当前位置:网站首页>REINFORCE
REINFORCE
2022-04-23 02:56:00 【Live up to your youth】
Basic concepts
The goal of reinforcement learning problem is to perform a series of appropriate actions according to the strategy to maximize the cumulative return . Reinforcement learning algorithms are mainly divided into three categories : The method based on value function 、 A policy based approach and a combination of the two . in other words , It can be reused by approximating the value function ϵ − g r e e d y \epsilon-greedy ϵ−greedy Strategy indirectly determines the strategy , You can also create a policy function , Parameterize the policy , We can also combine these two methods to learn value function , Learning strategies .
REINFORCE
REINFORCE It's a policy based algorithm . The strategy gradient method is used to parameterize the strategy , In the strategy gradient method , Policies often use a set of parameters θ \theta θ The functional representation of : π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s), Solve the update strategy parameter set θ \theta θ That is, the calculation process of the strategic gradient method . The goal of the strategy gradient method is to find the optimal θ \theta θ, Make the objective function ( Also called loss function ) Be able to maximize the expected return , The return value here is the sum of the returns from the initial state to the end state .
First, consider the one-step Markov decision process (MDP) Policy gradient . In this issue , Assuming that state s Obey the distribution d(s), End after one time step , Get paid r=r(s,a). Then the target function is :

To maximize the objective function J ( θ ) J(\theta) J(θ), The gradient rise method is used to solve the problem :
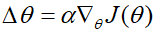
among α \alpha α It's the step length , And the strategy gradient is :

In multiple steps MDP In the calculation formula of strategy gradient , use Q- Value function q π ( s , a ) q_\pi(s,a) qπ(s,a) Replace r ( s , a ) r(s,a) r(s,a), Which is equivalent to one step MDP A generalization of the gradient calculation formula . therefore , Parameters θ \theta θ The learning formula is :

REINFORCE The pseudo code of the algorithm is shown in the figure below , Return on use v t v_t vt Instead of Q- Value function q π ( s , a ) q_\pi(s,a) qπ(s,a).

REINFORCE with Baseline
In multiple steps MDP Environment , The return on each step will have a high variance . If the baseline function is subtracted from the objective function when defining the objective function B(s), It can reduce the variance without changing the overall expectation , This will make the training process more stable . At this time there is :
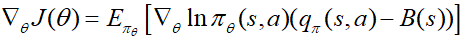
under these circumstances , Parameters θ \theta θ The update method of is :

版权声明
本文为[Live up to your youth]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204220657127048.html
边栏推荐
- JZ76 删除链表中重复的结点
- Sonic cloud real machine tutorial
- Winsock programming interface experiment: Ping
- How to use C language to realize [guessing numbers game]
- The shell monitors the depth of the IBM MQ queue and scans it three times in 10s. When the depth value exceeds 5 for more than two times, the queue name and depth value are output.
- Traversal of l2-006 tree (middle and later order determination binary tree & sequence traversal)
- Machine learning (Zhou Zhihua) Chapter 14 probability graph model
- VirtualBox virtual machine (Oracle VM)
- Jz76 delete duplicate nodes in linked list
- BLDC double closed loop (speed PI + current PI) Simulink simulation model
猜你喜欢

基于多态的职工管理系统源码与一些理解

1215_ Hello world used by scons

Machine learning (Zhou Zhihua) Chapter 14 probability graph model

Specific field information of MySQL export table (detailed operation of Navicat client)

Cloud computing learning 1 - openstack cloud computing installation and deployment steps with pictures and texts (Xiandian 2.2)
Innovation and management based on Scrum
Source code and some understanding of employee management system based on polymorphism
![Introduction to ACM [inclusion exclusion theorem]](/img/3a/9bc2a972d7587aab51fceb8cd2b9bd.png)
Introduction to ACM [inclusion exclusion theorem]

Solve the problem that PowerShell mining occupies 100% of cpu7 in win7

Domestic lightweight Kanban scrum agile project management tool
随机推荐
基于Scrum进行创新和管理
[unity3d] rolling barrage effect in live broadcasting room
Linux redis - redis ha sentinel cluster construction details & redis master-slave deployment
Machine learning (Zhou Zhihua) Chapter 14 probability graph model
ele之Table表格的封装
Solve the problem that PowerShell mining occupies 100% of cpu7 in win7
MySQL complex query uses temporary table / with as (similar to table variable)
Kubernetes study notes
[wechat applet] set the bottom menu (tabbar) for the applet
Linux Redis ——Redis HA Sentinel 集群搭建详解 & Redis主从部署
Chapter IV project cost management of information system project manager summary
First knowledge of C language ~ branch statements
《信息系統項目管理師總結》第六章 項目人力資源管理
[learn junit5 from official documents] [II] [writingtests] [learning notes]
JZ22 鏈錶中倒數最後k個結點
The input of El input input box is invalid, and error in data(): "referenceerror: El is not defined“
Interim summary (Introduction + application layer + transportation layer)
Actual combat of industrial defect detection project (IV) -- ceramic defect detection based on hrnet
Win view port occupation command line
【工欲善其事必先利其器】论文编辑及文献管理(Endnote,Latex,JabRef ,overleaf)资源下载及使用指南