题目:
给你一个字符串 s ,请你统计并返回这个字符串中 回文子串的数目。回文字符串是正着读和倒过来读一样的字符串。子字符串是字符串中的由连续字符组成的一个序列。
具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。
示例:
输入: s = "aaa"
输出: 6
解释: 6个回文子串: "a", "a", "a", "aa", "aa", "aaa"1 <= s.length <= 1000s由小写英文字母组成
题解概述:
本题目有两种解题思路,分别是:
- 枚举出所有的子串,然后再判断这些子串是否是回文;
- 枚举每一个可能的回文中心,然后用两个指针分别向左右两边拓展,当两个指针指向的元素相同的时候就拓展,否则停止拓展。
官方题解中给出了从第二种思路出发的题解,我们这篇文章主要从第一种思路出发,给出三种方法。这三种方法层层优化,从暴力解法,到使用动态规划的解法,再对动态规划进行空间上的优化。希望能够帮助大家理解动态规划的使用方法。
题解一:(暴力法)
我们最直观能想到的就是,枚举出所有的子串,然后再判断这些子串是否是回文。下面给出暴力解法的代码(Go):
func countSubstrings(s string) int { // 暴力法 时间复杂度O(n^3)
n := len(s)
sum := 0
for i := 0; i < n; i++ {
for j := i; j < n; j++ {
if isPalindromic(s, i, j) {
sum++
}
}
}
return sum
}
func isPalindromic(s string, l int, r int) bool {
for l < r {
if s[l] != s[r] {
return false
}
l++
r--
}
return true
}暴力法自然是思考难度最低的解法,相信的加都能够想到。然而我们可以看到遍历所有子字符串需要花费 O(n^2) 的时间,对于每个子字符串判断是否为回文需要花费 O(n) 的时间,那么这个算法的时间复杂度为 O(n^3) ,显然对于我们最求性能极致的程序设计师而言,这样的结果无法接受。接下来我们将使用 动态规划 的方法进行进一步的优化。
复杂度分析:
时间复杂度: O(n^3)。
空间复杂度: O(1)。额外的常数空间即可。
题解二:(动态规划)
我们先要找到暴力解法效率低在哪里。显然,字符串 s 的两个不同的字串 str1 和 str2 如果重叠的话,在计算过程中,重叠的子子串会执行相同的计算逻辑,于是造成了计算的冗余。
动态规划的思想,即是存储重复子运算的结果,从而使得每个子运算只需要计算一次,是一种时间和空间的权衡(trade-off)。
第一步,我们要归纳一个最优解的结构,我们判断一个字串是回文时,一共有三种情况:
- 当
len(s) == 1时,只有一个回文子串s。 - 当
len(s) == 2时,比较s[0],s[1],确定回文子串个数,2或3。 - 当
len(s) > 2时,假设其子字符串str左端字符为str[i]右端字符为str[j],其余部分为str(i,j),则判断str是回文时,需要保证str(i,j)是回文且str[i] == str[j]。
以上三点就是递归定义的判断逻辑。前两种情况作为递归的基础情况(base case)。在第三种情况中,我们发现如果在判断另一个 内容为 “AstrB”的子字符串 str2时,则我们判断 str 是回文时,需要保证 str 是回文且 A == B。那我们需要再次判断一次 str 是不是回文呀,不能接受!
我们其实可以在第一次判断完 str 结果后,存储它。之后如果需要再判断 str 是否为回文时,直接返回结果,就省了很多计算内容。这就是 动态规划 了!
我们如何存储每一个子字符串呢?一种可行的方法是,我们搞一个 n x n 的二维布尔数组 a[i][j],其中 i 代表子字符串的左端,j 代表子字符串的右端。就可以存储计算过的子字符串是否为回文了!
我们在写代码的时候采用 自下而上 的方法(具体概念参考我写过的一个关于动态规划的文章)。先贴代码(Go):
func countSubstrings(s string) int { // 空间复杂度O(n^2)
n := len(s)
sum := 0
var a = make([][]bool, n)
for index := 0; index < n; index++ {
a[index] = make([]bool, n)
a[index][index] = true
sum++
if index+1 < n && s[index] == s[index+1] {
a[index][index+1] = true
sum++
}
}
for i := n - 1; i >= 0; i-- {
for j := i + 2; j < n; j++ {
if a[i+1][j-1] && s[i] == s[j] {
a[i][j] = true
sum++
}
}
}
return sum
}首先我们创建一个 n x n 的数组,同时初始化 base case,用于存储各子字符串的计算结果。然后在设计代码时,我们要搞明白各个子字符串的依赖关系,如图:
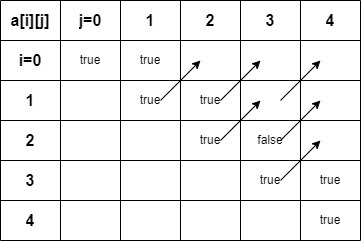
假设我们 s 是长度为 5 的字符串,则我们创建这样的二维数组,初始化base case。图中我们可以看到, 对于数组的每一行而言,a[n] 依赖于 a[n+1] ,对于数组的每一列而言 a[n][m] 依赖于 a[n][m-1]。所以我们需要从base case 开始,即横坐标由大(n-1)到小(0),纵坐标由小(当前横坐标i + 2)到大(n-1)遍历。对应于子字符串则是,子字符串的开端从 s 的最右端开始,确定开端后,再由小到大的设置子字符串尾端。
根据依赖的子子字符串的状态以及子字符串的开端尾端比较,可以在 O(1) 的时间内确定子字符串是否为回文。
复杂度分析:
时间复杂度: O(n^2)。遍历所有子字符串需要花费 O(n^2) 的时间
空间复杂度: O(n^2)。需要 n x n 的辅助二维数组。
题解三:(优化的动态规划)
我们再一次审视题解三,发现他需要额外的 n x n二位数组,且该二位数组其实有一半是用不到的,这无疑是一种浪费,那我们能不能节约空间呢?答案是肯定的。
通过观察我们发现,a[n] 只依赖于 a[n+1],那么我们计算 a[n+1] 时可以只保留 a[n], a[n+2] 再统计了 sum 之后则不需要再保存了。所以我们现在只需要两个长度为 n 的数组即可。
除此之外,我们发现, a[n][m] 也只依赖于 a[n][m-1],也就是说对于 a[n] 的更新,是从后往前依次更新的,那我们可以考虑,只使用一个长度为 n 的数组。在一次迭代计算 a[n][m] 时,当前 a[n][m-1] 的值实际上是上一次迭代 a[n+1][m-1] 的值,即是计算 a[n][m] 时需要的子子字符串的状态。下面是优化空间后的代码(Go):
func countSubstrings(s string) int { // 空间复杂度O(n)
n := len(s)
sum := 0
a := make([]bool, n)
a[0] = true
for index := 0; index < n; index++ {
// index指定数组需要处理次数,index+1 指定每次处理需要的长度
l := n - index - 1 // l代表字符串s开头的下标
for i := index; i > 0; i-- { // i表示处理数组的下标,倒序处理
if (i == 1 || a[i-2]) && s[l] == s[l+i] {
sum++
a[i] = true
} else {
a[i] = false
}
}
}
return sum + n
}复杂度分析:
时间复杂度: O(n^2)。遍历所有子字符串需要花费 O(n^2) 的时间
空间复杂度: O(n)。需要长度为 n 的辅助一维数组。