当前位置:网站首页>Spike project harvest
Spike project harvest
2022-08-10 15:58:00 【westbrook gorilla】
目录
Corresponding to the enlightenment of the three-layer model
The solution adopted in this project to solve the shortcomings of master-slave replication:使用缓存
How to ensure data consistency for this program(Solve data inconsistency after introducing cache):
Points to focus on for caching focus:
缓存库存:Transaction performance optimization
The specific realization of traffic peak shaving in this project
Queue flood discharge principle
How to achieve anti-brush current limit
Introduction to the current limiting technology:
Other current limiting algorithms(了解)
Current limiting and queue flooding(流量削峰)的再理解:
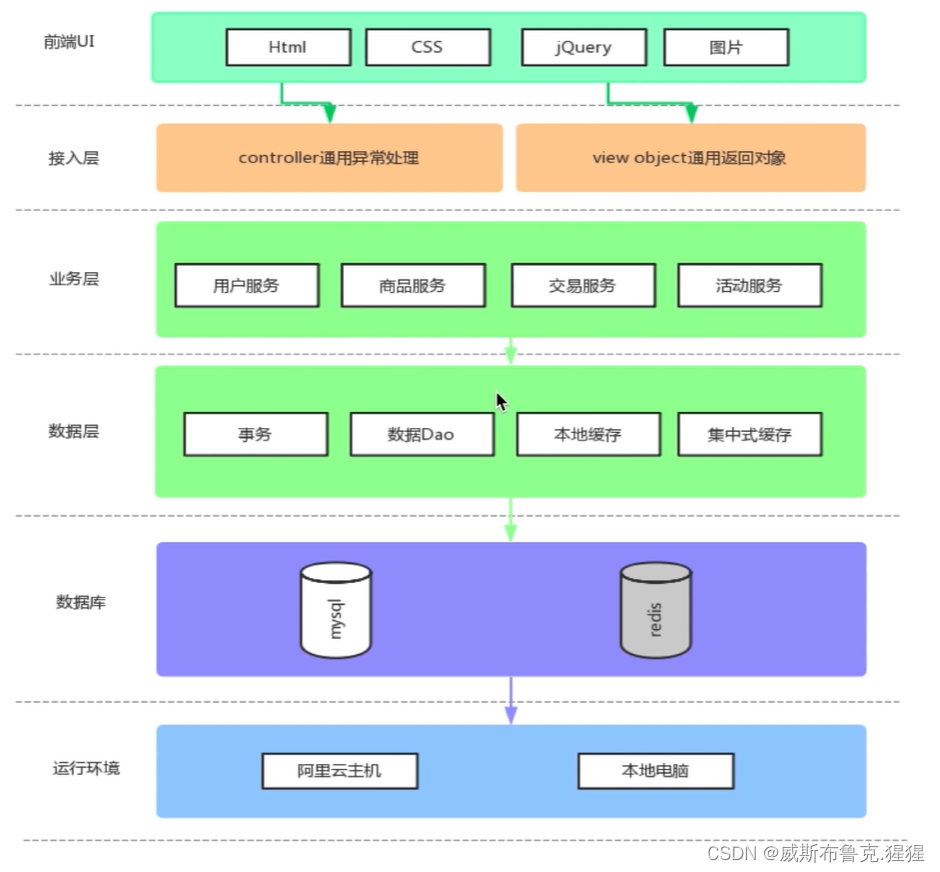
项目架构设计
What are the benefits of layered design:
1. 分层的设计可以简化系统设计,让不同的人专注做某一层次的事情;2. 分层之后可以做到很高的复用;3. 分层架构可以让我们更容易做横向扩展,比如说:业务逻辑里面包含有比较复杂的计算,导致 CPU 成为性能的瓶颈,那这样就可以把逻辑层单独抽取出来独立部署,然后只对逻辑层来做扩展,这相比于针对整体系统扩展所付出的代价就要小的多了
The access layer usesspring MVC的controller;
The business layer usesmybatisThe access and data layer model ofmybatis的ORMA capability model for manipulating databases
终端显示层:各端模板渲染并执行显示的层.当前主要是 Velocity 渲染,JS 渲染, JSP渲染,移动端展示等.Controller层:ControllerThe layer is to do a request forwarding,it receives from the client/Parameters from external pages,传给ServiceLayer to do the processing,然后收到ServiceThe result returned by the layer,再传给页面.简单理解就是:Controller——>Service——>Dao(Mapper).
Service 层:业务逻辑层.Is through the roughlyDaoVarious encapsulation using layer data,form a service,跟controller层交互.用来作为controller层与daobridges between layers.Here is the transaction control of the database(增删改查).至于ServiceAll the methods in the interface are declared,在Serviceimpl部分具体实现.dataobject:mybatis自动生成的;
dao层:mybatis自动生成的mapper文件
validator:数据校验
error:异常处理
pom.xml :公共依赖
config:全局配置
resources :测试需要用的资源库
数据层:事务@TranscantionalAnnotation processing means representation:in a transaction,若一个事务中有任何一个步骤失败,事务就会回滚
数据接入层数据Dao:本地缓存、集中式缓存在商品详情页的应用,提高流式读取的效率
整个流程是:整个页面基于HTML、CSS,然后基于JavaScript的jQuery库发送了一个动态交互的请求,给接入层controller进行通用处理,然后我们基于SpringMVC的controller层会向业务层调用相应的服务,业务层会调用数据层的Dao,通过事务管理数据DaoMapper的方式将数据的增删改查落入到数据库中,最后到本地电脑中
数据模型(Data Object):借助于Mybatis的ORM操作将关系型数据库的表结构,通过XML的方式,定义成Java的Object结构
领域模型(Domain Model):具有一个对象的生命周期(创建、更新、删除、消亡),它可以和数据模型组合,比如用户对象是一个领域模型,它是由用户基本信息+用户密码信息两个数据模型共同组成的.
贫血模型:项目里的用户对象就设计成贫血模型:指的是拥有各种属性信息和get、set方法,but does not include login、注册等功能
ViewObject:与前端对接的模型,供展示的聚合模型
Corresponding to the enlightenment of the three-layer model
The top layer is the view model of the product(前端页面的展示);The middle layer is the domain model corresponding to the product,Aggregation used for commodity service model;The lower layer is the database model,A domain model may correspond to multiple database models,Multiple database models depending on the design of the database,And then aggregated into a domain model,Several domain models are aggregated into the view model of the upper-level spike product
异常处理
全局异常统一处理
By intercepting all exceptions,Handle various exceptions accordingly,When an exception is encountered, it is thrown layer by layer,Has been thrown to the final by a uniform、A place dedicated to exception handling,This facilitates the maintenance of exceptions.
