当前位置:网站首页>A separate machine is connected to the spark cluster of cdh, and the task is submitted remotely (absolutely successful, I have tested it n times)
A separate machine is connected to the spark cluster of cdh, and the task is submitted remotely (absolutely successful, I have tested it n times)
2022-08-09 03:12:00 【I'm going to use code to confess to the girl I like】
I have 4 machines where hadoop1-hadoop3 is a cdh cluster and hadoop4 is a normal machine.
I use a machine that does not belong to the cdh cluster to make the cdh cluster perform operations in a remote way, and my local machine does not participate in the operation.
The operation process is as follows:

In order to understand remote submission, we should learn from 2 aspects
1. Understand the principles and ideas
2. Operation
Understand the rationale
First, let's understand the basic common sense of spat
There are 4 types of spark submissions
local, standalone, yarn, memos
In addition to the local mode, othercan be submitted remotely
local is to execute with local spark, which is basically not used except for testing, and if using yarn mode or other modes, using local in the code will also cause spark-submit to submit, spark does not know theRunning in yarn mode is still executed in local mode, resulting in an error.Therefore, local, we only use it in the idea test code. If we want to make a jar package, when we need to schedule yarn mode or other modes when using submit, we will delete the master line in the idea code, and then package it.
Standalone means that it does not rely on external plug-ins and relies solely on the spark cluster for tasks. We submit it remotely through master=spark://sparkmaster node:7077
.The code is separated by a , number.
In this case, the startup mode of the spark cluster must have master and worker processes, otherwise it cannot connect to this node.By default, cdh is in yarn mode. You need to start the master and work yourself, which is the master-slave architecture of the spark cluster.
The yarn mode cdh mode is also the most domestic mode.The advantage is that yarn automatically allocates resources and memory. Of course, you can also allocate resources yourself.
Yarn is divided into two types, client mode and cluster mode
These two types are actually allocated to the cluster to run, and yarn defaults to client mode, which can be changed by setting yarn-mode.
client mode is to start the driver from the current node and submit the task to the cluster for execution. You can see the log on the current node
cluster mode is submitted by the current node to the cluster, and yarn randomly assigns a machine as the driver, and then the driver submits the task to the cluster for execution. The current machine cannot see the log, only the log can be seen in the yarn service
Both of these modes can actually be used in a production environment.
Memos mode, I heard from them that the efficiency is also very high, and it is more friendly (convenient) for remote operations, but unfortunately in China, there is very little information.I haven't found any relevant study materials for him here, and I haven't conducted experiments, so I won't go into details here.
Take action
Here, we are using a machine, I installed spark and hadoop for it, and strive to be the same as the cdh version, so I downloaded spark2.4 and hadoop3.0, because cdh6.3.2 is also this version.

Of course, you have to install jdk first, and hadoop depends on java.
The process is as follows:
spark-submit yarn submits a task, he will read yarn-site.xml and other configurations in the HADOOP_HOME directory, and then connect to the worker node (node on the cluster) corresponding to the configuration through the driver, and then execute the task,Synchronize logs to this node.
The idea of remote processing is as follows:
Copy the Hadoop-related configuration files of cdh to the local hadoop directory and replace it.Since there is no configuration of its own node in the local hadoop directory, after submitting the cluster, his calculation will not be allocated to the local machine for calculation.However, since the driver is local, the processing log information of the cluster can be obtained.
Formal operation:
1. First upload and decompress these two files to the /hadoop directory
2. Go to the /etc/hadoop directory of any machine in the cdh cluster and copy it (this is the hadoop configuration directory of cdh)

3. Create the etc directory locally, put the /etc/hadoop directory of the cluster into it, and make it the same directory as the cluster
4. Copy /etc/hadoop (the current one is the cdh configuration file) to the /etc directory of the local hadoop software to overwrite hadoop. Back up the original one first.The orange part is local, the installed hadoop.You can only use cp but not mv, because the default configuration of cdh will find other configurations in the /etc/hadoop directory
cp -r /etc/hadoop/ /software/hadoop-3.0.0/etc/
5. Environment variable configuration
export JAVA_HOME=/software/jdk1.8.0_251
export PATH=$PATH:${JAVA_HOME}/bin
export HADOOP_HOME=/software/hadoop-3.0.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/conf
export SPARK_HOME=/software/spark-2.4.0-bin-hadoop2.7
export PATH=$PATH:${SPARK_HOME}/bin
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
source /etc/profile
Remember to configure hosts (all nodes) and turn off firewall
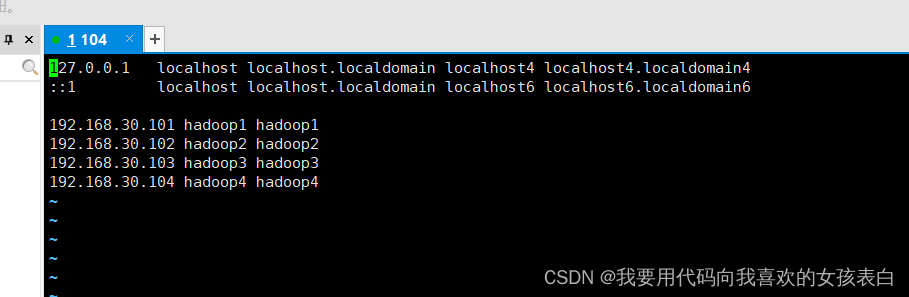
6.Test
First of all, I didn't lie to you, I don't have hadoop4 here

