当前位置:网站首页>FEMRL: A Framework for Large-Scale Privacy-Preserving Linkage of Patients’ Electronic Health Rec论文总结
FEMRL: A Framework for Large-Scale Privacy-Preserving Linkage of Patients’ Electronic Health Rec论文总结
2022-08-10 18:40:00 【桐青冰蝶Kiyotaka】
FEMRL: A Framework for Large-Scale Privacy-Preserving Linkage of Patients’ Electronic Health Records论文总结
Abstract
整合来自不同数据源的大量患者医疗保健数据,以促进数据分析和清理任务。
LSHDB,它是一个并行和分布式数据引擎,用于执行隐私保护记录链接 (PPRL) 任务,同时提供结果完整性的正式保证。
I. INTRODUCTION

记录链接包括两个步骤:阻塞和匹配
阻塞步骤中,记录链接算法旨在从参与典型记录链接设置的大量记录中制定尽可能多的匹配记录对。
在匹配步骤中,该算法旨在将在上一步中制定的对分类为匹配或不匹配。
隐私保护记录链接(PPRL)技术可用于在隐私保证下实现高链接质量。 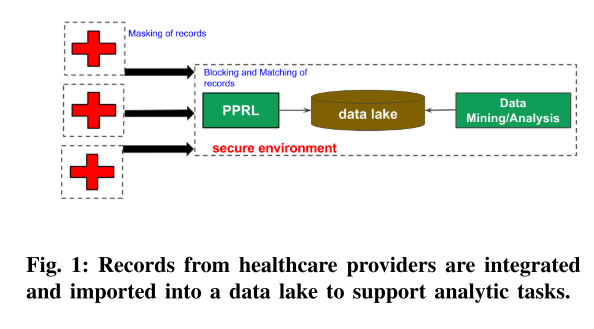
第一步,医疗保健提供者掩盖他们收集的电子患者记录,以保护某些(常见)直接标识符,例如患者姓名和家庭住址,这些标识符对于启用记录链接很有用 [30]。
其他直接标识符,例如患者的病历编号,由于它们既敏感又对 PPRL 无用(由于不通用)而从数据中隐藏。最后,选择的非直接标识符,例如症状或药物,保持未屏蔽,以促进基于这些维度的数据分析。
处理后的数据使用最先进的加密通信链路安全地传输到 TTP,并存储在安全环境中(遵循法律要求)。

