当前位置:网站首页>request模块
request模块
2022-04-23 14:01:00 【清新的草莓】
request模块
Python中原生的一款基于网络请求的模块。
作用:模拟浏览器发请求
安装
pip install requests
发送请求
r = requests.get('https://api.github.com/events')
r = requests.post('http://httpbin.org/post', data = {
'key':'value'})
r = requests.put('http://httpbin.org/put', data = {
'key':'value'})
r = requests.delete('http://httpbin.org/delete')
r = requests.head('http://httpbin.org/get')
r = requests.options('http://httpbin.org/get')
传递参数
payload = {
'key1': 'value1', 'key2': 'value2'}
r = requests.get("http://httpbin.org/get", params=payload)
# 还可以将一个列表作为值传入:
payload = {
'key1': 'value1', 'key2': ['value2', 'value3']}
响应内容
# Requests 会自动解码来自服务器的内容。大多数 unicode 字符集都能被无缝地解码。
r = requests.get('https://api.github.com/events')
r.text
# 查看编码
r.encoding
# 改变编码
r.encoding = 'ISO-8859-1'
## 二进制响应内容(以字节的方式访问请求响应体)
r.content
## json响应内容(内置的 JSON 解码器)
r.json()
定制请求头
# 简单地传递一个 dict 给 headers 参数就可以了。
url = 'https://api.github.com/some/endpoint'
headers = {
'user-agent': 'my-app/0.0.1'}
r = requests.get(url, headers=headers)
注意: 定制 header 的优先级低于某些特定的信息源,例如:
- 如果在
.netrc中设置了用户认证信息,使用 headers= 设置的授权就不会生效。而如果设置了auth=参数,.netrc的设置就无效了。 - 如果被重定向到别的主机,授权 header 就会被删除。
- 代理授权 header 会被 URL 中提供的代理身份覆盖掉。
- 在我们能判断内容长度的情况下,header 的 Content-Length 会被改写。
更加复杂的 POST 请求
你想要发送一些编码为表单形式的数据,只需简单地传递一个字典给 data 参数。你的数据字典在发出请求时会自动编码为表单形式:
payload = {
'key1': 'value1', 'key2': 'value2'}
r = requests.post("http://httpbin.org/post", data=payload)
# 你还可以为 data 参数传入一个元组列表:
payload = (('key1', 'value1'), ('key1', 'value2'))
# 发送 json 的 POST/PATCH 数据:
url = 'https://api.github.com/some/endpoint'
payload = {
'some': 'data'}
requests.post(url, data=json.dumps(payload)) # 2.4.2 版:requests.post(url, json=payload)
上传 Multipart-Encoded 的文件
url = 'http://httpbin.org/post'
files = {
'file': open('report.xls', 'rb')}
r = requests.post(url, files=files)
# 可以显式地设置文件名,文件类型和请求头:
files = {
'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {
'Expires': '0'})}
状态响应码
r = requests.get('http://httpbin.org/get')
r.status_code
# 内置的状态码查询对象
r.status_code == requests.codes.ok
# 抛出错误请求异常
r.raise_for_status()
响应头
r.headers # 查看响应头
## 查看响应头特定字段
r.headers['Content-Type']
r.headers.get('content-type')
Cookies
r.cookies['example_cookie_name']
# 发送cookies
url = 'http://httpbin.org/cookies'
cookies = dict(cookies_are='working')
r = requests.get(url, cookies=cookies)
# Cookie 的返回对象为 RequestsCookieJar,它的行为和字典类似,但接口更为完整,适合跨域名跨路径使用。你还可以把 Cookie Jar 传到 Requests 中:
jar = requests.cookies.RequestsCookieJar()
jar.set('tasty_cookie', 'yum', domain='httpbin.org', path='/cookies')
jar.set('gross_cookie', 'blech', domain='httpbin.org', path='/elsewhere')
url = 'http://httpbin.org/cookies'
r = requests.get(url, cookies=jar)
r.text -> '{"cookies": {"tasty_cookie": "yum"}}'
高级进阶
会话对象(Session)
会话对象让你能够跨请求保持某些参数。
s = requests.Session()
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
r = s.get("http://httpbin.org/cookies")
print(r.text)
# '{"cookies": {"sessioncookie": "123456789"}}'
会话也可用来为请求方法提供缺省数据。这是通过为会话对象的属性提供数据来实现的:
s = requests.Session()
s.auth = ('user', 'pass')
s.headers.update({
'x-test': 'true'})
# both 'x-test' and 'x-test2' are sent
s.get('http://httpbin.org/headers', headers={
'x-test2': 'true'})
流式上传
# 仅需为你的请求体提供一个类文件对象即可:
with open('massive-body') as f:
requests.post('http://some.url/streamed', data=f)
响应体内容工作流
# 默认情况下,当你进行网络请求后,响应体会立即被下载。你可以通过 stream 参数,推迟下载响应体,直到访问 Response.content 属性再去下载:
r = requests.get(tarball_url, stream=True)
你可以进一步使用 Response.iter_content 和 Response.iter_lines 方法来控制工作流,或者以 Response.raw 从底层 urllib3 的 urllib3.HTTPResponse <urllib3.response.HTTPResponse 读取未解码的响应体。
如果你在请求中把 stream 设为 True,Requests 无法将连接释放回连接池,除非你 消耗了所有的数据,或者调用了 Response.close。 这样会带来连接效率低下的问题。如果你发现你在使用 stream=True 的同时还在部分读取请求的 body(或者完全没有读取 body),那么你就应该考虑使用 with 语句发送请求,这样可以保证请求一定会被关闭:
with requests.get('http://httpbin.org/get', stream=True) as r:
# 在此处理响应。
pass
事件挂钩
# 你可以通过传递一个 {hook_name: callback_function} 字典给 hooks 请求参数为每个请求分配一个钩子函数:
hooks=dict(response=callback_function)
callback_function 会接受一个数据块作为它的第一个参数。
def callback_function(r, *args, **kwargs):
print(r.url)
超时(timeout)
requests 默认是不会自动进行超时处理的。
# 这一 timeout 值将会用作 connect 和 read 二者的 timeout。
r = requests.get('https://github.com', timeout=5)
# 如果要分别制定,就传入一个元组:
r = requests.get('https://github.com', timeout=(3.05, 27))
设置代理
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("http://example.org", proxies=proxies)
# 你也可以通过环境变量 HTTP_PROXY 和 HTTPS_PROXY 来配置代理。
$ export HTTP_PROXY="http://10.10.1.10:3128"
$ export HTTPS_PROXY="http://10.10.1.10:1080"
# 若你的代理需要使用HTTP Basic Auth,可以使用 http://user:password@host/ 语法:
proxies = {
"http": "http://user:[email protected]:3128/",
}
# 要为某个特定的连接方式或者主机设置代理,使用 scheme://hostname 作为 key, 它会针对指定的主机和连接方式进行匹配。
proxies = {
'http://10.20.1.128': 'http://10.10.1.10:5323'}
版权声明
本文为[清新的草莓]所创,转载请带上原文链接,感谢
https://blog.csdn.net/qq_36540244/article/details/124323437
边栏推荐
- Question bank and answer analysis of the 2022 simulated examination of the latest eight members of Jiangxi construction (quality control)
- Decimal 格式化小数位/DateTime 转换处理
- China creates vast research infrastructure to support ambitious climate goals
- Android 面试主题集合整理
- 接口文档yaml
- centOS下mysql主从配置
- Universal template for scikit learn model construction
- 1256:献给阿尔吉侬的花束
- STM32 learning record 0007 - new project (based on register version)
- scikit-learn构建模型的万能模板
猜你喜欢
Oracle alarm log alert Chinese trace and trace files
![[VMware] address of VMware Tools](/img/0e/13f263bd69c8224f7c755258d94777.png)
[VMware] address of VMware Tools
scikit-learn构建模型的万能模板

