当前位置:网站首页>SAS数据处理技术(一)
SAS数据处理技术(一)
2022-08-10 23:32:00 【metaX】
SAS数据处理技术
通常情况下,使用数据步进行数据处理是一个很好的选择。 数据步进行数据处理,可以提供。
灵活的编程功能 丰富的数据处理函数
其他的工具和技术
SORT, SQL, 以及TRANSPOSE过程步,其对数据的处理和变换是十分有用的。
SAS的宏功能让代码变的更加灵活。
调试(Debugging)技术,可以用来帮助识别逻辑错误。
SAS程序流程
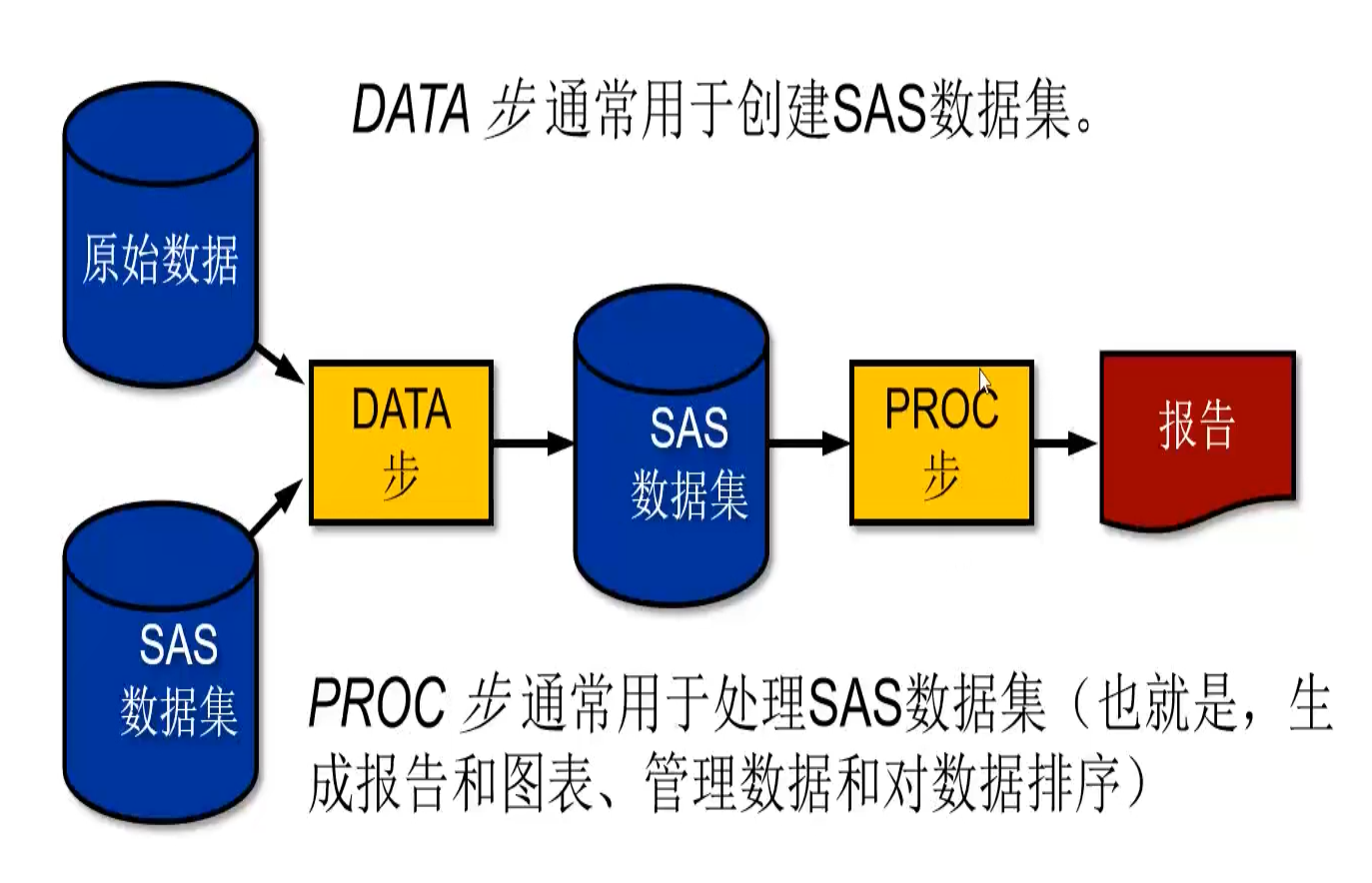
回顾一些知识点
SORT过程步的OUT=选项用来指定创建新的输出数据集, 而不是对原数据集进行覆盖。
用FORMAT过程可以创建用户自定义的输出格式和输入格式。默认情况下,创建的格式将被存储在目录
libname orion 's:\workshop';
data work.qtrlsalesrep;
proc sort data=work.qtrlsalesrep;
proc format;
value $ctryfmt 'AU'='Australia'
'US'='United tates';
run;

(选b; a是data那句,c是set那句)
由 INPUT语句和 赋值语句创建的变量会被重新初始化(初始化为缺失值)。 由 SET语句读取的变量不会被重新初始化(只会被后面的数据覆盖)
OUTPUT语句实现数据转置
输出多行观测
例中,每一行记录生成三个观测。每个新观测将包括代号ID和一次测验值SCORE.