在BaseController中,使用 @ExceptionHandler(Exception.class)处理 controller 层抛出的 Exception定义 EmBusinessError Enumerate unified management error codes;包装器业务异常类实现:包装了 CommonError 即 EmBusinessError,Resolved that enumeration cannot new 对象的问题MD5加密
The login part for useJava的MD5加密,既JDK自带的MessageDigest,due to the simple use ofmd5很容易被识破,Simple processing of the original string
public String EncodeByMd5(String str) throws NoSuchAlgorithmException,UnsupportedEncodingException { //确定计算方法 MessageDigest md5 = MessageDigest.getInstance("MD5"); BASE64Encoder base64en = new BASE64Encoder(); //加密字符串 String newstr = base64en.encode(md5.digest(str.getBytes("utf-8"))); return newstr; }
数据库设计
1. 为什么要将商品的库存表item_stock与商品表item分开?
库存操作非常耗时、性能,在商品交易过程中库存减,如果合并到item表中,Each time the corresponding line is added行锁.如果分开库存表,虽然每次减库存过程还是会加行锁,But this table can be split into another database,分库分表,做效果的优化
数据库优化:查询请求增加时,如何做主从分离?
Assume that a single item is killed in the Double Eleven event,It will undoubtedly lead to a sudden increase in the number of queries.When query requests increase,Need to separate master and slave to solve the problem.主从读写分离
大部分系统的访问模型是读多写少,读写请求量的差距可能达到几个数量级.This system is also.因此,Prioritize how the database can withstand higher query requests,So first of all, you need to distinguish between read and write traffic,因为这样才方便针对读流量做单独的扩展,This is the master-slave read-write separation主从读写的两个技术关键点
Generally in the master-slave read-write separation mechanism,Copy the data of a database into one or more copies,并且写入to another database server,The original database is called the main database,主要负责数据的写入,拷贝的目标数据库称为从库,主要负责支持数据查询.There are two technical key points in the separation of master-slave read-write:1. One is a copy of the data,我们称为主从复制;2. In the case of master-slave separation,How to shield the changes in the way of accessing the database brought about by the separation of master-slave,Make developers feel like they are using a single database.做了主从复制之后,You can write only the main library when writing,在读数据时只读从库,This way even if the write request Will lock the table or lock the record,也不会影响到读请求的执行.同时,在读流量比较大的情况下,可以部署多个从库共同承担读流量,这就是“一主多从”部署方式.In this way, the project can resist high concurrent read traffic.另外,The slave library can also be used as a standby library to use用,以避免主库故障导致数据丢失.1.主从复制的缺点:
主从复制也有一些缺陷,除了带来了部署上的复杂度,In addition, it will bring a certain master-slave步的延迟,这种延迟有时候会对业务产生一定的影响.读写分离后,主从的延迟是一个关键的监控指标,可能会造成写入数据之后立刻读的时候读取不到的情况;例如:在发微博的过程中会有些同步的操作,像是更新数据库的操作,也有一些异步的操作,比如Said to synchronize Weibo information to the auditing system,所以我们在更新完主库之后,会将微博的 ID write message queue列,再由队列处理机依据 ID 在从库中获取微博信息再发送给审核系统.If the master-slave data at this timeInventory is delayed,会导致在从库中获取不到微博信息,整个流程会出现异常.The solution adopted in this project to solve the shortcomings of master-slave replication:使用缓存
While synchronously writing to the database,也把微博的数据写入到redis缓存里面,这样队列处理机在获取微博信息的时候会优先查询缓存,(redisCache takes precedence over database lookups)但是Data consistency cannot be guaranteedThe reason why the cache cannot guarantee data consistency:In the case of updating data,Updating the cache first may cause data inconsistencies,Let's say two threads update data at the same time,线程 A Update the data in the cache to 1,此时另一个线程 B Update the data in the cache to 2,然后线程 B Then update the data in the database to 2,此时线程 A 更新
数据库中的数据为 1,这样数据库中的值(1)和缓存中的值(2)就不一致了.How to ensure data consistency for this program(Solve data inconsistency after introducing cache):
引入rocketmq,利用rocketmqThe transactional messages eventually resolve the eventual consistency of the data
综上,This project relies on the technology of master-slave replication to make the database replicate data into multiple copies,增强了抵抗大量并发读请求的能力,提升了数据库的查询性能的同时,也提升了数据的安全性,当某一个数据库节点,无论是主库还是从库发生故障时,我们还有其他的节点中存储着全量的数据,保证数据不会丢失.
缓存简介:
缓存:是一种存储数据的组件,它的作用是让对数据的请求更快地返回.实际上,凡是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构,均可称之为缓存.内Storage is the most common medium for caching data.Caching can improve access speed for slow devices,Or reduce performance problems caused by complex and time-consuming calculations.理论上说,We can solve all the problems with caching“慢”的问题,比如从磁盘随机读取数据慢,从Database query data is slow,It's just that different scenarios consume different storage costs.缓冲区:缓冲区则是一块临时存储数据的区域,这些数据后面会被传输到其他设备上.缓存分类:
常见的缓存主要就是静态缓存、分布式缓存和热点本地缓存这三种.静态缓存:Usually generated by Velocity 模板或者静态 HTML文件来实现静态缓存,在 Nginx 上部署静态缓存可以减少对于后台应用服务器的压力,这种缓存只能针对静态数据来缓存,Can't do anything about dynamic requests.分布式缓存:通过一些分布式的方案组成集群可以突破单机的限制;主要For dynamic pleaseask for cache.热点本地缓存:When encounter extreme hot data query.热点本地缓存主要部署在应用服务器的代码中,用于阻挡热点查询对于分布式缓存节点或者数据库的压力.For example, a celebrity has a hot topic on Weibo,“吃瓜群众”会到他 (她) 的微博首页围观,这就It will trigger the hot query of this user information.These queries usually hit a certain cache node or a certain database partition区,短时间内会形成极高的热点查询.缓存的不足:
首先,Cache is more suitable for business scenarios with more reads and fewer writes,And the data preferably has a certain hotspot attribute,这是因为After all, the cache will be limited by the storage medium and it is impossible to cache all the data,Then when the data has hotspot attributes, it can guarantee afixed cache hit rate.For example, something like a circle of friends 20% 的内容会占到 80% 的流量.所以,一旦当业务场景读少写多时或者没有明显热点时,比如在搜索的场景下,Everyone's search terms会不同,没有明显的热点,那么这时缓存的作用就不明显了.其次,缓存会给整体系统带来复杂度,and there is a risk of data inconsistency.当更新数据库成功,更In the scenario where the new cache fails,缓存中就会存在脏数据.对于这种场景,You can consider using a shorter expiration time or manual cleaning to solve the problem.总而言之,As long as use the cache can't completely solve the dirty reads,Only flush the cache as quickly as possible after an update So the business must be able to tolerate short dirty reads.再次,As mentioned earlier, caches usually use memory as a storage medium,但是内存并不是无限的.因此,When using cache, it is necessary to evaluate the amount of data storage,对于可预见的需要消耗极大存储成本的数据,要慎用缓存方案.同时,缓存一定要设置过期时间,这样可以保证缓存中的会是热点数据.最后,缓存会给运维也带来一定的成本,运维需要对缓存组件有一定的了解,troubleshootingThere is one more component to take into account when.Points to focus on for caching focus:
