当前位置:网站首页>XML file input of Chapter 13 of kettle paoding jieniu
XML file input of Chapter 13 of kettle paoding jieniu
2022-04-22 18:52:00 【Feige big data】
introduction
In the last article , We introduced :CSV Various detailed settings of the file input component , The actual combat demonstrates how to operate it to read the data on the disk CSV file . Finally, it expanded , Use the text file input component to read... On disk CSV file .
In this article , Let's go on to introduce :kettle Medium XML File input component (Get data from XML).
To learn to understand XML File input component , We're going to expand our conversation XML and XPath What happened .
XML Those things
a、 summary
Xml A markup language used to mark electronic documents to make them structured , Can be used to tag data 、 Define data types , Is a source language that allows users to define their own markup language .Xml It's a standard universal markup language (SGML) Subset , Very suitable Web transmission .XML Provides a unified way to describe and exchange structured data independent of the application or vendor .
In a word :xml Itself is a format specification , Is a text format specification that includes data and data description .
b、 Illustrate with examples
I want to transmit a piece of data to each other , The content is " Big Feige , Data architect ,88 year ". Split this paragraph into three data according to attributes , nickname : Big Feige , position : Data architect , The year of birth :88 year .
Programs are not like people , It can't literally , And automatically split the data . It needs human help to split the program , Therefore, there are various data formats and splitting methods .
(1)、 situation 1
The data is " Big Feige , Data architect ,88 year "
according to “,” Split , The first part is the nickname , The second part is the position , The third part is the age of birth .
(2)、 situation 2
The data is " Big Feige * Data architect *88 year "
according to “*” Split , The first part is the nickname , The second part is the position , The third part is the age of birth .
summary
Both methods can be used to hold data and can be parsed , But it's not intuitive , Versatility is not good , And if there is a string that exceeds the limited number of words, it can't hold , It is also possible that the data itself contains special characters , You also need to escape .
Based on this situation , There is xml This data format , The above data is used XML What they say , It will be much clearer .
(1)、xml How to write it 1
<person nickname=" Big Feige " title=" Data architect " birth="88 year "></person >
(2)、xml How to write it 2
<person>
<nickname value=" Big Feige "></nickname>
<title value=" Data architect "></title>
<birth value="88 year "></birth>
</person>
(3)、 Storage structure
A tree structure