data A;
input ID $ scorel-score3;
drop scorel-score3; # 不输出字段名(列名)
score=scorel;output;
score=score2;output;
score=score3;output;
cards;
02126 99 96 94
02128 89 90 88
;
proc print;
run;
使用一个数据步来输出创建多个SAS数据集
在一个数据步中,可以通过将输出数据集的 名称列在DATA语句内的方式来创建多个数据集。 通过在OUTPUT语句内指定数据集名称,可以直接输出至某个或多个特定的数据集
data usa australia other;
set orion.employee_addresses;
if Country='AU'then output australia;
else if Country='US'then output usa;
else output other;
run;
* 或者
data usa australia other;
set orion.employee addresses;
select (Country);
when ('US')output usa;
when ('AU')output australia;
otherwise output other;
end;
run;
*在SELECT语句中使用DO-END,当一个表达式为真时,使用DO-END语句可执行多个语句
使用条件语句来控制哪条观测输出至哪个数据集中
在数据步中,用DROP语句和KEEP语句可控制哪些变量会被输出至输出数据集中。
默认情况下,SAS对数据集中的所有观测逐条处理。用FIRSTOBS=和OBS=选项可控制对哪些观测进行处理。
创建一个累加变量
求和语句的一般形式:
variable + expression;
求和语句 若加号左边的变量之前不存在,则创建该变量 在数据步第一次循环前初始化该变量值为0 自动保留该变量 执行时,将表达式的值加在该变量上 忽略缺失值。
分组数据的累计求和
定义First..和Last.过程 计算分组数据的累计求和 使用子集IF语句来输出指定观测
data deptsals(keep=Dept Deptsal);
set SalSort;
by Dept;
if First.Dept then Deptsal=0;
Deptsal+Salary;
if Last.Dept;
run;
proc sort data=sashelp.cars
out=cars;
by Make;
run;
data total cars(keep=Make MSRP sum_price);
set cars;
by Make;
if first.Make then sum_price=0;
sum price+MSRP;
if last.Make;
run;
proc print data=total_cars noobs;
var Make sum_price;
format sum price dollar10.2;
run;
不同类型的数据使用不同的方式进行读取
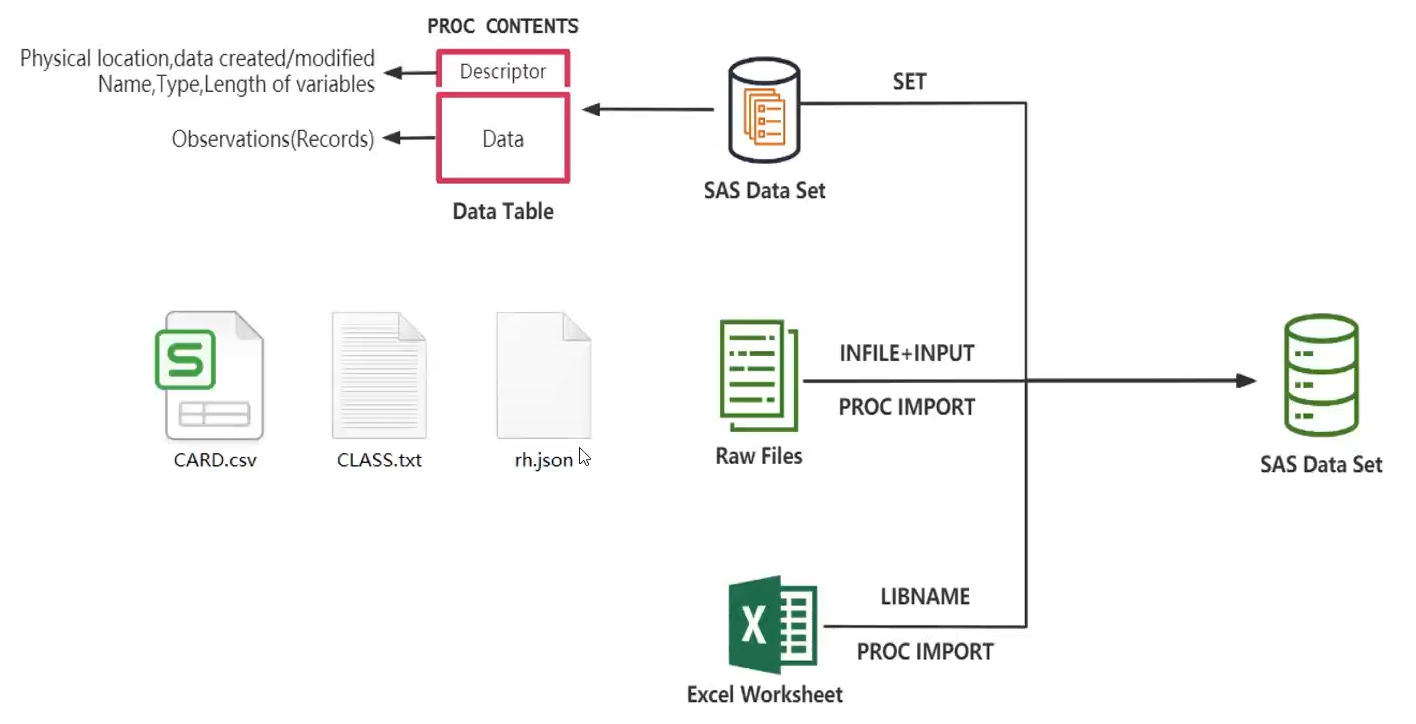
列输入,格式化输入和列表输入是用INPUT语句读取数据的三种方式。
| 方式 | 适用情况 |
|---|---|
| 列输入 | 数据列固定的标准数据 |
| 格式化输入 | 数据列固定的标准数据和非标准数据 |
| 列表输入 | 有空格或其他分隔符分开的标准数据和不标准数据 |
