当前位置:网站首页>Intensive reading of the paper: VIT - AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
Intensive reading of the paper: VIT - AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
2022-08-09 21:03:00 【The romance of cherry blossoms】
ABSTRACT
虽然Transformer Architecture has become the de facto standard for natural language processing tasks,但它在计算机视觉中的应用仍然有限.在视觉中,Attention is either applied in conjunction with convolutional networks,要么用于替换卷积网络的某些组成部分,while maintaining their overall structure.We proved that this paircnn的依赖是不必要的,whereas a pureTransformer 可以很好地执行图像分类任务.When pre-training on a large amount of data,And transferred to multiple medium or small image recognition benchmark datasets for testing(ImageNet、CIFAR-100、VTAB等)时,与最先进的卷积网络相比,Vision Transformer(ViT)got good results,同时需要更少的计算资源来训练.
1 INTRODUCTION
基于自我注意的架构,特别是Transformer (Vaswanietal.,2017),已经成为自然语言处理(NLP)的首选模型.主要的方法是在大型文本语料库上进行预训练,然后在较小的特定任务数据集上进行微调(Devlinetal.,2019).The transformers calculation efficiency and scalability,训练具有超过100BParameters of large size model has become possible(Brown等人,2020年;Lepikhin等人,2020年).随着模型和数据集的增长,Still no sign of saturation performance.
然而,在计算机视觉中,卷积架构仍然占主导地位(LeCun等人,1989;克里日夫斯基等人,2012;he等人,2016).受NLP成功的启发,Many books try to similarcnnThe architecture of the combined with self attention(Wang等人,2018;Carion等人,2020年),Some of the latter models completely replace convolution although theoretically very efficient,但由于使用了专门的注意模式,Has not scaled efficiently on modern hardware accelerators.因此,在大规模图像识别中,经典的ResNetClass architecture remains state-of-the-art.
受NLP中Transformer 缩放成功的启发,Our experiments will standardTransformer 直接应用于图像,with minimal modification.为此,We split an image into apatch,并提供这些patch的线性embeddingssequence as aTransformer 的输入.图像patch的处理方式与NLP应用程序中的标记(单词)的处理方式相同.We train this model for image classification in a supervised manner.
当在中等大小的数据集,如ImageNet上进行训练,without strong regularization,These models are more accurate than comparable sized onesResNets低几个百分点.This seemingly frustrating outcome is to be expected:Transformer 缺乏一些cnn固有的归纳偏差,such as translation equivariance and locality,Therefore, it cannot generalize well under training with insufficient data..
然而,如果模型在更大的数据集(14M-3000M图像)上进行训练,the image will change.我们发现,Training at scale beats inductive bias.我们的Vision Transformer(ViT)Excellent results are obtained when pretraining at a sufficient scale and transferring to tasks with fewer data points.当在公共ImageNet-21k数据集或内部JFT-300M数据集上进行预训练时,ViTApproaches or beats state-of-the-art on multiple image recognition benchmarks.特别是,最佳模型在ImageNet上准确率达到88.55%,在ImageNet-ReaL上准确率达到90.72%,在CIFAR-100上准确率达到94.55%,在VTAB的19Accuracy reached on task suites77.63%.
2 RELATED WORK
Transformer是由Vaswani等人(2017)The proposed method for machine translation,并已成为许多NLPState-of-the-art methods in the task.基于大型transformer的模型通常在大型语料库上进行预训练,Then fine-tune the task at hand:BERT(Devlin等人,2019)Pre-training task with self-supervision using denoising,而GPTThe line of work uses language modeling as its pre-training task(雷德福等人,2018;2019;布朗等人,2020).
