当前位置:网站首页>Correct method of calculating inference time of neural network
Correct method of calculating inference time of neural network
2022-04-23 08:47:00 【a little cabbage】
Preface
In the area of network deployment , Computing the reasoning time of the network is a crucial aspect , however , Correctly and meaningfully measure the reasoning time or delayed task of neural network , Need a deep understanding . Even experienced programmers often make some common mistakes , These errors can lead to inaccurate delay measurement .
In this article , We reviewed some of the main issues that should be addressed , In order to correctly measure the delay time . We reviewed what made GPU Perform unique main processes , Including asynchronous execution and GPU preheating . Then we share code samples , In order to be in GPU Measure the time correctly on the . Last , We looked back at gpu Some mistakes people often make when quantifying reasoning time on .
Reference resources :The Correct Way to Measure Inference Time of Deep Neural Networks
Asynchronous execution
Let's start from the discussion GPU The implementation mechanism of . In multithreading or multi device programming , Two independent blocks of code can be executed in parallel ; This means that the second code block may be executed before the first code block . This process is called asynchronous execution . In a deep learning environment , We often use this to perform , Because by default GPU The operation is asynchronous .

Asynchronous execution provides great advantages for deep learning , For example, it can greatly reduce the running time . for example , When reasoning in multiple batches , Can be in CPU Up to the second batches Pre treatment , And the first one batches stay GPU On forward. obviously , It would be beneficial to use asynchrony when reasoning as much as possible .
The effect of asynchronous execution is invisible to the user , however , When it comes to time measurement , It can be the cause of many headaches . When you use Python Medium “time” When calculating the time in the library , The measurement will take place at CPU On the device . because GPU The asynchronous nature of , The code to stop timing will be in GPU Execute before the process completes . result , The calculated time is not the correct reasoning time . please remember , We want to use asynchronous , At the end of this article , We will explain how to measure time correctly , Despite asynchronous processes .
GPU warm-up
modern GPU The device can exist in one of several different power states . When GPU Not used for any purpose , And persistent patterns ( That is to keep GPU open ) When not enabled ,GPU Will automatically reduce its power state to a very low level , Sometimes it's even completely closed . At low power consumption ,GPU Will shut down different hardware , Including memory subsystem 、 Internal subsystem , Even computing cores and caches .
Any attempt to communicate with GPU The calling of interactive programs will lead to driver loading and / Or initialize GPU. The driver loading behavior is noteworthy . Trigger GPU Initialized applications can produce up to 3 Second delay , This is due to the scrubbing behavior of error correction code . for example , If we measure network reasoning time , Reasoning about an example requires 10 millisecond , Reasoning 1000 This example may cause most of our running time to be wasted in initialization GPU On . Of course , We don't want to measure these factors , Because the time of measurement is not accurate . This does not reflect GPU A production environment that has been initialized or working in persistent mode .
below , Let's see how to overcome... When measuring time GPU The initialization .
A method of correctly measuring reasoning time
Below pytorch The reasoning block measures the correct time . Here I use Efficient-net-b0 The Internet , You can also use any other network . In the code , We deal with the two considerations described above . Before we take any time measurements , Let's run some virtual examples through the network to make a “GPU warm-up”. This will automatically initialize GPU, And prevent it from entering power saving mode , When we measure time . Next , We use tr.cuda.event stay GPU Measure the time on the , Here we use torch.cuda.synchronize() Is crucial . This line of code executes the host and device ( namely GPU and CPU) Synchronization between , therefore , Only in GPU After running the process on , Will record the time . This overcomes the problem of asynchronous execution .
model = EfficientNet.from_pretrained(‘efficientnet-b0’)
device = torch.device(“cuda”)
model.to(device)
dummy_input = torch.randn(1, 3,224,224,dtype=torch.float).to(device)
starter, ender = torch.cuda.Event(enable_timing=True), torch.cuda.Event(enable_timing=True)
repetitions = 300
timings=np.zeros((repetitions,1))
#GPU-WARM-UP
for _ in range(10):
_ = model(dummy_input)
# MEASURE PERFORMANCE
with torch.no_grad():
for rep in range(repetitions):
starter.record()
_ = model(dummy_input)
ender.record()
# WAIT FOR GPU SYNC
torch.cuda.synchronize()
curr_time = starter.elapsed_time(ender)
timings[rep] = curr_time
mean_syn = np.sum(timings) / repetitions
std_syn = np.std(timings)
print(mean_syn)
Common mistakes in measuring time
When we calculate the reasoning time of the network is , Our goal is to calculate only the time of forward reasoning . Usually , Even experts , They also make some common mistakes in their measurement . Here are some examples of common mistakes :
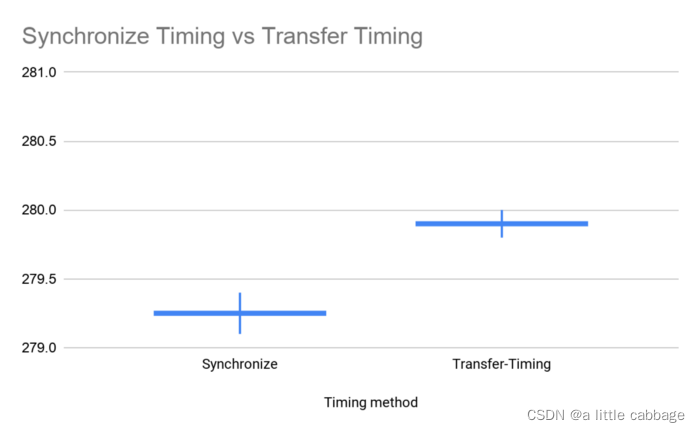
- The measurement includes CPU and GPU Data transfer between . This is usually in CPU Create a tensor on , And then in GPU Done unintentionally while executing reasoning on . This memory allocation takes quite a long time . The effect of this error on the mean and variance of the measurement is as follows :
- Not used GPU warm-up. As mentioned above , For the first time in GPU Running on will initialize .GPU Initialization requires 3 second .
- standards-of-use CPU timing . The most common error is measuring time without synchronization . Even experienced programmers will use the following code . Of course , This completely ignores the asynchronous execution mentioned earlier , So the wrong time is output . The effect of this error on the mean and variance of the measured value is as follows :