xml Statement
xml Statements are generally xml The first line of the document ,xml The declaration consists of the following 2 Component composition :version and encoding
Example :<?xml version="1.0" encoding="UTF-8"?>
Root element
Whole XML In file , There is and only one root element . It is XML In file , The first is the beginning \ The last tag pair . In the following data ,person It's the root element .
<person> ----------- In the beginning
<nickname value=" Big Feige "></nickname>
<title value=" Data architect "></title>
<birth value="88 year "></birth>
</person> --------- At the end of the day
Elements
grammar :< The element tag > Content </ The element tag >
(1) be-all xml Every element must have an end tag ;
<title> Data architect </title>
(2)xml Tags are case sensitive ;
correct :<title> Data architect </title>
error :<Title> Data architect </title>
(3)xml You have to nest... Correctly ;
correct :<title><birth> Data architect </birth></title>
error :<title><birth> Data architect </title></birth>
(4) Naming rules for elements :
The name can contain letters 、 Numbers or other characters ;
Names cannot begin with numbers or punctuation ;
The name cannot contain spaces .
(5) Empty elements
<nickname></nickname>
<title></title>
<birth></birth>
attribute
(1)、 grammar
< Element name Property name =" Property value "/>
Examples are as follows :
<person>
<nickname value=" Big Feige "/>
<title value=" Data architect "/>
<birth value="88 year "/>
</person>
(2)、 Be careful
Attribute values are wrapped in double quotation marks ; An element can have multiple attributes , Its basic format is :
< Element name Property name =" Property value " Property name =" Property value ">
Property values cannot contain <.",&.
xml Parsing
Constant XML Analytical techniques include 3 Kind of :SAX analysis XML、DOM analysis XML、Pull analysis XML
A comparison of technologies
Memory footprint :SAX、Pull Than DOM It is better to ;
programmatically :SAX Use event driven , When the corresponding event is triggered , Will call the method prepared by the user , That is to say, every kind of XML, It is necessary to write a new one suitable for this class XML The processing of the class .DOM yes W3C The specification of ,Pull concise .
Access and modify :SAX Flow analysis is adopted ,DOM Random access .
access :SAX,Pull The parsing method is synchronous ,DOM Word for word
XPath expression
XPath( Full name :XML Path Language) namely XML Path to the language , It's a door in XML The language in which information is found in a document , Originally used to search XML file , At the same time, it is also suitable for searching HTML file .
Multiple types of nodes
XPath Various types of nodes are provided , Common nodes are : Elements 、 attribute 、 Text 、 Comments and document nodes . As shown below :
<?xml version="1.0" encoding="utf-8"?>
<website>
<site>
<title lang="zh-CN">website name</title>
<name> Programming help </name>
<year>2010</year>
<address>www.biancheng.net</address>
</site>
</website>
above XML Examples of nodes in the document :
<website></website> ( Document nodes )
<name></name> ( Element nodes )
lang="zh-CN" ( Attribute node )
Node relationship
XML The node relationship and HTML Document similarity , There is also a father 、 Son 、 The same generation 、 Forefathers 、 Next generation nodes . As shown below :
<?xml version="1.0" encoding="utf-8"?>
<website>
<site>
<title lang="zh-CN">website name</title>
<name> Programming help </name>
<year>2010</year>
<address>www.biancheng.net</address>
</site>
</website>
After the analysis of the above example , We will get the following results :
title name year address All are site Child nodes of
site yes title name year address Parent node
title name year address Nodes of the same generation
title The ancestor node of the element is site website
website The descendant node of is site title name year address
Basic grammar uses
Xpath Use path expressions to select nodes in the document , The following table lists the common expression rules
expression |
describe |
node_name |
Select all children of this node . |
/ |
Absolute path matching , Select from root node . |
// |
Relative path matching , Find the currently selected node from all nodes , Including child nodes and descendant nodes , Its first / Represents the root node . |
. |
Select the current node . |
.. |
Select the parent of the current node . |
@ |
Select the attribute value , Select data by attribute value . Common element attributes are @id 、@name、@type、@class、@tittle、@href.: |
xpath wildcard
Xpath The wildcard of the expression can be used to select unknown node elements , The basic grammar is as follows
wildcard |
Description |
* |
Match any element node |
@* |
Match any attribute node |
node() |
Match any type of node |
Xpath Built-in functions
Xpath Provide 100 Multiple built-in functions , These functions provide us with a lot of convenience , For example, to achieve text matching 、 Fuzzy matching 、 And location matching , Here are some common built-in functions .
The name of the function |
xpath Examples of expressions |
example |
text() |
./text() |
Text matching , The representation value takes the text content in the current node . |
contains() |
//div[contains(@id,'stu')] |
Fuzzy matching , Express choice id Contained in the “stu” All of the div node . |
last() |
//*[@class='web'][last()] |
Position matching , Express choice @class='web' The last node of . |
position() |
//*[@class='site'][position()<=2] |
Position matching , Express choice @class='site' The first two nodes of . |
start-with() |
"//input[start-with(@id,'st')]" |
matching id With st Elements at the beginning . |
ends-with() |
"//input[ends-with(@id,'st')]" |
matching id With st Ending element . |
concat(string1,string2) |
concat('C Chinese language network ',.//*[@class='stie']/@href) |
C Chinese language and tag Category attribute are "stie" Of href Address splicing . |
transformation
transformation (transaformation) yes ETL The main part of the solution , It handles extraction 、 transformation 、 Loading various operations on data lines .
Create transformations
What we have to do ETL operation , It's all designed in transformation , So we need to create a transformation first .
Save conversion
Give you a new conversion , Name it , And save


XML File input
This component can realize , From the specified XML File input data .


a、 The file specified
1、 The file label specifies the data source file , Click on “ Browse ” Button , Browse local xml file . Click on " increase " Button , You can add a file to " Select File " in , As shown below :




The option configuration in this part is similar to that of the text file input component , No more detailed explanation .
b、 Content

Option description
Options |
describe |
Loop read path |
refer to xml Hierarchy in file |
code |
refer to xml The character encoding type of the file |
Consider the namespace |
Check this item to identify XML Document namespace |
Ignore comments |
Ignore... When parsing XML All comments in the document |
verification XML |
Verify... Before parsing XML |
Ignore empty files |
The file is empty and no data is read |
Don't report errors without documentation |
If no files are found , Please don't make mistakes . |
Limit |
Limit output lines |
Used to intercept data XML route ( A large file ) |
And loop read path Is essentially the same , Related to processing big data |
The output includes the file name |
Every line of data read in , There is one more field column ,xml The absolute path of |
The output includes line numbers |
Display row number , Is an incremental column |
Add the file to the result file |
After being referenced in a transformation , Will save the name of the file to memory , And then the next one job Or convert to reference |
c、 Field