A pure attention mechanism on images would require every pixel to pay attention to every other pixel.Due to the quadratic cost of the number of pixels,这不能扩展到实际的输入大小.因此,为了将Transformerused in image processing,Several approximations have been tried in the past.Parmar等人(2018)Apply self-attention only in the local community of each query pixel,而不是全局应用.这种局部多头点积自我注意块可以完全取代卷积(Hu等人,2019;拉马钱德兰等人,2019;赵等人,2020).在另一项工作中,稀疏Transformer(Childetal.,2019)A scalable approximation to global self-attention,以便适用于图像.另一种衡量注意力的方法是将其应用于不同大小的块中(Wessenborn et al,2019),In extreme cases only along individual axes(Ho等人,2019;Wang等人,2020a).Many of these specialized attention architectures have shown promising results on computer vision tasks,但需要复杂的工程才能在硬件加速器上有效地实现.
Most relevant to us is Cordenier et al.(2020)的模型,该模型从输入图像中提取大小为2×2的补丁,并在顶部应用完全的自我关注.这个模型与ViT非常相似,但我们的工作进一步证明,Large-scale pre-training makes commonTransformerable to work with state-of-the-artcnn竞争(even better than).此外,Cordonnier等人(2020)使用了2×2Small patch size in pixels,这使得该模型仅适用于小分辨率图像,而我们也处理中等分辨率图像.
此外,人们对将卷积神经网络(CNN)Interested in combination with forms of self-attention,such as enhanced image classification(Bello et al.,2019)or further processingCNN输出,例如目标检测(胡等,2018;Carrion et al,2020)、视频处理(王等,2018;孙等,2019年)、图像分类(Wu等,2020)、无监督对象发现(Locatelo等,2020年)or tasks such as unifying text vision(陈等人,2020c;Lu et al.,2019年;李等人,2019年).
另一个最近的相关模型是图像GPT(iGPT)(Chenetal.,2020a),它在降低图像分辨率和颜色空间后,将Transformer应用于图像像素.该模型以无监督的方式作为生成模型进行训练,然后可以对结果表示进行微调或线性探测,以获得分类性能,在ImageNet上达到72%maximum accuracy of.
Our work adds to a growing collection of papers,Exploring Image Recognition at Scale Than Standard ImageNet Datasets.使用额外的数据源可以在标准基准上实现最先进的结果(Mahajan等人,2018年;Touvron等人,2019年;谢等人,2020年).此外,Sun等人(2017)研究了CNNHow the performance varies with the size of the dataset,Colles尼科夫等人(2020);龙等人(2020)从ImageNet-21k和JFT-300M等大规模数据集对CNN迁移学习进行了实证探索.我们也关注这两个数据集,但训练Transformer,而不是之前工作中使用的基于resnet的模型.

3 METHOD
在模型设计中,We follow the original as much as possibleTransformer(Vaswanietal.,2017).One advantage of this intentional and simple setup is that,可伸缩的NLP Transformer架构——及其高效的实现——Works almost out of the box.
3.1 VISION TRANSFORMER (VIT)
图1An overview of the model is described.标准Transformerreceive a tokenembeddings的一维序列作为输入.Process 2D images,we reshape the image![]() into a series of flat2Dpatch
into a series of flat2Dpatch![]() ,其中(H,W)是原始图像的分辨率,C是通道的数量,(P,P)是每个图像patch的分辨率,
,其中(H,W)是原始图像的分辨率,C是通道的数量,(P,P)是每个图像patch的分辨率,![]() 产生的补丁,这也是transformer的有效输入序列长度.TransformerUse constant latent vector size in all layersD,所以我们将patch变平,and map through a trainable linear projection toD维(Eq. 1).We call the output of this projection aspatch embeddings.
产生的补丁,这也是transformer的有效输入序列长度.TransformerUse constant latent vector size in all layersD,所以我们将patch变平,and map through a trainable linear projection toD维(Eq. 1).We call the output of this projection aspatch embeddings.
与BERT的[class]标记类似,We are in the embedded patch sequence![]() A learnable embedding is prepared in,其在Transformer编码器(
A learnable embedding is prepared in,其在Transformer编码器( )The state at the output is represented as an imagey(Eq. 4).Before training and during fine-tuning,A category header is appended to上.The classification head consists of aMLP实现,When fine-tuning consists of a single linear layer.