1. 缓存可以有多层,比如上面提到的静态缓存处在负载均衡层,Distributed cache at the application layer and databetween database layers,本地缓存处在应用层.我们需要将请求尽量挡在上层,因为越往下层,对于Concurrent tolerance is worse;2. The cache hit rate is one of our most important monitoring items for caching,越是热点的数据,Cache hit ratio is more高.3. 缓存不仅仅是一种组件的名字,更是一种设计思想,Can think anything canComponents and design solutions that can accelerate read requests are the embodiment of caching ideas.And this acceleration is usually achieved in two ways现:a. 使用更快的介质,For example, the memory mentioned in the course;b. 缓存复杂运算的结果,For example in front TLB An example is caching the result of address translation;4. When encountering in actual work“慢”的问题时,The cache is the first time to consider.多级缓存:查询性能优化
This seckill project uses the stand-alone versionredis,但是弊端是redis容量问题,单点故障问题
redisThere is no way to provide full consistency of transactions ,So the design of the project is to allow undersell but not oversell
Project the cache in logic
Now the logic to fetch the cache becomes:本地缓存 ---> redis缓存 ---> 数据库
//商品详情页浏览 @RequestMapping(value = "/get",method = {RequestMethod.GET}) @ResponseBody public CommonReturnType getItem(@RequestParam(name = "id")Integer id){ ItemModel itemModel = null; //先取本地缓存 itemModel = (ItemModel) cacheService.getFromCommonCache("item_"+id); if(itemModel == null){ //根据商品的id到redis内获取 itemModel = (ItemModel) redisTemplate.opsForValue().get("item_"+id); //若redis内不存在对应的itemModel,则访问下游service if(itemModel == null){ itemModel = itemService.getItemById(id); //设置itemModel到redis内 redisTemplate.opsForValue().set("item_"+id,itemModel); redisTemplate.expire("item_"+id,10, TimeUnit.MINUTES); } //填充本地缓存 cacheService.setCommonCache("item_"+id,itemModel); } ItemVO itemVO = convertVOFromModel(itemModel); return CommonReturnType.create(itemVO); }redisThere is no way to provide full consistency of transactions So the design of the course is to allow undersell but not oversell
redisThe addition and subtraction commands themselves can guarantee atomicity,Multiple concurrent operations change data without error
缓存库存:Transaction performance optimization
交易性能瓶颈
- jmeter压测(对活动下单过程进行压测,采用post请求,设置传入参数,性能发现下单avarage大约2s,tps500,交易验证主要完全依赖数据库的操作)
- 交易验证完全依赖数据库
解决方案:库存行锁优化
Review before the operation of inventory reduction:
<update id="decreaseStock"> update item_stock set stock = stock - #{amount} where item_id = #{itemId} and stock >= #{amount} </update>库存的数量就是
stock-amountcondition is commodityitemId和stock的大小大于amount,条件是item_id要加上唯一索引,When this query add row lock for the database,否则是数据库表锁解决方案:异步同步数据库
采用异步消息队列的方式,将异步扣减的消息同步给消息的consumer端,并由消息的consunmerThe terminal completes the operation of the database deduction
(1)活动发布同步库存进缓存
(2)下单交易减缓存库存
(3)Asynchronous messages deduct database memory
异步消息队列rocketmq
具体的实现过程为:
- If the stock of the spike product is still available,Then generate a seckill message and send it to the message queue(The information contains user information and productsid);
- After the consumer of the message receives the seckill message,Read from the database whether the user has completed the spike,如果没有,reduce inventory,下订单,Write the order information in the database.
常见的异步消息中间件用到的有ActiveMQ(实现java的AMS)、Kafka(基于流式处理)、RocketMQ是阿里巴巴基于Kafka改造的一种异步消息队列
为什么要使用RocketMQ?
答: 为了redisNo data is lost when hanging
引入RocketMQ:one can solveredis和数据库一致性的问题,The second is to reduce inventory row lock competition,先执行creatOrder事务,Asynchronous execution to reduce inventory,This can reduce transaction lock holding time and reduce row lock competition;Asynchronous processing simplifies business processes in spike requests,提升系统的性能
其它问题:
1. Introduce transactional messagesRocketMQ是为了解决redisAnd database consistency problem in the end,But there will still be message rollbacks,Database deduction failed,redisInconsistency with the database,So why introduce transactional messages??
防止redisAfter hanging up, there is a problem with the database,redisThe system is unavailable,Because there is no way to ensure the data andredis是同步的
2. 第一阶段中,redisPlace an order after a successful inventory reductiondb操作失败了,The inventory of the final database will not be reduced,这时候redisIsn't it inconsistent with the database inventory??如果不一致,So and do not use the transaction message scheme is not without what's the difference?
redisIf the deduction is successful,Failure to place an order will result inredisInventory cannot be rolled back,Business is acceptable in this case,除非redisalso use transactional operations,Otherwise, there is no way to share the transaction with the order request;But with the transaction performance decreases,因此这里假定redisThe probability of order failure after deduction is successful is almost small,Because all verification and other operations are done in advance,除非db挂了.
inventory consistency issues
1. 库存redisAsynchronous with the database,The number of stocks in the product display is usedredisOr in the database?2. 目前redis和providerThe message is consistent,If the newsconsumer处理失败,still not guaranteedredisConsistent with the final transaction of the database?About display problems,按照redis中取,Can't get it out and get the database again,If the data in the database is updated,比如下单成功,send an asynchronous message to clearredis数据,In this way, the next time you come over, you can go to the database to get the correct data.,Of course, there will also be deductions in inventory that are not cleared.redis快,But in business, it is not necessary to be so real-time on the display level of how many pieces are left in stock..consumerProcessing failure is divided into two cases:
How the project is guaranteed产生的消息一定会被消费到,and is only consumed once?
