当前位置:网站首页>搭建自己的以图搜图系统 (一):10 行代码搞定以图搜图
搭建自己的以图搜图系统 (一):10 行代码搞定以图搜图
2022-08-10 18:16:00 【Zilliz】
目前市面上有很多以图搜图的服务,如 Google 识图,百度图片搜索,淘宝拍立淘等。本文将介绍如何快速搭建自己的图片搜索引擎,只要 10 行 Python 代码就能轻松搞定!
import towhee
towhee.read_csv('reverse_image_search.csv') \
.runas_op['id', 'id'](func=lambda x: int(x)) \
.image_decode['path', 'img']() \
.image_embedding.timm['img', 'vec'](model_name='resnet50') \
.to_milvus['id', 'vec'](collection=collection, batch=100)
towhee.glob['path']('./test/*/*.JPEG') \
.image_decode['path', 'img']() \
.image_embedding.timm['img', 'vec'](model_name='resnet50') \
.milvus_search['vec', 'result'](collection=collection, limit=10)
图 1 为查询图像时的展示结果,左侧为搜索的图片,右侧是得到的相似图片。
在介绍如何搭建系统之前,我们先简单了解下以图搜图的基本原理。
以图搜图
以图搜图,顾名思义就是用图片搜索图片。它的应用场景包括查找原始图片、搜索相似的图片、商品搜索和推荐(根据图片在商品库中搜索同款,或者推荐相似商品)等。
传统图像搜索¹是利用增加元数据的方法,例如:根据图片添加字幕、关键词或是文段说明,通过打标签的方式来完成检索。而以图搜图是一种基于内容的图像检索 (CBIR) 技术²,它的特点是无需关键字就能理解图像的相关内容,主要依赖于 AI 算法,目前一些排名较好的图像分类算法可以到达 99% 准确率(TOP5)³。本文将利用 AI 模型提取图像特征向量,通过特征向量计算来完成以图搜图。
准备工作
完整的代码已上传到 Github,欢迎读者参考和使用:https://github.com/towhee-io/examples/blob/main/image/reverse_image_search/1_build_image_search_engine.ipynb
数据准备
ImageNet⁴数据集是深度学习领域中图像分类和检测最常用数据集之一,本文的图像数据就是从中随机抽取的。我们所使用的数据集中包括训练集(train)和测试集(test)两部分,训练集有 100 个分类,每个分类有 10 张图片,测试集则是 100 个分类,每个分类 1 张图片。
我们先下载数据并解压:
$ curl -L https://github.com/towhee-io/examples/releases/download/data/reverse_image_search.zip -O
$ unzip -q -o reverse_image_search.zip
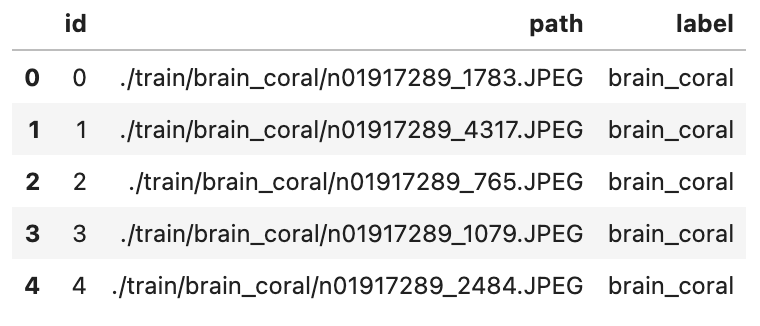
解压后会发现有一个 CSV 格式的文件,它包含了训练集中 1000 张图片的基础信息,如图像的 id、所在路径、以及类别。
让我们以表格方式查看下文件的内容(图 2 所示):
import pandas as pd
df = pd.read_csv('reverse_image_search.csv')
df.head()
为了记录数据集中每个id对应的图片路径,接下来我们将读取的df转换为id_img字典。同时定义read_images函数,该函数根据搜索结果的id返回图片列表,便于最终的图片展示。
import cv2
from towhee._types.image import Image
id_img = df.set_index('id')['path'].to_dict()
def read_images(results):
imgs = []
for re in results:
path = id_img[re.id]
imgs.append(Image(cv2.imread(path), 'BGR'))
return imgs
至此我们完成了数据准备过程,接下来是关于图像处理的准备工作,需要用到两个重要组件 Towhee 和 Milvus。
Towhee & Milvus
图片搜索需要用特征向量来表征图像,我们通常利用 AI 模型提取特征向量,但面对业界的诸多模型我们该如何快速上手?"X2Vec, Towhee is all you need!",Towhee (https://github.com/towhee-io/towhee)提供开箱即用的 Embedding 流水线可以将任何非结构化数据(图像,视频,音频等)转为特征向量,通过 Towhee 我们运行一条流水线就能轻松得到特征向量。