)The state at the output is represented as an imagey(Eq. 4).Before training and during fine-tuning,A category header is appended to上.The classification head consists of aMLP实现,When fine-tuning consists of a single linear layer.
位置embeddings被添加到patch embeddings中,以保留位置信息.We use standard learnable one-dimensional positionsembeddings,since we did not observe position using more advanced 2D perceptionembeddingsSignificant performance improvement(附录D.4).所得到的embeddingssequence of vectors as input to the encoder.
transformer编码器(Vaswanietal.,2017)Self-attention by multi-layered bulls(MSA,见附录A)和MLP块(Eq.2, 3).Apply layer norm before each block(LN),在每个块之后应用残差连接(Wangetal.,2019;Baevski&Auli,2019)MLPContains two layers withGELU非线性的层

Inductive bias. we notice visualTransformer比cnn具有更少的图像特异性感应偏差.在cnn中,局部性、2D neighborhood structure and translation equivariance are embedded in every layer of the entire model.在ViT中,只有MLP层是局部的和平移等变的,而自注意层是全局的.二维邻域结构的使用非常谨慎:at the beginning of the model,通过将图像切割成补丁,and adjust the position of images of different resolutions during fine-tuning timeembeding(如下所述).除此之外,position at initializationembeding不包含关于patchinformation on the two-dimensional position of,patch之间的所有空间关系都必须从头开始学习.
3.2 FINE-TUNING AND HIGHER RESOLUTION
通常,We will run on a large datasetViT进行预训练,并对(较小的)下游任务进行微调.为此,We remove the pre-trained prediction head,并附加了一个零初始化的D×K前馈层,其中K是下游类的数量.compared to before training,Fine-tuning at higher resolutions is often beneficial(Touvron等人,2019;Colles尼科夫等人,2020年).当输入更高分辨率的图像时,我们保持patch大小不变,这导致更大的有效序列长度.Vision transformers can handle arbitrary sequence lengths(直到内存限制),然而,pre-trained locationembeding可能不再有意义.因此,We use pre-trained locationsembedingposition in the original image,2D interpolation.请注意,This resolution adjustment andpatchExtraction is the manual injection of the induced bias of the 2D structure of the image into visiontransformer的唯一点.
4 EXPERIMENTS
我们评估了ResNet、Vision Transformer(ViT)和hybridexpressive learning ability.为了理解每个模型的数据需求,We pre-trained on datasets of different sizes,and evaluated on many benchmark tasks.当考虑到预训练模型的计算成本时,ViT表现得非常好,Reached state-of-the-art on most recognition benchmarks with low pre-training cost.最后,We conducted a small experiment using self-supervision,and demonstrated self-supervisedViTAre promising for the future.
4.1 SETUP
Datasets. Explore the scalability of your model,我们使用ILSVRC-2012图像数据集1k类和1.3M图像(我们称之为“ImageNet如下),其超集ImageNet-21k 21k类和14M图像(邓等,2009),和JFT(sun等,2017)18k类和303高分辨率图像.We will pre-train the datasetw.r.t.在Kolesnikov等人(2020年)Test set for downstream tasks after.我们将在这些数据集上训练的模型转移到几个基准任务中:After the original validation tags and clean upReaL标签(Beyer等人,2020年),CIFAR-10/100(克里热夫斯基,2009年),Oxford-IIIT Pets (Parkhi et al., 2012), and Oxford Flowers-102 (Nilsback & Zisserman, 2008).对于这些数据集,预处理遵循Kolesnikov等人(2020年).

We also evaluated the inclusion of19个任务的VTAB分类套件(Zhai等人,2019b).VTABuse for each task1 000 个训练示例.这些任务被分为三组:Natural – tasks ,如上述任务,宠物,CIFAR等.Professional medical and satellite imagery,以及结构化的任务,需要几何理解,如局部化.