II. RELATED WORK

缺乏:执行并行计算、处理分布式数据存储或构建有效的索引结构以在线查询数据。
III. PRELIMINARIES
A. Data Masking Methods
采用 Schnell 等人介绍的基于 Bloom 过滤器的编码方法,其中每个 Bloom 过滤器代表一个完整的数据记录。
频率攻击
B. Locality-Sensitive Hashing
Locality-Sensitive Hashing (LSH) technique
随机局部敏感散列 (LSH) 技术
LSH 保证使用严格定义数量的哈希表 [18] 以高概率识别每个相似的记录对。一对记录之间的相似性是通过在所使用的度量空间中指定适当的距离阈值来定义的。
C. Overview of LSHDB
分布式引擎,它利用 LSH 和并行性的力量来执行记录链接和相似性搜索任务。
对记录进行散列处理并将其保持为准备链接状态可以节省工作时间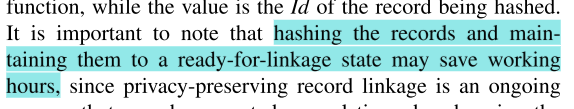
在创建数据存储时,开发人员只需指定两个参数:
(i) 将采用的 LSH 方法,例如 Hamming、Min-Hash 或 Euclidean LSH
(ii) 底层 noSQL 数据引擎将用于托管数据。
跨分布式数据存储
IV. FEMRL: A FRAMEWORK FOR ELECTRONIC MEDICAL RECORD LINKAGE
A. Blocking and Matching of Records
一个非常重要的配置参数是定义将在距离计算期间使用的阈值,因为该阈值将指定将创建的哈希表的数量。
1) The Monolithic Mode单体模式:
在单体模式下,数据保管人会屏蔽他们的记录并将它们发送到 TTP (Trusted Third Party )。
反过来,TTP 将提交的数据集的屏蔽记录提供给 LSHDB,以构建必要的哈希表
将属于不同医疗保健提供者的已制定记录对与指定的距离阈值进行比较,以检测对应于同一患者的那些记录。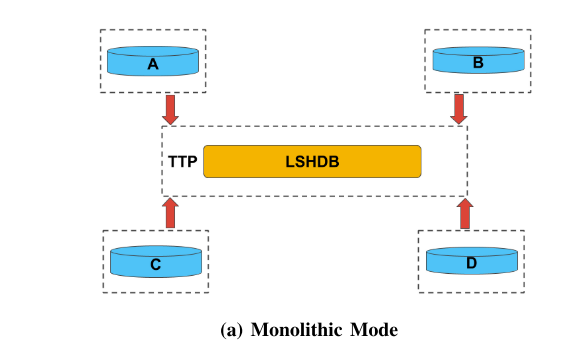
优点:简单
缺点:使单个站点不堪重负、可扩展性只能通过昂贵的软件和硬件升级来实现
2) The Distributed Mode分布模式:
TTP 在安全环境中维护多个站点,每个站点都持有数据保管人先前提交的屏蔽记录的水平分区。
被屏蔽的记录被提交到一个中心站点,然后转发到其余站点。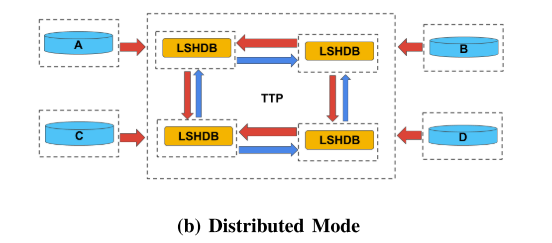
优点:(a) 在单个站点没有大规模发布和维护记录、 (b) FEMRL 可以轻松扩展
缺点:带有 noSQL 系统的 LSHDB 必须安装在每个站点中
3) Algorithms Used by Both Modes:(没有理解)


