当前位置:网站首页>pytorch调整模型学习率
pytorch调整模型学习率
2022-08-11 05:35:00 【Pr4da】
目录
1.定义衰减函数
定义learning rate衰减方式:
L R e p o c h = L R 0 × 0. 8 e p o c h + 1 10 LR_{epoch}=LR_{0}\times 0.8^{\frac{epoch+1}{10}} LRepoch=LR0×0.810epoch+1
import matplotlib.pyplot as plt
from torch import nn
import math
from torch import optim
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.net = nn.Linear(10,10)
def forward(self, input):
out = self.net(input)
return out
learning_rate = 1e-3
L2_DECAY = 5e-4
MOMENTUM = 0.9
def step_decay(epoch, learning_rate):
""" Schedule step decay of learning rate with epochs. """
initial_learning_rate = learning_rate
drop = 0.8
epochs_drop = 10.0
learning_rate = initial_learning_rate * math.pow(drop, math.floor((1 + epoch) / epochs_drop))
return learning_rate
model = Net()
LR = 0.01
lr_list = []
for epoch in range(100):
current_lr = step_decay(epoch, learning_rate)
optimizer = torch.optim.SGD(model.parameters(), lr=current_lr)
lr_list.append(current_lr)
plt.plot(range(100), lr_list, color = 'r')
plt.show()
绘出的lr更新曲线如下所示: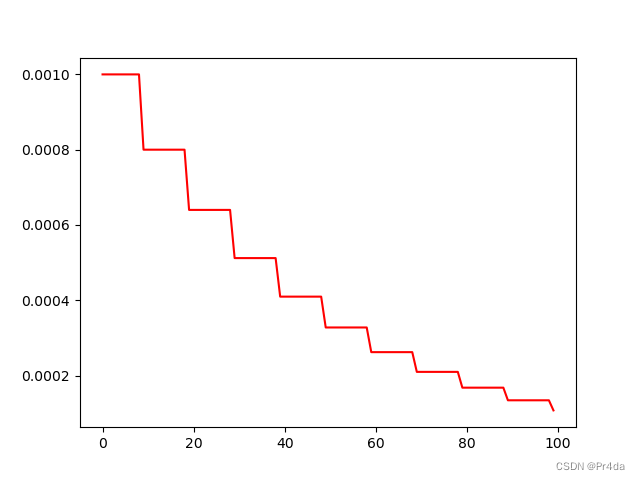
2. 手动修改optinmizer中的lr
import matplotlib.pyplot as plt
from torch import nn
import torch
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.net = nn.Linear(10,10)
def forward(self, input):
out = self.net(input)
return out
model = Net()
LR = 0.01
optimizer = torch.optim.Adam(model.parameters(), lr = LR)
lr_list = []
for epoch in range(100):
if epoch % 5 == 0:
for p in optimizer.param_groups:
p['lr'] *= 0.9 # 学习率调整为原来的0.9
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100), lr_list, color = 'r')
plt.show()
学习率每个epoch变为原来的0.9,衰减曲线如下图所示: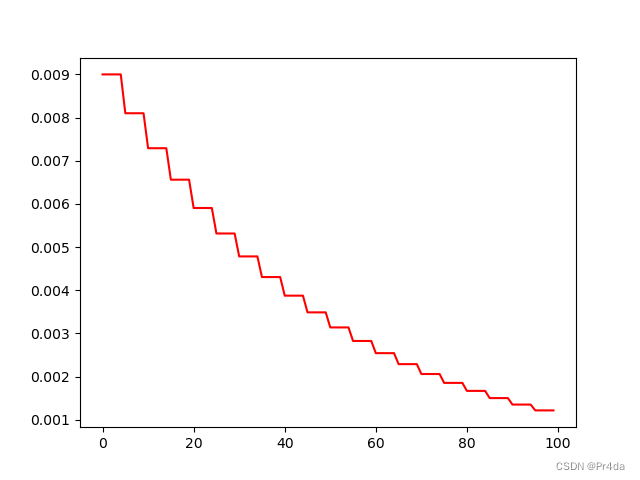
Pytorch中给了很多学习率衰减的函数,我们不需要自己定义也可以动态调整学习率。
3. lr_scheduler.LambdaLR
如何在pytorch中调整lr具体请参考Pytorch文档How to adjust learning rate
CLASS torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
import numpy as np
import torch
from torch import nn
import matplotlib.pyplot as plt
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.net = nn.Linear(10,10)
def forward(self, input):
out = self.net(input)
return out
model = Net()
lr_list = []
LR = 0.01