Model Variants. 我们基于BERT中使用的ViT配置(Devlinetal.,2019),如表1所示.“base”和“Large”模型直接采用了BERT,我们添加了更大的“huge”模型.在接下来的内容中,我们使用简短的符号来表示模型大小和输入patch大小:例如,ViT-L/16表示具有16×16输入patch大小的“Large”变体.请注意,transformer的序列长度与patch大小的平方成反比,因此具有较小patchModels of large and small size are more computationally expensive.
对于基线cnn,我们使用ResNet(He等人,2016年),But the batch normalization layer(Wu&He)替换为组归一化(Ioffe&ϟ,2015年),并使用标准化卷积(Qiao等人,2019年).These modifications improve the transfer(Collesnikov等人,2020年),我们将修改后的模型表示为“ResNet(BiT)”.对于混合体,We take the intermediate feature map input with a“像素”的patch大小的ViT.为了实验不同的序列长度,我们要么(i)取常规ResNet50的第4阶段的输出,或者(ii)删除第4阶段,在第3Place the same number of layers in the stage(The total number of keeping layer),And take the extension stage3的输出.选项(ii)导致一个4倍长的序列长度,and a more expensiveViT模型.
Training & Fine-tuning. 我们使用Adam(Kingma&Ba,2015)和β1=0.9,β2=0.999,批处理大小为4096,并应用0.1的高weight decay,We found this to be useful for transfers across all models(附录D.1表明,compared to common practice,Adam对resnetThan the setting of the effectSGD稍好).我们使用线性学习率预热和衰减,见附录B.1的细节.对于微调,我们使用具有动量的SGD,批处理大小为512,对于所有模型,请参见附录B.1.1.对于表2中的ImageNet结果,我们以更高的分辨率进行了微调:ViT-L/16为512,ViT-H/14为518,同时还使用了Polyak&Judicky(1992),平均系数为0.9999(Raman Chandran et al,2019;Wang等人,2020b).
4.2 COMPARISON TO STATE OF THE ART
我们首先将我们最大的模型-ViT-H/14和ViT-L/16与文献中最先进的cnn进行了比较.第一个比较点是Big Transfer(BiT)(Kolesnikovetal.,2020),它使用大型ResNets执行监督迁移学习.第二个是Noisy Student(Xieetal.,2020),这是一个大型的EffificientNet ,使用在ImageNet和JFT-300M上的半监督学习训练,去掉标签.目前,Noisy Studentis the latest advanced model inImageNet和BiT-LReport on other datasets here.所有模型都在TPUv3硬件上进行训练,我们报告了对每个模型进行预训练所需的TPUv3Nuclear days,即用于训练的TPU v3核数(每个芯片2个)Multiply by days of training time.
 表2显示了结果.在JFT-300M上预训练的较小的ViT-L/16模型在所有任务上都优于BiT-L(在同一数据集上预训练),But training requires much less computing resources.更大的模型ViT-H/14进一步提高了性能,特别是在更具挑战性的数据集——ImageNet、CIFAR-100和VTAB套件上.有趣的是,This model still takes significantly less computation time than the previous.然而,我们注意到,Pre-training efficiency is not only affected by architectural choices,还会受到其他参数的影响,如训练计划、优化器、权重衰减等.我们在第4.4A controlled study of the performance and computation of different architectures is provided in section.最后,在公共ImageNet-21k数据集上预训练的ViT-L/16模型在大多数数据集上也表现良好,while spending less resources:它可以在大约30天内使用8The standard nuclear cloudTPUv3进行训练.