Option description
Options |
describe . |
name |
Set the name of the field to be displayed in the output stream . |
XML route |
The path of the element node or attribute to be read |
node |
The type of element to read : Node or attribute |
Result Type |
Field type (String、Date、Number etc. ). |
Format |
Controls the format of input data ( Integers 、 There are decimal places 、 Date format, etc ) |
length |
about Number: Number of significant numbers . about String: The length of the characters . about Date: The length of the printout character ( for example 4 Represents the year of return ). |
precision |
about Number: Number of floating point numbers . about String,Date,Boolean: not used . |
Currency symbols |
Used to explain, for example $10,000.00 The number of . |
Decimal symbol |
The decimal point can be ”.”(10;000.00) perhaps ”,”(5.000,00). |
Group |
Grouping can be ”.”(10;000.00) perhaps ”,”(5.000,00). |
Empty string |
Empty before processing . |
repeat |
Y/N: If the corresponding value in the current line is empty , Repeat the last non empty value . |
d、 Other output fields
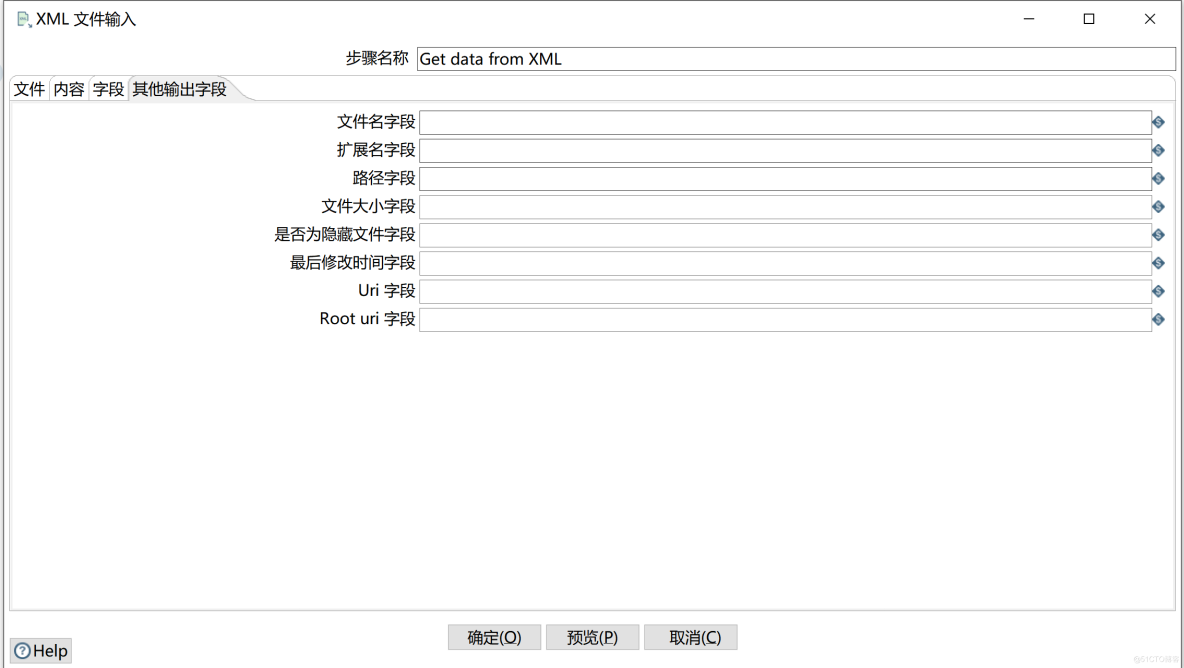
Option description
Options |
describe |
File name field |
Include file name and extension , And the whole file path |
Extended name field |
Just include the file name and extension name |
Path field |
Include only the path of the file |
File size field |
size |
Whether it is a hidden file field |
Is it hidden |
Finally, modify the time field |
Last modification time of this file |
Uri Field |
file / The absolute path to the directory |
Root uri Field |
The root path |
Okay , About XML Each tab of the file input component , I explained as much as I could . In fact, in my daily work , Not used so much , There are a few commonly used . But in the process of our study , I'd better speak more fully , I hope you spend time studying , Try to have a general understanding . Let's take an example to operate , This is a better way to absorb and understand .
Actual demonstration
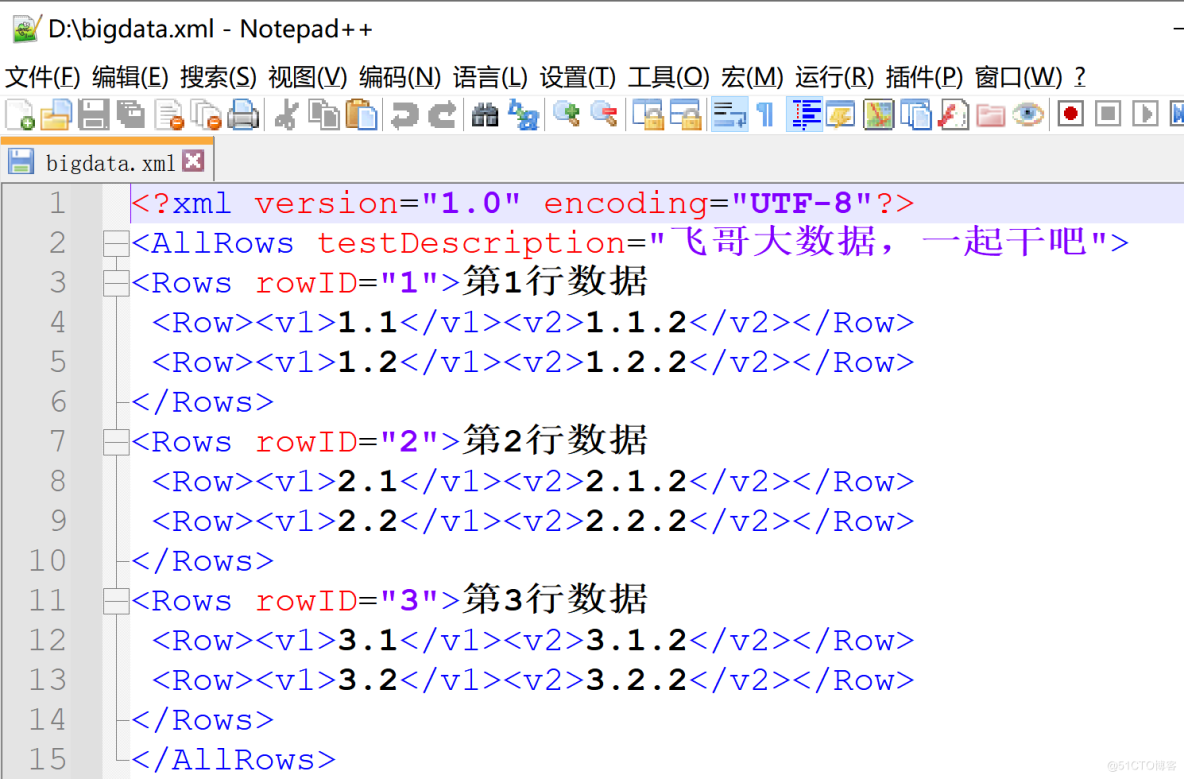
a、 establish xml file
I am here D Under the plate , Create a xml file , Name it bigdata. The details are as follows
b、 Create transformations

