当前位置:网站首页>9、Neural Sparse Voxel Fields
9、Neural Sparse Voxel Fields
2022-08-11 07:26:00 【C--G】
简介
该论文解决的是原始NeRF训练过程收敛速度慢的问题。原始NeRF是使用MLP网络的参数对整个空间进行建模,即原始NeRF的MLP网络的输入只有采样点的坐标和方向,输出就是该采样点的颜色和密度,因此我们可以理解为所有的信息都保存在MLP网络中。而NSVF是使用一个稀疏的体素八叉树(Sparse Voxel Octree)来辅助对空间建模,具体说来就是NSVF通过稀疏的体素八叉树保存了空间中各个节点位置的Feature,然后根据采样点的位置对Feature进行插值,最终输入MLP网络的是采样点的Feature和方向,因此空间中的信息一部分保存在了MLP网络中,另一部分则保存在稀疏的体素八叉树的Feature中
论文贡献

- 提出了由一组体素有界隐式字段组成的 NSVF,其中对于每个体素,体素嵌入被学习以编码局部属性以实现高质量渲染
- NSVF 利用稀疏体素结构实现高效渲染
- 引入了一种渐进式训练策略,该策略以端到端的方式从一组有姿势的 2D 图像中通过可微分的光线行进操作有效地学习底层稀疏体素结构
实现流程

对于表面渲染,至关重要的是找到一个准确的表面,使学习到的颜色在多视角中保持一致。体积渲染方法需要沿光线采样大量点以进行颜色累积,以实现高质量渲染,但是像 NeRF 那样沿射线评估每个采样点是低效的,例如,NeRF 渲染 800 × 800 图像需要大约 30 秒。
尽可能防止在没有相关场景内容的空白空间中采样点很重要,减低模型训练参数也很重要
体素有界隐式场

假设场景的相关非空部分包含在一组稀疏(有界)体素V = {V1…Vk},P∈Vi。 3D 点 p 的颜色和密度与NeRF一致,v 表示光线方向
p1…p8表示体素的八个顶点,gi(p*1)表示第i个体素的第1个顶点的特征向量,χ(.)是指三线性插值,ζ(.)是后处理函数,在这里ζ(.)是由 (Vaswani et al., 2017; Mildenhall et al., 2020) 提出的位置编码
NSVF 的渲染算法
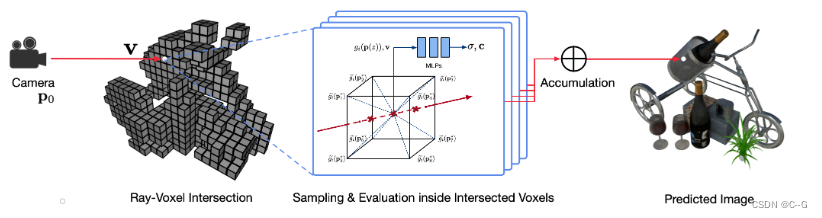

NSVF 在任何点 p ∈ V 对场景的颜色和密度进行编码。 与渲染模拟整个空间的神经隐式表示相比,渲染 NSVF 效率更高,因为它避免了空白空间中的采样点。 渲染分两步进行:(1)光线-体素相交(Ray-voxel Intersection); (2) 在体素内的光线行进(Ray Marching inside Voxels)。
光线-体素相交
首先对每条光线应用轴对齐边界框相交测试(AABB 测试)。 它通过比较从光线原点到体素的六个边界平面中的每一个的距离来检查光线是否与体素相交。 AABB 测试非常有效,尤其是对于分层八叉树结构(例如 NSVF),因为它可以轻松地实时处理数百万个体素。 实验表明,NSVF 表示中的 10k ∼ 100k 稀疏体素足以对复杂场景进行逼真的渲染在体素内的光线行进
为了处理光线错过所有对象的情况,在NeRF的权重公式的基础上,增加了一个背景项