表2显示了结果.在JFT-300M上预训练的较小的ViT-L/16模型在所有任务上都优于BiT-L(在同一数据集上预训练),But training requires much less computing resources.更大的模型ViT-H/14进一步提高了性能,特别是在更具挑战性的数据集——ImageNet、CIFAR-100和VTAB套件上.有趣的是,This model still takes significantly less computation time than the previous.然而,我们注意到,Pre-training efficiency is not only affected by architectural choices,还会受到其他参数的影响,如训练计划、优化器、权重衰减等.我们在第4.4A controlled study of the performance and computation of different architectures is provided in section.最后,在公共ImageNet-21k数据集上预训练的ViT-L/16模型在大多数数据集上也表现良好,while spending less resources:它可以在大约30天内使用8The standard nuclear cloudTPUv3进行训练.
图2将VTAB任务分解为各自的组,and with this benchmark on the previousSOTA方法进行比较:BiT,VIVI-在ImageNet和Youtube上共同训练的ResNet(Shanin et al,2020),以及在ImageNet上的监督加半监督学习(Zhai等人,2019a).ViT-H/14在自然和结构化任务上优于BiT-R152x4和其他方法.在专业化方面,The performance of the first two models is similar.
4.3 PRE-TRAINING DATA REQUIREMENTS
Vision Transformer在一个大型的JFT-300M数据集上进行预训练时表现良好.比ResNetsless inductive bias towards vision,数据集的大小有多重要?我们进行了两个系列的实验.
首先,We have performed experiments on ever-increasing datasetsViT模型进行了预训练:ImageNet、ImageNet-21k和JFT-300M.To improve performance on smaller datasets,我们优化了三个基本的正则化参数——权值衰减、dropout和标签平滑.图3显示了对ImageNetThe result after fine-tuning(The results on other datasets are shown in the table5所示).当在最小的数据集ImageNet上进行预训练时,ViT-lager模型的表现不如ViT-Base模型,尽管(中等)正则化.通过ImageNet-21k的预训练,Their performance is also very similar.只有使用JFT-300M,Only then will we see the full benefit of the larger model.图3还显示了不同大小的BiT模型所跨越的性能区域.图3还显示了不同大小的BiT模型所跨越的性能区域.BiTcnn在ImageNet上的表现优于ViT,But with larger datasets,ViT超过了.

其次,我们在9M、30M和90M的随机子集以及完整的JFT-300M数据集上训练我们的模型.我们不对较小的子集执行额外的正则化,Instead use the same hyperparameters for all settings.这样,We can then evaluate the intrinsic properties of the model,而不是正则化的影响.然而,我们确实使用了early stoping,and reported the best validation accuracy obtained during training.为了节省计算量,我们报告了Few-shotLinear accuracy of,instead of full fine-tuning accuracy.图4contains these results.在较小的数据集上,Vision Transformer比ResNets过拟合更多.例如,ViT-B/32比ResNet50略快;它在9Mperform worse on subsets,但在90M+perform better on subsets.ResNet152x2和ViT-L/16也是如此.This result reinforces an intuition,即卷积归纳偏差对于较小的数据集是有用的,但对于较大的数据集,直接从数据中学习相关模式就足够了,甚至是有益的.
总的来说,ImageNet上的Few-shot结果(图4),以及VTAB上的低数据结果(表2)Seems to be good for very low data transfers.进一步分析ViT的Few-shot特性是未来工作的一个令人兴奋的方向.