c、XML File input settings
Add local xml file , As a data source
Set content and coding

Set fields ( Here you can refer to XPth expression )

d、 Preview the record



brothers , See the interface for previewing data , Prove that you have successfully passed XML File input component , Put one on your disk xml file , Read in . Congratulations , You already know how to use XML File input component .
Conclusion
This article mainly explains :XML and XPath Those things , Then I explained XML Various detailed settings of the file input component , Finally, the actual combat demonstrates how to operate it to read the data on the disk xml file .
brothers , In fact, there is a distance between thinking and acting , If you think about it, it's gone , But you're doing it , It landed .
Don't say anything , Brothers, follow me and it's over , We still break up the way of kneading to say . The following content is more wonderful , Coming soon , Thank you for your attention !!
版权声明
本文为[Feige big data]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204221727532051.html
边栏推荐
- Career planning of data analysts -- career anxiety and future development of data analysts
- yes. Net future
- AWSL!这波回忆杀真的爱了!
- Classes and objects - 5
- 高并发之——深度解析ScheduledThreadPoolExecutor类的源代码
- Simulation experiment of Arduino uno steering gear
- 【最佳实践】巡检项:内容分发网络(CDN)开启URL鉴权
- nodejs如何预防xss攻击
- CVPR2022 | 跨模态检索的协同双流视觉语言预训练模型
- [most complete in the whole network] jsr303 parameter verification and global exception handling (don't use if to judge parameters from theory to practice)
猜你喜欢








随机推荐
视频知识点(16)- 如何将y4m文件转换成yuv文件?
深圳大学课题组发布《深圳市可持续发展评估报告(2016-2021年)》
Popular grass planting product forecast, guess the top 3 to get a red envelope!
[extensive reading of papers] eating embedded learning by comprehensive transcription of heterogeneous information networks
Simple application of tablayout + viewpager2 + fragment
Kellerman Software . NET SFTP Library
Better than SQL, another domestic database language was born
062 deserialization vulnerability
MySQL数据库中的索引(含SQL语句)
大话测试数据(一)
DL之YoloV3:YoloV3论文《YOLOv3: An Incremental Improvement》的翻译与解读
Use bitnami PostgreSQL docker image to quickly set up stream replication clusters
stream演示
2022装载机司机(建筑特殊工种)上岗证题目模拟考试平台操作
Type description file of module code
The balance between safety and opportunity -- the choice and thinking of St stock investment target
【Spark】(task6)Spark RDD完成统计逻辑
JSP learning (VIII. JDBC and file upload processing project)
B03 based on STM32 single chip microcomputer independent key control nixie tube stopwatch Proteus design, Keil program, C language, source code, standard library version
爱可可AI前沿推介 (4.22)