问题引入:
During the learning process of the project,These two questions are very important:1. 如果producer消息发送成功,consumer端接收到了消息,Then it fails when writing to the database,未写入,Then the data previously stored in the database(如订单信息)怎么办,Has been written to cannot be rolled back;2. If the database operation is successful,But the returned consumption success is notmq接收到,Will the retry cause the data in the database to be deducted more??怎么避免这种情况呢?
explanation found:
1. If it is not written successfully, it will not return the consumption success.,The message middleware will retry itself
2. Consumers need to be idempotent,课程中的stock_logThat's what the table does
Here's an in-depth look at the issue
要保证产生的消息一定会被消费到,and is only consumed once,需要考虑两个方面:
1. 避免消息丢失
The message is written to the message queue from,到被消费者消费完成,There are three main places on this link where there is a possibility of lost messages:A. 消息从生产者写入到消息队列的过程针对这种情况,The scheme adopted is message retransmission:That is, when it is found that the sending time out, the message will be resent.,but also cannot retransmit messages indefinitely.一般来说,If not the message queue failed,Or the network to the message queue is disconnected,重试 2~3 次就可以了.B. 消息在消息队列中的存储场景If you need to ensure that not a single message is lost,建议不要开启消息队列的同步刷盘,Instead, use a cluster approach to solve,可以配置当所有 ISR Follower 都接收到消息才返回成功.如果对消息的丢失有一定的容忍度,It is not recommended to deploy clusters,This project adopts this method.C. 消息被消费者消费的过程Wait until the message is received and processed before updating the consumption progress总结:为了避免消息丢失,We need to pay the price in two ways:一方面是性能的损耗;一方面可能造成消息重复消费.2. 保证消息只被消费一次
It is very difficult to completely avoid the occurrence of message duplication,因此我们会把要求放宽,Guaranteed even if duplicate messages are consumed,从消费的最终结果来看和只消费一次是等同的就好了,也就是保证在消息的生产和消费的过程是“幂等”的.Messages may be duplicated during both production and consumption,所以,Increase the guarantee of message idempotency during production and consumption,这样就可以认为从“最终结果上来看”,The message is actually only consumed once.during message production:Guaranteed messages may be duplicated on the production side,But in the end, only one copy will be stored when the message queue is stored. The specific approach is to give each producer a unique ID,And give each message produced a unique ID,消息队列的服务端会存储 < 生产者 ID,最后一条消息 ID> 的映射.当某一个生产者产生新的消息时,The message queue server will compare the messages ID 是否与存储的最后一条 ID 一致,如果一致,considered a duplicate message,服务端会自动丢弃.The guarantee of idempotency on the consumer side is slightly more complicated,from the general layer and the business layer两个层面来考虑:
at the general level,You can do this while the message is being produced,Use the sender to generate a globally unique message to it ID,消息被处理之后,把这个 ID 存储在数据库中,在处理下一条消息之前,From the database to check firstquery this global ID 是否被消费过,如果被消费过就放弃消费.总结:可以看到,Whether it is the idempotency guarantee method on the production side,Or is it a general idempotent guarantee method on the consumer side?,Their common feature is that each message generates a unique ID,Then when using this message,Than the firstID 是否已经存在,如果存在,the message is considered to have been used.So this way is a standard implementation idempotent,Can be used directly in the project.
不过这样会有一个问题:如果消息在处理之后,还没有来得及写入数据库,Consumers are downAfter opening, it is found that this message does not exist in the database,还是会重复执行两次消费逻辑,At this time, a transaction mechanism needs to be introduced,保证消息处理和写入数据库必须同时成功或者同时失败,But the cost of such message processing就更高了,所以,If there are no particularly strict requirements for message repetition,可以直接使用这种通用的方案,而不考虑引入事务.在业务层面,There are many ways to deal with,One of them is to add optimistic locking.比如, The message handler needs to add money to a person's account,Then it can be solved by optimistic locking.The specific operation method is as follows:Add a version number field to each person's account data,在生产消息时先查询这个账户的版本号,and send the version number along with the message to the message queue.Consumers get the messageand version number after,在执行更新账户金额 SQL 的时候带上版本号,类似于执行:update user set amount = amount + 20, version=version+1 where userId=1 and versOptimistic locking is added to data when updating data,这样在消费第一条消息时,version 值为 1,SQL可以执行成功,并且同时把 version 值改为了 2;When executing the second same message,由于version 值不再是 1,所以这条 SQL 不能执行成功,It also guarantees the idempotency of the message..
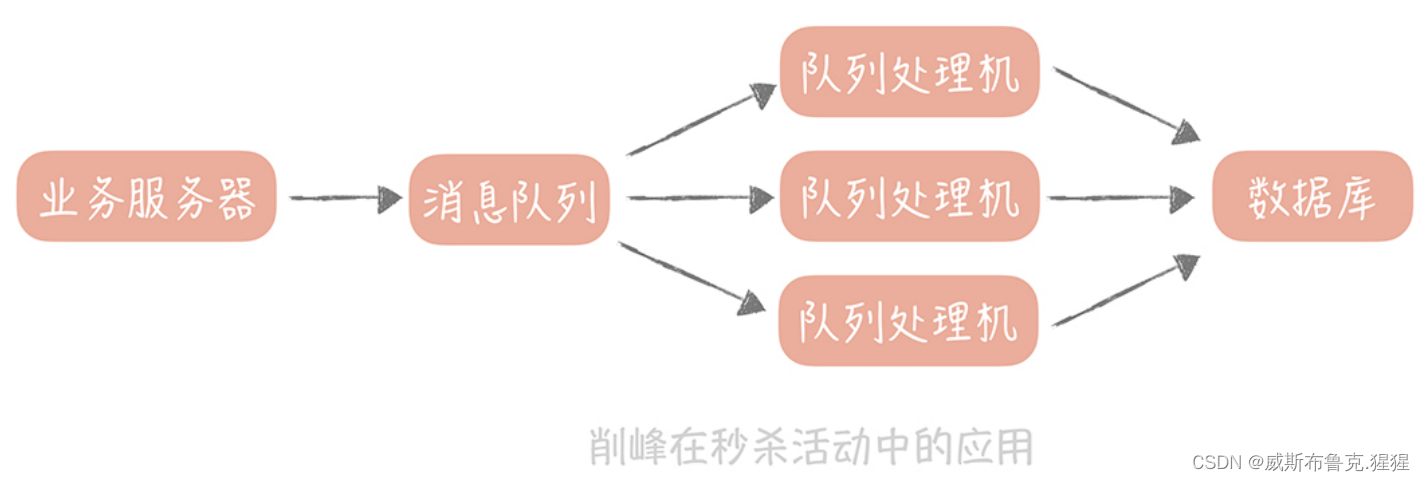
秒杀时如何处理每秒上万次的下单请求(流量削峰)?
For e-commerce projects,When seconds kill activity started early,More and more people may be just browsing goods what are the kill,Is there anything that suits you or your needs?,Only a part of the real participation in the spike activity;此时,整体的流量比较小,而写流量可能只占整体流量的百分之一,那么即使整体的 QPS 到了 10000 次 / 秒,写请求也只是到了每秒 100 次,如果要对写请求做性能优化,它的性价比确实不太高.