列输入(Column Input) 用列输入读入,数据满足的条件
in fixed fields
standard character or numeric values (如 58 -23 67.23 00.99 5.67E5 1.2E-2)
INPUT语句列输入法一般形式 :
INPUT variable <$> startcol-endcol...;
用格式化输入法读取原始数据文件
INPUT语句格式化输入法的一般形式: INPUT 指针控制 变量 输入格式...;格式化输入法通过下列方式读取数据: 移动输入指针至起始位置 对变量命名 规定输入格式 input @5 FirstName $10.;列控制指针:@n 将指针移至第n列 +n 将指针向后移动n列
控制何时载入记录
读取原始数据文件的多条记录为一条观测。
DATA SAS-data-set; INFILE 'raw-data-file-name'; INPUT specifications; INPUT specifications; <additional SAS statements> RUN;读取一个混合类型记录的原始数据文件。
行指针控制符控制何时载入新记录
DATA SAS-data-set; INFILE 'raw-data-file-name'; INPUT specifications/ specifications; <additional SAS statements> RUN;当SAS遇到一个“/”时,下一行的记录被载入。 行控制指针:# n 载入第n行 / 载入下一行
读取混合类型记录的原始数据文件的子集。
列表输入法的其他技巧
记录末尾的数据为缺失值。
INFILE 'raw-data-file'MISSOVER;缺失数据由两个连续分隔符表示
INFILE 'file-name' DSD;。每个记录含多条观测。
INPUT var1 var2 var3 [email protected]@
边栏推荐
猜你喜欢


随机推荐
62.【彻底改变你对C语言指针的厌恶(超详细)】
好用的翻译插件-一键自动翻译插件软件
HFCTF 2021 Internal System writeup
深度学习 Transformer架构解析
小程序平台工具如何选择和使用?
完全自定义MaterialButtonToggleGroup颜色。
性能不够,机器来凑;jvm调优实战操作详解
How to quickly grasp industry opportunities and introduce new ones more efficiently is an important proposition
2022牛客多校(七)K. Great Party博弈方法证明
postman+jmeter接口实例
房间虚拟样板间vr制作及价格
[uniapp] uniapp WeChat applet development: no such file or directory error when starting the WeChat developer tool
【C语言】初识指针
MySQL之JDBC编程增删改查
mysql数据库高级操作
【C语言篇】操作符之 位运算符详解(“ << ”,“ >> ”,“ & ”,“ | ”,“ ^ ”,“ ~ ”)
Geogebra 教程之 03 没有铅笔的数学
App的回归测试,有什么高效的测试方法?
proxy代理服务_2
Parse method's parameter list (including parameter names)