
The Python Package for DataHerb
A DataHerb Core Service to Create and Load Datasets.
Install
pip install dataherb
Documentation: dataherb.github.io/dataherb-python
The DataHerb Command-Line Tool
Requires Python 3
The DataHerb cli provides tools to create dataset metadata, validate metadata, search dataset in flora, and download dataset.
Search and Download
Search by keyword
dataherb search covid19
# Shows the minimal metadata
Search by dataherb id
dataherb search -i covid19_eu_data
# Shows the full metadata
Download dataset by dataherb id
dataherb download covid19_eu_data
# Downloads this dataset: http://dataherb.io/flora/covid19_eu_data
Create Dataset Using Command Line Tool
We provide a template for dataset creation.
Within a dataset folder where the data files are located, use the following command line tool to create the metadata template.
dataherb create
Upload dataset to remote
Within the dataset folder, run
dataherb upload
UI for all the datasets in a flora
dataherb serve
Use DataHerb in Your Code
Load Data into DataFrame
# Load the package
from dataherb.flora import Flora
# Initialize Flora service
# The Flora service holds all the dataset metadata
use_flora = "path/to/my/flora.json"
dataherb = Flora(flora=use_flora)
# Search datasets with keyword(s)
geo_datasets = dataherb.search("geo")
print(geo_datasets)
# Get a specific file from a dataset and load as DataFrame
tz_df = pd.read_csv(
dataherb.herb(
"geonames_timezone"
).get_resource(
"dataset/geonames_timezone.csv"
)
)
print(tz_df)
The DataHerb Project
What is DataHerb
DataHerb is an open-source data discovery and management tool.
- A DataHerb or Herb is a dataset. A dataset comes with the data files, and the metadata of the data files.
- A Herb Resource or Resource is a data file in the DataHerb.