其中,透明度为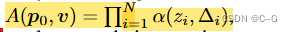
颜色
体渲染需要在非空空间中沿着光线的密集样本来实现高质量渲染,在整个空间中的均匀采样点进行密集评估是低效的,为了专注于更重要区域的采样,NeRF采用训练两个网络,采取二次采样措施,NSVF使用稀疏体素的抛弃采样方法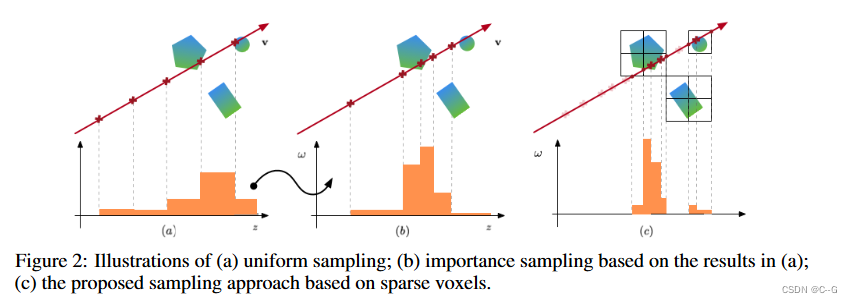
(a)为均匀采样,(b)在(a)的基础上进行重要性采样,(c)基于稀疏体素的采样方法
明显看到(c)避免的无效采样,更专注于重要区域采样
额外返回透明度 A 和预期深度 Z,可进一步用于可视化具有有限差异的法线
- 提前中止

NSVF 可以同样好地表示透明和实体对象,当A(p0,v)达到阈值(0.01)即可认为是透明的,而不用积累透明度到0
渐进式学习策略
渲染过程是完全可微的,NSVF 可以通过将渲染的输出结果与一组目标图像进行比较,通过反向传播进行端到端优化,无需任何 3D 监督
损失函数为
Ω(.) 是 Lombardi(2019) 等人提出的 beta 分布正则化器
首先学习用于细分初始边界框(具有体积 V )的一组初始体素的隐函数,该边界框以足够的间隔粗略包围场景。 初始体素大小设置为
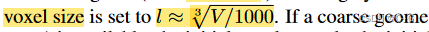
采用自剪枝策略,在训练期间基于粗几何信息有效去除非必要体素的策略


是体素 Vi 内的 G 个均匀采样点(G在实验中为16^3),σ(gi (pj)) 为pj的预测密度,γ 是一个阈值(实验中 γ = 0.5),满足上列式子时,Vi被减去
修剪策略使我们能够逐步调整体素化以适应底层场景结构,并自适应地为重要区域分配计算和内存资源。假设学习从初始光线行进步长 τ 和体素大小 l 开始。 经过一定的训练步骤后,我们将 τ 和 l 减半以用于下一阶段。 具体来说,当体素大小减半时,我们将每个体素细分为 个子体素,并且通过原始八个体素顶点处的特征表示的三线性插值初始化新顶点的特征表示。当使用嵌入作为体素表示时,我们实质上是逐步增加模型容量以了解场景的更多细节
实验中,训练了 4 个阶段的合成场景和 3 个阶段的真实场景
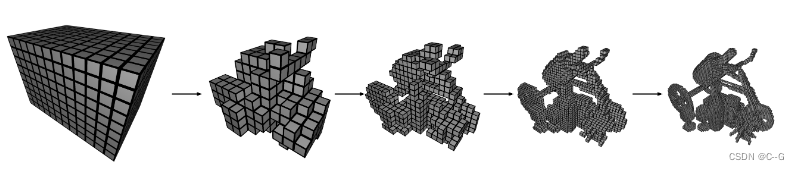
网络结构

其中,Voxel Embedding部分即为稀疏的体素八叉树保存的特征
边栏推荐
- 6月各手机银行活跃用户较快增长,创半年新高
- oracle数据库中列转行,列会有变化
- 结合均线分析k线图的基本知识
- 流式结构化数据计算语言的进化与新选择
- 【LaTex-错误和异常】\verb ended by end of line.原因是因为闭合边界符没有在\verb命令所属行中出现;\verb命令的正确和错误用法、verbatim环境的用法
- 3GPP LTE/NR信道模型
- Activity的四种启动模式
- tf.reduce_mean() and tf.reduce_sum()
- 1036 Programming with Obama (15 points)
- oracle19c不支持实时同步参数,请教一下大佬们有什么好的解决办法吗?
猜你喜欢





随机推荐
Two startup methods and differences of Service
基于微信小程序的租房小程序
1046 划拳 (15 分)
【sdx62】XBL设置共享内存变量,然后内核层获取变量实现
2.1-梯度下降
JRS303-Data Verification
【BM87 合并两个有序的数组】
1081 检查密码 (15 分)
伦敦银规则有哪些?
2022 China Soft Drink Market Insights
My creative anniversary丨Thank you for being with you for these 365 days, not forgetting the original intention, and each is wonderful
JRS303-数据校验
js根据当天获取前几天的日期
1046 punches (15 points)
2022年中国软饮料市场洞察
动态代理学习
Service的两种状态形式
Redis source code-String: Redis String command, Redis String storage principle, three encoding types of Redis string, Redis String SDS source code analysis, Redis String application scenarios
Pico neo3 Unity打包设置
接口测试的基础流程和用例设计方法你知道吗?