s = time.time()
_ = model(dummy_input)
curr_time = (time.time()-s )*1000
- Reason only once . Like many processes in computer science , The feedforward of neural network has ( Small ) Random component . Runtime differences can be very large , Especially when measuring low delay networks . So , You must run the network in more than one example ( That is, more basic reasoning ) Then calculate the average result .
版权声明
本文为[a little cabbage]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230837010670.html
边栏推荐
- Go语言自学系列 | golang结构体作为函数参数
- Consensus Token:web3. 0 super entrance of ecological flow
- Star Trek's strong attack opens the dream linkage between metacosmic virtual reality
- 【58】最后一个单词的长度【LeetCode】
- 关于cin,scanf和getline,getchar,cin.getline的混合使用
- ONEFLOW learning notes: from functor to opexprinter
- 扣缴义务人
- 00后最关注的职业:公务员排第二,第一是?
- MATLAB 画五星红旗
- Introduction to GUI programming swing
猜你喜欢

Share the office and improve the settled experience

测试你的机器学习流水线

洋桃電子STM32物聯網入門30步筆記一、HAL庫和標准庫的區別

'bully' Oracle enlarged its move again, and major enterprises deleted JDK overnight...

洋桃电子STM32物联网入门30步笔记四、工程编译和下载

Solidity 问题汇总

正点原子携手OneOS直播 OneOS系统教程全面上线

Introduction to GUI programming swing

增强现实技术是什么?能用在哪些地方?

Consensus Token:web3. 0 super entrance of ecological flow
随机推荐
《深度学习》学习笔记(八)
第一性原理 思维导图
uni-app和微信小程序中的getCurrentPages()
Output first order traversal according to second order and middle order traversal (25 points)
Notes on 30 steps of introduction to Internet of things of yangtao electronics STM32 III. Explanation of new cubeide project and setting
Notes on 30 steps of introduction to the Internet of things of yangtao electronics STM32 III. cubemx graphical programming and setting the IO port on the development board
应纳税所得额
Redis Desktop Manager for Mac(Redis可视化工具)
DJ音乐管理软件Pioneer DJ rekordbox
根据后序和中序遍历输出先序遍历 (25 分)
Introduction to GUI programming swing
四张图弄懂matplotlib的一些基本用法
Navicat远程连接mysql
Star Trek强势来袭 开启元宇宙虚拟与现实的梦幻联动
Go语言自学系列 | golang嵌套结构体
Anonymous type (c Guide Basics)
【58】最后一个单词的长度【LeetCode】
Enctype attribute in form
synchronized 锁的基本用法
Go语言自学系列 | golang结构体指针