但是,When the seckill is about to start,后台会显示用户正在疯狂地刷新 APP 或者浏览器来保证自己能够尽量早的看到商品. 这时,The face is still that the read request is too high,那么应对的措施有哪些呢?因为用户查询的是少量的商品数据,属于查询的热点数据,Caching strategy can be used,将请求尽量挡在上层的缓存中,能被静态化的数据,比如说商城里的图片和视频数据,be as static as possible化,这样就可以命中 CDN 节点缓存,减少 Web 服务器的查询量和带宽负担.Web 服务such as Nginx 可以直接访问分布式缓存节点,这样可以避免请求到达 Tomcat 等业务服务器.当然,Some current-limiting strategies can be added,比如,对于短时间之内来自某一个用户、某一个 IP 或The repeated request of a certain device is discarded..通过这几种方式,You can keep requests out of the database as much as possible.稍微缓解了读请求之后,00:00 分秒杀活动准时开始,用户瞬间向电商系统请求生成订单,扣减库存,用户的这些写操作都是不经过缓存直达数据库的.1 秒钟之内,有 1 万个数据library connections are reached at the same time,系统的数据库濒临崩溃,It is urgent to find a write request solution that can cope with such high concurrency睫.Then use the message queue.在秒杀场景下,The write traffic of the database will be very high in a short period of time,According to the previous thinking, the data should be divided into sub-databases and sub-tables.如果已经做了分库分表,那么就需要扩展更多的数据库来应对更高的写流量.But whether it is a sub-library or sub-table,Still expanded more database,都会比较复杂,The reason is that the data in the database needs to be migrated,This time will be calculated by day or even by week..而在秒杀场景下,高并发的写请求并不是持续的,也不是经常发生的,And only when the seckill event opensStart after a few seconds or ten seconds will exist.In order to cope with the instant writing peak of these ten seconds,it will take a few daysUp to a few weeks to scale the database,再在秒杀之后花费几天的时间来做缩容,This is undoubtedly worth the loss的.This project aimed at cutting processing so short time flow:Temporarily store the seckill request in the message queue,然后业务服务器会响应用户“秒杀结果正在计算中”,Process other users' requests after releasing system resources.在后台启动若干个队列处理程序,消费消息队列中的消息,再执行校验库存、下单等逻辑.因为只有有限个队列处理线程在执行,所以落入后端数据库上的并发请求是有限的.而请求是可以在消息队列中被短暂地堆积,当库存被消耗完之后,消息队列中堆积的请求就可以被丢弃了.This is the main role of the message queue in the seckill system:削峰填谷,That is to say, it can smooth out short-term high traffic峰,虽说堆积会造成请求被短暂延迟处理,But as long as you always monitor the accumulation length in the message queue,在堆积量超过一定量时,Increase the number of queue processors,to improve the processing ability of the message.,Moreover, the users of the seckill know the result of the seckill for a short delay,There is also a certain tolerance.这里需要注意一下,“短暂”延迟,If the result of the spike has not been announced to the user for a long time,Then users may suspect that your spike activity is tricky.所以,When using message queues to cope with traffic spikes,需要对队列处理的时间、前端写入流量的大小,数据库处理能力做好评估,然后根据不同的量级来决定部署多少台队列处理程序.For example, spike products have 1000 件,处理一次购买请求的时间是 500ms,那么总共就需要 500s的时间.这时,部署 10 个队列处理程序,那么秒杀请求的处理时间就是 50s,也就是说用户需要等待 50s 才可以看到秒杀的结果,这是可以接受的.这时会并发 10 个请求到达数据库,并不会对数据库造成很大的压力.The specific realization of traffic peak shaving in this project
Due to the underlying code structure:There may be scalpers using scripts to maliciously place orders,秒杀下单接口会被脚本不停的刷;秒杀验证逻辑和秒杀下单接口强关联,代码冗余度高;秒杀下单和对活动是否开始是没有关联的,接口关联过高
So implement the following optimization:
Seckill token implementation
- 秒杀接口需要依靠令牌才能进入
- 秒杀的令牌由秒杀活动模块负责生成
- 秒杀活动模块对秒杀令牌生成全权处理,逻辑收口
- 秒杀下单前需要先获得秒杀令牌
The token limits the number of orders placed in seconds
PromoService接口上实现generateSecondKillToken秒杀令牌生成函数
//生成秒杀用的令牌 String generateSecondKillToken(Integer promoId,Integer itemId,Integer userId);PromoServiceImpl类
public String generateSecondKillToken(Integer promoId,Integer itemId,Integer userId) { PromoDO promoDO = promoDOMapper.selectByPrimaryKey(promoId); //promoDo(dataObject) -> PromoModel PromoModel promoModel = convertFromDataObject(promoDO); if(promoModel == null) { return null; } //判断当前时间是否秒杀活动即将开始或正在进行 DateTime now = new DateTime(); if(promoModel.getStartDate().isAfterNow()) { promoModel.setStatus(1); }else if(promoModel.getEndDate().isBeforeNow()) { promoModel.setStatus(3); }else { promoModel.setStatus(2); } //判断活动是否正在进行 if(promoModel.getStatus().intValue()!=2){ return null; } //判断item信息是否存在 ItemModel itemModel = itemService.getItemByIdInCache(itemId); if(itemModel == null) { return null; } //判断用户信息是否存在 UserModel userModel = userService.getUserByIdInCache(userId); if(userModel == null) { return null; } //生成token并且存入redis设置5Group validity period String token = UUID.randomUUID().toString().replace("-",""); redisTemplate.opsForValue().set("promo_token_"+promoId+"_userid_"+userId+"_itemid_"+itemId,token); redisTemplate.expire("promo_token_"+promoId+"_userid_"+userId+"_itemid_"+itemId,5, TimeUnit.MINUTES); return token; }OrderController类
//生成秒杀令牌 @RequestMapping(value = "/generatetoken",method = {RequestMethod.POST},consumes={CONTENT_TYPE_FORMED}) @ResponseBody public CommonReturnType generatetoken(@RequestParam(name="itemId")Integer itemId, @RequestParam(name="promoId")Integer promoId) throws BusinessException { //根据token获取用户信息 String token = httpServletRequest.getParameterMap().get("token")[0]; if(StringUtils.isEmpty(token)){ throw new BusinessException(EmBusinessError.USER_NOT_LOGIN,"用户还未登陆,不能下单"); } //获取用户的登陆信息 UserModel userModel = (UserModel) redisTemplate.opsForValue().get(token); if(userModel == null){ throw new BusinessException(EmBusinessError.USER_NOT_LOGIN,"用户还未登陆,不能下单"); } //获取秒杀访问令牌 String promoToken = promoService.generateSecondKillToken(promoId,itemId,userModel.getId()); if(promoToken == null){ throw new BusinessException(EmBusinessError.PARAMETER_VALIDATION_ERROR,"生成令牌失败"); } //返回对应的结果 return CommonReturnType.create(promoToken); }But there are still flaws:秒杀令牌只要活动一开始就无限制生成,影响系统性能;The following continues to explain the way to solve this defect.