基础知识学习记录
What is the difference between blue-green publishing, rolling publishing and gray publishing?
Quartus Prime硬件实验开发(DE2-115板)实验一CPU指令运算器设计

Express ② (routage)
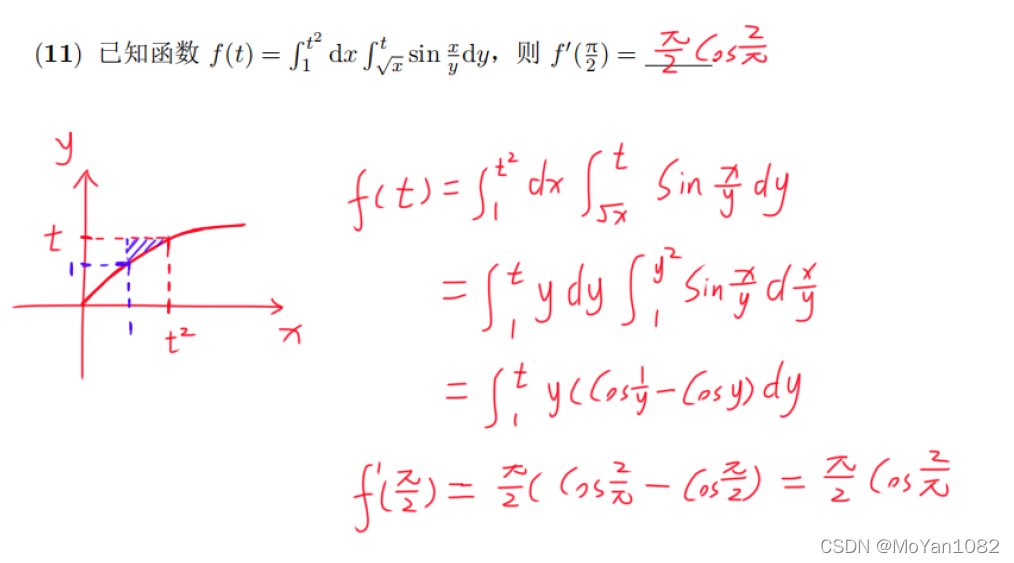
专题测试05·二重积分【李艳芳全程班】

Android interview theme collection

Reading notes: meta matrix factorization for federated rating predictions
随机推荐
Express中间件③(自定义中间件)
BUG_me
编程旅行之函数
2021年秋招,薪资排行NO
L2-024 部落 (25 分)
Android: answers to the recruitment and interview of intermediate Android Development Agency in early 2019 (medium)
初探 Lambda Powertools TypeScript
生产环境——
cnpm的诡异bug
程序编译调试学习记录
China creates vast research infrastructure to support ambitious climate goals
初识go语言
VsCode-Go
STM32学习记录0007——新建工程(基于寄存器版)
Reading notes: fedgnn: Federated graph neural network for privacy preserving recommendation
Universal template for scikit learn model construction
Analysis and understanding of atomicintegerarray source code
websocket
What is the difference between blue-green publishing, rolling publishing and gray publishing?
New关键字的学习和总结