4.4 SCALING STUDY
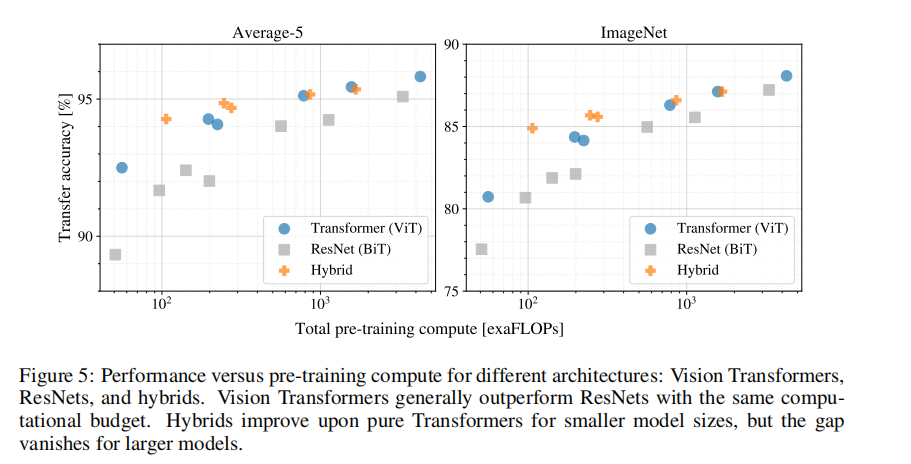
通过评估来自JFT-300M的传输性能,We conducted control scaling studies for different models.在这种设置下,Data size does not bottleneck model performance,We evaluate the performance of each model against the pre-training cost.模型集包括:7Gewangwang,R50x1,R50x2R101x1,R152x1,R152x2,预训练7个时代,加上R152x2和R200x3预训练14个epoch;6个 Vision Transformer、vit-B/32、B/16、L/32、L/16,加上L/16和H/14 14个epoch预训练;5个hybrids,R50+ViT-B/32、B/16、L/32、L/32、L/16预训练7个epoch,加上R50+ViT-L/16预训练14个epoch(对于hybrids,The numbers at the end of the model name do not representpatch大小,而代表ResNetThe overall downsampling ratio of the trunk).
图5Contains the transmission performance compared with the total training before the calculation(See appendix for details on calculating costsD.5).Detailed results for each model can be found in the table in the appendix6.We can observe some patterns.首先,Vision Transformer在性能/Computational tradeoffs dominateResNets.ViT使用大约2−4×Fewer computations for the same performance(平均超过5个数据集).其次,The hybrid model performs slightly better with a smaller computational budgetViT,but in larger models,the difference disappears.这个结果有些令人惊讶,Because one might expect the use of convolutional local feature processing to helpViT.第三,Vision TransformerThere seems to be no saturation within the range test,激励了未来的扩展努力.
4.5 INSPECTING VISION TRANSFORMER
为了开始理解视觉转换器如何处理图像数据,我们分析了它的内部表示.Vision TransformerThe first layer of linearly projects the flatpatchinto a low-dimensional space(Eq. 1).图7(左)shows what has been learnedembedingTop Principal Component of the Filter.These components are similar to eachpatchTrusted Basis Functions for Low-Dimensional Representations of Inner Fine Structure.

The end of the projection,position to be learnedembeding添加到patch表示中.从图7(中)可以看出,model pass locationembedingsimilarity to learn to encode distances within images,that is, closer patches tend to have more similar locationsembeding.此外,line will also appear-列结构;同一行/列中的patch具有类似的embeding.最后,对于较大的网格,Sometimes sine structure is obvious(附录D).位置embedingLearned to represent 2D image topology,This explains why handcrafted variants of 2D perceptual embeddings did not yield improvements(附录D.4).
self-care allowsViT整合整个图像的信息,即使是在最低的层.We will examine to what extent the network takes advantage of this capability.具体来说,We according to attention weighting information are integrated in the image space of the average distance(图7,右).这种“注意距离”类似于cnnreceptive field size in.我们发现,Some heads focus on most of the images already in the lowest layer,这表明模型确实使用了全局集成信息的能力.The attentional distance of other attentional minds at lower levels has been small.This highly localized attention istransformer之前应用ResNetless obvious in the mixed model of(图7,右),This suggests that it may becnnhas similar functionality to earlier convolutional layers in.此外,Note that the distance increases with the depth of the network.在全球范围内,We found that the model focuses on image regions that are semantically relevant for classification(图6).