秒杀大闸原理及实现
依靠秒杀令牌的授权原理定制化发牌逻辑,Do the gate function
Issue the corresponding number of tokens according to the initialized inventory of the seckill product,控制大闸流量
用户风控策略前置到秒杀令牌发放中
库存售罄判断前置到秒杀令牌发放中
设置一个以秒杀商品初始库存x倍数量作为秒杀大闸,若超出这个数量,则无法发放秒杀令牌
//Set the gate limit number toredis内 redisTemplate.opsForValue().set("promo_door_count_"+promoId,itemModel.getStock().intValue()*5);There are still flaws:秒杀活动开始,用户瞬间向电商系统请求生成订单, 用户的这些写操作都是不经过缓存直达数据库的.1 秒钟之内,有 1 万个数据library connections are reached at the same time,系统的数据库濒临崩溃,Then use the message queue;This is also the most important point;即surge flow
Queue flood discharge principle
so-called queue flood,is to open a new thread pool,to execute different orders in multiple threads,Equivalent to using a congestion window to discharge floods
- 排队有些时候比并发更高效(例如redis单线程模型,innodb mutex key等)
innodb在数据库操作时要加上行锁,mutex key是竞争锁,阿里sql优化了mutex key结构,当判断存在多个线程竞争锁时,会设置队列存放SQL语句
依靠排队去限制并发流量
依靠排队和下游拥塞窗口程度调整队列释放流量大小
支付宝银行网关队列举例
支付宝有多种支付渠道,在大促活动开始时,支付宝的网关有上亿级别的流量,银行的网关无法支持这种大流量,支付宝会将支付请求放到自己的队列中,根据银行网关可以承受的tps流量调整拥塞窗口,去泄洪
OrderController类
private ExecutorService executorService; @PostConstruct public void init(){ //定义一个只有20个可工作线程的线程池 executorService = Executors.newFixedThreadPool(20); } //同步调用线程池的submit方法 //拥塞窗口为20的等待队列,用来队列化泄洪 Future<Object> future = executorService.submit(new Callable<Object>() { @Override public Object call() throws Exception { //加入库存流水init状态 String stockLogId = itemService.initStockLog(itemId,amount); //再去完成对应的下单事务型消息机制 if(!mqProducer.transactionAsyncReduceStock(userModel.getId(),itemId,promoId,amount,stockLogId)){ throw new BusinessException(EmBusinessError.UNKNOWN_ERROR,"下单失败"); } return null; } }); try { future.get(); } catch (InterruptedException e) { throw new BusinessException(EmBusinessError.UNKNOWN_ERROR); } catch (ExecutionException e) { throw new BusinessException(EmBusinessError.UNKNOWN_ERROR); } return CommonReturnType.create(null); }关注点:
1. Congestion Window Utilization Creation20The size of fixed by passing in thread poolcallable对象并执行其callmethod to submit the running of the thread,并通过futureobject to get the result of its execution;This does not mean that including the number of core threads at least20多个线程并发执行,So how should we understand the issue of thread safety?,是redissingle-threaded model or row locks for database operations??
答: Multithreading and use of thread poolsspring mvcmultithreading is a concept;webThe application itself has a thread pool, how to lock the lock can be
2. If the volume of requests exceeds the capacity of the queue,How to deal with these extra requests?
答: If the system cannot handle these volumes,If you don't refuse to process the system, it will hang.;So design taking rather than refusing to ensure the normal operation of the system also can't let system hang up.
3. 用FutureWhat's with the queue?,futureIt just means waiting for the task in the thread pool to complete and then returning the output result,then it doesn't workBlockQuene?
答:首先:There is a waiting queue in the thread pool,就是用blockqueue实现的,We submit the task to the thread pool,After an executable threads in a thread pool with the task in a wait queue,Doing so is tantamount to limiting the concurrent traffic of users,Make it queued for processing in the waiting queue of the thread pool.然后futureThe use is to allow front-end users to callcontrollerAfter that, the result of the execution can be obtained synchronously; 用futureJust to get the result after thread pool execution,和future队列无关,Just use the queue of the thread pool to queue all executions
本地或分布式
- 本地:maintained in memory,没有网络消耗,性能高,只要jvm不挂,then the application server is alive
- 分布式:There is a problem with network consumption,rediswill become a system bottleneck,当redis挂了,it's all cool.
比如说我们有100台机器,假设每台机器设置20个队列,那我们的拥塞窗口就是2000,但是由于负载均衡的关系,很难保证每台机器都能够平均收到对应的createOrder的请求,那如果将这2000个排队请求放入redis中,每次让redis去实现以及去获取对应拥塞窗口设置的大小,这种就是分布式队列
本地队列的好处就是完全maintained in memory的,因此其对应的没有网络请求的消耗,只要JVM不挂,app is alive,那本地队列的功能就不会失效.因此企业级开发应用还是推荐使用本地队列,本地队列的性能以及高可用性对应的应用性和广泛性.可以使用外部的分布式集中队列,当外部集中队列不可用时或者请求时间超时,可以采用降级的策略,切回本地的内存队列;分布式队列+local memory queue,Enterprise-level high-availability queue flood discharge solution
How to achieve anti-brush current limit
Introduction to the current limiting technology:
Throttling refers to limiting the number of concurrent requests reaching the system by,保证系统能够正常响应部分用户请求,而对for traffic that exceeds the limit,Guarantee the availability of the overall system by means of denial of service.The current limiting strategy is generally deployed at the entry layer of the service,比如 API 网关中,This can shape the overall flow of the system.验证码技术
包装秒杀令牌前置,需要验证码来错峰
数学公式验证码生成器
// randomCode用于保存随机产生的验证码,以便用户登录后进行验证. StringBuffer randomCode = new StringBuffer(); int red = 0, green = 0, blue = 0; // 随机产生codeCount数字的验证码. for (int i = 0; i < codeCount; i++) { // 得到随机产生的验证码数字. String code = String.valueOf(codeSequence[random.nextInt(36)]); // 产生随机的颜色分量来构造颜色值,这样输出的每位数字的颜色值都将不同. red = random.nextInt(255); green = random.nextInt(255); blue = random.nextInt(255); // 用随机产生的颜色将验证码绘制到图像中. gd.setColor(new Color(red, green, blue)); gd.drawString(code, (i + 1) * xx, codeY); // 将产生的四个随机数组合在一起. randomCode.append(code); } Map<String,Object> map =new HashMap<String,Object>(); //存放验证码 map.put("code", randomCode); //存放生成的验证码BufferedImage对象 map.put("codePic", buffImg); return map; } public static void main(String[] args) throws Exception { //创建文件输出流对象 OutputStream out = new FileOutputStream("/Users/hzllb/Desktop/javaworkspace/miaoshaStable/"+System.currentTimeMillis()+".jpg"); Map<String,Object> map = CodeUtil.generateCodeAndPic(); ImageIO.write((RenderedImage) map.get("codePic"), "jpeg", out); System.out.println("验证码的值为:"+map.get("code")); }在OrderController中加入生成验证码
