当前位置:网站首页>Contrastive Learning Series (3)-----SimCLR
Contrastive Learning Series (3)-----SimCLR
2022-08-11 08:46:00 【Tao Jiang】
SimCLR
SimCLRRepresentations are learned by maximizing the consistency of the same data under different augmentations through a contrastive loss in the hidden space.SimCLRThe framework has four main components,分别是:数据增广,encode网络,projection headNetworks and Contrastive Learning Functions.
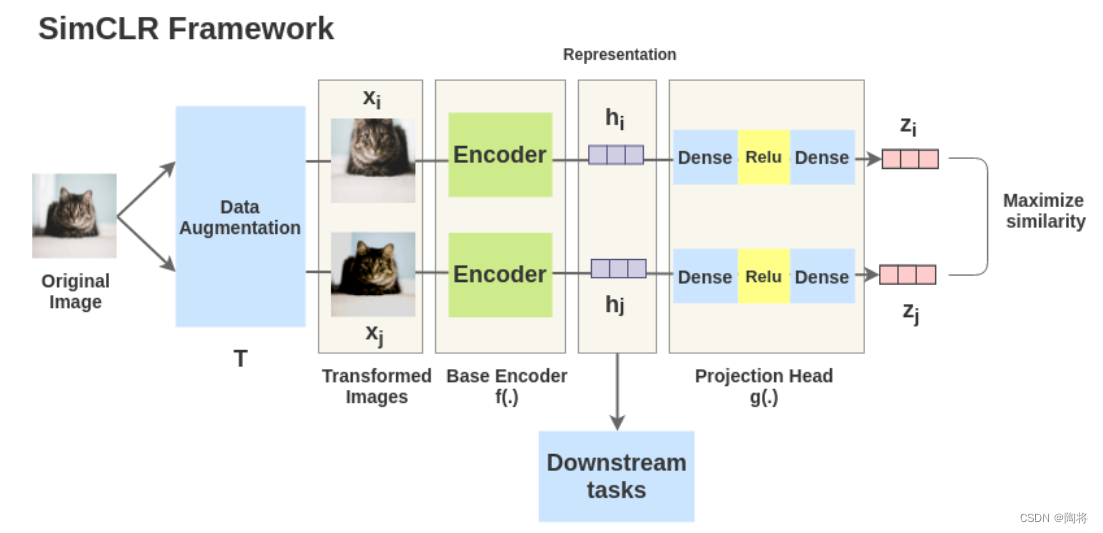
对于数据 x x x,Extract two independent data augmentation operators from the same data augmentation family( t ∼ T t \sim T t∼T和 t ′ ∼ T {t}' \sim T t′∼T),to get two related views x ^ i \hat{x}_{i} x^i和 x ^ j \hat{x}_{j} x^j, x ^ i \hat{x}_{i} x^i和 x ^ j \hat{x}_{j} x^j是一对正样本,Then a neural network encoder f ( ⋅ ) f\left( \cdot \right) f(⋅)Extract features from augmented data h i = f ( x ^ i ) , h j = f ( x ^ j ) , h_{i}=f\left( \hat{x}_{i} \right), h_{j}=f\left( \hat{x}_{j} \right), hi=f(x^i),hj=f(x^j),.And then a small neural networkproject head g ( ⋅ ) g\left( \cdot \right) g(⋅)Map features into the space of contrastive losses.project headwith one hidden layerMLP获取 z i = g ( h i ) = W ( 2 ) σ ( W ( 1 ) h i ) z_{i} = g\left( h_{i} \right) = W^{\left( 2 \right)} \sigma \left( W^{\left( 1 \right)} h_{i}\right) zi=g(hi)=W(2)σ(W(1)hi).
