当前位置:网站首页>On the problem of cliff growth of loss function in the process of training
On the problem of cliff growth of loss function in the process of training
2022-04-23 14:13:00 【All the names I thought of were used】
The reasons for the cliff like growth of loss function in the process of training
( One ). Since the loss function is nonconvex , Setting the learning rate too large leads to jumping out of the interval of the optimal solution , We can choose an optimization algorithm that dynamically changes the learning rate , such as adam
( Two ) When the gradient explosion occurs in the training process, the loss will also increase like a cliff
Reasons for gradient explosion or disappearance
The root cause : When we take improper training methods, ah, resulting in the disappearance of the gradient in the front layer , The model will greatly adjust the parameters of the next few layers , Cause the gradient to be too large , Finally, there is a gradient explosion
Be careful : The gradient disappears in the first few layers , Gradient explosions occur in the latter layers
Solutions
Be careful : Gradient truncation method is also an important means to prevent gradient explosion
1. Select the appropriate distribution to initialize the parameters ,w Too large can easily lead to gradient explosion or disappearance , For example, use tanh When activating the function ,w To cause to z Too big , The derivative tends to 0
2. use BN The way , Make the input and output keep the same distribution as much as possible , Slowing the appearance of gradient disappearance can also avoid gradient explosion or disappearance ( Very easy to use )
3. According to the chain rule , When we w The value of is small ,a The derivative of will also be smaller ,a The smaller the derivative of the previous layer w The smaller the gradient , So we can use L1、L2 Regularization to slow down the gradient explosion
4. Choose the appropriate activation function ,relu Is the most commonly used activation function
5. When the effect is similar , The simpler the neural network is, the less prone it is to gradient explosion and gradient disappearance
版权声明
本文为[All the names I thought of were used]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231404419479.html
边栏推荐
猜你喜欢

金融行业云迁移实践 平安金融云整合HyperMotion云迁移解决方案,为金融行业客户提供迁移服务
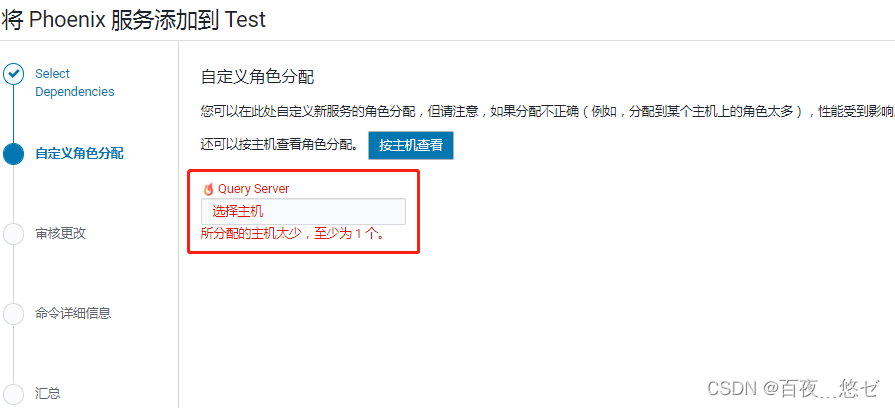
Intégration de Clusters CDH Phoenix basée sur la gestion cm
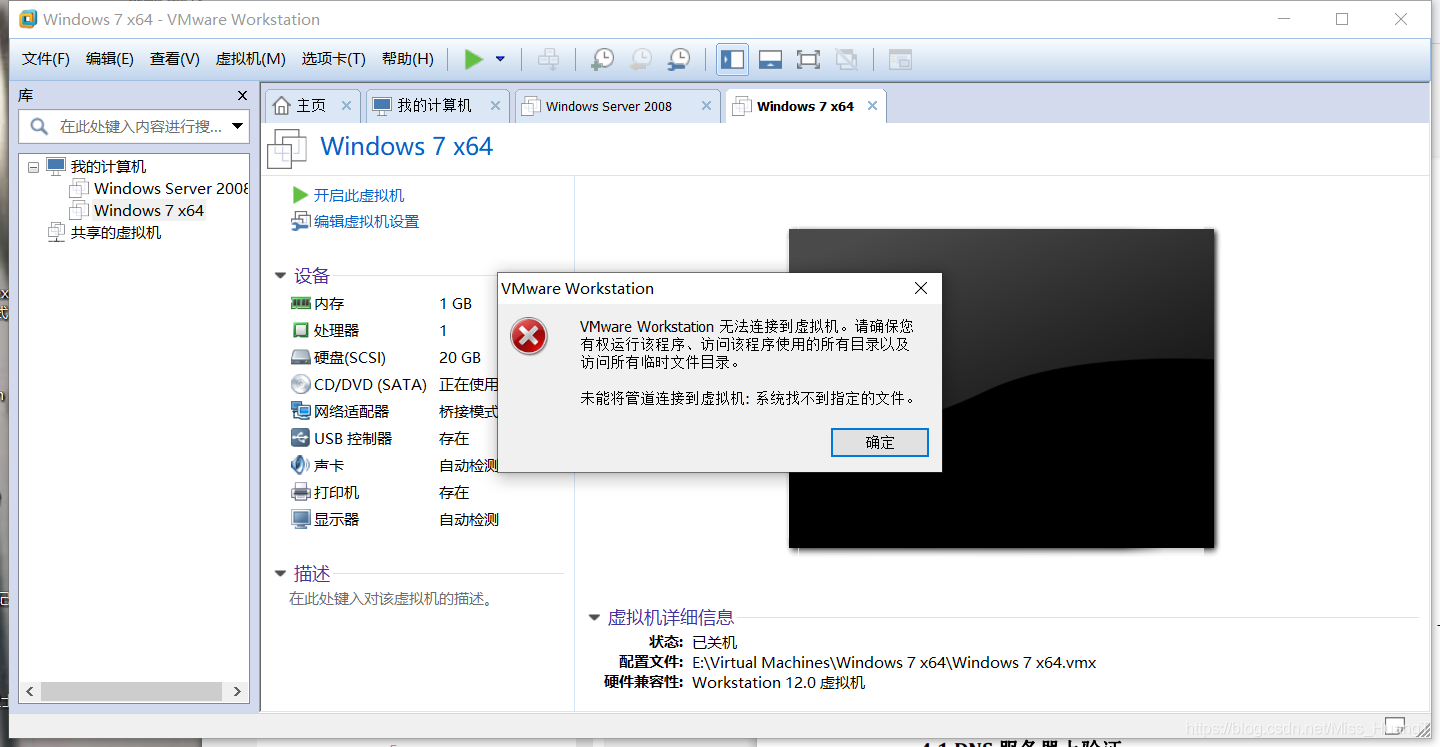
VMware Workstation 无法连接到虚拟机。系统找不到指定的文件
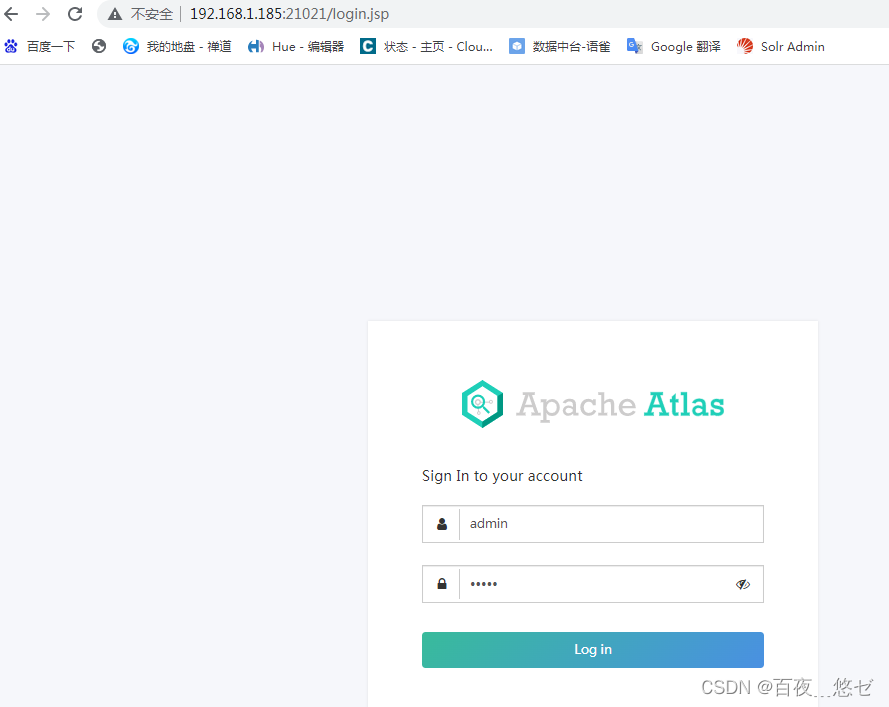
Cdh6 based on CM management 3.2 cluster integration atlas 2 one