解决了如何提取特征向量的问题,接下来要解决的是向量搜索问题。
想要快速简单的实现向量检索功能,选择使用 Milvus 是一个不错的技术方案。Milvus(https://github.com/milvus-io/milvus) 是一个开源的向量数据库项目,它支持丰富的向量索引算法和向量计算方式,轻松实现对数百万、数十亿甚至数万亿向量的相似性搜索,具有高度灵活、稳定可靠以及高速查询等特点。
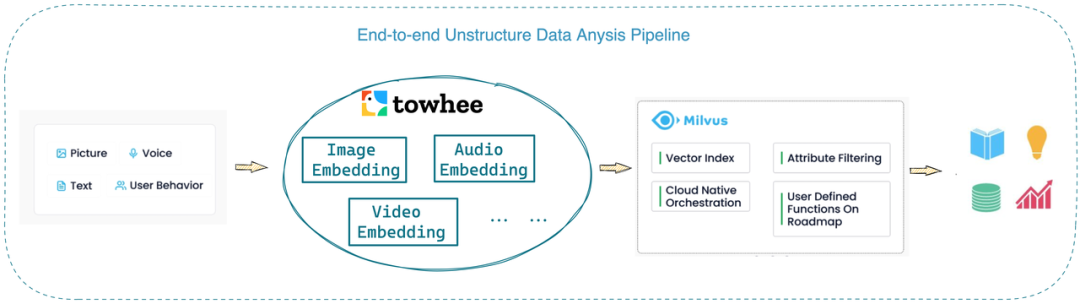
完整的系统架构如图 3 所示,通过 Towhee + Milvus 就可以实现端到端的图像等非结构化数据分析。我们先使用 Towhee 完成非结构化数据的特征向量提取,然后 Milvus 负责存储并搜索向量,最终获取与查询数据最相似的结果并展示。
理解了基于 Tohwhee 和 Milvus 的以图搜图架构,接下来我们要先完成 Towhee 和 Milvus 的安装:
注意:Milvus 支持单机安装和集群安装,本文使用docker-compose(https://milvus.io/docs/v2.0.x/install_standalone-docker.md)方式安装单机 Milvus,在此之前请先检查本机环境的软硬件条件(https://milvus.io/docs/v2.0.x/prerequisite-docker.md)。
#安装 Towhee
$ pip install towhee
#安装单机版 Milvus
$ wget https://github.com/milvus-io/milvus/releases/download/v2.0.2/milvus-standalone-docker-compose.yml -O docker-compose.yml
$ docker-compose up -d
Towhee
Towhee 支持图像 Embedding,音频 Embedding,视频 Embedding 等非结构化数据特征提取的方法,这些都被称为 Towhee 的算子(Operator),算子是流水线(Pipeline)中的单个节点,一个图像特征提取流水线就可以通过连接 image_decode(https://towhee.io/image-decode/cv2) 算子和 image_embedding.timm(https://towhee.io/image-embedding/timm) 算子实现,其中 Embedding 算子可以通过指定model_name="resnet50"利用 ResNet50 模型生成特征向量(结果如图 4 所示):
import towhee
towhee.glob['path']('./test/lion/n02129165_13728.JPEG') \
.image_decode['path', 'img']() \
.image_embedding.timm['img', 'vec'](model_name='resnet50') \
.select['img', 'vec']() \
.show()

image_embedding.timm 算子支持各种预训练好的模型,包括 vgg16,resnet50,vit_base_patch8_224,convnext_base等。该算子被托管在 Towhee Hub 上,Hub 上有成百上千个算子,你可以在其中找到任何你想要的 Embedding 处理方式。
Milvus
接下来在 Milvus 数据库中创建集合(Collection),集合中的 Fields 包含两列:id 和 embedding,其中 id 是集合的主键。另外我们可以为 embedding 创建 IVF_FLAT (https://milvus.io/docs/v2.0.x/index.md#IVF_FLAT) 基于量化的索引,其中索引的参数是 nlist=2048,计算方式是 "L2" 欧式距离:
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
def create_milvus_collection(collection_name, dim):
connections.connect(host='127.0.0.1', port='19530')
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, descrition='ids', is_primary=True, auto_id=False),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, descrition='embedding vectors', dim=dim)
]
schema = CollectionSchema(fields=fields, description='reverse image search')
collection = Collection(name=collection_name, schema=schema)
