当前位置:网站首页>ETCD单节点故障应急恢复
ETCD单节点故障应急恢复
2022-08-11 05:32:00 【!&君子九思&!】
系列文章目录
前言
生产环境中,经常遇到etcd集群出现单节点故障或者集群故障。针对这两种情况,进行故障修复。本文介绍etcd的单节点故障时,故障应急的恢复手册
一、总体恢复流程
由于etcd的raft协议,整个集群能够容忍的故障节点数为(n-1)/ 2,因此在单个节点故障时,单个集群的仍然可用,不会影响业务的读写。
整体的恢复流程如下
二、详细恢复指导
2.1 环境信息
使用本地的vmstation创建3个虚拟机,信息如下
| 节点名称 | 节点IP | 节点配置 | 操作系统 | Etcd版本 | Docker版本 |
|---|---|---|---|---|---|
| etcd1 | 192.168.82.128 | 1c1g 20g | CentOS7.4 | v3.5 | 13.1 |
| etcd2 | 192.168.82.129 | 1c1g 20g | CentOS7.4 | v3.5 | 13.1 |
| etcd3 | 192.168.82.130 | 1c1g 20g | CentOS7.4 | v3.5 | 13.1 |
假设etcd2节点异常,并且本地的数据已经损坏。
2.2 集群删除异常节点
通过member remove命令删除异常节点,此时整个集群只有2个节点,不会触发master重新选主,集群正常运行。
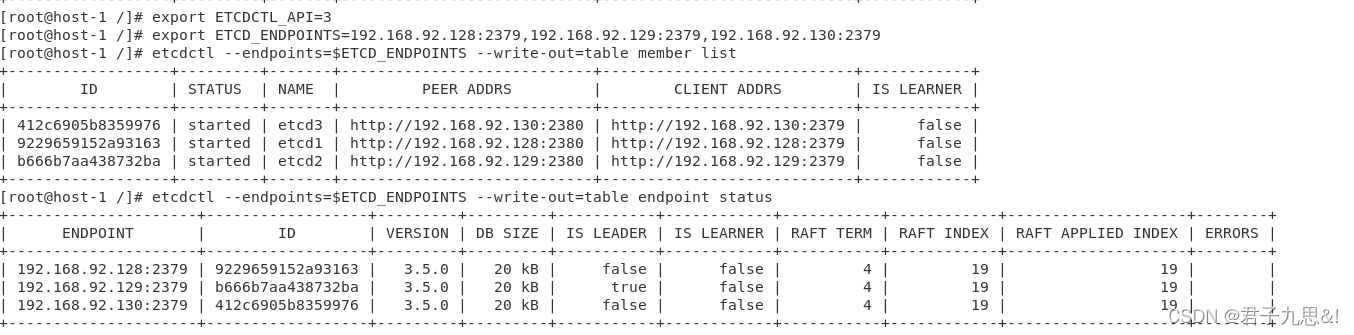
查看当前集群状态
export ETCDCTL_API=3
export ETCD_ENDPOINTS=192.168.92.128:2379,192.168.92.129:2379,192.168.92.130:2379
etcdctl --endpoints=$ETCD_ENDPOINTS --write-out=table member list
etcdctl --endpoints=$ETCD_ENDPOINTS --write-out=table endpoint status
2.2 删除异常节点数据
2.2.1 删除异常member
docker stop etcd2
2.2.2 删除数据
由于数据通过-v /data/etcd:/data/etcd的方式挂载,因此删除对应的数据,会清理etcd数据。
rm -rf /data/etcd/*
2.3 集群重新添加节点
通过如下命令,将异常节点添加到集群中,等对应的节点启动后,就会自动完成集群数据同步和选主
export ETCDCTL_API=3
export ETCD_ENDPOINTS=192.168.92.128:2379,192.168.92.129:2379,192.168.92.130:2379
etcdctl --endpoints=$ETCD_ENDPOINTS member add etcd2 --peer-urls=http://192.168.92.129:2380

2.4 启动节点
2.4.1 完整的启动脚本为
[[email protected] ~]#
[[email protected] ~]# cat start_etcd.sh
/bin/sh
name="etcd2"
host="192.168.92.129"
cluster="etcd1=http://192.168.92.128:2380,etcd2=http://192.168.92.129:2380,etcd3=http://192.168.92.130:2380"