多云数据流转?云上容灾?年前最后的价值内容分享

HyperMotion云迁移助力中国联通,青云完成某央企上云项目,加速该集团核心业务系统上云进程
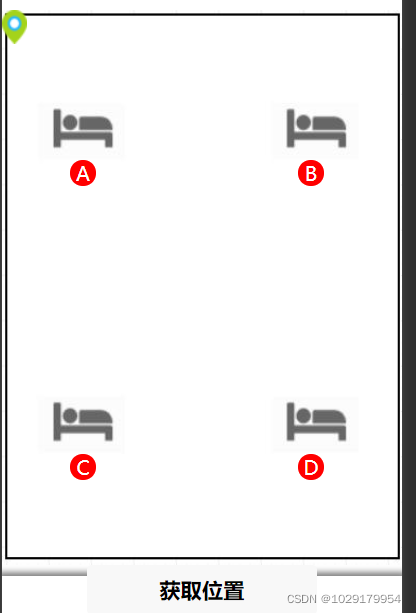
Indoor and outdoor map switching (indoor three-point positioning based on ibeacons)
Visio installation error 1:1935 2: {XXXXXXXX
VMware15Pro在Deepin系统里面挂载真机电脑硬盘
Some experience of using dialogfragment and anti stepping pit experience (getactivity and getdialog are empty, cancelable is invalid, etc.)
随机推荐
帆软报表设置单元格填报以及根据值的大小进行排名方法
关于云容灾,你需要知道这些
On the multi-level certificate based on OpenSSL, the issuance and management of multi-level Ca, and two-way authentication
星界边境Starbound创意工坊订阅的mod的存放路径
Idea控制台乱码解决
Three point positioning based on ibeacons (wechat applet)
mysql 5.1升级到5.69
困扰多年的系统调研问题有自动化采集工具了,还是开源免费的
Operation instructions of star boundary text automatic translator
DeepinV20安装Mariadb
基于CM管理的CDH6.3.2集群集成Atlas2.1.0
回顾2021:如何帮助客户扫清上云最后一公里的障碍?
logback-logger和root
On September 8, the night before going to Songshan Lake
基于ibeacons签到系统
帆软中需要设置合计值为0时,一整行都不显示的解决办法
Prediction of tomorrow's trading limit of Low Frequency Quantization
帆软中使用if else 进行判断-使用标题条件进行判断
云迁移的六大场景
微信小程序的订阅号开发(消息推送)