# create IVF_FLAT index for collection.
index_params = {
'metric_type':'L2',
'index_type':"IVF_FLAT",
'params':{"nlist":2048}
}
collection.create_index(field_name="embedding", index_params=index_params)
return collection
collection = create_milvus_collection('reverse_image_search', 2048)运行以图搜图并展示
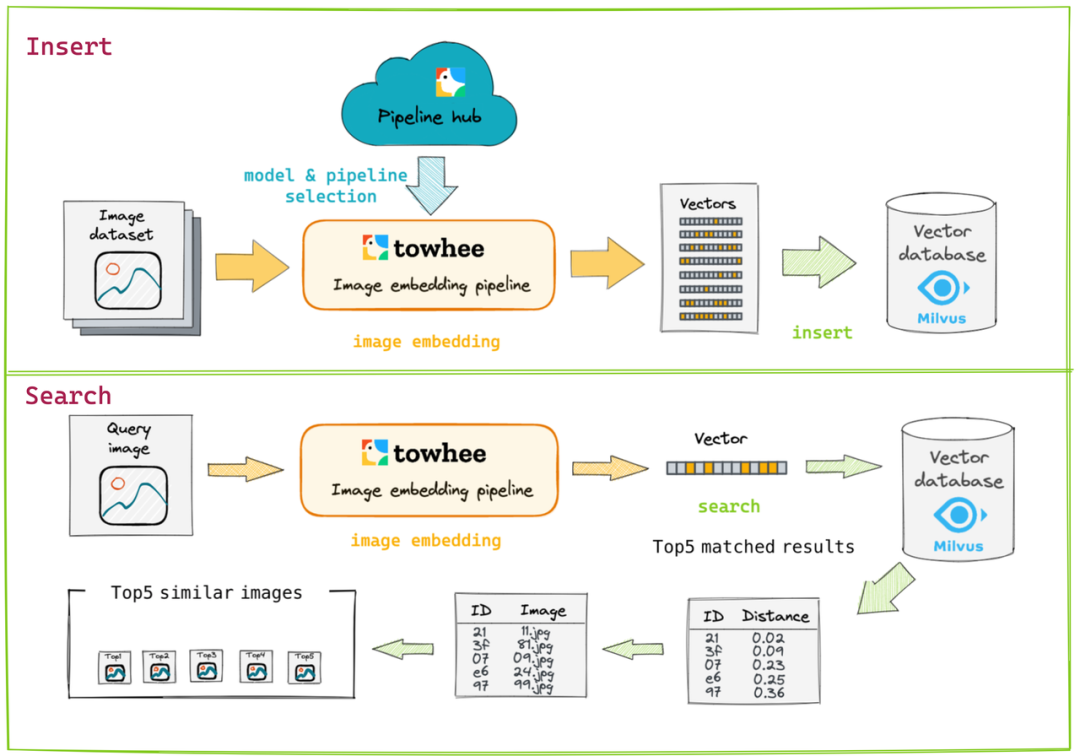
如图 5 所示,我们将以图搜图服务分为插入和查询两步:首先在 Towhee hub 上选择所需的图像 Embedding 流水线,用来提取图像数据集的特征向量,再将特征向量存入 Milvus 中;查询的时候利用同样的流水线提取查询图像的特征向量,然后在 Milvus 中检索得出相似的结果,最终展示出图片。
图像数据入库
Towhee 不光拥有丰富的算子来处理非结构化数据,还提供了简单好用的接口来处理各种数据,当然也集成了 Milvus 的一些基本用法,通过在“流水线”中连接这些算子或接口,图像入库操作将变得十分简单。