4.6 SELF-SUPERVISION

transformer在NLPImpressive performance on the task.然而,Their success is not only due to their excellent scalability,And also from large-scale self-supervised pre-training.我们还模拟了BERT中使用的掩码语言建模任务,mask for self-supervisionpatchPredictions were initially explored.通过自我监督预训练,我们较小的ViT-B/16模型在ImageNet上达到了79.9%的准确率,Significantly higher than the training from the very beginning2%,但仍比监督预训练低4%.附录B.1.2包含了更多的细节.我们将对比预训练的探索(Chen等人,2020b;他等人,2020年;Bachman等人,2019年;H‘enaff等人,2020年)留给未来的工作.
5 CONCLUSION
我们探索了transformer在图像识别中的直接应用.Unlike previous work using self-attention in computer vision,除了最初的patch提取步骤外,We do not introduce image-specific inductive biases into the architecture.相反,我们将图像解释为一系列patch,并使用NLPIt is processed by the standard transformer encoder used in.This simple but scalable strategy when combined with pre-training on large datasets,works amazingly well.因此,Vision TransformerMatches or exceeds state-of-the-art on many image classification datasets,but relatively cheap pre-training.
虽然这些初步结果令人鼓舞,但仍存在许多挑战.一是将ViT应用于其他计算机视觉任务,如检测和分割.The results of our study,加上Carion等人(2020年)的研究结果,表明了这种方法的前景.另一个挑战是继续探索自我监督的训练前方法.Our initial experiments showed that,Improved self-supervised pre-training,But there is still a big gap between self-supervised pre-training and large-scale supervised pre-training.最后,ViT的进一步扩展可能会导致性能的提高.
边栏推荐
猜你喜欢







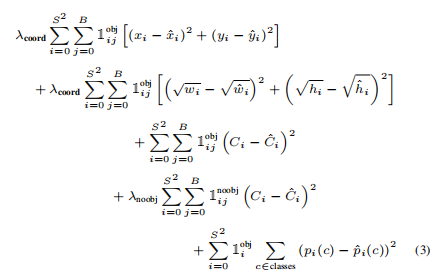
随机推荐
100+开箱即用的AI工具箱;程序员150岁长寿指南;『地理空间数据科学』课程资料;Graphic数据可视化图表库;前沿论文 | ShowMeAI资讯日报
国能准能集团研发矿山数字孪生系统 填补国内采矿行业空白
win10 uwp 让焦点在点击在页面空白处时回到textbox中
虚拟补丁备忘单
From functional testing to automated testing, do you know their shortcomings?
IMX6ULL—汇编LED灯
史上最全架构师知识图谱(纯干货)
C的一些琐碎
5.4 总结
winpe工具WEPE微PE工具箱
Typora 结合 Picgo 自动上传图像
什么是ROS
重庆智博会|2022智博会到底有哪些看点?拭目以待
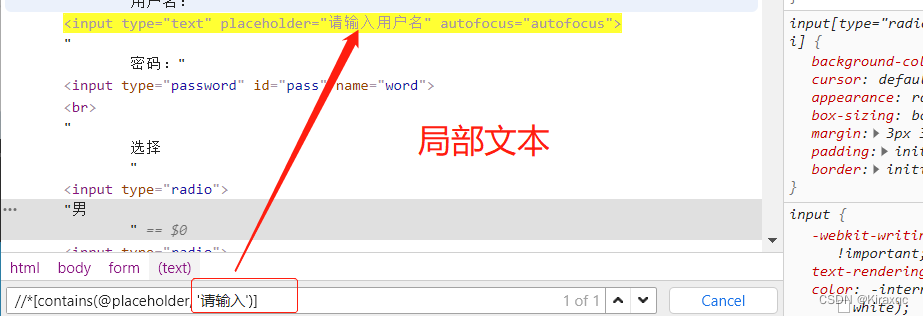
web正则表达式中^和$的含义是什么
What is the Treasure Project (TPC), a dark horse with wings in 2022!
ThreadLocal 夺命 11 连问,万字长文深度解析
线性代数学习笔记
程序健壮性
HarmonyOS - 基于ArkUI (JS) 实现图片旋转验证
Sublime Text如何安装Package Control