optimizer = torch.optim.Adam(model.parameters(), lr = LR)
lambda1 = lambda epoch: 0.95 ** epoch
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer,lr_lambda = lambda1)
for epoch in range(100):
optimizer.zero_grad() # clear previous gradients
optimizer.step() # performs updates using calculated gradients
scheduler.step() # update lr
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')
plt.show()
学习率衰减如图所示: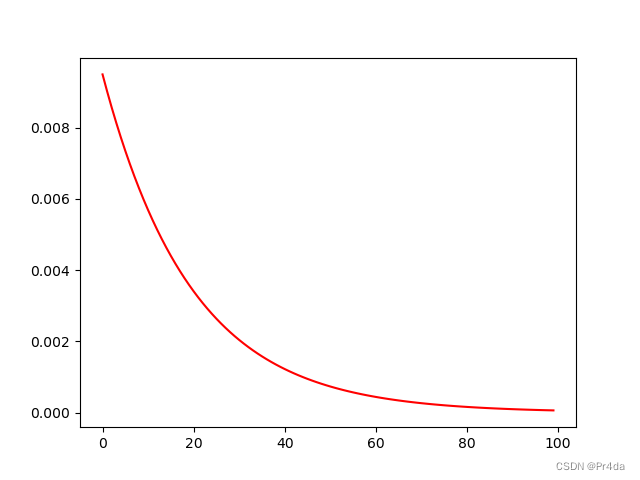
4. lr_scheduler.StepLR
CLASS torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False)
- step_size: lr的衰减步长
- gamma: lr衰减的乘法因子
每隔step_size个epoch,学习率变为原来的gamma,例如,step_size设置为30,初始学习率设置为0.05,学习率变化如下所示:
>>> # Assuming optimizer uses lr = 0.05 for all groups
>>> # lr = 0.05 if epoch < 30
>>> # lr = 0.005 if 30 <= epoch < 60
>>> # lr = 0.0005 if 60 <= epoch < 90
>>> # ...
>>> scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
import numpy as np
import torch
from torch import nn
import matplotlib.pyplot as plt
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.net = nn.Linear(10,10)
def forward(self, input):
out = self.net(input)
return out
model = Net()
lr_list = []
LR = 0.01
optimizer = torch.optim.Adam(model.parameters(), lr = LR)
lambda1 = lambda epoch: 0.95 ** epoch
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma = 0.8)
for epoch in range(100):
optimizer.zero_grad() # clear previous gradients
optimizer.step() # performs updates using calculated gradients
scheduler.step() # update lr
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')
plt.show()
学习率衰减曲线如下所示: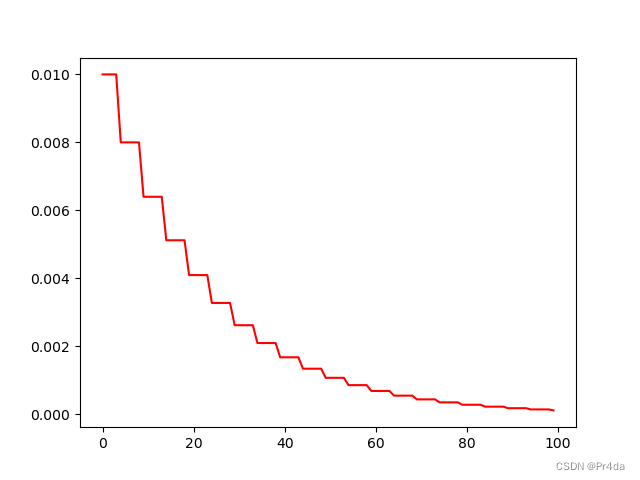
5. lr_scheduler.ExponentialLR
CLASStorch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=- 1, verbose=False)
- gamma: 学习率衰减乘数因子
import numpy as np
import torch
from torch import nn
import matplotlib.pyplot as plt
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.net = nn.Linear(10,10)
def forward(self, input):
out = self.net(input)
return out
model = Net()
lr_list = []
LR = 0.01
optimizer = torch.optim.Adam(model.parameters(), lr = LR)
lambda1 = lambda epoch: 0.95 ** epoch
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer,gamma = 0.8)