图像数据入库”流水线“的代码说明参考注释,如果你有不明白的地方,欢迎留言讨论,或者直接给 Towhee 项目提 ISSUE。(https://github.com/towhee-io/towhee/issues)
import towhee
dc = (
towhee.read_csv('reverse_image_search.csv') #读取 CSV 格式的表格,包含了 id,path 和 label 列
.runas_op['id', 'id'](func=lambda x: int(x)) #将每一行的 id 从 str 类型转为 int 类型
.image_decode['path', 'img']() #读取每一行 path 对应的图像,并将其解码为 Towhee 的图像格式
.image_embedding.timm['img', 'vec'](model_name='resnet50') #提取特征向量
.tensor_normalize['vec', 'vec']() #将向量进行归一化
.to_milvus['id', 'vec'](collection=collection, batch=100) #将 id 和 vec 批量 100 条插入到 Milvus 集合
)
查询图像并展示
查询图像时需要的图像处理算子与前面类似,包括image_decode,image_embedding.timm和tensor_normalize,而在最后分析检索结果时,需用到数据准备部分定义好的read_images函数,通过指定runas_op中的func将该函数加入到 Towhee 流水线中。
查询图像”流水线“的代码说明参考注释,如果你有不明白的地方,欢迎留言讨论,或者直接给 Towhee 项目提 ISSUE。
(towhee.glob['path']('./test/w*/*.JPEG') #读取满足指定模式下的所有图片数据为 path
.image_decode['path', 'img']() #读取每一行 path 对应的图像,并将其解码为 Towhee 的图像格式
.image_embedding.timm['img', 'vec'](model_name='resnet50') #提取特征向量
.tensor_normalize['vec', 'vec']() #将向量进行归一化
.milvus_search['vec', 'result'](collection=collection, limit=5) #在 Milvus 集合中搜索向量,并返回结果