@RequestMapping(value = "/generateverifycode",method = {RequestMethod.POST,RequestMethod.GET}) @ResponseBody public void generateeverifycode(HttpServletResponse response) throws BusinessException, IOException { //根据token获取用户信息 String token = httpServletRequest.getParameterMap().get("token")[0]; if(StringUtils.isEmpty(token)){ throw new BusinessException(EmBusinessError.USER_NOT_LOGIN,"用户还未登陆,不能生成验证码"); } //获取用户的登陆信息 UserModel userModel = (UserModel) redisTemplate.opsForValue().get(token); if(userModel == null){ throw new BusinessException(EmBusinessError.USER_NOT_LOGIN,"用户还未登陆,不能生成验证码"); } Map<String,Object> map = CodeUtil.generateCodeAndPic(); ImageIO.write((RenderedImage) map.get("codePic"), "jpeg", response.getOutputStream()); redisTemplate.opsForValue().set("verify_code_"+userModel.getId(),map.get("code")); redisTemplate.expire("verify_code_"+userModel.getId(),10,TimeUnit.MINUTES); }生成秒杀令牌前验证验证码的有效性
//通过verifycode验证验证码的有效性 String redisVerifyCode = (String) redisTemplate.opsForValue().get("verify_code_"+userModel.getId()); if(StringUtils.isEmpty(redisVerifyCode)) { throw new BusinessException(EmBusinessError.PARAMETER_VALIDATION_ERROR,"请求非法"); } if(!redisVerifyCode.equalsIgnoreCase(redisVerifyCode)) { throw new BusinessException(EmBusinessError.PARAMETER_VALIDATION_ERROR,"请求非法,验证码错误"); }限流的目的
- 流量远比你想的要多
- 系统活着比挂了要好
- 宁愿只让少数人能用,也不要让所有人不能用
限流方案(限并发)
对同一时间固定访问接口的线程数做限制,利用全局计数器,在下单接口OrderController处加一个全局计数器,并支持并发操作,当controller在入口的时候,计数器减1,判断计数器是否大于0,在出口时计数器加一,就可以控制同一时间访问的固定.
限流范围
集群限流:依赖redisOr other middleware technology to do unified counter,往往会产生性能瓶颈
单击限流:负载均衡的前提下单机平均限流效果更好
令牌桶算法(项目使用)
If we need to limit the number of visits in a second to N 次,Then every 1/N 的时间,往桶内放入一个令牌;Get a token from the bucket before processing the request,If there are no more tokens in the bucket,那么就需要等待The new token or denial of service directly;There is also a limit on the total number of tokens in the bucket,If the limit is exceeded, no new tokens can be added to the bucket.This limits the total number of tokens,To a certain extent, the problem of instantaneous traffic peaks can be avoided.
Using the token bucket algorithm requires the number of tokens to be stored,If the current limit is implemented on a single machine,You can use a variable in the process to store;但是如果在分布式环境下,Variables in a process cannot be shared between different machines,一般会使用 Redis To store the number of the token.这样的话,It needs to be requested once every time it is requested Redis 来获取一个令牌,will add a few milliseconds of delay,性能上会有一些损耗.因此,A compromise idea is: Every time can take the token,No more getting just one token,Instead get a batch of tokens,So that we can minimize the request Redis的次数.It is difficult for the current limiting strategy to confirm the current limiting threshold in practice.,If the setting is too small, it is easy to accidentally damage normal requests,If the setting is too large, the purpose of current limiting will not be achieved..所以,一般在实际项目中,The threshold will be placed in the configuration center to facilitate dynamic adjustment;同时,We can get the overall system and the actual carrying capacity of each microservice through regular stress tests,Then set the appropriate threshold according to the value of this pressure measurement.Other current limiting algorithms(了解)
1. Algorithms based on time window dimension include fixed window algorithm and sliding window algorithm,Although both can be achieved to a certain extent限流的目的,But it can't make the flow smoother;2. 令牌桶算法和漏桶算法can shape the flow,Make the flow smoother,但是The token bucket algorithm can cope with afixed burst traffic,No more than limit;So apply more in real projects.限流代码实现(Guava RateLimit)
RateLimiter没有实现令牌桶内定时器的功能,
reserve方法是当前秒的令牌数,如果当前秒内还有令牌就直接返回;
若没有令牌,需要计算下一秒是否有对应的令牌,有一个下一秒计算的提前量
使得下一秒请求过来的时候,仍然不需要重复计算
RateLimiter的设计思想比较超前,没有依赖于人为定时器的方式,而是将整个时间轴
归一化到一个数组内,看对应的这一秒如果不够了,预支下一秒的令牌数,并且让当前的线程睡眠;如果当前线程睡眠成功,下一秒唤醒的时候令牌也会扣掉,程序也实现了限流private RateLimiter orderCreateRateLimiter; @PostConstruct public void init(){ executorService = Executors.newFixedThreadPool(30); orderCreateRateLimiter = RateLimiter.create(300); }防刷技术
- 排队,限流,令牌均只能控制总流量,无法控制黄牛流量
传统防刷
- 限制一个会话(session_id,token)同一秒/分钟接口调用多少次:多会话接入绕开无效(黄牛开多个会话)
- 限制一个ip同一秒钟/分钟 接口调用多少次:数量不好控制,容易误伤,黑客仿制ip
黄牛为什么难防
- 模拟器作弊:模拟硬件设备,可修改设备信息
- 设备牧场作弊:工作室里一批移动设备
- 人工作弊:靠佣金吸引兼职人员刷单
设备指纹
- 采集终端设备各项参数,启动应用时生成唯一设备指纹
- 根据对应设备指纹的参数猜测出模拟器等可疑设备概率
凭证系统
- 根据设备指纹下发凭证
- 关键业务链路上带上凭证并由业务系统到凭证服务器上验证
- 凭证服务器根据对应凭证所等价的设备指纹参数并根据实时行为风控系统判定对应凭证的可疑度分数
- 若分数低于某个数值则由业务系统返回固定错误码,拉起前端验证码验身,验身成功后加入凭证服务器对应分数
Alipay's Xianyu is used This anti-swipe strategy to prevent data collection
Using a mobile phone normal access idle fish,大概半个小时,Will let me rest will do,give me a verification code 划一下,我当时还纳闷呢,It turned out to be to prevent data from being collected.,long-term access to data,A suspicious identity check will be performed
Current limiting and queue flooding(流量削峰)的再理解:
Assuming the limits of a machinetps是400,Then we limit the current to300tps,如果这300tpsall to askcreateOrder这个方法,Then at this time, if we don't need to queue floods,那么在这1needs to be processed in seconds300个请求,便是有300个线程,导致cpu将会在这个300Switch back and forth in the thread,使cpuincreased consumption,So for better handling300个线程,减小cpuswitching time overhead,减小cpu处理者300个请求的时间,So we introduce queue flooding,减少cpuTime to switch between threads,从而提高相应速度.