for epoch in range(100):
optimizer.zero_grad() # clear previous gradients
optimizer.step() # performs updates using calculated gradients
scheduler.step() # update lr
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')
plt.show()
学习率曲线如下图所示: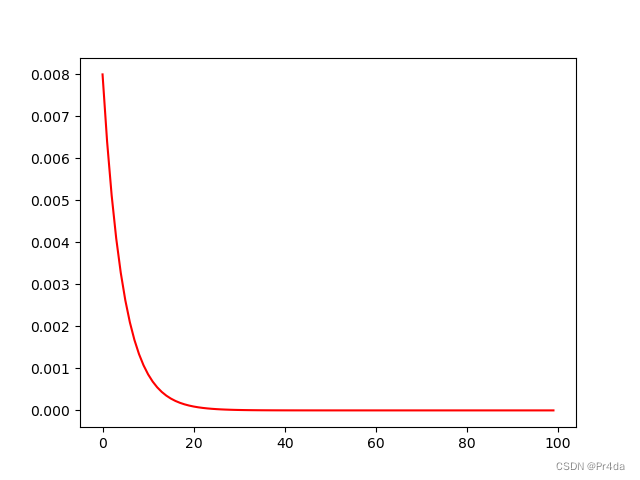
注意,如果相打印每一个epoch的当前学习率,官网中说的方法是调用
print_Lr(),但实际上pytorch中并没有该方法,我们需要使用get_last_lr()方法才能打印每一个epoch的学习率。
更多学习率调整方法的介绍可以参考文档.
References:
[1] https://github.com/agrija9/Deep-Unsupervised-Domain-Adaptation/tree/master/DDC
[2] Pytorch学习率lr衰减(decay)(scheduler)
边栏推荐
- 八股文之mysql
- ETCD containerized to build a cluster
- ETCD Single-Node Fault Emergency Recovery
- TOP2两数相加
- (2) Software Testing Theory (*Key Use Case Method Writing)
- CLUSTER DAY01(集群及LVS简介 、 LVS-NAT集群 、 LVS-DR集群)
- OA项目之会议通知(查询&是否参会&反馈详情)
- ansible batch install zabbix-agent
- HCIP BGP built adjacent experiment
- 华为防火墙会话 session table
猜你喜欢
MoreFileRename batch file renaming tool
window7开启远程桌面功能
VMware workstation 16 installation and configuration
Top20括号匹配
arcgis填坑_2
Solve win10 installed portal v13 / v15 asked repeatedly to restart problem.
HCIA实验

查看可执行文件依赖的库ldd
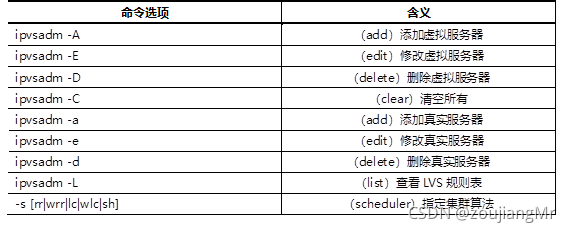
CLUSTER DAY01 (Introduction to cluster and LVS, LVS-NAT cluster, LVS-DR cluster)
OA项目之待开会议&历史会议&所有会议
随机推荐
arcmap下的多进程脚本
MoreFileRename批量文件改名工具
MoreFileRename batch file renaming tool
vnc remote desktop installation (available for personal testing on 2021-10-20)
SECURITY DAY01(监控概述 、 Zabbix基础 、 Zabbix监控服 )
SECURITY DAY04( Prometheus服务器 、 Prometheus被监控端 、 Grafana 、 监控数据库)
HCIP-BGP的选路实验
【LeetCode】1036. 逃离大迷宫(思路+题解)压缩矩阵+BFS
Solve the problem that port 8080 is occupied
(2) Software Testing Theory (*Key Use Case Method Writing)
Numpy_备注
照片的35x45,300dpi怎么弄
China Mobile Communications Group Co., Ltd.: Business Power of Attorney
华为防火墙-4-安全策略
ramdisk实践1:将根文件系统集成到内核中
OA项目之项目简介&会议发布
SECURITY DAY06 ( iptables firewall, filter table control, extended matching, typical application of nat table)
HCIP BGP built adjacent experiment
SECURITY DAY05 (Kali system, scanning and caught, SSH basic protection, service SECURITY)
buildroot嵌入式文件系统中vi显示行号