.runas_op['result', 'result_img'](func=read_images) #处理 Milvus 的检索结果,最终返回图像用于展示
.select['img', 'result_img']() #选择指定列;
.show()
)
当代码执行完毕之后,我们将得到类似下面的结果。

Gradio 部署服务
Gradio⁵为机器学习模型提供 Web 演示界面,我们所熟知的 Huggingface 的 Demo 界面也是利用它实现的。Gradio 支持上传和展示图片,如图 7 所示,我们可以利用它实现一个以图搜图可交互的服务,可以在它生成的 Web 界面中上传一张图片,来查询与其相似的其他图片。
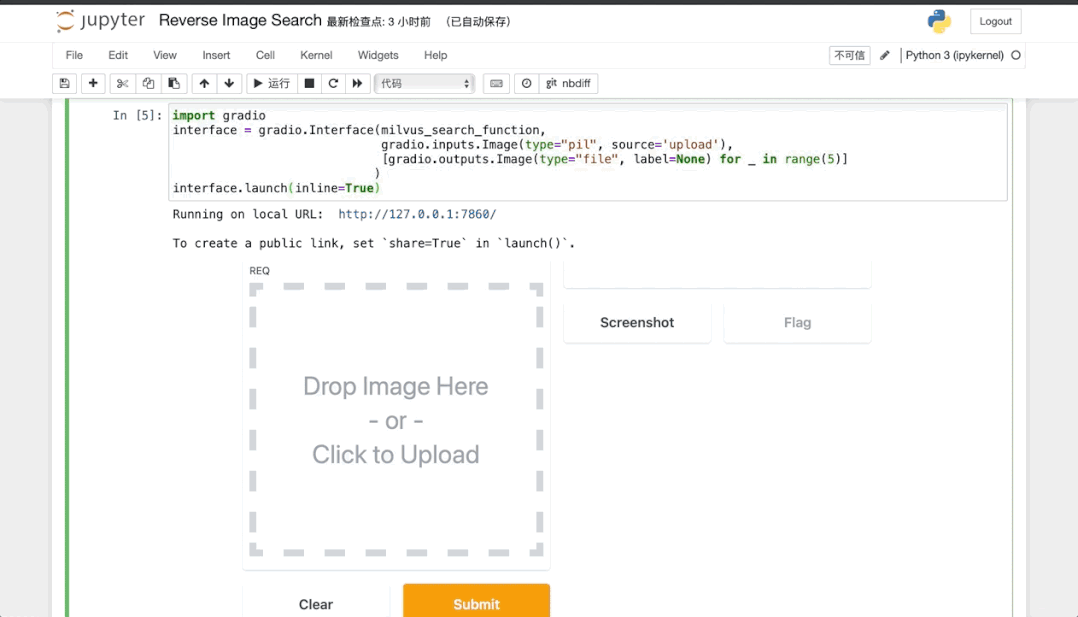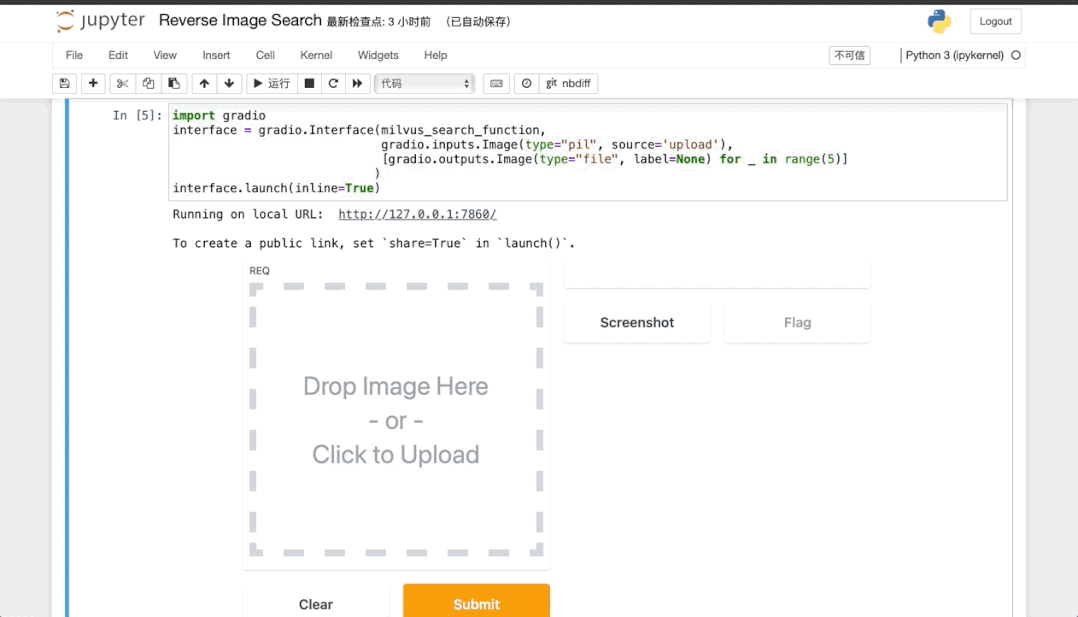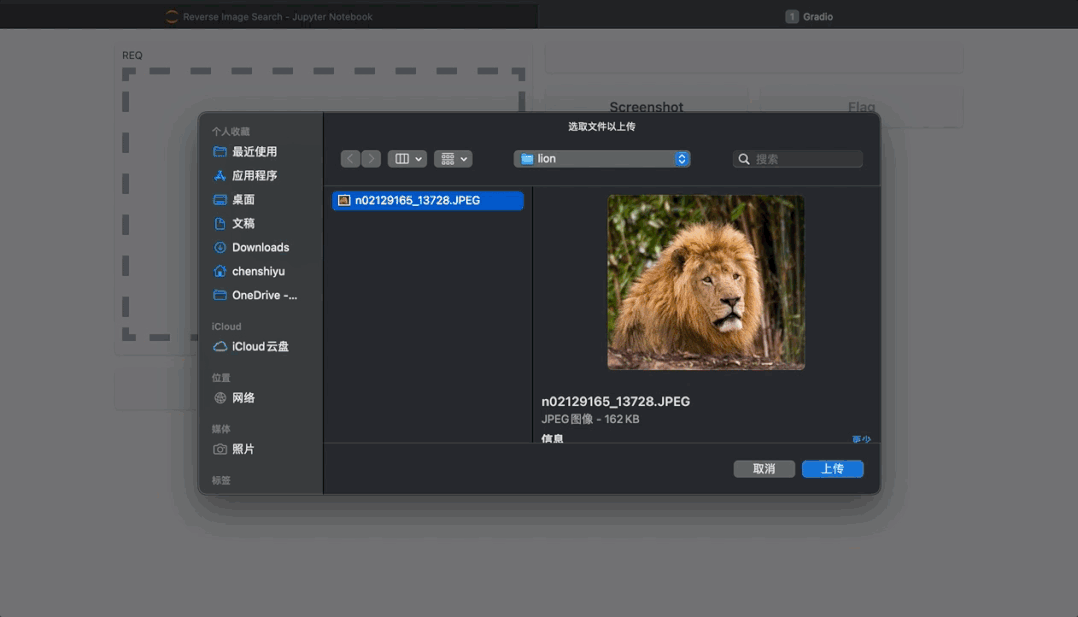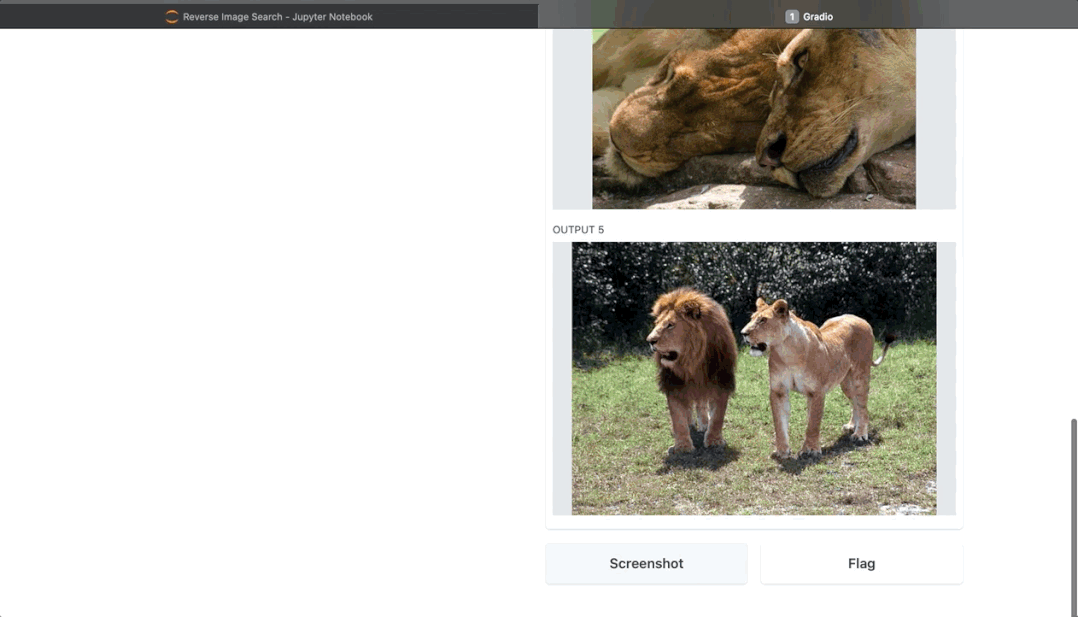
Gradio 的使用十分简单,我们只需要定义查询图片的函数image_search_function,确定其输入和输出,在创建 Gradio 服务的时候绑定函数与对应的输入输出,最后启动服务就搞定了!