Complexity
算法 1 的运行时间与 A 的记录数成线性关系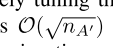
算法 2 的总运行时间为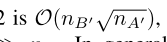
B. Integration with MapReduce
FEMRL 在 MapReduce 基础架构之上运行。
Map 阶段属于阻塞步骤,而 Reduce 阶段属于匹配步骤
- Map phase.
map阶段。每个映射任务构建手头的每个屏蔽记录的哈希键,并将它们与相应记录的 ID 一起发送到分区任务。 - Distribution of tuples.
元组的分布。每个分区任务,总是绑定到一个映射任务,控制制定的元组到归约任务的分布。具有相同哈希键的元组将被转发到特定的 reduce 任务。 - Reduce phase.
每个reduce任务处理任务转发的接收到的元组的负载。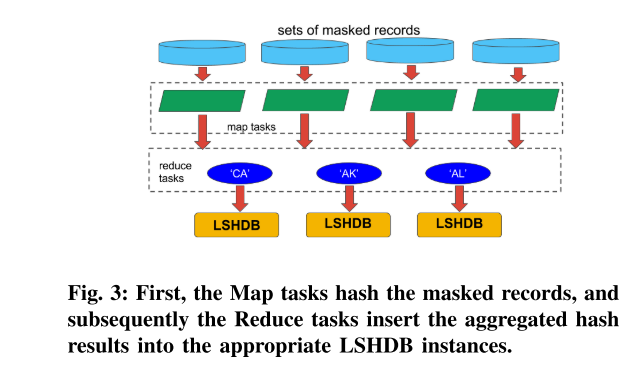
首先,Map 任务对屏蔽的记录进行哈希处理,随后 Reduce 任务将聚合的哈希结果插入到适当的 LSHDB 实例中。
V. EXPERIMENTAL EVALUATION
实验评价
A. Data Sets and Metrics
数据集和指标
使用了两个指标:
(a) 配对完整性(PC 或召回率),即返回的真阳性数与真阳性总数的比率,
(b) 配对质量(PQ 或精度),即返回的真阳性数与处理的真假阳性总数之比。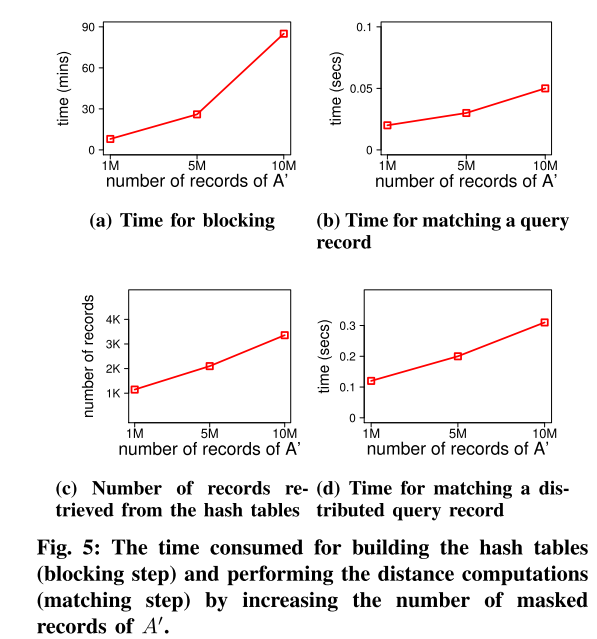
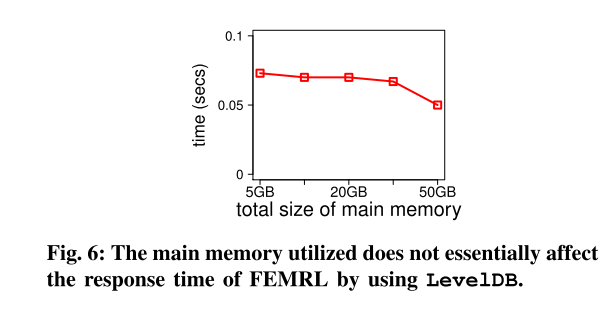
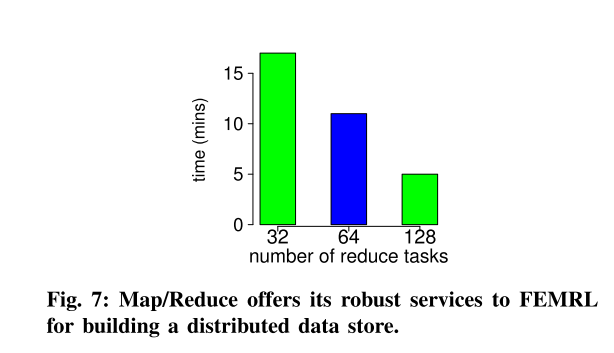
VI. CONCLUSIONS
FEMRL,一种用于记录链接的隐私保护框架。
FEMRL 的核心组件是 LSHDB,这是一个并行的分布式数据引擎
LSHDB 与 MapReduce 的集成导致构建了一个分布式数据存储,用于执行按需 PPRL 任务。
边栏推荐
猜你喜欢



随机推荐
CAS:190598-55-1_Biotin sulfo-N-hydroxysuccinimide ester生物素化试
StoneDB Document Bug Hunting Season 1
【图像去雾】基于颜色衰减先验的图像去雾附matlab代码
Scala中使用 Jackson API 进行JSON序列化和反序列化
6-12 二叉搜索树的操作集(30分)
JVM内存和垃圾回收-11.执行引擎
About npm/cnpm/npx/pnpm and yarn
stm32中的CAN通讯列表模式配置解析与源码
FPGA:基础入门按键控制蜂鸣器
803. 区间合并(贪心)左端点、右端点排序均可
Redis 持久化机制
003-序列图(一)
【OpenCV】-物体的凸包
【图像分割】基于元胞自动机实现图像分割附matlab代码
How to choose Fengjiawei PHY62xx series?PHY6222/PHY6212/PHY6252
LeetCode·26.删除有序数组中的重复项·双指针
钻石价格预测的ML全流程!从模型构建调优道部署应用!
Keras深度学习实战(17)——使用U-Net架构进行图像分割
6-10 二分查找(20分)
TikTok选品有什么技巧?