Then hadoop4 (104 nodes)

Of course, you can also drop the jar package to hdfs
spark-submit --class demo.test2_hive --master yarn hdfs://hadoop1/test/WordCount.jar
You see all, hadoop2 and hadoop3 are used as memory nodes
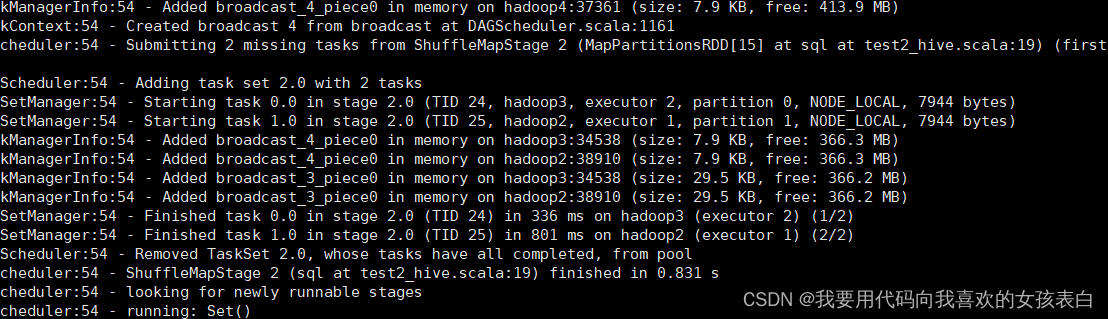
Successfully executed

边栏推荐
- 【扫雷--1】
- ARM开发(二)ARM体系结构——ARM,数据和指令类型,处理器工作模式,寄存器,状态寄存器,流水线,指令集,汇编小练习题
- 2022-08-08 The fifth group Gu Xiangquan study notes day31-collection-junit unit test
- pytorch 自定义dataset
- Building PO layered architecture of automated testing framework from 0
- 高并发+海量数据下如何实现系统解耦?【中】
- 数学基础(三)PCA原理与推导
- Rotate the neon circle
- SQLserver重新累计问题
- MVVM项目开发(商品管理系统二)
猜你喜欢

【机器学习】21天挑战赛学习笔记(三)

【扫雷--1】

23 Lectures on Disassembly of Multi-merchant Mall System Functions-Platform Distribution Level

CI/CD:持续集成/持续部署(难舍难分)

1.02亿美元从数字资产基金撤出!BTC价格已经触底!预示下跌趋势即将逆转?

grafana的panel点击title,没有反应,没有出现edit选项

书签收藏难整理?这款书签工具管理超方便

2022-08-08 The fifth group Gu Xiangquan study notes day31-collection-IO stream-File class

Zabbix 5.0 监控教程(四)

Second data CEO CAI data warming invited to jointly organize the acceleration data elements online salon
随机推荐
C专家编程 第9章 再论数组 9.3 为什么C语言把数组形参当做指针
如何实现有状态转化操作
甲乙丙丁加工零件,加工的总数是370, 如果甲加工的零件数多10,如果乙加工的零件数少20,如果丙加工的 零件数乘以2,如果丁加工的零件数除以2,四个人的加工数量相等,求甲乙丙丁各自加工多少个零件?
1.02亿美元从数字资产基金撤出!BTC价格已经触底!预示下跌趋势即将逆转?
【机器学习】21天挑战赛学习笔记(三)
【图像增强】基于Step和Polynomial 滤波实现图像增强附matlab代码
Matlab实现异构交通流
条件变量condition_variable实现线程同步
【CAS:41994-02-9 |Biotinyl Tyramide|】生物素基酪氨酰胺
Embedded system driver advanced [3] - __ID matching and device tree matching under platform bus driver development
Second data CEO CAI data warming invited to jointly organize the acceleration data elements online salon
别了,IE浏览器
23 Lectures on Disassembly of Multi-merchant Mall System Functions-Platform Distribution Level
ros入门(安装)
Redis expiration strategy and elimination strategy
What are the functions and applications of the smart counter control board?
Shell脚本:函数
嵌入式系统驱动高级【3】——平台总线式驱动开发下__ID匹配和设备树匹配
JSON的使用
2027年加密市场将会发生什么?思维的跨越?长期预测无法脱离形势变化