import gradio
from towhee.types.image_utils import from_pil
with towhee.api() as api:
image_search_function = (
api.runas_op(func=lambda img: from_pil(img))
.image_embedding.timm(model_name='resnet50')
.tensor_normalize()
.milvus_search(collection='reverse_image_search', limit=5)
.runas_op(func=lambda res: [id_img[x.id] for x in res])
.as_function()
)
interface = gradio.Interface(image_search_function,
gradio.inputs.Image(type="pil", source='upload'),
[gradio.outputs.Image(type="file", label=None) for _ in range(5)]
)
interface.launch(inline=True)
当你成功启动了 Gradio,前端页面会嵌入到当前 notebook 中,如图 7 所示,你也可以点击 Gradio 提供的链接(http://127.0.0.1:7860)打开前端,用于查询图片并查看结果。
如果你想要把以图搜图服务和朋友分享,也可以尝试在launch函数中设置参数share=True,这时会得到一个公共网址,诸如https://xxxx.gradio.app,我们就可以把自己搭建的以图搜图服务分享给小伙伴啦。
写在最后
其实 Towhee 不仅仅能处理图片这种非结构化数据,对于音频、视频等数据也能进行分析处理,参考本文的实现,同样我们也可以 10 行代码来实现音频处理、视频处理等相关业务的 AI 服务,感兴趣的话大家可以自行尝试。
在下一篇内容中,我将介绍如何对这个系统进行调优处理,敬请期待。
参考
[1]https://zh.wikipedia.org/wiki/%E5%9C%96%E5%83%8F%E6%AA%A2%E7%B4%A2
[2]https://en.wikipedia.org/wiki/Reverse_image_search
[3]https://paperswithcode.com/sota/image-classification-on-imagenet?metric=Top%205%20Accuracy
[4]https://www.image-net.org/
[5]https://gradio.app/
更多项目更新及详细内容请关注我们的项目( https://github.com/towhee-io/towhee/blob/main/towhee/models/README_CN.md) ,您的关注是我们用爱发电的强大动力,欢迎 star, fork, slack 三连 :)
本文分享自微信公众号 - ZILLIZ(Zilliztech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
边栏推荐
猜你喜欢

机器人控制器编程整理汇总-辞旧迎新-

Toronto Research Chemicals BTK抑制剂丨ACP-5197

HarmonyOS自动化测试框架—Hypium

Xilinx FPGA收发器参考时钟设计应用
postgis空间数据导入及可视化
Live Review|How to build an enterprise-level cloud management platform in the multi-cloud era?(with the download of the construction guide)
WebRTC source code analysis nack detailed explanation

报告详解影响英特尔10/11/12代酷睿处理器的ÆPIC Leak安全漏洞

五菱宏光MINI EV,唯一的缺点就是安全性
【快应用】如何使用命令打包快应用rpk
随机推荐
多线程与高并发(五)—— 源码解析 ReentrantLock
Redis command---key chapter (super complete)
Toronto Research Chemicals霉菌毒素分析丨T2 四醇
搭载2.8K 120Hz OLED华硕好屏 无畏Pro15 2022锐龙版屏开得胜
Flexsim 发生器设置label和颜色
flex使用align-content无效
VoLTE基础自学系列 | 3GPP规范解读之Rx接口(上集)
How to choose Fengjiawei PHY62xx series?PHY6222/PHY6212/PHY6252
剖析Framework面试—>>>冲击Android高级职位
CSV(Comma-Separate-Values)逗号分隔值文件
智能安防产品公司及产品
三星Galaxy Watch5产品图片流出 非Pro表款亦有蓝宝石加持
定时器循环展示数组
#yyds干货盘点# 面试必刷TOP101:二分查找-I
企业如何通过北森HR SaaS 自动化管理员工账号生命周期
兼具外观、性能、屏幕!华硕灵耀X 14火热抢购中
测试接口出现“data“: “Full authentication is required to access this resource“凭证已过期
Scala中使用 Jackson API 进行JSON序列化和反序列化
FlexSim仿真软件入门笔记:基本操作、快捷键
【FAQ】OpenHarmony与HarmonyOS的有什么区别?