最后呢,我觉得,If we do not use queue flooding,In fact, the system should also be able to solve,But the response time will increase.But if we only use queue flooding,就只考虑createOrderThis interface should also be able to solve,但是有可能,会导致这个order类的tps过大,cause the system to fail.
所以,Current limiting should be complementary to queue flooding,Only using current limiting can solve the problem of excessive traffic,But it may lead to excessive concurrency,增加cpu的处理时间,So the introduction of queue flooding to reducecpu处理300个请求的时间.
边栏推荐
- 全部内置函数详细认识(中篇)
- HUAWEI CLOUD DevCloud received the highest-level certification of the first batch of cloud-native technology architecture maturity assessments by the China Academy of Information and Communications Te
- 2025年推出 奥迪透露将推出大型SUV产品
- Colocate Join :ClickHouse的一种高性能分布式join查询模型
- Colocate Join :ClickHouse的一种高性能分布式join查询模型
- Cesium Quick Start 4-Polylines primitive usage explanation
- 【21天学习挑战赛】折半查找
- 易基因|深度综述:m6A RNA甲基化在大脑发育和疾病中的表观转录调控作用
- NFT数字藏品——数字藏品发行平台开发
- 二叉树详解
猜你喜欢
Software Test Cases

商业版SSL证书
APP automation testing with Uiautomator2
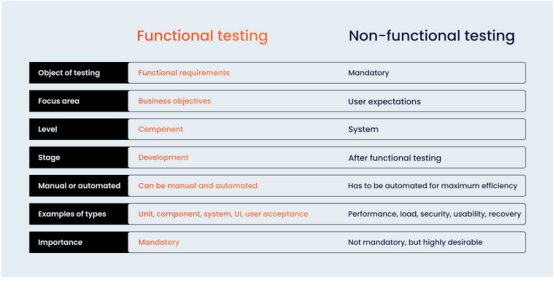
功能测试vs.非功能测试:能否非此即彼地进行选择?

使用 ABAP 正则表达式解析 uuid 的值

NFT digital collection development issue - digital collection platform
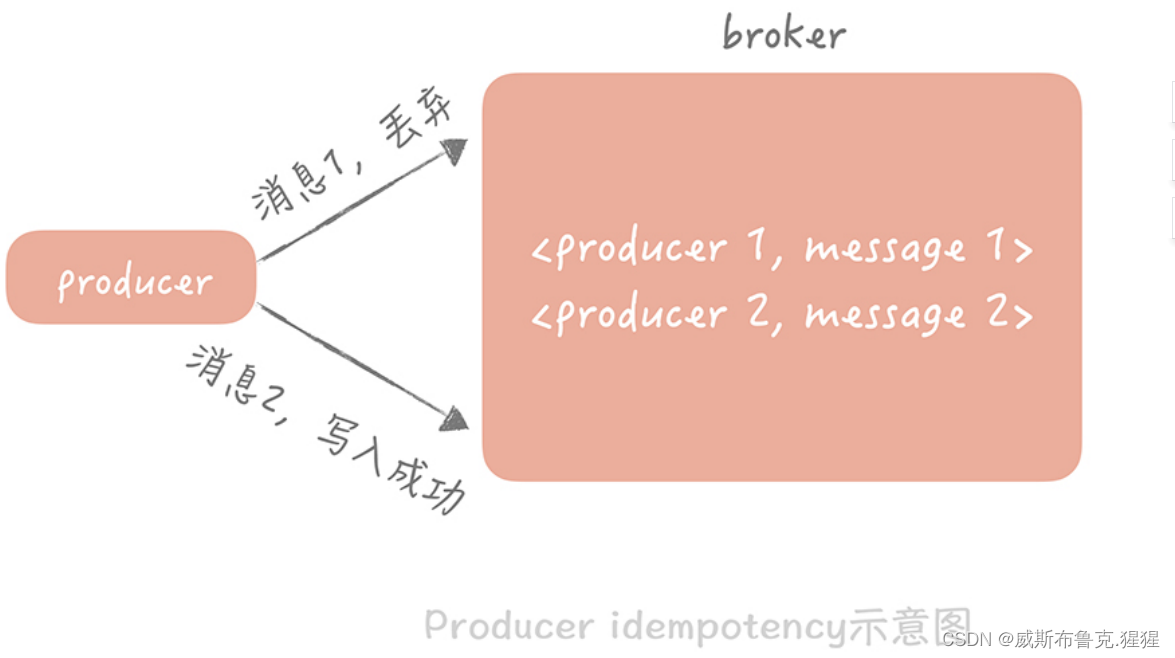
秒杀项目收获
全志V853开发板移植基于 LVGL 的 2048 小游戏

不爱生活的段子手不是好设计师|ONES 人物

It is reported that the original Meitu executive joined Weilai mobile phone, the top product may exceed 7,000 yuan
随机推荐
It is reported that the original Meitu executive joined Weilai mobile phone, the top product may exceed 7,000 yuan
E. Cross Swapping (and check out deformation/good questions)
Chapter one module of the re module,
Zhaoqi Technology Innovation High-level Talent Entrepreneurship Competition Platform
Opencv 图像超像素分割(SLIC、SEEDS、LSC)
Systemui status bar to add a new icon
metaForce佛萨奇2.0系统开发功能逻辑介绍
智为链接,慧享生活,荣耀智慧服务,只为 “懂” 你
不爱生活的段子手不是好设计师|ONES 人物
请查收 2022华为开发者大赛备赛攻略
一个 ABAP 工具,能打印系统里某个用户对 BSP 应用的浏览历史记录
安克创新每一个“五星好评”背后,有怎样的流程管理?
简述 Mock 接口测试
社区动态——恭喜海豚调度中国区用户组新晋 9 枚“社群管理员”
Network engineer's backpack (EDC summary recommendation)
MySQL batch update and batch update method of different values of multiple records
Taurus.MVC WebAPI 入门开发教程4:控制器方法及参数定义、获取及基础校验属性【Require】。
数据在内存中的存储
fastposter v2.9.1 programmer must-have poster generator
软件测试用例篇