- A Flora is the combination of all the DataHerbs.
In many data projects, finding the right datasets to enhance your data is one of the most time consuming part. DataHerb adds flavor to your data project. By creating metadata and manage the datasets systematically, locating an dataset is much easier.
Currently, dataherb supports sync dataset between local and S3/git. Each dataset can have its own remote location.
What is DataHerb Flora
We desigined the following workflow to share and index open datasets.
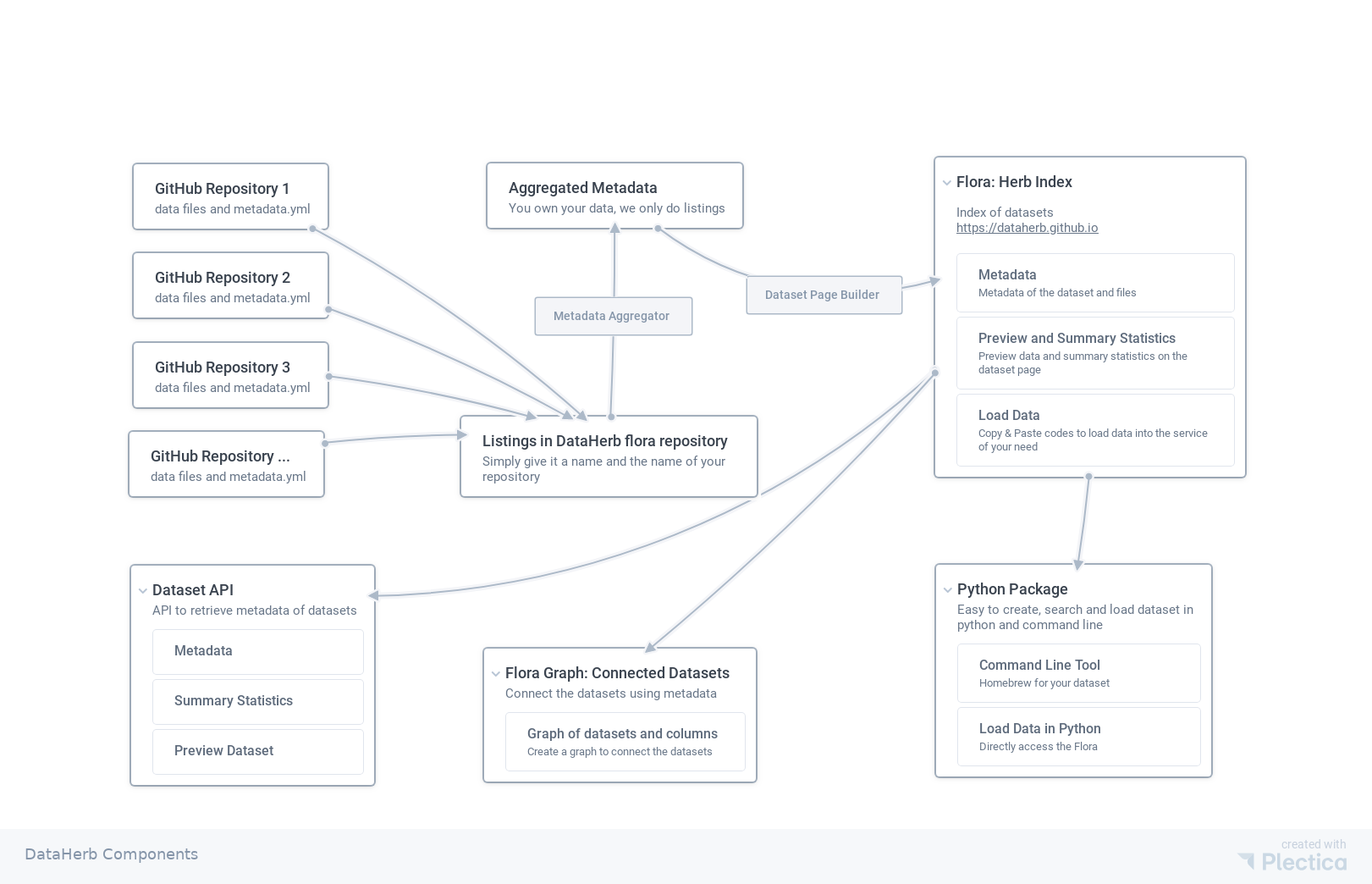
The repo dataherb-flora is a demo flora that lists some datasets and demonstrated on the website https://dataherb.github.io. At this moment, the whole system is being renovated.
Development
- Create a conda environment.
- Install requirements:
pip install -r requirements.txt
Documentation
The source of the documentation for this package is located at docs.
References and Acknolwedgement
dataherbusesdatapackagein the core.datapackageis a python library for the data-package standard. The core schema of the dataset is essentially the data-package standard.




 3k Jan 02, 2023
3k Jan 02, 2023
 107 Jan 04, 2023
107 Jan 04, 2023
 1 Feb 07, 2022
1 Feb 07, 2022
 21 Mar 16, 2022
21 Mar 16, 2022
 906 Jan 01, 2023
906 Jan 01, 2023
 5 Jul 13, 2022
5 Jul 13, 2022
 16 Jun 09, 2022
16 Jun 09, 2022
 16 Nov 04, 2022
16 Nov 04, 2022
 65 Dec 09, 2022
65 Dec 09, 2022
 1 Feb 14, 2022
1 Feb 14, 2022
 1 Dec 29, 2021
1 Dec 29, 2021
 2 Feb 10, 2022
2 Feb 10, 2022
 37 Dec 27, 2022
37 Dec 27, 2022
 25 Dec 26, 2022
25 Dec 26, 2022
 2 Jun 17, 2022
2 Jun 17, 2022
 2 Jul 22, 2022
2 Jul 22, 2022
 48 Dec 21, 2022
48 Dec 21, 2022
 32 Nov 27, 2022
32 Nov 27, 2022
 3 Aug 22, 2022
3 Aug 22, 2022
 4 Jan 12, 2022
4 Jan 12, 2022