For contains a pair of positive samples x ^ i \hat{x}_{i} x^i和 x ^ j \hat{x}_{j} x^j的集合 { x ^ k } \{ \hat{x}_{k} \} { x^k},The contrast prediction task aims for a given x ^ i \hat{x}_{i} x^i在 { x ^ } k ≠ i \{ \hat{x} \}_{k \neq i} { x^}k=i中识别出 x ^ j \hat{x}_{j} x^j.随机挑选 N N N个样本组成一个minibatch,这个minibatch中则有 2 N 2N 2N个数据样本,将其他 2 ( N − 1 ) 2\left( N - 1\right) 2(N−1)an amplified sample as thisminibatch中的负样本,设 s i m ( u , v ) = u T v / ∥ u ∥ ∥ v ∥ sim\left( u, v\right) = u^{T}v / \| u\| \| v\| sim(u,v)=uTv/∥u∥∥v∥表示 l 2 l_{2} l2Yours after regularization u u u和 v v v的点积,Then for a pair of positive samples ( i , j ) \left( i, j \right) (i,j),The loss function is defined as follows:
l i , j = − l o g e x p ( s i m ( z i , z j ) / τ ) ∑ k = 1 2 N 1 [ k ≠ i ] e x p ( s i m ( z i , z k ) / τ ) l_{i,j} = - log \frac{exp\left( sim \left( z_{i}, z_{j}\right) / \tau \right)}{\sum_{k=1}^{2N} \mathbb{1}_{[ k \neq i]} exp\left( sim \left( z_{i}, z_{k}\right) / \tau \right)} li,j=−log∑k=12N1[k=i]exp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)
The final loss function computes aminibatchAll positive sample pairs in ,包括 ( i , j ) \left( i, j \right) (i,j)和 ( j , i ) \left( j,i \right) (j,i).下面是SimCLR的伪代码.从伪代码中可以看出,编码器 f ( ⋅ ) f\left( \cdot \right) f(⋅)和project head g ( ⋅ ) g\left( \cdot \right) g(⋅) Parameters are updated during training,But only the encoder f ( ⋅ ) f\left( \cdot \right) f(⋅)用于下游任务.
simCLR不采用memory bank的形式进行训练,rather increasebatchsize,bacth size为8192,对于每一个正样本,将会有16382Instances of negative samples.增大batch sizeActually equivalent to eachminibatchdynamically generate onememory bank.The papers found using standard onesSGD/Momentum,大batch sizeIt is unstable during training,论文中采用LARS优化器.
参考
边栏推荐
- 兼容并蓄广纳百川,Go lang1.18入门精炼教程,由白丁入鸿儒,go lang复合容器类型的声明和使用EP04
- Unity3D - modification of the Inspector panel of the custom class
- 【C语言】每日一题,求水仙花数,求变种水仙花数
- 抽象类和接口
- Getting Started with Kotlin Algorithms Calculating Prime Numbers and Optimization
- 【wxGlade学习】wxGlade环境配置
- 如何仅更改 QGroupBox 标题的字体?
- 仙人掌之歌——大规模高速扩张(1)
- WiFi cfg80211
- 为什么会没有内存了呢
猜你喜欢
Nuget找不到包的问题处理
企业服务器主机加固现状分析
如何通过 IDEA 数据库管理工具连接 TDengine?
JUC Concurrent Programming
Jupyter Notebook 插件 contrib nbextension 安装使用
Creo9.0 特征的成组
基于 VIVADO 的 AM 调制解调(1)方案设计
Unity3D - modification of the Inspector panel of the custom class

go-grpc TSL authentication solution transport: authentication handshake failed: x509 certificate relies on ... ...
基础SQL——DDL
随机推荐
法律顾问成了律所鸡肋产品了吗?
几何EX3 功夫牛宣布停售,入门级纯电产品为何总成弃子
gRPC系列(四) 框架如何赋能分布式系统
剑指offer专项突击版第26天
One network cable to transfer files between two computers
Kotlin算法入门计算质因数
Interview questions about Android Service
《价值》读书与投资
eureka和consul的区别
flex布局回顾
dsu on tree(树上启发式合并)学习笔记
mysql添加用户以及设置权限
用 Antlr 重构脚本解释器
框架外的PHP读取.env文件(php5.6、7.3可用版)
Creo9.0 特征的成组
Go 语言的诞生
Audio and video + AI, Zhongguancun Kejin helps a bank explore a new development path | Case study
C语言-结构体
Break pad source code compilation--refer to the summary of the big blogger
Linux,Redis中IOException: 远程主机强迫关闭了一个现有的连接。解决方法