docker run -d --privileged=true -p 2379:2379 -p 2380:2380 -v /data/etcd:/data/etcd --name $name --net=host quay.io/coreos/etcd:v3.5.0 /usr/local/bin/etcd --name $name --data-dir /data/etcd --listen-client-urls http://$host:2379 --advertise-client-urls http://$host:2379 --listen-peer-urls http://$host:2380 --initial-advertise-peer-urls http://$host:2380 --initial-cluster $cluster --initial-cluster-token tkn --initial-cluster-state existing --log-level info --logger zap --log-outputs stderr
注意,由于etcd的数据已经被删除,因此当前节点重启时,从其他的节点获取数据,因此需要调整参数–initial-cluster-state,从new改成existing
--initial-cluster-state existing
2.4.2 查看日志
docker logs 8bf31834f8ce
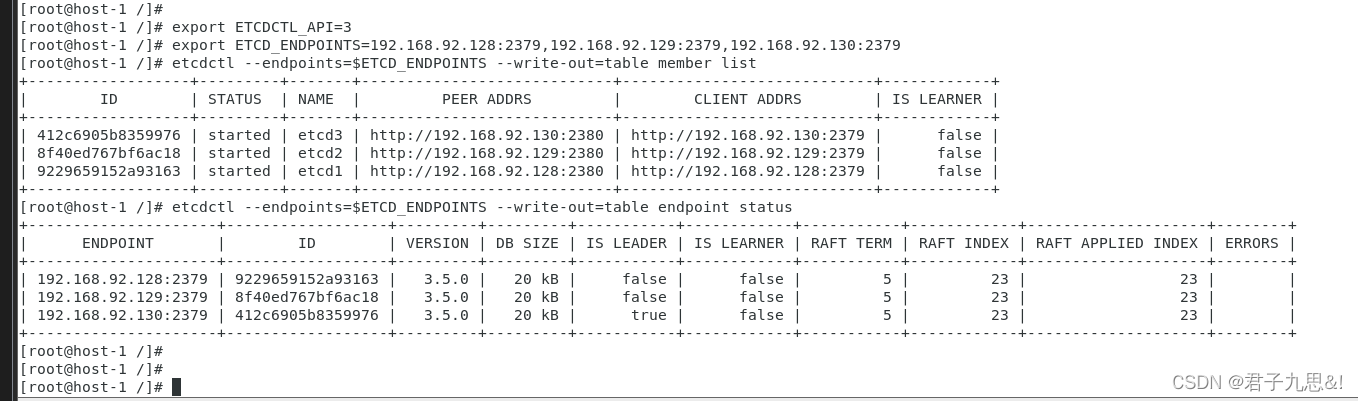
2.4 等待集群数据完成同步并恢复
查看当前集群的member信息
export ETCDCTL_API=3
export ETCD_ENDPOINTS=192.168.92.128:2379,192.168.92.129:2379,192.168.92.130:2379
etcdctl --endpoints=$ETCD_ENDPOINTS --write-out=table member list
etcdctl --endpoints=$ETCD_ENDPOINTS --write-out=table endpoint status
总结
由于整体集群有多副本,因此单节点异常时,并不会导致整个集群异常,只要正常启动对应的节点并同步数据即可恢复。
边栏推荐
猜你喜欢





随机推荐
【LeetCode-49】字母异位词分组
【LeetCode-389】找不同
Unity的程序集Assembly 与 加快代码编译速度
无胁科技-TVD每日漏洞情报-2022-7-29
无胁科技-TVD每日漏洞情报-2022-7-31
【LeetCode-350】两个数组的交集II
勒索病毒eking.devos.mkp.makop.lockbit.eight.locked.roger等剖析及中毒文件恢复
文本三剑客——awk 截取+过滤+统计
mongo-express 远程代码执行漏洞复现
Two hundred questions in C language (0 basic continuous update) (1~5)
C语言两百题(0基础持续更新)(1~5)
CLR via C# 第一章 CLR的执行模型
IP证书申请
VMware workstation 16 安装与配置
中小微企业需要使用SSL证书吗?
Threatless Technology-TVD Daily Vulnerability Intelligence-2022-7-27
C# 基础之字典——Dictionary(一)
(一)软件测试理论(0基础了解基础知识)
Threatless Technology-TVD Daily Vulnerability Intelligence-2022-7-28
软件使用代码签名证书的好处和必要性