
- Leetcode 200.岛屿数量 BFS
- 【毕业设计】基于Stm32的智能疫情防控门禁系统 - 单片机 嵌入式 物联网
- 七月券商金工精选
- IIC通信协议总结[通俗易懂]
- 怎么完全卸载赛门铁克_Symantec卸载方法,赛门铁克卸载「建议收藏」
- uni-app 数据上拉加载更多功能
- whois information collection & corporate filing information
猜你喜欢
[Teach you how to do mini-games] How to lay out the hands of Dou Dizhu?See what the UP master of the 250,000 fan game area has to say
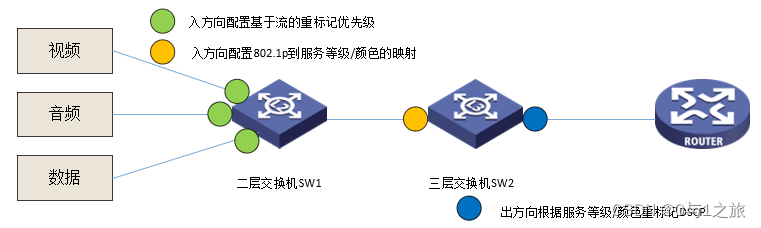
QoS Quality of Service Seven Switch Congestion Management
测试/开发程序员值这么多钱么?“我“不会愿赌服输......
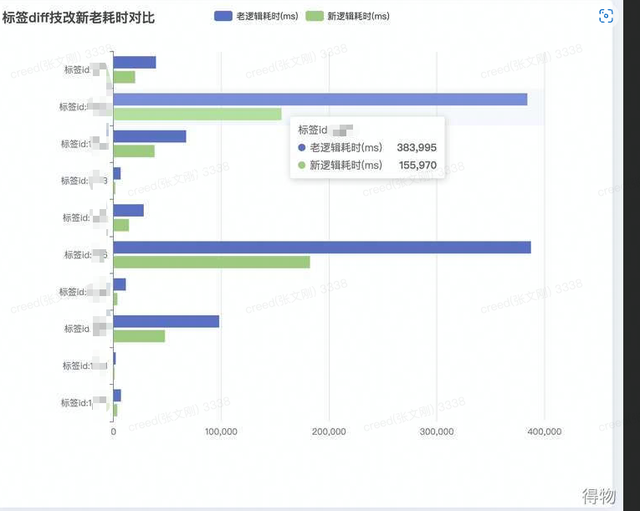
巧用RoaringBitMap处理海量数据内存diff问题

端口探测详解

2022杭电多校七 Black Magic (签到)
![[Natural Language Processing] [Vector Representation] PairSupCon: Pairwise Supervised Contrastive Learning for Sentence Representation](/img/e3/a1adb56678e9d26e09ff30be781e2a.png)
[Natural Language Processing] [Vector Representation] PairSupCon: Pairwise Supervised Contrastive Learning for Sentence Representation
转铁蛋白修饰长春新碱-粉防己碱脂质体|转铁蛋白修饰共载紫杉醇和金雀异黄素脂质体(试剂)
(12) findContours function hierarchy explanation
Metasploit——渗透攻击模块(Exploit)
![[Teach you how to do mini-games] How to lay out the hands of Dou Dizhu?See what the UP master of the 250,000 fan game area has to say](/img/11/eb7278ac9ebdfbd5835d147320efe7)
随机推荐
MATLAB设计,FPGA实现,联合ISE和Modelsim仿真的FIR滤波器设计
Modern Privacy-Preserving Record Linkage Techniques: An Overview论文总结
Apache DolphinScheduler 3.0.0 正式版发布!
echart 特例-多分组X轴
水溶性合金量子点纳米酶|CuMoS纳米酶|多孔硅基Pt(Au)纳米酶|[email protected]纳米模拟酶|PtCo合金纳米粒子
「POJ 3666」Making the Grade 题解(两种做法)
【greenDao】Cannot access ‘org.greenrobot.greendao.AbstractDaoSession‘ which is a supertype of
[CNN] Brush SOTA's trick
Hangdian Multi-School Seven 1003-Counting Stickmen (Combination Mathematics)
Tf铁蛋白颗粒包载顺铂/奥沙利铂/阿霉素/甲氨蝶呤MTX/紫杉醇PTX等药物
机器学习|模型评估——AUC
运维面试题(每日一题)
FEMRL: A Framework for Large-Scale Privacy-Preserving Linkage of Patients’ Electronic Health Rec论文总结
@Autowired annotation --required a single bean, but 2 were found causes and solutions
代理模式的使用总结
重载和重写
Apple Font Lookup
Metasploit——渗透攻击模块(Exploit)
哈工大软件构造Lab3(2022)
从 GAN 到 WGAN